全局广播和本地广播的区别及原理
区别及原理
锁
美团技术博客-锁相关
美团的这篇文章很详细,需要仔细看。
Okhttp源码解析
精品解析Okhttp
Okhttp几个问题
前言:
Okhttp有几个核心类,我们需要对其功能有个大致的了解:
①OkHttpClient:整个OkHttp的核心管理类。
②Request:发送请求封装类,内部有 url 、header、method、body等常见参数
③Response:请求的结果,包含code、message、header、body
④RealCall:负责请求的调度(同步走当前线程发送请求,异步使用Okhttp内部线程池进行);同时负责构造内部逻辑【责任链】。虽然OkHttpClient是整个Okhttp的核心管理类,但真正发送请求并组织逻辑的是RealCall类,它同时肩负了调度和责任链组织的两大重任。有两个最重要的方法execute()和enqueue(),前者处理同步请求,后者处理异步请求。而这个异步请求,就是通过异步线程和callback做了一个异步调用的封装,最终还是和exucute()方法一样调用getResponseWithInterceptorChain()获得请求结果。
接下来我们进行具体的分析,这里用的是Okhttp 4.9.1版本。也是截止到2021/05/16最新的版本。
OkhttpClient
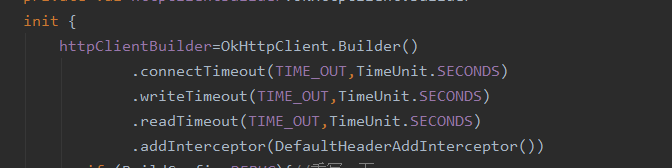
我们构造OkhttpClient的时候,都是用OkhttpClient.Builder()来构造实例的,可以看到这里用的第一个设计模式就是建造者模式。
我们可以使用通过Builder来指定用户自定义的拦截器、超时时间,连接池、事件监听器等诸多属性。最后调用build()方法来创建OkhttpClient。
在其init方法中会创建TrustManager、sslSockFacotry等(跟https有关)、

RealCall
我们在发送请求的时,会调用OkHttpClient的newCall方法发送同步或异步请求。
此方法实际上就是new了一个RealCall对象。

在RealCall中有几个重要的属性:

①RealConnectionPool:连接池,负责管理和复用连接
②eventListener:请求回调,比如连接请求开始、取消、失败、结束等
③executed:原子类。连接是否已经执行,每次execute前都会检查此字段,避免请求重复执行
④connection:RealConnection类型,代表真实的连接。
其他字段暂不分析。
具体请求【execute()/enqueue()执行流程】
因为execute()和enqueue()最终都是调用getReponseWithInterceptorsChain()方法。所以两个方法我们只挑出enqueue进行分析。

首先就是一个CAS操作,判断executed字段,也就是请求是否执行过。然后调用eventListener通知各个监听者请求开始。

接着就是构造一个AsyncCall对象塞进OkHttpClient的Dispatcher中

Dispatcher中创建了请求线程池executorService,而AsyncCall实现了Runnable接口,实际上就是将请求放到线程池中处理。
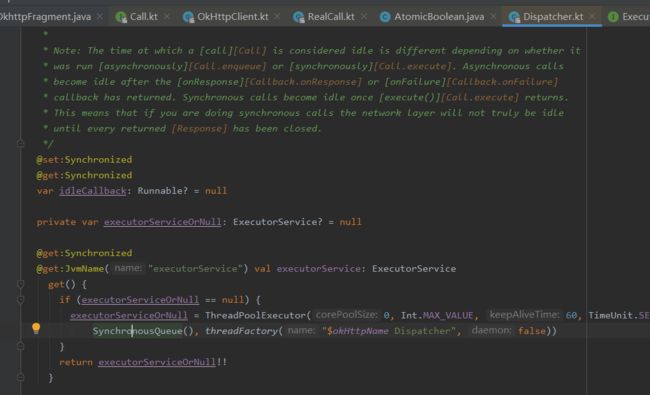
可以看到这里的阻塞队列用的是SynchronousQueue,一个不存储元素的阻塞队列,容量为0,默认非公平。
Java常见阻塞队列详解
所以具体逻辑还是在AsyncCall中的#run方法中,AsyncCall是RealCall的一个内部类,在其构造方法中传入了responseCallback参数。
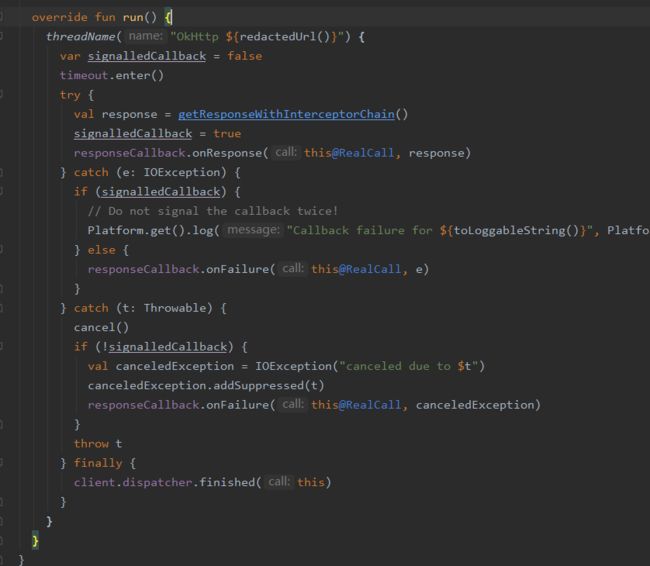
可以看到在run方法中通过getResponseWithInterceptorChain()方法拿到请求结果后,会通过reponseCallback将请求结果(失败、成功结果)通知给上层。
下面就是OkHttpClient最核心的getResponseWithInterceptorChain()方法的分析了,此方法承载了整个请求的核心逻辑:

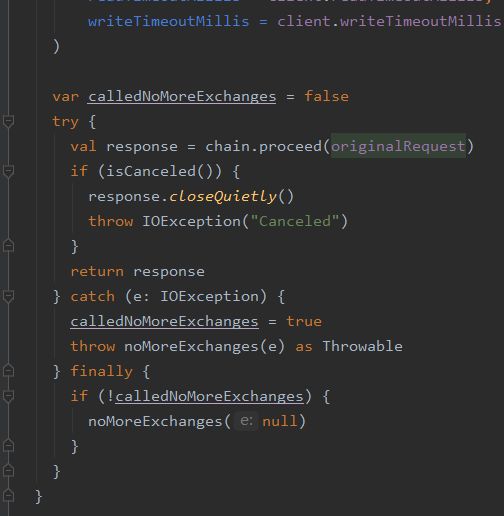
首先生成了一个Interceptors,拦截器的List列表,按顺序依次将:
client.Interceptors
RetryAndFollowUpInterceptor,
BridgeInterceptor
CacheInterceptor
ConnectInterceptor
client.networkInterceptors
CallServerInterceptor
这些拦截器添加到List中,然后创建了一个RealInterceptroChain的类,最后的请求结果Response通过chain.proceed获取到。
OkHttp将整个请求的复杂逻辑切成了一个一个的独立模块并命名为拦截器(Interceptor),通过责任链的设计模式串联到了一起,最终完成请求获取响应结果。 这也是我们看到的第二个设计模式:责任链模式。
proceed方法:
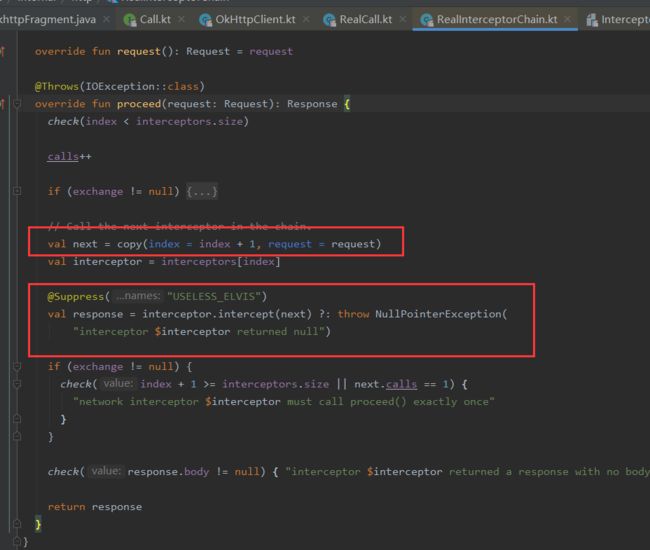
其处理流程就是按照责任链添加进来的顺序依次执行各个责任链:

**每个拦截器在执行之前,会将剩余尚未执行的拦截器组成新的RealInterceptorChain。
拦截器的逻辑被新的责任链调用next.preceed()切分为start、next.preceed、end这三个部分执行。
next.proceed()所代表的其实就是剩余所有拦截器的执行逻辑。
所有拦截器最终会形成一个层层嵌套的嵌套结构。(N个RealInterceptorChain)
**
抛开用户自定义的拦截器client.interceptors和client.networkInterceptors,总共添加了五个拦截器:
**
RetryAndFollowUpInterceptor : 失败和重定向拦截器
BridgeInterceptor : 封装request和response拦截器
CacheInterceptor : 缓存相关的过滤器,负责读取缓存直接返回、更新缓存
ConnectInterceptor : 连接服务,负责和服务器建立连接,真正网络请求开始的地方
CallServerInterceptor :执行流操作(写出请求体、获得相应数据)负责向服务器发送请求数据、从服务器读取相应数据,进行http请求报文的封装和请求报文的解析。
**
下面我们挨个对每一个拦截器进行分析。
1.RetryAndFollowUpInterceptor
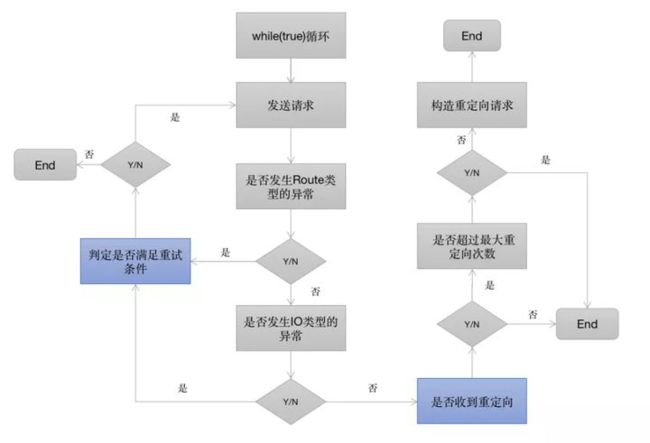

RetryAndFollowUpInterceptor的#intercept开启了一while(true)死循环,并在循环内部完成两个重要的判定:
①当请求内部抛出异常时,判断是否需要重试
②当响应结果是3xx重定向时,构建新的请求并发送请求。
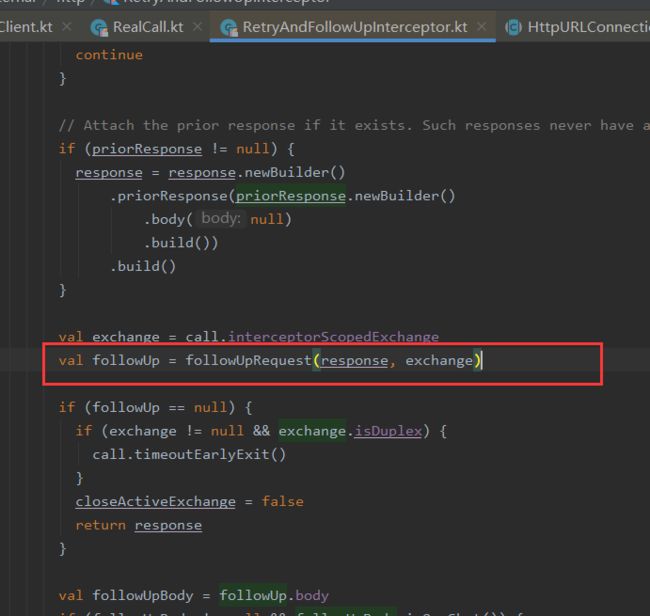
是否重试的逻辑在RetryAndFollowUpInterceptor的#recover方法中:
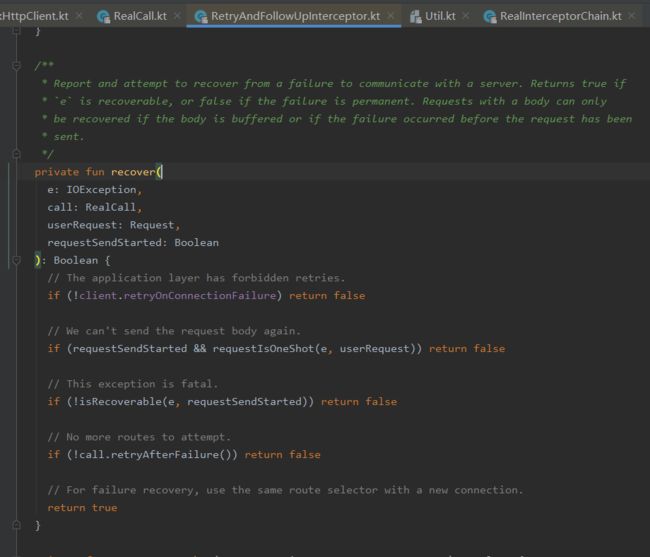
判断逻辑如上图所示:
①client的retryOnConnectionFailure参数设置为false,不进行重试
②请求的body已经发出,不进行重试
③特殊的异常类型不进行重试,如ProtocolException、SSLHandshakeException等
④没有更多的route,不进行重试
前面四条规则都不符合的请求下,才会重试。
重定向调用的是#followUpRequest方法:
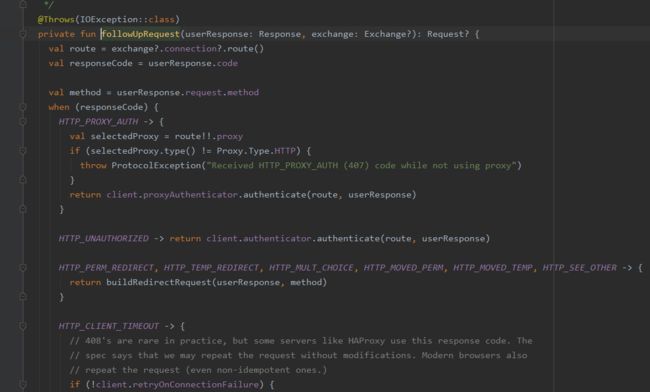
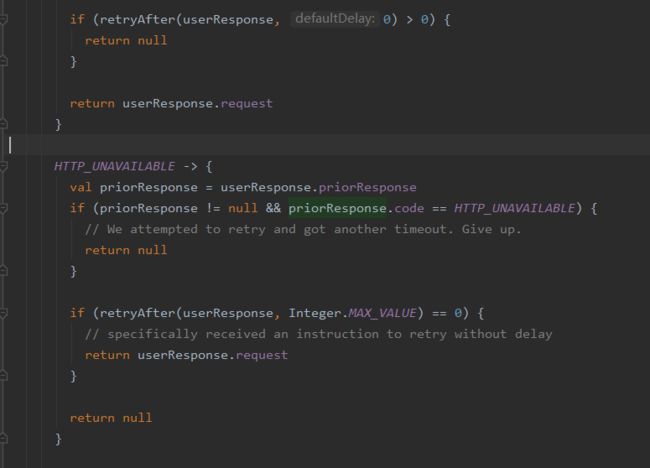
就是根据各种错误码,重构Request进行请求,或者直接返回null.
Interceptors和NetworkInterceptors的区别

getResponseWithInterceptorChain中之前说过的两种用户自义定的拦截器:
interceptors和networkInterceptors从RetryAndFollowUpInterceptor分析后就可以看出区别了:
从前面添加拦截器的顺序可以知道** Interceptors 和 networkInterceptors 刚好一个在 RetryAndFollowUpInterceptor 的前面,一个在后面。**
结合前面的责任链调用图可以分析出来,假如一个请求在 RetryAndFollowUpInterceptor 这个拦截器内部重试或者重定向了 N 次,那么其内部嵌套的所有拦截器也会被调用N次,同样 networkInterceptors 自定义的拦截器也会被调用 N 次。而相对的 Interceptors 则一个请求只会调用一次,所以在OkHttp的内部也将其称之为 Application Interceptor。
2.BridgeInterceptor

