函数式编程是什么
函数式编程更加强调程序执行的结果而非执行的过程,倡导利用若干简单的执行单元让计算结果不断渐进,逐层推导复杂的运算,而不是设计一个复杂的执行过程。 -- wiki
例子一 累加运算
// sum
List nums = Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 10);
public static Integer sum(List nums) {
int result = 0;
for (Integer num : nums) {
result += num;
}
return result;
}
sum(nums); // -> 46
同样的代码用 Java8 Stream 实现
Arrays.asList(0, 1, 2, 3, 4, 5, 6, 7, 8, 10).stream().reduce(0, Integer::sum);
同样的代码用 Clojure 实现
(apply + [0 1 2 3 4 5 6 7 8 10]) ; -> 46
#_(reduce + [0 1 2 3 4 5 6 7 8 10])
例子二 fabonacci数列
// java
public static int fibonacci(int number) {
if (number == 1) {
return 1;
}
if(number == 2) {
return 2;
}
int a = 1;
int b = 2;
for(int cnt = 3; cnt <= number; cnt++) {
int c = a + b;
a = b;
b = c;
}
return b;
}
// java8
Stream.iterate(new int[]{1, 1}, s -> new int[]{s[1], s[0] + s[1]})
.limit(10)
.map(n -> n[1])
.collect(toList())
// -> [1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
// clojure
(->> (iterate (fn [[a b]] [b (+ a b)]) [1 1])
(map second)
(take 10))
; -> (1 2 3 5 8 13 21 34 55 89)
比起命令式的语言,函数式语言更加关注执行的结果,而非执行的过程。
函数式编程的历史
从Hilbert 23个数学难题谈起
1900年,Hilbert 提出了数学界悬而未决的10大问题,后续陆续添加成了23个问题,被称为著名的 Hilbert 23 Problem。针对其中第2个决定数学基础的问题——算术公理之相容性,年轻的哥德尔提出了哥德尔不完备定理,解决了这个问题形式化之后的前两点,即数学是完备的吗?数学是相容的吗?哥德尔用两条定理给出了否定的回答。
所谓不完备,即系统中存在一个为真,但是无法在系统中推导出来的命题。比如:U说:“U在PM中不可证”。虽然和说谎者很类似,但其实有明显的差异。我们可以假设U为可证,那么可以推出PM是矛盾(不相容)的;但是假设U不可证,却推导不出PM是矛盾的。U的含义是在PM中不可证,而事实上,它被证明不可证,所以U是PM中不可证的真命题。
基于第一条不完备定理,又可以推导出第二条定理。如果一个(强度足以证明基本算术公理的)公理系统可以用来证明它自身的相容性,那么它是不相容的。
而最后一个问题,数学是确定的吗?也就是说,存在一个算法判定一个给定的命题是否是不确定的吗(Entscheidungsproblem 判定性问题)?这个问题引起了阿隆佐·邱奇和年轻的阿兰·图灵的兴趣。
阿隆佐·邱奇的 lambda calculus 和图灵的图灵机构造出了可计算数,图灵的那篇论文 ON COMPUTABLE NUMBERS, WITH AN APPLICATION TO THE ENTSCHEIDUNGSPROBLEM 的意义不在于证明可计算数是否可数,而在于证明可判定性是否成立。在1936年他们对判定性问题分别独立给出了否定的答案。也就是现在被我们熟知的图灵停机问题:不存在这样一个程序(算法),它能够计算任何程序(算法)在给定输入上是否会结束(停机)。图灵借此发明了通用图灵机的概念,为后来的冯·诺依曼体系的计算机体系提供了理论基础。
Lambda Calculus

Lambda 表达式包含三个要素
- 变量
- lambda 抽象
- lambda 应用
据此我们可以用函数给出布尔值的定义
data BOOL = FALSE | TRUE
TRUE = λx.λy.x
FALSE = λx.λy.y
not = λb.b FALSE TRUE
and = λb1.λb2.b1 b2 FALSE
or = λb1.λb2.b1 TRUE b2
xor = λb1.λb2.b1 (not b2) b2