主要功能如下:
①负责把用户构造的请求转换转换为发送到服务器的请求、把服务器返回的响应转换为用户友好的响应,是从应用程序代码到网络代码的桥梁。(第三个模式:桥接模式)
但实际上看源码,只看到设置一些请求头,没看到其他操作。
②设置内容长度,内容编码
③设置gzip压缩,并在接收到内容后进行解压。
④添加cookie
⑤ 设置其他报文头,如Keep-Alive,Host等。其中Keep-Alive是实现连接复用的必要步骤。

3.CacheInterceptor
具体逻辑如下:
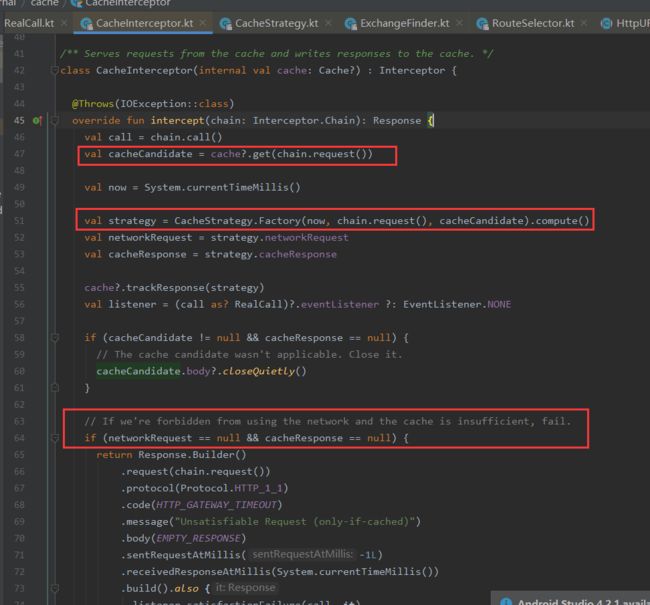
① 通过Request尝试到Cache拿缓存。前提是OkHttpClient中配置了缓存,默认是不支持的。Cache中用的是DiskLruCache,也就是磁盘缓存。
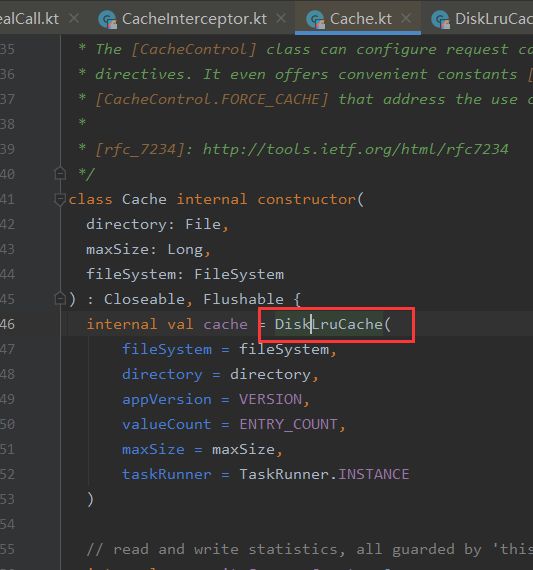
②根据当前时间now、request、response创建一个缓存策略,用户判断这样使用缓存。这里的缓存工厂:CacheStrategy.Factory用到的是工厂模式(第四个设计模式)
③如果缓存策略中设置禁止使用网络,并且缓存为空,则构建一个Response直接返回,返回码为504.(网关超时)
④缓存策略中 不使用网络,但是有缓存,直接返回缓存
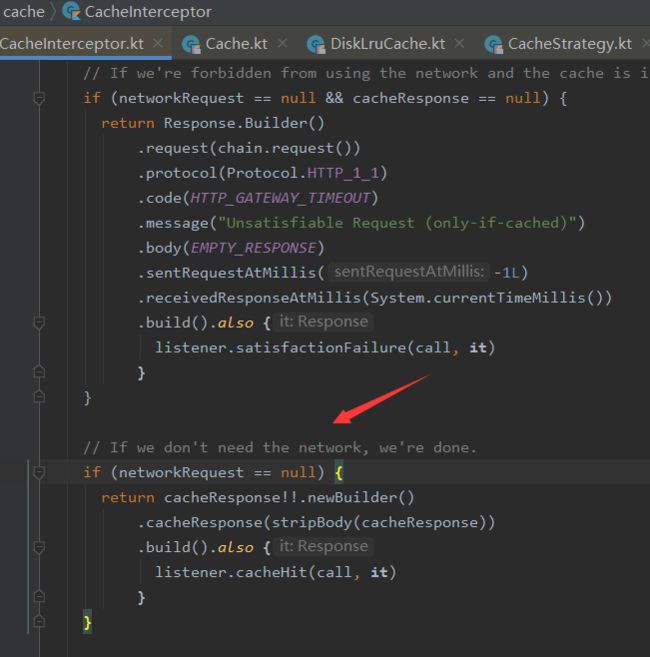
⑤接着走后续过滤器的流程,chain.proceed(networkRequest)
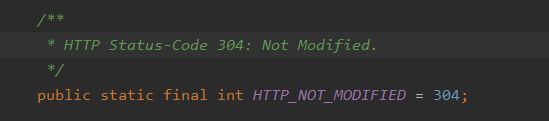
⑥当缓存存在的时候,如果网络返回的Response为304,则使用缓存的Response
⑦根据返回的networkReponse构造网络网络请求的Response
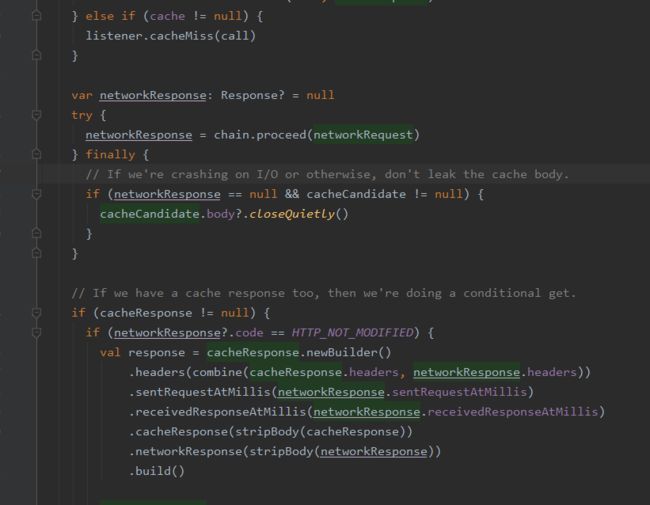
⑧当在OkHttpClient中配置了缓存,则将这个Response缓存起来。
⑨缓存起来的步骤是先缓存header,再缓存body。
⑩返回Response。
接下来的两个Interceptor就是OKHttp中最重要的两个拦截器了:
4.ConnectInterceptor

只有简单的两句:
val exchange = realChain.call.initExchange(chain)
val connectedChain = realChain.copy(exchange = exchange)
调用RealCall的initExchange初始化Exchange。Exchange中有很多逻辑,涉及了整个网络连接建议的过程,包括dns过程和socket连接的过程。(注意,在javva实现的时候,试试从Transmitter获得了一个新的Exchange对象,之前Exchange)

** 里面直接new了一个Exchange对象,并传入了RealCall、eventListener、exchangeFinder、codec对象。
codec是ExchangeCodec类型的,这是一个接口,有两个实现:
①Http1ExchangeCodec
②Http2ExchangeCodec
分别对应Http1协议和Http2协议。**

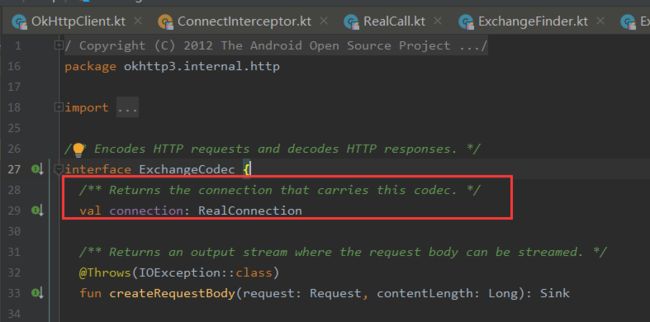
Exchange里包含了一个ExchangeCodec对象,这个对象里面又包含了一个RealConnection对象,RealConnection的属性成员有socket、handShake、protocol、http2Connection等,实际上RealConnection就是一个Socket连接的包装类。而ExchangeCode对象就是对RealConnection操作(writeRequestHeader、readResponseHeader)的封装。

ConnectInterceptor内部完成了socket连接,其连接对应的方法就是ExchangeFinder里的#findHealthyConnection


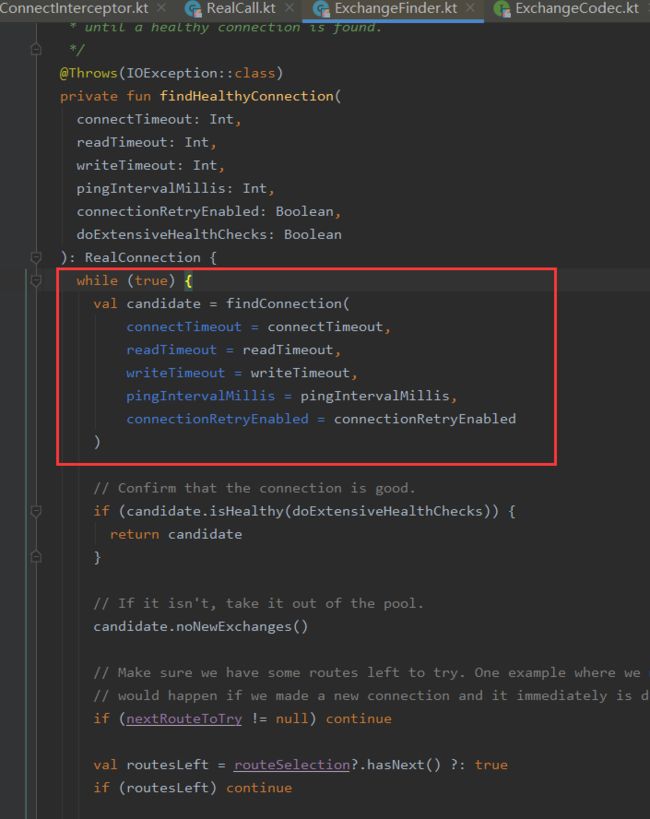
在findHealthyConnection中会开启一个死循环,调用findConnection方法获取一个正确的连接,直到获取一个正确的连接才会退出。接下来我们就看socket连接到底是在哪里建立的:
在findConnection中会先从连接池中尝试获取连接,如果能获取到就返回连接;如果获取不到,则通过RouteSelector选择合适的Route(保存请求地址、代理服务器等信息),然后调用RealConnection的connect方法。
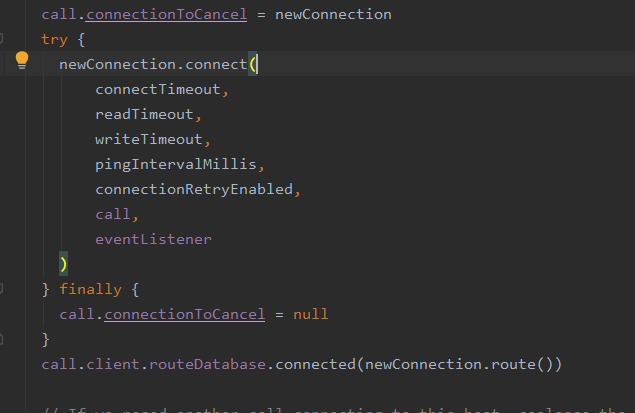
其内部或调用connectSocket方法:
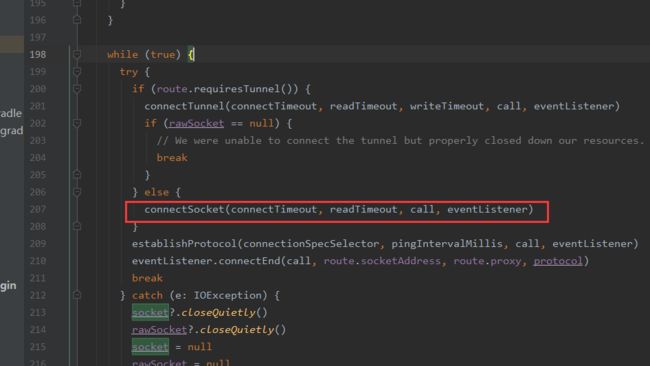
内部又调用:
Platform.get().connectSocket(rawSocket, route.socketAddress, connectTimeout)
Platform的connectonSocket中会调用socket.connect进行真正的socket连接。