自然数的定义
data NAT = Z | S NAT
0 = λf.λs.s
1 = λf.λs.f s
2 = λf.λs.f f s
succ n = λf.λs.f (n f s)
zero? n = n (λb.FALSE) TRUE
add = succ n1 n2
函数式编程语言的发展
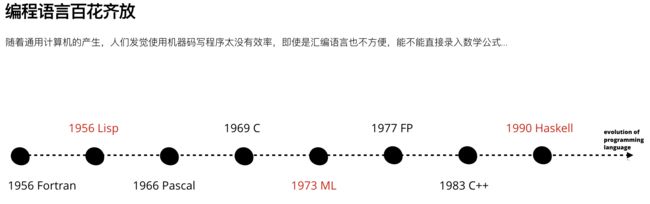
在这之后,随着通用计算机的产生,人们发觉使用机器码写程序太没有效率。所以1956年左右,John Buckus发明了Fortran(FORmula TRANslating 的缩写)语言,如果对编译原理有了解,那么对BNF范式就不陌生了。与此同时,John McCarthy 发明了Lisp语言,现代的Clojure就是Lisp的方言之一。1966年,Niklaus Wirth发明了Pascal。1969年,Ken Thompson和Dennis Ritchie发明了C语言,过程式语言由于其高效和可移植性迅速崛起。1973年,Robin Milner 发明了ML(Meta Language),后来演变成了OCaml和Stardard ML。1977年,John Buckus在其图灵奖的演讲中创造了 Functional Programming 这个词。1990年,惰性求值的函数式编程语言 Haskell 1.0 发布。
神奇的 Y Combinator
(def Y (fn [f]
((fn [x] (x x))
(fn [x]
(f (fn [y]
((x x) y)))))))
Lisp、ML以及Haskell的关系
Lisp是动态语言,使用S表达式
ML和Haskell都是静态强类型函数式语言
ML是第一个使用Hindley-Milner type inference algorithm的语言
Lisp和ML都是call-by-value,但是Haskell则是call-by-name
Lisp和ML都是不纯的编程语言,但是Haskell是side effect free的
函数是一等公民
函数是一等公民,指的是你可以将函数作为参数、返回值、数据结构存在,而且不仅可以用函数名引用,甚至可以匿名调用。
1. 作为参数
(map inc [1 2 3 4 5]) ;-> (2 3 4 5 6) ;; inc is an argument
2. 作为返回值
(defn add [num]
(fn [other-num] (+ num other-num))) ;; as return-value
(def add-one (add 1))
(add-one 2) ;-> 3
(defn flip [f] ;; as argument and return-value
(fn [x y]
(f y x)))
3. 数据结构
(def dictionary {:a "abandon"}) ;; map is also a function, data is code.
(dictionary :a) ;-> "abandon"
(:a dictionary) ;-> "abandon"
4. 匿名函数
((fn [x] (* x x))
2) ;-> 4
(map
(fn [num] (+ 1 num)) ;; anonymous function
[1 2 3 4 5]) ;-> (2 3 4 5 6)
5. 模块化
在面向对象中,对象是一等公民。所以我们处处要从对象的角度去考虑计算问题,然后产生一种共识——数据应该和它相关的操作放到一起,也就是我们所说的封装。确实没错,但是我们得知道封装的意义在哪里?功能内聚好理解(分块)和局部性影响(控制可变性)。函数式编程同样考虑这些,功能内聚不一定要用类的方式(考虑一下JS的prototype,也是一种面向对象),只要模块做得好,一样能达到效果。局部性影响,其本质是封装可变因素以避免其扩散到代码各处。函数式给出了自己的答案,消除可变因素。
高阶函数和惰性求值也非常有利于模块化。
纯函数和不可变性
纯函数是指执行过程中没有副作用的函数,所谓副作用是说超出函数控制的操作,比如在执行过程中操作文件系统、数据库等外部资源。纯函数还具有引用透明性的特点,也就是同样的输入导致同样的输出,以至于完全可以用函数的值代替对函数的调用。
引用透明
举个例子:
(inc 1) ; -> 2
(= (inc (inc 1)
(inc 2))) ; -> true
你们可能就会问,这种东西究竟有什么用呢?纯函数可以很方便地进行缓存。
(defn fibonacci [number]
(if (or (zero? number) (= 1 number)) 1
(+
(fibonacci (dec number))
(fibonacci (- number 2)))))
(fibonacci 30) ; -> "Elapsed time: 185.690208 msecs"