在socket连接之前,还有一个dns的过程,也是隐含在findHealthConnection的内部逻辑。后面再说。
在执行完ConnectInterceptor之后,其实添加了自定义的网络拦截器networkInterceptors,按照顺序执行的规定,所有的networkInterceptor执行执行,socket连接其实已经建立了,可以通过realChain拿到socket做一些事情了,这也就是为什么称之为network Interceptor的原因。
5.CallServerInterceptor
最后一个拦截器,前面的拦截器已经完成了socket连接和TLS连接,这一步就是传输http的头部和body数据。
由以下步骤组成:
①向服务器发送request header
②如果有request body,就向服务器发送
③读取response header,先构造一个Response对象
④读取有reponse body,就在③的基础上加上body构造一个新的Response对象。
一些其他重要概念分析
1.Connection连接复用
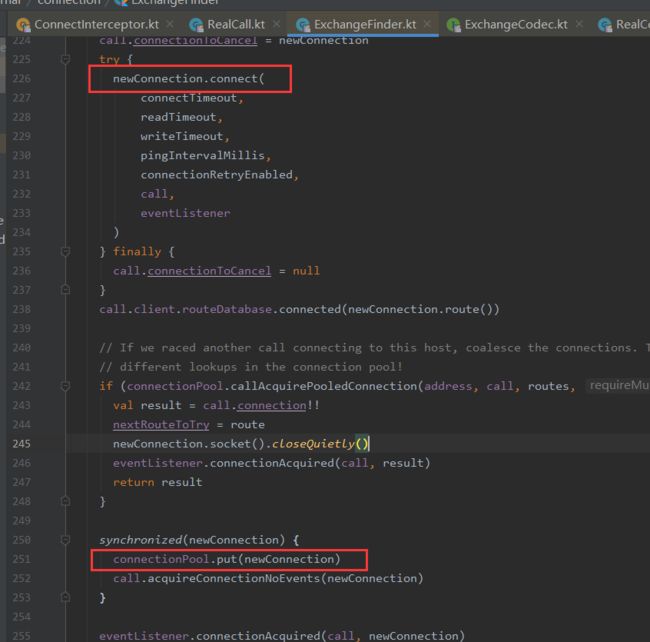
在ExchangeFinder的#findConnection方法中,通过RealConnection的connect方法建立socket连接后,RealConnection中持有的socket更新为连接的socket,之后回在临界区中将这个newConnection也就是RealConnetion放到connectionPool中。
在RealConnectionPool中有一个ConcurrentLinkedQueue类型的connections用俩存储复用的RealConnection对象。

2.DNS过程
DNS过程隐藏在RouteSelector检查中,我们需要搞明白RouteSelector、RouterSelection、Route三个类的关系。


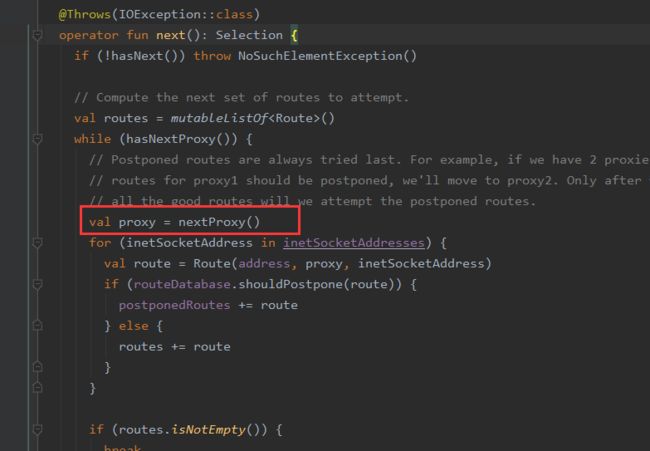
①RouteSelector在调用next遍历在不同proxy情况下获得下一个Selection封装类,Selection持有一个Route列表,也就是每个proxy都对应有Route列表
②Selection其实就是针对List
③RouteSelector的next()方法内部调用了nextProxy(),nextProxy()内部又调用resetNextInetSocketAddress()方法。
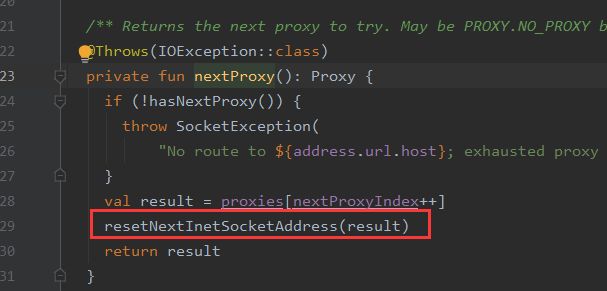
④resetNextInetSocketAddress通过address.dns.lookup获取InetSocketAddress,也就是IP地址。

通过上面一系列流程知道,IP地址最终是通过address的dns获取到的,而这个dns又是怎么构建的呢?
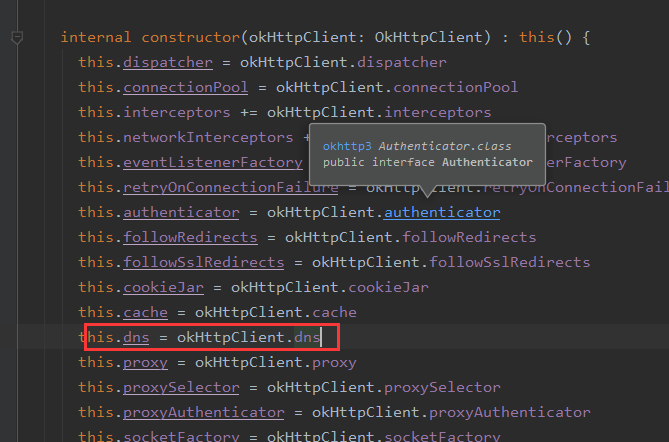
反向追踪代码可以看到就是构建OkhttpClient的时候传递进来的。默认值是
内部的lookup是通过InetAddress.getAllByName方法获取到对应域名的IP,也就是默认的DNS实现。

涉及到的设计模式简单总结
①责任链,这个无需多言
②建造者模式:OkHttpClient的构造过程
③工厂模式:CacheInterceptor中缓存工厂:CacheStrategy.Factory
④观察者模式:eventListener中的各种监听回调
⑤单例模式:Platform中的get()方法,一个懒汉。(其中的connectSocket方法是socket真正connect的地方)
其他
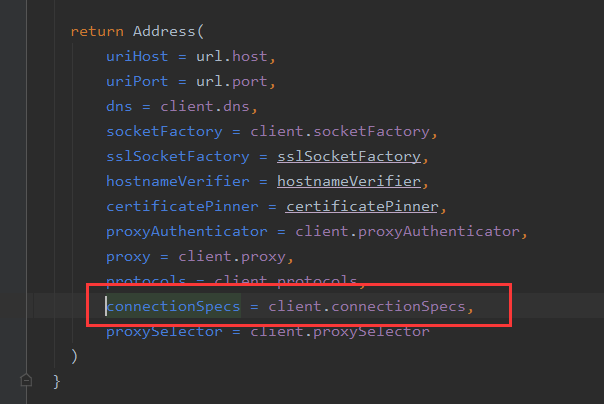
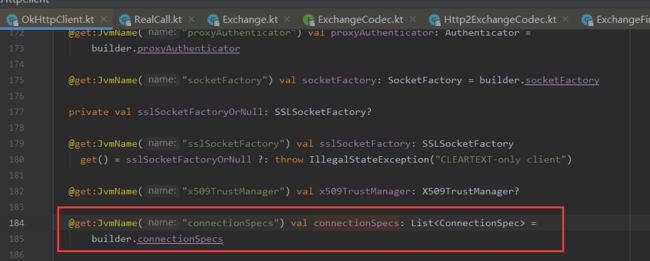
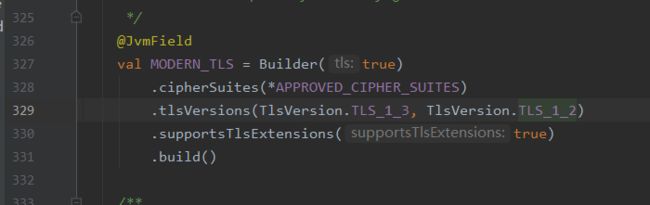
是否使用Http2是由Address中的protocols决定的,这个List中记录了客户端支持的协议。protocols又取自connectionSpecs字段。由OkHttpClient.Builder中指定connectionSpecs。具体使用的协议由RealConnection中的Protocol记录。

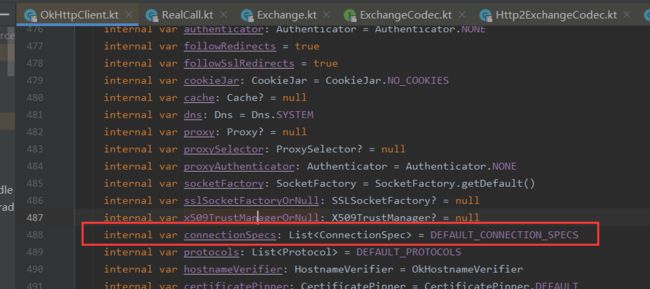
默认支持的协议是TLS_1_3和TLS_1_2

Android大图加载
Android加载大图、多图策略
我们编写的应用程序都是有一定内存限制的,程序占用了过高的内存就容易出现OOM异常,我们可以通过以下代码查看每个应用程序最高可用内存是多少
public static String getDeviceMaxMemory() {
long maxMemory = Runtime.getRuntime().maxMemory();
return maxMemory / (8 * 1024 * 1024) + "MB";
}
因此在展示高分辨率图片的时候,最好先将图片进行压缩。压缩后的图片大小应该和用来展示它的空间大小相近。
BitmapFactory这个类提供了多个解析方法(decodeByteArray, decodeFile, decodeResource等)用于创建Bitmap对象,我们应该根据图片的来源选择合适的方法。

①decodeFile:可以从本地File文件中加载Bitmap
②decodeResource:加载资源文件中的图片
③decodeByteArray:加载字节流形式的图片
④decodeStream:加载网络图片
这些方法均会为已经构建的bitmap分配内存,这是就很容易会导致OOM.
为此每一种解析方法都提供了一种可选的BitmapFactory.Options参数,将这个参数的inJustDecodeBounds属性设置为true就可以让解析方法禁止为bitmap分配内存,返回值也不再是一个Bitmap对象,而是null。虽然是null,但是BitamapFactory.Options的outWidth、outHeight和outMineType属性都会被赋值,这个技巧就可以让我们在加载图片之前就获得图片的长宽值和MIME类型,从而根据情况对图片进行压缩。
当我们知道图片大小后,就可以决定是把整张图加载到内存中还是加载一个压缩版的图片,下面这些因素就是我们接下来要考虑的:
①预估一下加载整张图片所需占用的内存
②为了加载这一张图片我们愿意提供多少内存
③用于展示这张图片的控件的实际大小
③当前设备的屏幕尺寸和分辨率
如果将一张1080×720的图像放到840×480的屏幕并不会得到更好的显示效果(和840×480的图像显示效果是一致的),反而会浪费更多的内存。
那么这时候怎么压缩呢?
inSampleSize参数
通过设置BitmapFactory.Options中的inSampleSize的值就可以实现.inSampleSize即采样率,采样率为1时是原始大小,为2时,宽高均为原来的二分之一,像素数和占用内存数就变为原来的四分之一,采样率一般是2的指数,即1.2.4.8...
为甚是2的指数呢,因为源码里注释里标了:

inPreferredConfig
这个值是设置色彩模式,默认值是ARGB_8888,在这个模式下,一个像素点占用4个字节,如果不对透明度有要求的话,一般采用RGB_565模式,这个模式下一个像素点占用2个字节,只解析RGB通道颜色值。
ALPHA_8:每个像素点仅表示alpha的值,不会存储任何颜色信息,占1个字节。
ARGB_4444:和8888类似,2个字节,但图片分辨率较低,已经不推荐使用了。
并不是每次通过设置inPreferredConfig都能减少我们Bitmap所占的内存。
当我们图片是png的时候,我们设置成什么都没用。当我们图片是jpg8位,24位,32位时,我们通过设置inPreferredConfig位RGB_565时,可以减少一半的内存占用。当我们解析的图片是jpg8位时,通过设置inPreferredConfig位ALPHA_8时可以减少四分之三的内存占用。
当我们不指定inPreferredConfig的值时,我们默认使用RGB_8888来解码,当指定了的inPreferredConfig值不满足时,例如png图片使用RGB_565来解码时,系统默认会选择RGB_8888来解码。
接下来我们就可以进行具体操作了:
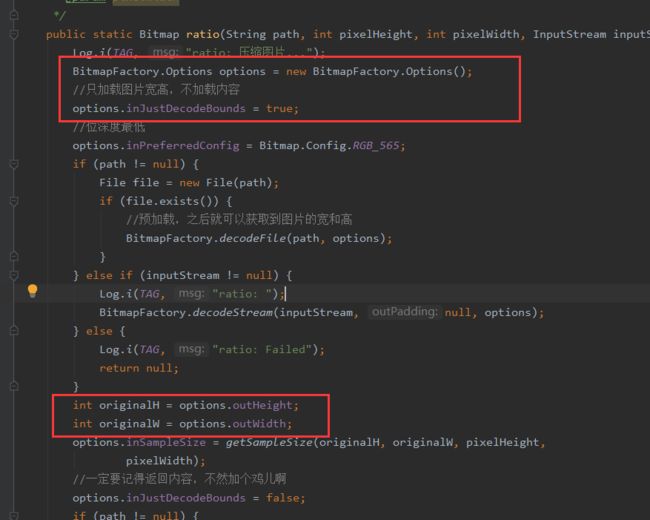
public static Bitmap ratio(String path, int pixelHeight, int pixelWidth, InputStream inputStream) {
Log.i(TAG, "ratio: 压缩图片...");
BitmapFactory.Options options = new BitmapFactory.Options();
//只加载图片宽高,不加载内容
options.inJustDecodeBounds = true;
//位深度最低
options.inPreferredConfig = Bitmap.Config.RGB_565;
if (path != null) {
File file = new File(path);
if (file.exists()) {
//预加载,之后就可以获取到图片的宽和高
BitmapFactory.decodeFile(path, options);
}
} else if (inputStream != null) {
Log.i(TAG, "ratio: ");
BitmapFactory.decodeStream(inputStream, null, options);
} else {
Log.i(TAG, "ratio: Failed");
return null;
}
int originalH = options.outHeight;
int originalW = options.outWidth;
options.inSampleSize = getSampleSize(originalH, originalW, pixelHeight,
pixelWidth);
//一定要记得返回内容,不然加个鸡儿啊
options.inJustDecodeBounds = false;
if (path != null) {
return BitmapFactory.decodeFile(path, options);
} else {
Log.i(TAG, "ratio: decodeStream...");
return BitmapFactory.decodeStream(inputStream, null, options);
}
}
private static int getSampleSize(int imgHeight, int imgWidth, int viewHeight, int viewWidth) {
int inSampleSize = 1;
if (imgHeight > viewHeight || imgWidth > viewWidth) {
int heightRatio = Math.round((float) imgHeight / (float) viewHeight);
int widthRatio = Math.round((float) imgWidth/ (float) viewWidth);
inSampleSize = Math.min(widthRatio, heightRatio);
}
return inSampleSize;
}
①首先构造BitmapFactory.Options,指定inJustDecodeBounds为true,只加载图片宽高,不加载到内存中。
②接着指定位深度,也就是inPreferredConfig为Bitmap.Config.RGB_565.
③然后就可以通过#decodeFile或者#decodeStream等方法预加载图片的原始宽高。
拿到图片原始宽高后,再根据传进来的控件的宽高计算采样率,选择宽和高中最小的比率作为采样率值,这样能保证图片最后的宽高一定都会大于等于目标的宽、高。
④指定好采样率后,将inJustDecodeBounds置为false,调用deoceFile等将期望尺寸的图片加载到内存中返回。
图片三级缓存
/**
* 用户加载网络图片
*
* @param view
* @param url
*/
public void displayImage(ImageView view, String url) {
Bitmap bitmap;
bitmap = getBitmapFromCache(url);
Log.i(TAG, "displayImage: bitmap:" + (bitmap == null));
if (bitmap != null) {
Log.i(TAG, "displayImage: getBitmap From Cache");
view.setImageBitmap(bitmap);
return;
}
bitmap = getBitmapFromLocal(url);
if (bitmap != null) {
Log.i(TAG, "displayImage: getBitmap From Local");
view.setImageBitmap(bitmap);
//从本地取得也要放到缓存中
putBitmapToCache(url, bitmap);
return;
}
getBitmapFromNet(view, url);
}
整体思路就是先从LruCache缓存中获取图片,如果缓存中直接返回。如果没有,从本地文件中获取,如果本地文件中有,将其加到缓存中并返回;如果本地文件中也没有,就网络请求,并加载到本地文件和缓存中返回。
Handler源码解析
Handler源码分析
Handler 27问
1.创建流程
再创建Handler的时候,会创建Looper对象,并获取Looper的MessageQueue消息队列:
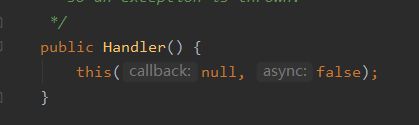

其中Looper是从Looper.myLooper()中获取的:
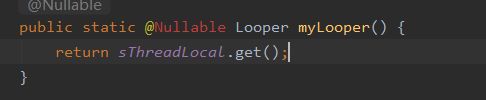
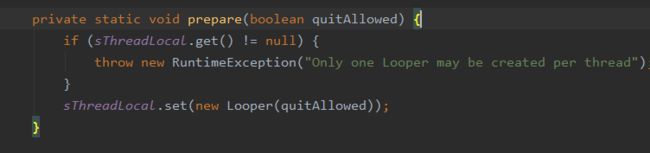
而Looper对象从上面可以看出,是在Looper的#prepare方法中,new了一个Looper存放到ThreadLocal中,这就保证了每一个线程只有一个唯一的Looper。
在Looper的构造方法中实例化了两个重要的参数:
①mQueue:MessageQueue,也就是消息队列
②mThread:当前线程。
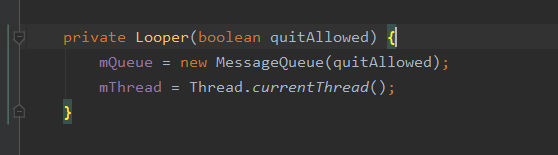
Looper的创建主要有两种方法:
①Looper.prepare()
②Looper.prepareMainLooper():主线程Looper,在ActivityThread的mai方法中调用并创建主线程Looper
2.Looper消息循环
生成Looper&MessageQueue之后,会自动进入消息循环Looper.loop(),一个隐式操作。(没找到手动调用的地方)
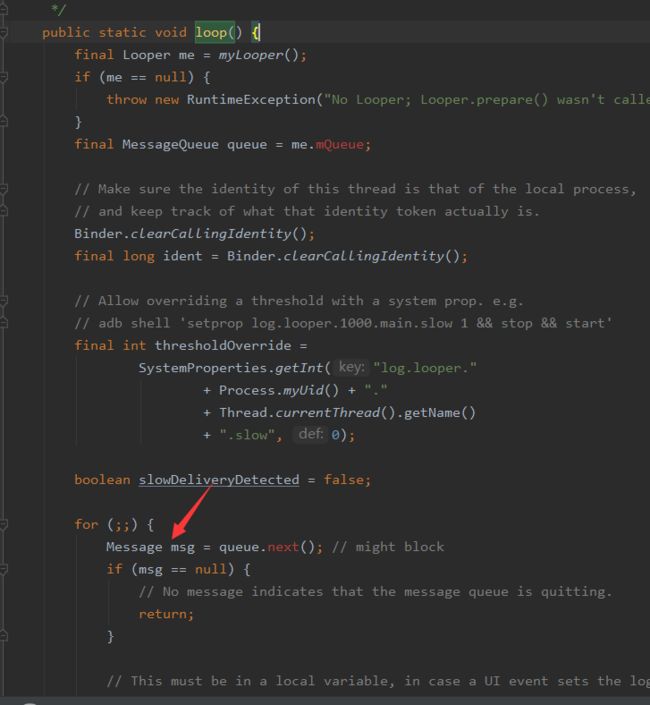
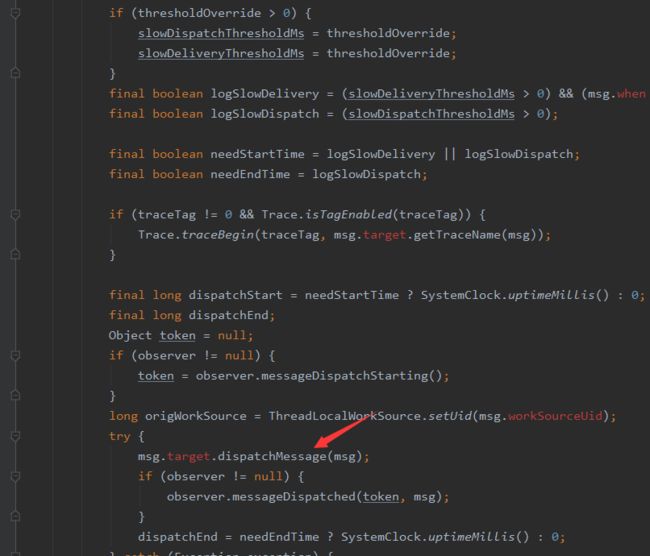

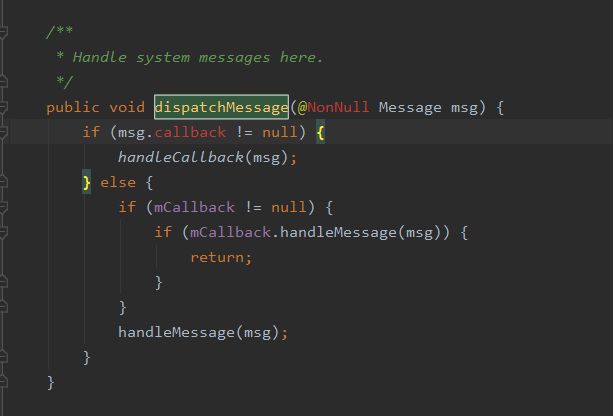
在#loop方法中,会开始一个for死循环,调用MessageQueue的next方法一直从消息队列中取出消息,调用Handler的dispatchMessage方法,将消息发送到对应的Handler。最后调用Message的#recycleUnChecked方法释放消息占据的资源。
特别注意:在进行消息分发时(dispatchMessage(msg)),会进行1次发送方式的判断(Activity插件化的重点):
若msg.callback属性不为空,则代表使用了post(Runnable r)发送消息,则直接回调Runnable对象里复写的run()
若msg.callback属性为空,则代表使用了sendMessage(Message msg)发送消息,则回调复写的handleMessage(msg)
3.创建消息对象
一般创建消息调用的是Message.obtain()方法:
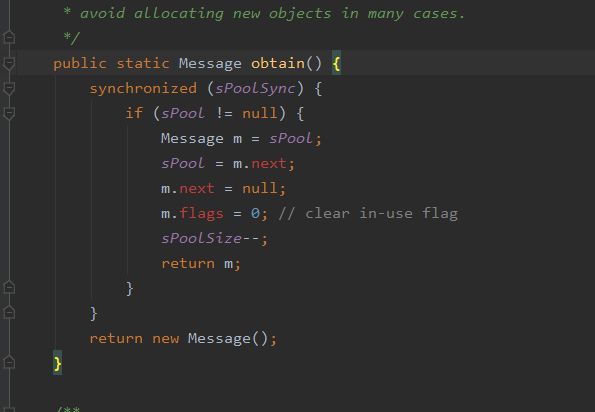
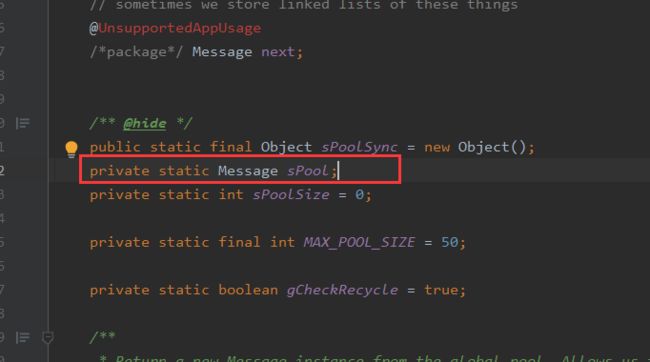
Message内部为了1个Message池,用于Message消息对象的复用。使用obtain就是从池中获取。(说是池,但是这个sPool就是一个静态的Message对象)
4.发送消息
发送消息调用的sendMessage方法

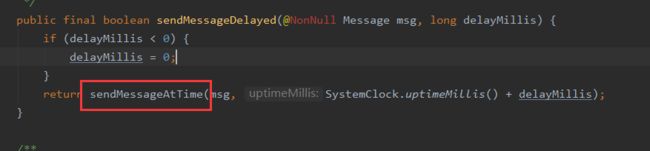
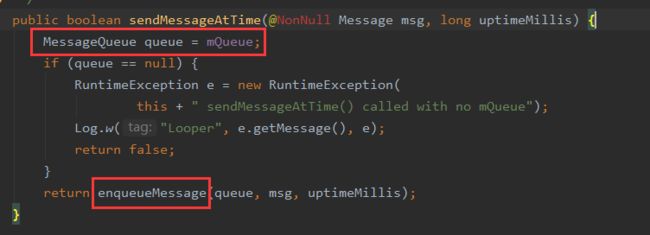
最终会拿到当前Handler的消息队列和Message调用Handler的#enqueueMessage方法
在此方法中会将msg.target复制为this,之前说的Looper的#loop方法会通过MessageQueue的next方法后调用msg.target.dispatchMessage(msg)去处理消息,实际上就是将该消息发送对应,也就是当前的Handler实例
接着就是调用消息队列的enqueueMessage方法:


将Message根据时间放入到消息队列中。MessageQueue采用单链表实现,提高插入消息、删除消息的效率。会判断消息队列中有无消息,若无,则将当前插入的消息作为队头,若有消息,则根据消息创建的事件插入到队列中。(单链表的实现就是Message中持有一个Message类型的mMessages对象,通过指定此对象的next对象来实现单链表)
5.Handler#post(runnable)


在#post方法中会调用getPostMessage方法,其中会通过Message.obtain方法获取Message,并指定msg的callback为传入的runnable对象。
在Looper#loop方法取出消息调用Handler的#dispatchMessage将消息发送给当前Handler:
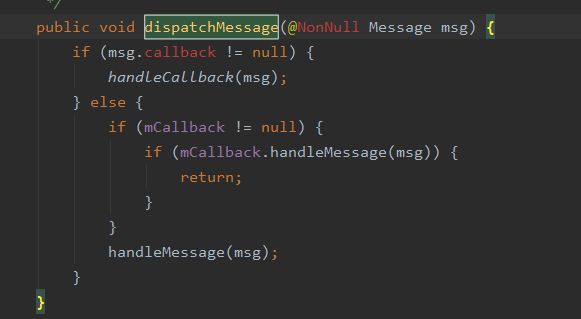
此方法中会判断msg.callback是否为空,如果不为空调用handleCallback方法,否则调用handleMessage方法。
在#handleCallback中就是调用callback的run方法,执行传入的Runnable#run里的逻辑