(def fibonacci
(memoize (fn [number] ;;
(if (or (zero? number) (= 1 number)) 1
(+
(fibonacci (dec number))
(fibonacci (- number 2)))))))
(fibonacci 30) ; -> "Elapsed time: 0.437114 msecs"
不可变计算
谈到不可变性,我们做个游戏。统计在座的一共有多少人数。我们都知道从某个人开始依次报数,最后得到的数字就是总人数,其实这就是一种不可变计算的游戏,为什么这么说呢?因为报数其实一个计算的过程,第一个人计算出1这个数,传递给第二个人。然后第二个人拿着前面的1进行加一操作,然后把结果2传递给后面的人做加法,以此类推。为了提高统计的效率,我也可以进行分组,然后每组自行报数,最后统计结果。但是如果我在白板上写个数字1,然后让大家来过来该这个数字,很大可能会出现错误,因为这个数字成为了竞态条件。在多并发的情况下,就得用读写锁来控制。所以不可变性特别利于并发。

不可变的链式结构
好了,现在我们有个新的需求,设计一个不可变列表收集大家的名字。每个节点存储一个姓名的字符串,并且有个指针指向下一个节点。但是这也打破了列表的不可变性。怎么办?我们可以把新的节点指向旧有的列表,然后返回一个新的列表。这就是不可变列表实现的机制。随便一提,这也是区块链不可变特征的由来。

Clojure的创造者Rich Hickey扩展了Ideal Hash Tree数据结构,实现了Persistent Vector。由于此处的叶子节点可以扩展成32个,所以可以大量存储数据。利用Ideal Hash Tree的特点可以快速索引出数据,与此同时,数据的“增删改”也能做到近常数化的时间,并且总是产生新的数据结构替换原有的数据结构,即一种不可变的链式存储结构。

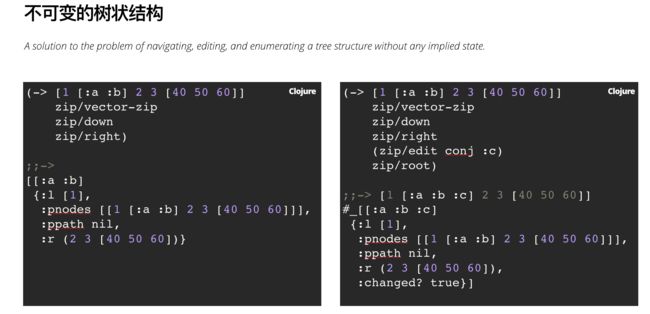
不可变的树状结构
Zipper数据结构类似于文本编辑器中的 gap buffer,编辑文本时,光标左边和右边分别是独立的buffer,光标处也是单独的buffer,这样便可以方便地添加文字,也很方便删除左右buffer中的文字;移动光标会涉及buffer之间的拷贝。基本上能在常数时间内完成编辑。Zipper数据结构模仿了这种方式,能在常数时间内完成树的编辑工作,也能很快地重新构建一棵树。
递归
可计算很大问题就是得实现递归功能。
(defn reverse-seq [coll]
(when-let [elem (first coll)]
(concat (reverse-seq (rest coll)) [elem])))
(reverse-seq [1 2 3]) ; -> (3 2 1)
和循环无异的尾递归
(defn gcd [& nums]
(reduce #(if (zero? %2)
%
(recur %2 (mod % %2))) nums))
(gcd 8 16) ; -> 8
生成式测试
生成式测试会基于输入假设输出,并且生成许多可能的数据验证假设的正确性。
(defn add [a b]
(+ a b))
;; 任取两个整数,把a和b加起来的结果减去a总会得到b。
(def test-add
(prop/for-all [a (gen/int)
b (gen/int)]
(= (- (add a b) a) b)))
(tc/quick-check 100 test-add)
; -> {:result true, :num-tests 100, :seed 1515935038284}
测试结果表明,刚才运行了100组测试,并且都通过了。理论上,程序可以生成无数的测试数据来验证add方法的正确性。即便不能穷尽,我们也获得一组统计上的数字,而不仅仅是几个纯手工挑选的用例。
抽象是什么
抽取共性,封装细节,忘记不重要的差异点。这样的好处是可以做到局部化影响和延迟决策。

命名
命名就是一种抽象,重构中最重要的技法就是重命名和提取小函数
(* 3 3 3)
(* x x x)
(* y y y)
->
(defn cube [x]
(* x x x))
延迟决策
例如:我们定义数对 pair
pair:: (cons x y)
first pair -> x
second pair -> y
那么它的具体实现会是这样的
(defn cons [x y]
(fn [m]
(cond (= m 0) x
(= m 1) y)))
(defn first [z]
(z 0))
(defn second [z]
(z 1))
也可以是这样的,还可以是其它各种各样的形式。
(defn cons [x y]
(fn [b]
(b x y))
(defn first [z]
(z (fn [x y] x)))
(defn second [z]
(z (fn [x y] y)))
高阶函数
高阶函数就是可以接收函数的函数,高阶函数提供了足够的抽象,屏蔽了很多底层的实现细节。比如Clojure中的map高阶函数,它接收(fn [v] ...),把一组数据映射成另外一组数据。
过程抽象
(map inc [1 2 3 4 5]) ; -> (2 3 4 5 6)
这些函数抽象出映射这样语义,除了容易记忆,还能很方便地重新编写成高效的底层实现。也就是说,一旦出现了更高效的map实现算法,现有的代码都能立刻从中受益。
函数的组合
函数组合之后会产生巨大的能量
神奇的加法
(((comp (map inc) (filter odd?)) +) 1 2) ; -> 4
怎么去理解这个函数的组合?我们给它取个好听的名字
(def special+ ((comp (map inc) (filter odd?)) +))
(special+ 1 2) ; -> 4
; <=> 等价于
(if (odd? (inc 2))
(+ 1 3))
1)
这个未必是个好的组合方式,但是不可否认的是,我们可以用这些随意地将这些函数组合到一起,得到我们想要的结果。
transducer
(def xf (comp (filter odd?) (take 10)))
(transduce xf conj (range))
;; [1 3 5 7 9 11 13 15 17 19]
这里直接将求值延迟到了transduce计算的时候,换句话说,xf定义了一种过程:filter出奇数并取出前10个元素。同等的代码,如果用表达式直接书写的话,如下:
(->> (range)
(filter odd?)
(take 10))
这里的问题就是我们没能使用高阶函数抽象出过程,如果把 conj 换成其他的reduce运算,现在的过程无法支撑,但是tranducers可以!
(transduce xf + (range)) ;-> 100
我们再看一个tranducer的神奇使用方式:
(defn log [& [idx]]
(fn [rf]
(fn
([] (rf))
([result] (rf result))
([result el]
(let [n-step (if idx (str "Step: " idx ". ") "")]
(println (format "%sResult: %s, Item: %s" n-step result el)))
(rf result el)))))
(def ^:dynamic *dbg?* false)
(defn comp* [& xforms]
(apply comp
(if *dbg?*
(->> (range)
(map log)
(interleave xforms))
xforms)))
(binding [*dbg?* true]
(transduce
(comp*
(map inc)
(filter odd?))
+
(range 5))) ;; -> 9
Step: 0. Result: 0, Item: 1
Step: 1. Result: 0, Item: 1
Step: 0. Result: 1, Item: 2
Step: 0. Result: 1, Item: 3
Step: 1. Result: 1, Item: 3
Step: 0. Result: 4, Item: 4
Step: 0. Result: 4, Item: 5
Step: 1. Result: 4, Item: 5
之所以会出现上述的结果,是因为interleave xforms将(map inc)以及(filter odd?)和logs进行了交叉,得到的结果是(comp (map inc) (log) (filter odd?) (log)),所以如果是偶数就会被filter清除,看不见log了。
首先一定得理解:每个tranducer函数都是同构的!
形式如下
(defn m [f]
(fn [rf]
(fn [result elem]
(rf result (f elem)))))
这意味着(m f)的函数都是可以组合的,组合的形式如下:
(comp (m f) (m1 f1) ...)
展开之后
((m f)
((m1 f1)
((m2 f2) ...)))
->
(fn [result elem]
(((m1 f1)
((m2 f2) ...)) result (f elem)))
所以可以看到第一个执行的一定是 comp 的首个 reducing function 参数。故:
- xform 作为组合的前提
- 执行顺序从左到右;
-
+作为 reducing function 最后执行;
Monad
什么是Monad呢?A monad is just a monoid in the category of endofunctors.