子线程直接创建Handler会抛出异常,原因就是:
主线程默认执行了looper.prepare方法,此时使用Handler就可以往相信队列中不断进行发送消息和取出消息处理(#loop),反之没有执行looper.prepare方法,就会抛出异常,这个在源码中有所体现。
6.Looper中的死循环为什么没有阻塞主线程?
解析的很清楚
主线程的死循环一直运行是不是特别消耗CPU资源呢? 其实不然,这里就涉及到Linux pipe/epoll机制,简单说就是在主线程的MessageQueue没有消息时,便阻塞在loop的queue.next()中的nativePollOnce()方法里,详情见Android消息机制1-Handler(Java层),此时主线程会释放CPU资源进入休眠状态,直到下个消息到达或者有事务发生,通过往pipe管道写端写入数据来唤醒主线程工作。这里采用的epoll机制,是一种IO多路复用机制,可以同时监控多个描述符,当某个描述符就绪(读或写就绪),则立刻通知相应程序进行读或写操作,本质同步I/O,即读写是阻塞的。 所以说,主线程大多数时候都是处于休眠状态,并不会消耗大量CPU资源。
7.【Handler延迟消息】
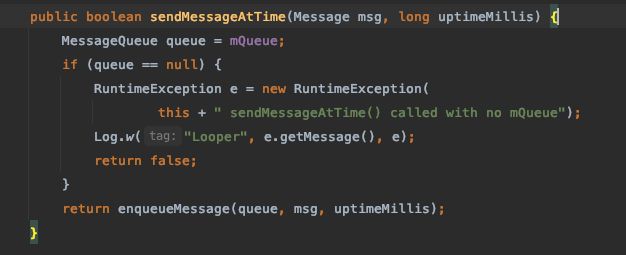
最终会调用Handler#enqueueMessage将消息存入消息队列中。这个延迟时间,也就是消息真正要发送的时间会作为消息的属性存入到Message的when字段中。
在Looper#loop方法中循环取数据的时候,会调用MessageQueue#next方法获取下一条消息,next中也是一个死循环获取消息:

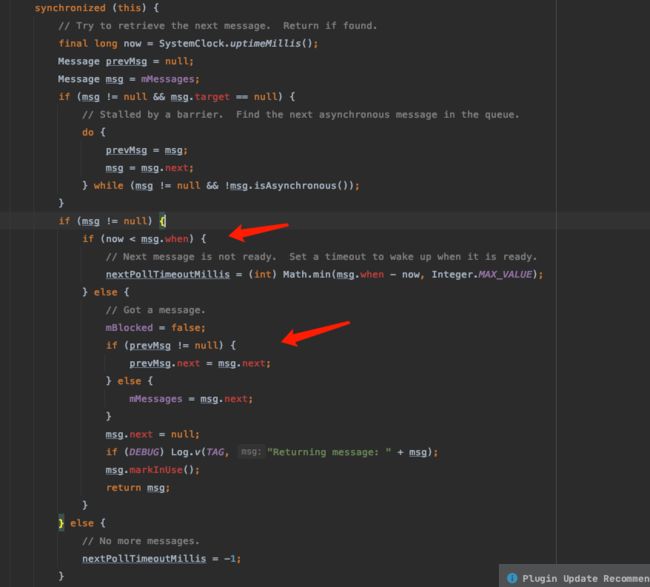
判断当前时间是否到达消息的执行时间,如果没有到,则调用nativePollOnce这个native方法进行阻塞。直到时间到了消息的执行时间,才将消息返回。
而唤醒则是在消息真正执行的地方,也就是MessageQueue#enqueueMessage方法中调用nativeWake唤醒。没有消息的时候就阻塞。

8.【IdleHandler】
IdleHandler介绍
IdleHandler,它可以在主线程空闲时执行任务,而不影响其他任务的执行。
使用起来很简单:
Looper.myQueue().addIdleHandler(new MessageQueue.IdleHandler() {
@Override
public boolean queueIdle() {
//此处添加处理任务
return false;
}
});
使用场景
寻找其合适的使用场景可以从如下几点出发:
在主线程中干的事、与消息队列有关、根据返回值不同做不同的处理
①Activity启动优化:
onCreate/onStart/onResume中耗时较短但非必要的代码可以放到IdleHandler中执行,减少启动时间
②可以替换View.post()
③发生一个返回true的IdleHandler,在里面让某个View不停闪烁,这样当用户发呆时就可以诱导用户点击这个View(实际上就是需要在主线程闲置时做些处理的场景都可以用这个来做)
IdleHandler源码解析
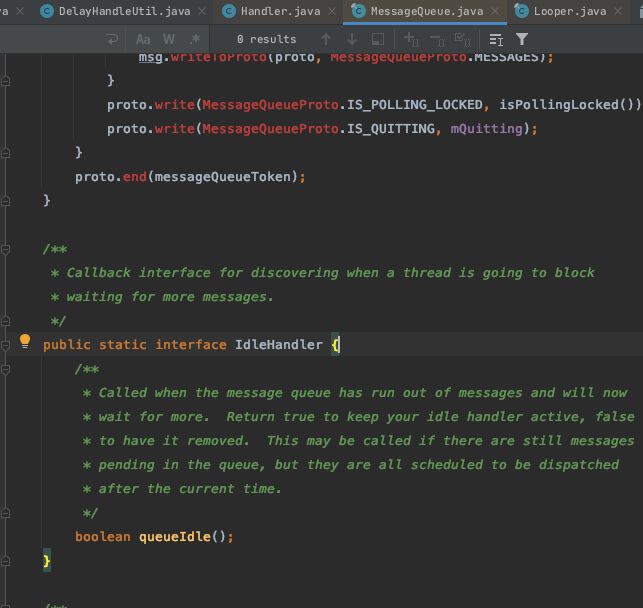
可以看到IdleHandler是声明在MessageQueue的一个静态接口,只有一个方法:
queueIdle(),返回值为true的时候,表示IdleHandler存活;返回值为false的时候,则会直接直接移除掉IdleHandler,不需要我们手动移除。
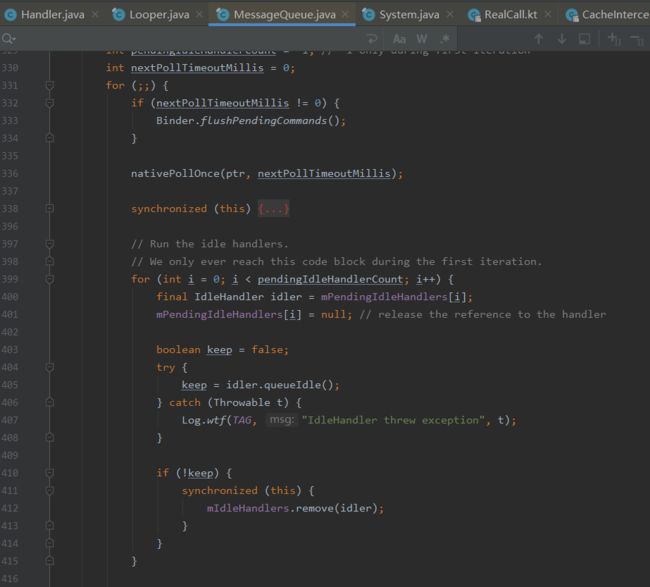
其调用处理就在MessageQueue#next方法中,当没有消息的时候,会遍历mPendingIdleHandlers列表,调用IdleHandler的#queueIdle方法,同时执行完获取#queueIdle的返回值,如果为false,则从mIdleHandlers移除掉,这也就是为什么我们不需要手动移除掉IdleHandler,只需要在#queueIdle中返回false即可。

这里的mIdleHandlers和mPendingIdleHandlers,实际上是同一个,只是中间将这个列表转成数组处理了。

9.MessageQueue没有消息时候会怎样?阻塞之后怎么唤醒呢?说说pipe/epoll机制?
当消息不可用或者没有消息的时候就会阻塞在next方法,而阻塞的办法是通过pipe/epoll机制
epoll机制是一种IO多路复用的机制,具体逻辑就是一个进程可以监视多个描述符,当某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作,这个读写操作是阻塞的。在Android中,会创建一个Linux管道(Pipe)来处理阻塞和唤醒。
当消息队列为空,管道的读端等待管道中有新内容可读,就会通过epoll机制进入阻塞状态。
当有消息要处理,就会通过管道的写端写入内容,唤醒主线程。
10.同步屏障和异步消息是怎么实现的?
其实在Handler机制中,有三种消息类型:
①同步消息。也就是普通的消息。
②异步消息。通过setAsynchronous(true)设置的消息。
③同步屏障消息。通过postSyncBarrier方法添加的消息,特点是target为空,也就是没有对应的handler。
这三者之间的关系如何呢?
正常情况下,同步消息和异步消息都是正常被处理,也就是根据时间when来取消息,处理消息。
当遇到同步屏障消息的时候,就开始从消息队列里面去找异步消息,找到了再根据时间决定阻塞还是返回消息。
也就是说同步屏障消息不会被返回,他只是一个标志,一个工具,遇到它就代表要去先行处理异步消息了。
所以同步屏障和异步消息的存在的意义就在于有些消息需要“加急处理”
11.同步屏障使用场景
View刷新流程里,ViewRootImpl的scheduleTraversals里的postSyncBarriar
12.【Message是如何复用的?】
在Looper#loop方法中取出消息后,调用了Message#recycleUnchecked
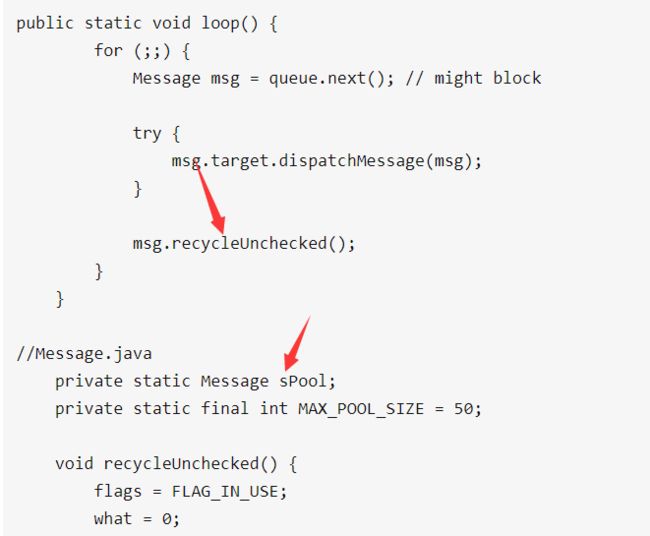
在recycleUnchecked方法中,释放了所有资源,然后将当前的空消息插入到sPool表头。
这里的sPool就是一个消息对象池,它也是一个链表结构的消息,最大长度为50。
然后在Message#obtain方法中,复用消息对象池里的第一个消息对象。
直接复用消息池sPool中的第一条消息,然后sPool指向下一个节点,消息池数量减一。

13.可以多次创建Looper吗?
当然不可以,在Looper#prepare方法中加了判断,如果当前线程已经创建了looper直接抛出异常:

14.Looper中的quitAllowed字段是啥?有什么用?
是否退出消息循环
Looper#quit方法用到了,如果这个字段为false,代表不允许退出,就会报错。
那么这个quit方法一般是什么时候使用呢?
主线程中,一般情况下肯定不能退出,因为退出后主线程就停止了。所以是当APP需要退出的时候,就会调用quit方法,涉及到的消息是EXIT_APPLICATION,大家可以搜索下。
子线程中,如果消息都处理完了,就需要调用quit方法停止消息循环。
15.Message是怎么找到它所属的Handler然后进行分发的?
在loop方法中,找到要处理的Message,然后调用了这么一句代码处理消息:
在使用Hanlder发送消息的时候,会设置msg.target = this,所以target就是当初把消息加到消息队列的那个Handler。
16.Handler 的 post(Runnable) 与 sendMessage 有什么区别
Hanlder中主要的发送消息可以分为两种:
post(Runnable)
sendMessage
其实post和sendMessage的区别就在于:
post方法给Message设置了一个callback
在dispatchMessage的时候:

如果msg.callback不为空,也就是通过post方法发送消息的时候,会把消息交给这个msg.callback进行处理,然后就没有后续了。
如果msg.callback为空,也就是通过sendMessage发送消息的时候,会判断Handler当前的mCallback是否为空,如果不为空就交给Handler.Callback.handleMessage处理。
如果mCallback.handleMessage返回true,则无后续了。
如果mCallback.handleMessage返回false,则调用handler类重写的handleMessage方法。
所以post(Runnable) 与 sendMessage的区别就在于后续消息的处理方式,是交给msg.callback还是 Handler.Callback或者Handler.handleMessage
17.Handler.Callback.handleMessage 和 Handler.handleMessage 有什么不一样?为什么这么设计?
根本在于Handler的两种创建方式:

常用的方法就是第1种,派生一个Handler的子类并重写handleMessage方法。而第2种就是系统给我们提供了一种不需要派生子类的使用方法,只需要传入一个Callback即可。
View绘制流程
TODO
Android UI刷新机制
github解答
参考文章
刷新本质流程
通过ViewRootImpl的scheduleTraversals()进行界面的三大流程。
调用到scheduleTraversals()时不会立即执行,而是将该操作保存到待执行队列中。并注册监听底层的刷新信号。
当VSYNC信号到来时,会从待执行队列中取出对应的scheduleTraversals()操作,并将其加入到主线程的消息队列中。
主线程从消息队列中取出并执行三大流程: onMeasure()-onLayout()-onDraw()
同步屏障的作用
同步屏障用于阻塞住所有的同步消息(底层VSYNC的回调onVsync方法提交的消息是异步消息)
用于保证界面刷新功能的performTraversals()的优先执行。
同步屏障的原理?
主线程的Looper会一直循环调用MessageQueue的next方法并且取出队列头部的Message执行,遇到同步屏障(一种特殊消息)后会去寻找异步消息执行。如果没有找到异步消息就会一直阻塞下去,除非将同步屏障取出,否则永远不会执行同步消息。
界面刷新操作是异步消息,具有最高优先级
我们发送的消息是同步消息,再多耗时操作也不会影响UI的刷新操作
流程详解
在Android端,是谁在控制 Vsync 的产生?又是谁来通知我们应用进行刷新的呢? 在Android中, Vysnc 信号的产生是由底层 HWComposer 负责的,SurfaceFlinger 服务把 VSync 信号通知到应用进行刷新,刷新处理是在Java层的 Choreographer ,Android整个屏幕刷新的核心就在于这个 Choreographer
【具体流程】
当我们进行UI重绘的时候,都会调用ViewRootImpl#requestLayout
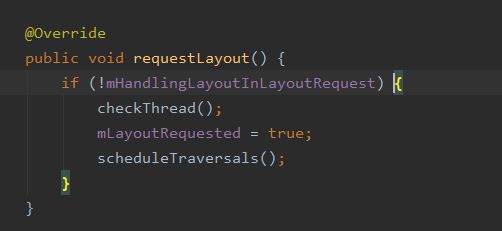
requestLayout中又会调用scheduleTraversals()

可以看到这里这里并没有立即进行重绘,而是做了两件事:
①往消息队列中插入了一条SyncBarrier(同步屏障)
②通过Cherographer post了一个callback
这里的SyncBarrier,也就是同步屏障作用:
①阻止同步消息的执行
②优先执行异步消息
为什么设计这个同步屏障呢?
主要原因在于提高消息的优先级,保证消息能高优先级执行。
之所以没有在Message中加一个优先级的变量,链接中也指出,可能是因为在Android中MessageQueue是一个单链表,整个链表的排序是根据时间进行排序的。如果再加入一个优先级的排序规则,一方面会是排序规则更为复杂,另一方面也会使消息不可控。
小问题:如果在一个方法中连续调用了requestLayout多次,系统会插入多条内存屏障或者post多个callback吗?
答案是不会,因为在执行scheduleTraversals前会判断mTraversalScheduled是否为true。
看一下Choreographer:
主要作用就是进行系统协调,通过ThreadLocal存储,每个线程都有一个Choreographer:

Choreographer post的callback会放入CallbackQueue里面,这个CallbackQueue也是一个单链表。
Choreographer的postCallback方法会调用scheduleFrameLocked方法:
里面会调用scheduleVsyncLocked()方法:

内部会调用注册VSYNC信号监听:每次调用requestLayout都会主动调用DisplayEventReceiver的scheduleVsync方法,DisplayEventReceiver的作用就是注册Vsync信号的监听,当下个Vsync信号到来的时候就会通知DisplayEventReceiver。
接收VSYNC信号的地方在FrameDisplayEventReceiver中的onVsync方法,这个类继承自DisplayEventReceiver实现了Runnable接口,接收消息后会执行run方法里的#doFrame()方法:

doFrame中主要进行了两部分处理:
①判断处理一帧的时长,打印:
The application may be doing too much work on its main thread
②从CallbackQueue中取出到执行时间的callback进行处理**
这个callback实际上就是TraversalRunnable,也就是我们ViewRootImpl#scheduleTraversals中postCallback传入的mTraversalRunnable

TraversalRunnable中会调用doTraversal

doTraversal中会移除同步屏障,执行#performTraversals
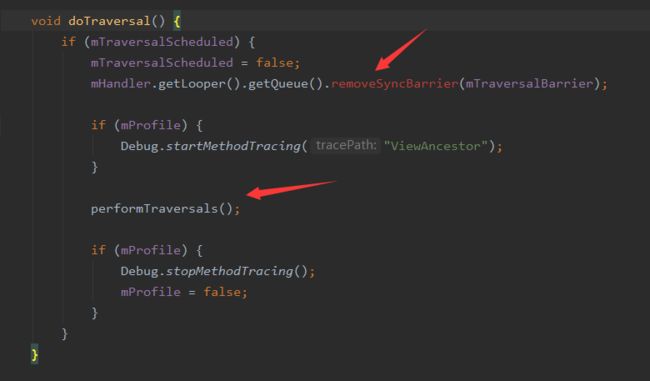

performTraversals中处理了大量的逻辑后(是我看源码中最长的方法,800多行),会调用#performDraw开始进行真正的界面绘制。performDraw中会调用draw方法,而draw方法绘制完毕会调用View的mTreeObserver.dispatchOnDraw回调给View树中的onDraw方法。

与UI刷新相关的问题
①我们都知道Android的刷新频率是60帧/秒,这是不是意味着每隔16ms就会调用一次onDraw方法?
这里60帧/秒是屏幕刷新频率,但是是否会调用onDraw()方法要看应用是否调用requestLayout()进行注册监听
②如果界面不需要重绘,那么16ms到后还会刷新屏幕吗?
如果不需要重绘,那么应用就不会收到Vsync信号,但是还是会进行刷新,只不过绘制的数据不变而已;
③我们调用invalidate()之后会马上进行屏幕刷新吗?
不会,到等到下一个Vsync信号到来
④我们说丢帧是因为主线程做了耗时操作,为什么主线程做了耗时操作就会引起丢帧?
原因是,如果在主线程做了耗时操作,就会影响下一帧的绘制,导致界面无法在这个Vsync时间进行刷新,导致丢帧了。
⑤如果在屏幕快要刷新的时候才去OnDraw()绘制,会丢帧吗?
这个没有太大关系,因为Vsync信号是周期的,我们什么时候发起onDraw()不会影响界面刷新;
requestLayout和invalidate的区别:
requestLayout会直接递归调用父窗口的requestLayout,直到ViewRootImpl,然后触发peformTraversals,由于mLayoutRequested为true,会导致onMeasure和onLayout被调用,不一定会触发OnDraw。requestLayout触发onDraw可能是因为在在layout过程中发现l,t,r,b和以前不一样,那就会触发一次invalidate,所以触发了onDraw,也可能是因为别的原因导致mDirty非空(比如在跑动画)
view的invalidate不会导致ViewRootImpl的invalidate被调用,而是递归调用父view的invalidateChildInParent,直到ViewRootImpl的invalidateChildInParent,然后触发peformTraversals,会导致当前view被重绘,由于mLayoutRequested为false,不会导致onMeasure和onLayout被调用,而OnDraw会被调用
BlockCanary
BlockCanary原理解析
BlockCanary源码解析
我们先看一下原理,BlockCanary的原理很简单:
在Android中,应用的卡顿主要是主线程阻塞导致的。Looper是主线程的消息调度点。
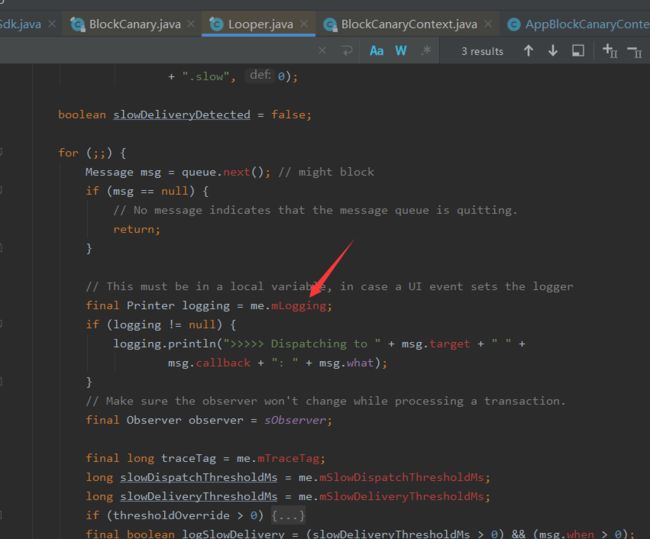
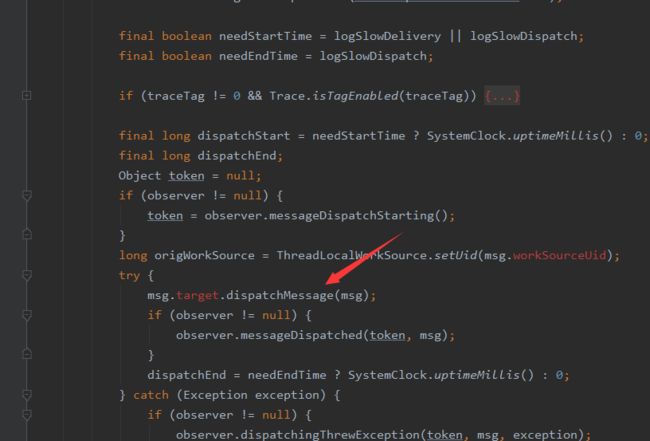
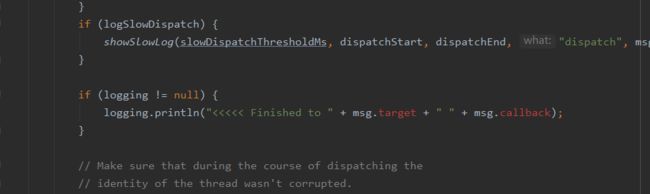
就是在Looper#loop方法中,在msg.target.dispatchMessage方法前后会调用Printer输出日志,判断dispatchMessage方法的耗时。我们可以传入自定义的Printer,置定一个阈值,如果超过这个时间就可以判断为主线程阻塞了。
这个Printer可以通过Looper的#setMessagLoggging传入。MainLooper里默认是没有Printer的。可以在ActivityThread的#main方法中看到:


参考第一篇博客,我们就可以自己定义一个Printer,通过Looper.getMainLooper().setMessageLogging(printer)方法传入我们的printer,判断每个方法的耗时情况。
BlockCanary原理图解:

源码分析:
BlockCanary初始化代码就一句:
BlockCanary.install(context, new AppBlockCanaryContext()).start();
传入Application的Context以及BlockCanaryContext,其中BlockCanaryContext可以配置BlockCanary的各种自定义配置参数,比如耗时阈值、日志保存目录、是否展示通知等。
install流程

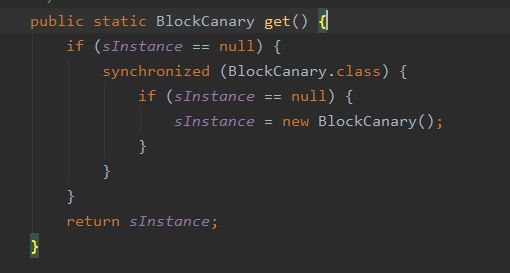
通过DCL创建BlockCanary单例。

在BlockCanary的构造方法中,创建了核心处理类:BlockCanaryInternals,其创建也是一个DCL单例。创建了BlockCanaryInternals后,会将BlockCanaryContext加到其责任链中。如何开启展示前台通知的开关,DisplayService也会被加到责任链中。
看一下BlockCanaryInternals:

在BlockCanaryInternals中有条责任链mInterceptors负责处理相关流程。
三个参数:
StackSampler:表示线程堆栈采样
CpuSampler:表示Cpu相关数据采样
LooperMonitor:其中的#onBlockEvent函数会在发生Block的时候,输出相关log
在BlockCanaryInternals的构造方法中,会调用setMonitor方法,监听#onBlcokEven回调,监听到block事件后,构造BlockInfo也就是阻塞信息,然后交给责任链处理。实际上这个责任链上只有BlockCanaryContext和DisplayService....ORZ:


start流程

start流程就是调用Looper.getMainLooper().setMessageLogging()方法传入自定义的日志输出类LooperMonitor。
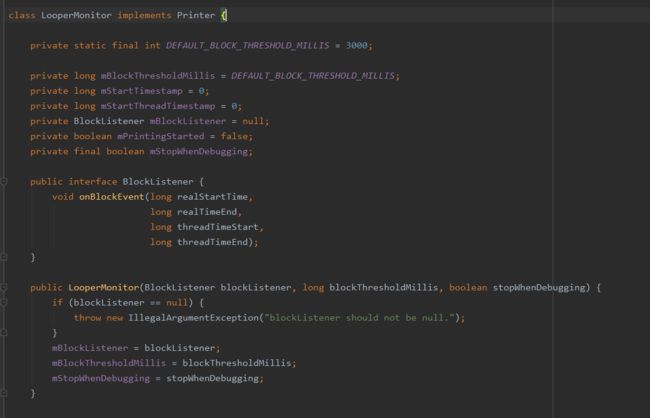

重写了Printer的println方法:
①在dispatchMessage前执行一次println方法,记录开始时间并调用startDump方法
②在dispatchMessage后再执行一次println方法,并对比执行时间
对比的逻辑十分简单,结束时间减去开始时间大于预先设置的阀值,即可理解发生block,这时调用notifyBlockEvent,将发生block的时间信息回传给BlockCanaryInternals。就回到上面的逻辑,构造BlockInfo交给责任链处理。
简要概括:
1.自定义一个Looper的MessageLogging设置给主线程的Looper
2.在Looper.loop的dispatchMessage方法前打印线程和CPU的堆栈信息
3.在Looper.loop的dispatchMessage方法后判断是否发生block
4.发生block时调用DisplayService创建NotificationManager消息通过
5.点击NotificationManager窗口跳转到DisplayActivity,并展示发生block时的线程堆栈以及CPU堆栈
Rxjava消息订阅和线程切换
Rxjava消息订阅和线程切换
Rxjava消息订阅
1.简单使用:
①创建被观察者Observable,定义要发送的事件
②创建观察者Observer,接收事件并作出响应操作
③观察者通过订阅(subscribe)被观察者把它们连接到一起
demo:
private void create() {
//上游
Observable.create((ObservableOnSubscribe) emitter -> {
emitter.onNext("1---秦时明月");
emitter.onNext("2---空山鸟语");
emitter.onNext("3---天行九歌");
emitter.onComplete();
stringBuffer.append("发送数据:" + "\n"
+ "1---秦时明月" + "\n" + "2---空山鸟语" + "\n" + "3---天行九歌" + "\n"
);
Log.i(TAG, "subscribe: .....");
}).subscribeOn(Schedulers.newThread())
.observeOn(AndroidSchedulers.mainThread())
.subscribe(new Observer() {//通过subscribe连接下游
private Disposable mDisposable;
private int i = 0;//计数器
@Override
public void onSubscribe(Disposable d) {
Log.i(TAG, "onSubscribe: ");
mDisposable = d;
}
@Override
public void onNext(String s) {
Log.i(TAG, "onNext: ");
if (i == 0) {
stringBuffer.append("接收到的数据:" + "\n");
}
stringBuffer.append(s + "\n");
i++;//第几个事件
if (i == 2) {
setResult();
mDisposable.dispose();//阻断,dls上线!
}
}
@Override
public void onError(Throwable e) {
}
@Override
public void onComplete() {
//走不到,被上面的拦截了
Log.i(TAG, "onComplete: " + stringBuffer);
}
});
}
消息订阅源码分析:①创建被观察者 ②订阅过程
①创建被观察者Observable
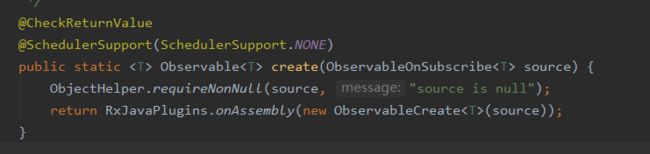
创建了一个ObservableCreate并将我们自定义的ObservableOnSubscribe作为参数传到ObservableCreate中去。然后调用RxJavaPlugins.onAssembly方法。
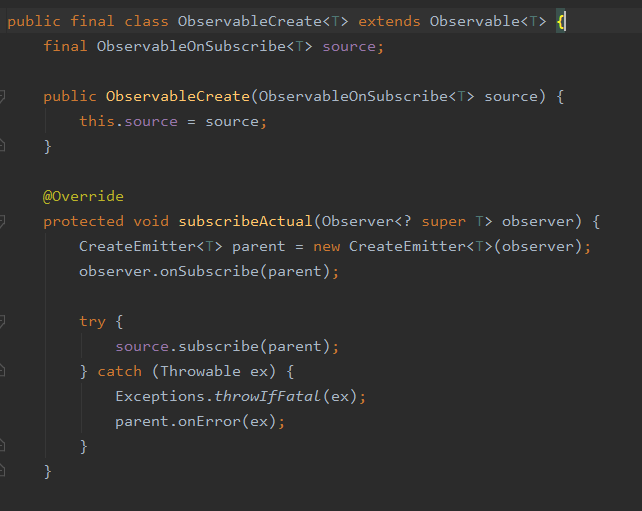
ObservableCreate继承自Observalbe,并且会将我们的ObservalbeOnSubscribe作为source变量存储起来。
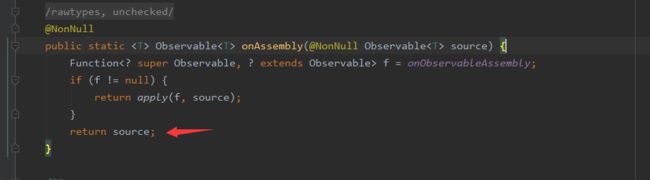
onAssembly会将我们创建的ObservableCreate给返回。
创建过程简单总结
Observable.create()中就是把我们自定义的ObservableOnSubscribe对象重新包装到ObservableCreate对象,然后返回这个ObservableCreate对象。
②订阅流程
订阅流程也就是Observable.subscribe()

其核心就在于这两句:
observer = RxJavaPlugins.onSubscribe(this, observer);
subscribeActual(observer);
RxJavaPlugins.onSubscribe将observer返回。
订阅流程的实现就在#subscribeActual方法中:

subscribeActual是一个抽象方法,其实现就在我们刚才创建的ObservableCreate中:

subscribeActual方法中会创建一个CreateEmitter对象,将我们自己定义的Observer作为参数传递进来,实际上就是CreateEmitter会包装一下observer
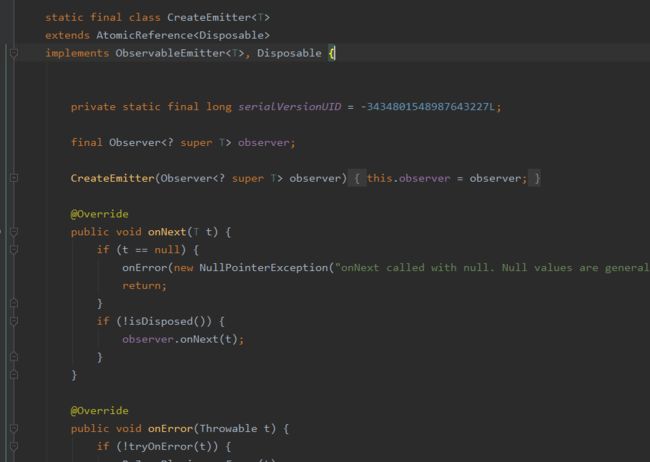
这个CreateEmitter是ObservableCreate的一个静态内部类,其主要作用就是对事件进行拦截、observer的事件回调等。
接着回到subscribeActual中,会调用observer的#onSubscribe方法:
也就是通知观察者已经成功订阅了被观察者
接着subscribeActual方法中会继续调用source.subscribe方法,这里的source就是我们自定义的ObservableOnSubscribe对象。
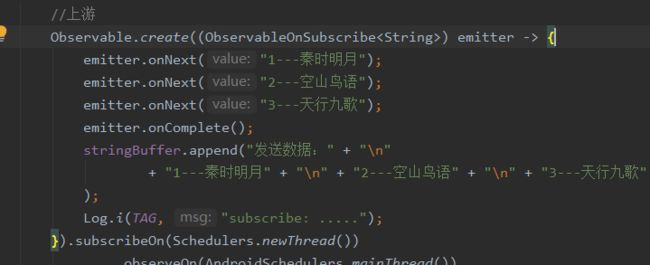
在我们自定义的ObservableOnSubscribe的#subscribe方法中,我们会通过ObservableEmitter一次调用onNext和onComplete方法,这里的ObservalbeEmitter接口具体实现为CreateEmitter:
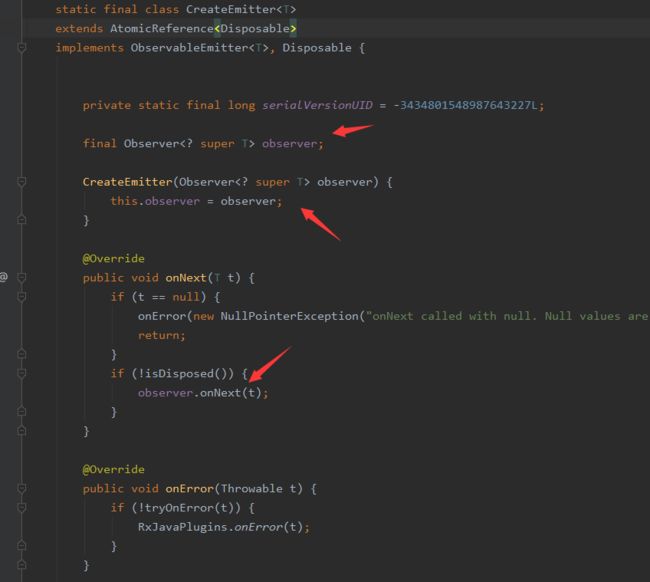
在CreateEmitter的onNext、onComplete方法中会调用我们subscribe传入的自定义的Observer的onNext、onComplete方法。这样一个完整的消息订阅流程就完成了。在发送事件前都会调用isDisposed来判断是否拦截事件,这个拦截机制我们下面分析。
订阅流程简单总结
Observable(被观察者)和Observer(观察者)建立连接(订阅)之后,会创建出一个发射器CreateEmitter,发射器会把被观察者中产生的事件发送到观察者中去,观察者对发射器中发出的事件做出响应处理。可以看到,是订阅之后,Observable(被观察者)才会开始发送事件
切断流程分析

切换上层实现就是调用onSubsribe中传递进来的Disposable的dispose方法,拦截掉事件。
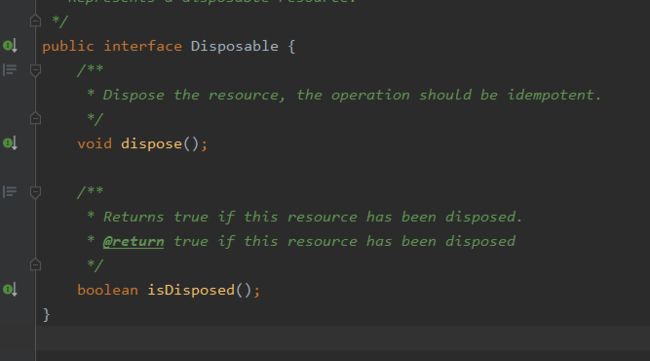
Disposable是一个接口,只有两个方法dispose和isDisposed。具体实现是在CreateEmitter中(CreateEmitter中实现了Disposable接口)
就是调用DisposableHelper.dispose(this)。
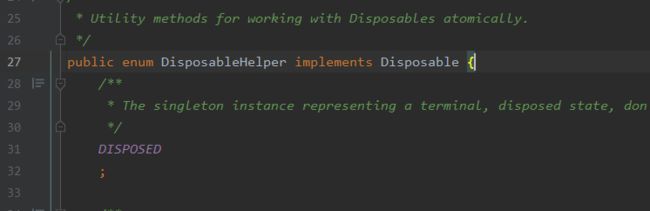
DisposableHelper是一个枚举类,并且只有一个值DISPOSED,dispose()方法中会将这个原子引用field设为DISPOSED,即标记为中断状态,后面就可以通过isDisposed方法判断连接器是否被中断,也就是是否会中断事件分发。
CreateEmitter类中的onNext、onComplete前都会调用isDisposed来决定是否中断事件。
如果没有dispose,observer.onNext()才会被调用到。
onError()和onComplete()互斥,只能其中一个被调用到,因为调用了他们的任意一个之后都会调用dispose()。
先onError()后onComplete(),onComplete()不会被调用到。反过来,则会崩溃,因为onError()中抛出了异常:RxJavaPlugins.onError(t)。实际上是dispose后继续调用onError()都会炸。
【Rxjava的线程切换】
线程切换操作就两步:
subscribeOn:指定上游线程
observerOn:指定下游线程

①Observer(观察者)的onSubscribe()方法运行在当前线程中。
②Observable(被观察者)中的subscribe()运行在subscribeOn()指定的线程中。
③Observer(观察者)的onNext()和onComplete()等方法运行在observeOn()指定的线程中。
线程切换的源码分析也就分为两部分:subsribeOn()和observerOn()
subscribeOn()
一般使用:
subscribeOn(Schedulers.newThread())
subscribeOn需要传入一个Scheduler类对象作为参数,Scheduler是一个调度类,能延时或者周期性地去执行一个任务。
Scheduler类型
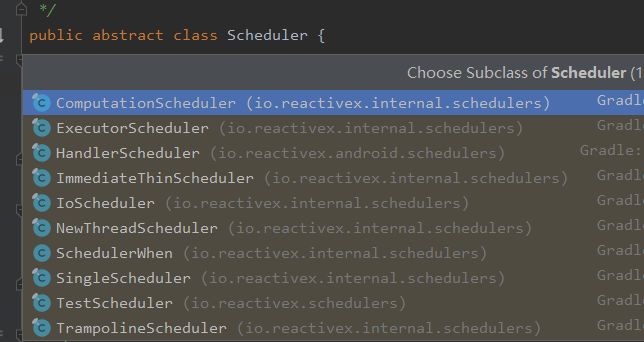
Scheduler是一个抽象类,有10个具体实现,其中常用的有:

IoScheduler、NewThreadScheduler、HandlerScheduler;
Schueduler这些子类的基本实现基本差不多,我们根据参考博文分析一下Schedulers.io():


在Schedulers的静态代码块中初始了IoScheduler,初始化的时候会创建一个IOTask。

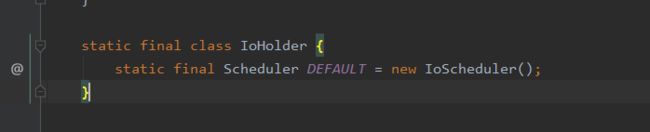
可以看到Schedulers.io()使用了静态内部类的方式来出创建了一个单例IoScheduler对象。
下面就可以看一下subscribeOn方法了:

调用RxJavaPlugins.onAssembly
首先会将当前的Observable具体实现为ObservableCreate包装成一个新的ObservableSubcribeOn对象,Observable中传入的是ObservalbeOnSubsribe:
RxJavaPlugins.onAssembly也是将ObservableSubscribeOn对象原样返回,看一下ObservableSubscribeOn的构造方法:
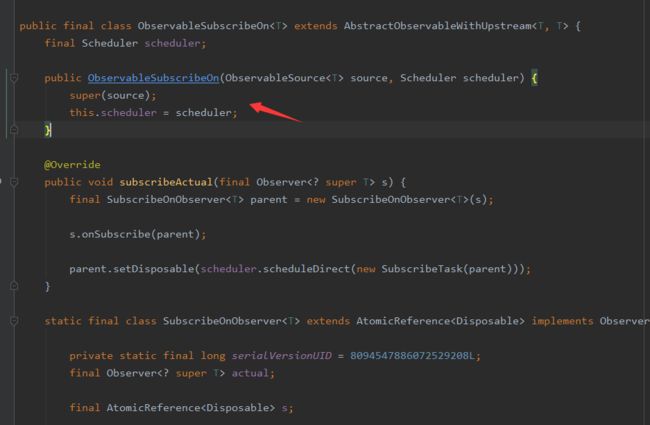
就是把source也就是我们的被观察者Observable以及scheduler保存一下。
subscribeOn就是将我们的Observable以及Scheduler重新包装成ObservableSubscribeOn,然后返回。
【ObservableSubscribeOn#subscribeActual】
在之前的subscribe订阅流程汇总,具体实现是ObservableCreate类,但在调用subscribeOn之后,ObservableCreate对象被封装成了一个新的ObservableSubscribeOn对象了,subscribeActual的具体实现也就是在ObservableSubscribeOn中了:
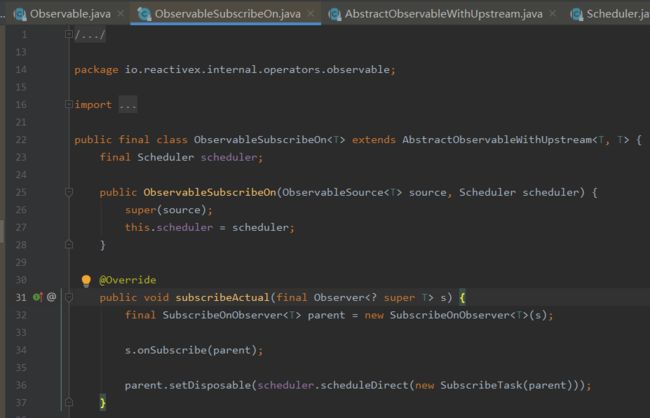
subscribeActual同样将我们自定义的Observer包装成一个新的SubscribeOnObserver对象:

然后调用Observer的onSubscribe方法,目前还没有任何线程切换,所以Observer的onSubscribe方法还是运行在当前线程中的。
最重要的还是subscribeActual最后一行代码:
parent.setDisposable(scheduler.scheduleDirect(new SubscribeTask(parent)));
首先创建一个SubscribeTask对象,然后调用scheduler.scheduleDirect().

此类是ObservableSubscribeOn的内部类,实现了Runnable接口,然后run中调用了Observer.subscribe
【Scheduler类的scheduleDirect:线程切换的真正逻辑所在】

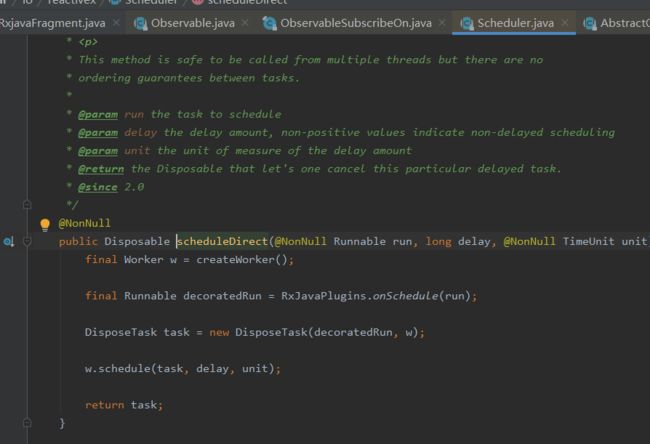
#scheduleDirect中就是在当前线程调用createWorker创建了一个Worker,Worker中可以执行Runnable;然后将Runnable和Workder包装成一个DisposeTask,然后通过Worker#schedule执行这个task。
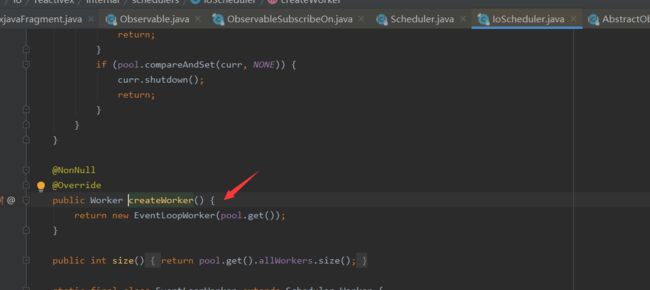

在IoScheduler的createWorker方法中就是new一个EventLoopWorker,并且传一个Worker缓存池进去。不同的Scheduler的createWork中会创建不同类型的Worker,这点需要注意。
在EventLoopWorker的构造方法中会从缓存Worker池中取一个Worker出来,然后将Runnable交给这个threadWorkder的#scheduleActual去执行。
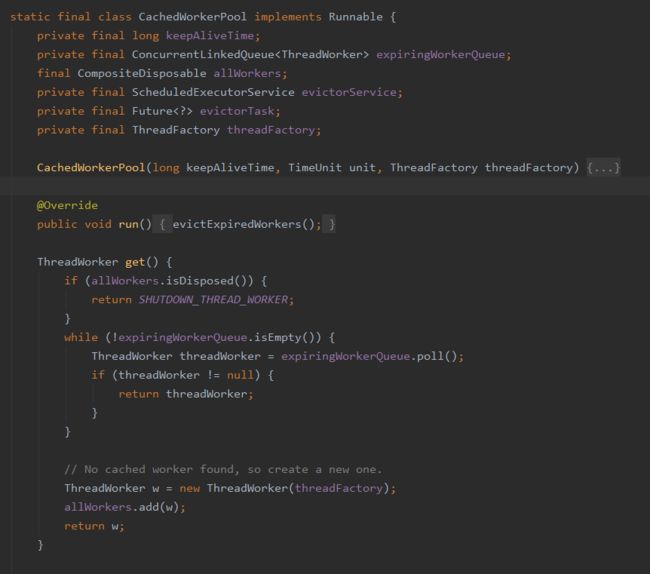
Worker的缓冲池对象是CachedWorkPool,其内部的ConcurrentLinkedQueue列表缓存了ThreadWorker。其#get方法中会判断如果缓冲池不为空,则从缓冲池中取threadWorker,如果缓冲池为空,就创建一个ThreadWorker并返回。
接下来就看一下ThreadWorker的#scheduleActual()里的具体实现了:



在NewThreadWorker的构造方法中会创建一个ScheduledExecutorService对象,通过ScheduledExecutorService来使用线程池。
在其#sceduleActual中,会将runnable对象包装成一个新对象ScheduledRunnable
由是否延迟决定是调用sumbit还是schedule去执行runnable,最终SubscribeTask的run方法就会在线程池中执行,即Observable的subscribe方法会在IO线程执行。
简单总结:
Observer(观察者)的onSubscribe()方法运行在当前线程中,因为在这之前都没涉及到线程切换。
如果设置了subscribeOn(指定线程),那么Observable(被观察者)中subscribe()方法将会运行在这个指定线程中去。
多次设置subscribeOn的问题
如果多次设置subscribeOn,只有第一次有作用,其原因如下:
每调用一次subscribeOn就会被旧的被观察者也就是ObservableCreate包装成一个新的被观察者也就是ObservableSubscribeOn,如果调用三次,包装就会变成如下样式:
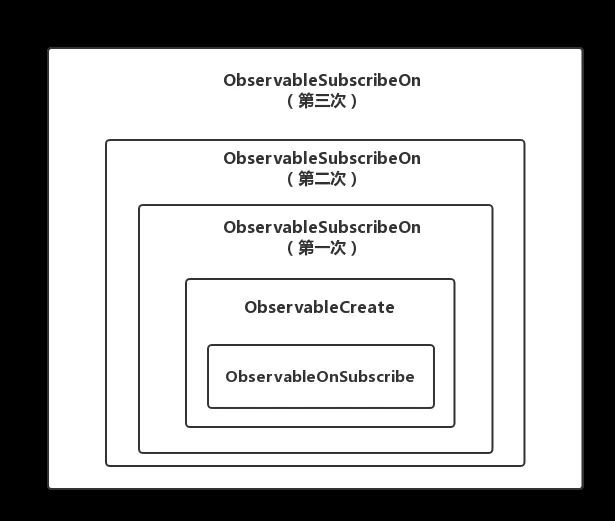
由底层向上层一层一层通知,到了第一层ObservableSubscribeOn的时候(也就是第一次调用subscribeOn)都会把线程切到IO线程中执行,后面也就不会在切其他线程了。
observeOn()
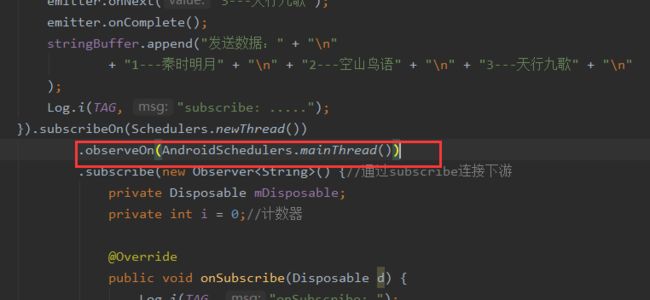
将Observer新包装成一个ObservableObserveOn对象,这里被包装的旧的被观察者是ObservableSubscribeOn对象(也就是subscribeOn时的包装)
此时包装逻辑如下:

和subscribeOn逻辑类似,线程切换的逻辑主要在ObservableObserverOn(构造方式中只有一些赋值操作)当中的subscribeActual中
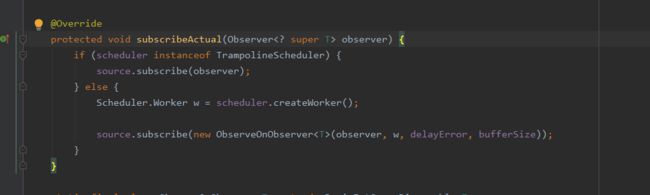
subscribeActual方法中首先会判断是否是当前新城,如果是当前线程的话,直接调用里面一层的subscribe方法;如果不是当前线程,就调用Scheduler的createWorker方法创建一个Worker,然后将Worker和ObservableObserverOn包装成ObserverOnObserver,调用source也就是上游的IO线程中的ObservableSubscribeOn的subscribe方法将事件逐一发送,此时包装为:

ObserverOnObserver是ObservableObserverOn的一个静态内部类:
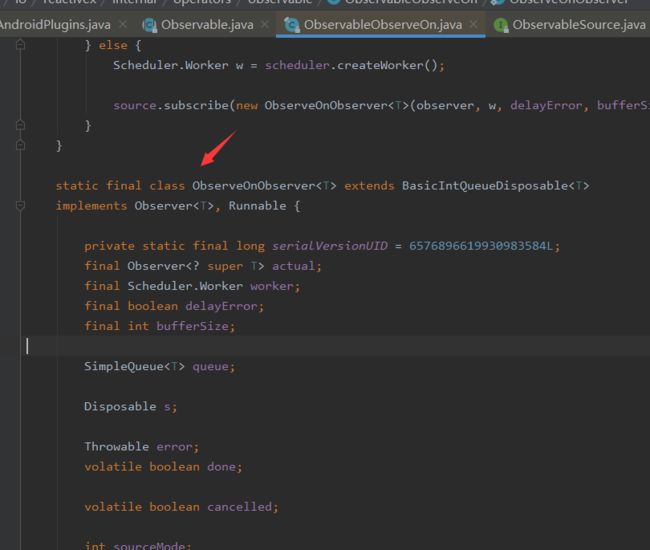
ObserverOnObserver的onNext()、onComplete处理逻辑差不多,我们主要看一下onNext:
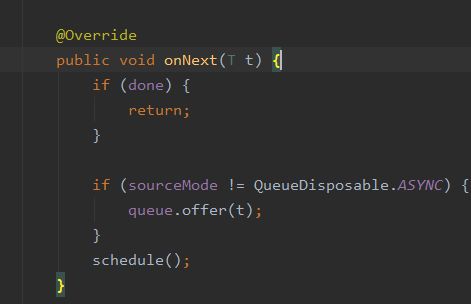
onNext中首先通过CAS操作保持并发的安全性,然后调用workder的#schedule方法,因为我们上面用的是Schedulers.mainThread(),其实现就是HandlerThread
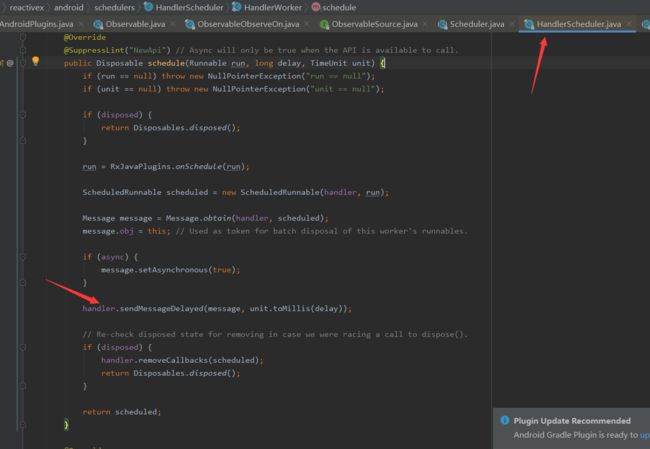
HandlerScheduler的scedule中就是通过Handler来发送Message来讲消息从IO线程发送到主线程中。最终还是在主线程中调用ObserverOnObserver的run方法
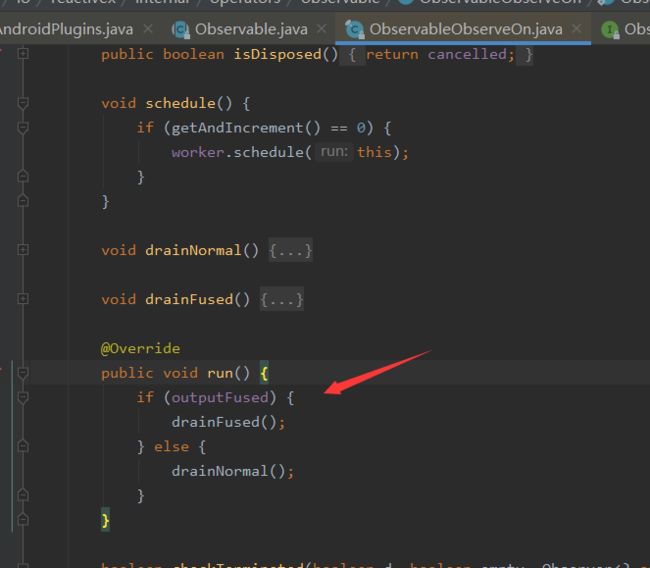
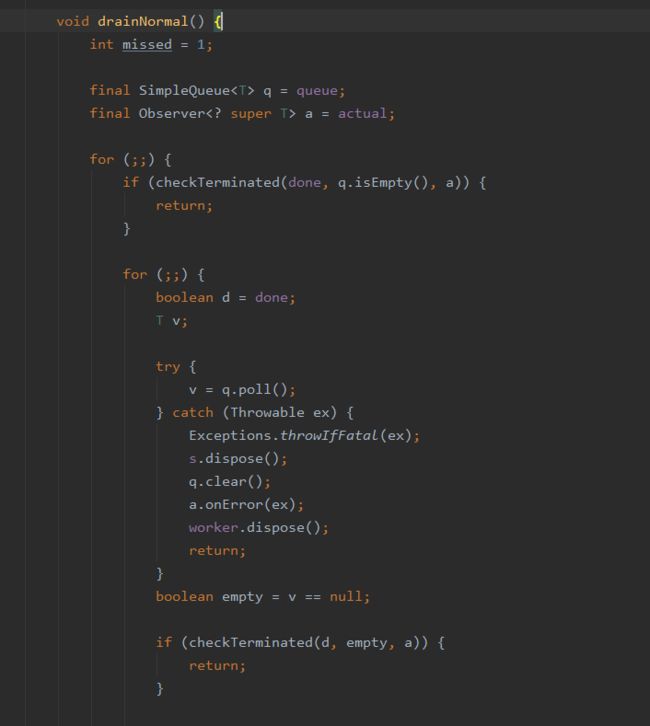
会调用drainNormal方法(当前已经运行在主线程中了),方法内部会开启一个死循环,从队列中也就是SimpleQueue中一直取消息,然后调用Observer的onNext方法,也就是在observerOn中指定的线程中调用了,这里就是主线程。
【 Activity、Window、View三者关注】
参考