- Identity—For a monad m, m flatMap unit => m
- Unit—For a monad m, unit(v) flatMap f => f(v)
- Associativity—For a monad m, m flatMap g flatMap h => m flatMap {x => g(x) flatMap h}
// java8 实现的 9*9 乘法表
public class ListMonad {
private List elements;
private ListMonad(T elem) {
this.elements = singletonList(elem);
}
private ListMonad(List elems) {
this.elements = elems;
}
public ListMonad flatmap(Function> fn) {
List newElements = new ArrayList<>();
this.elements.forEach(elem -> newElements.addAll(fn.apply(elem).elements));
return new ListMonad<>(newElements);
}
public ListMonad uint(X elem) {
return new ListMonad<>(elem);
}
public ListMonad apply(ListMonad> m) {
return m.flatmap(this::map);
}
public ListMonad map(Function fn) {
return flatmap(t -> uint(fn.apply(t)));
}
public static void main(String[] args) {
ListMonad m = new ListMonad<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9));
ListMonad m1 = new ListMonad<>(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9));
ListMonad list = m.apply(m1.map(x -> y -> x * y));
// [1...81]
}
}
表达式优于语句
S表达式
- 原子,或者;
- 形式为 (x • y) 的表达式,其中x和y也是S表达式。
举个例子,递增一组数据,过滤奇数,然后进行排序,最终取出第一个。如果取不到,返回:not-found。
(-> [1 2 3]
(->> (map inc)
(filter odd?)
(sort)
(first))
(or :not-found))
; -> 3
(-> [1 1 3]
(->> (map inc)
(filter odd?)
(sort)
(first))
(or :not-found)
; -> :not-found
当然你也可以写成
(if-let [r (first (sort (filter odd? (map inc [1 1 1]))))]
r
:not-found)
; -> :not-found
其实两者都是S表达式,但是下面的写法更加偏向于语句。从串联起来读来讲,前者明显是由于后者的。这要是放在其他函数式语言上,效果更加显著。比如下面重构if-else控制语句到Optional类型。
if-else -> Optional
Optional rule = ruleOf(id);
if(rule.isPresent()) {
return transform(rule.get());
} else {
throw new RuntimeException();
}
public Rule transform(Rule rule) {
return Rule.builder()
.withName("No." + rule.getId())
.build();
}
这是典型的语句可以重构到表达式的场景,关键是怎么重构呢?
第一步,调转if。
Optional rule = ruleOf(id);
if(!rule.isPresent()) {
throw new RuntimeException();
}
return transform(rule.get());
第二步,Optional.map函数
...
return rule.map(r -> transform(r)).get();
第三步,inline transform函数
...
rule.map(r -> Rule.builder()
.withName("No." + r.getId())
.build()).get();
第四步,Optional.orElseThrow函数
...
rule.map(r -> Rule.builder()
.withName("No." + r.getId())
.build())
.orElseThrow(() -> new RuntimeException());
第五步,注if释语句中的throw new RuntimeException()
if(!rule.isPresent()) {
// throw new RuntimeException();
}
这时候发现语句中为空,即可将整个语句删除。可以考虑inline rule。
ruleOf(id).map(r -> Rule.builder()
.withName("No." + r.getId())
.build())
.orElseThrow(() -> new RuntimeException());
完毕。
我们认识事物的方式
- 把几个简单的想法合并成一个复合概念,从而创造出所有复杂的概念。
- 简单的或复杂的两种思想融合在一起,并立即把它们联系起来,不要把它们统一起来,从而得到它所有的关系思想。
- 把他们与其他所有陪伴他们的真实存在的想法分开:这就是所谓的抽象,因此所有的一般想法都是被提出来的。
推荐的书籍
- 逻辑的引擎
- 函数式编程思维
- 算机程序的构造和解释
 推荐的书籍
推荐的书籍
参考资料
- 图灵停机问题
- 康托尔、哥德尔、图灵 - 永恒的金色对角线
- Y combinator in Clojure
- 希尔伯特的23个问题
- 再谈哥德尔不完备定理
- wiki 函数式编程
- lambda 演算
- History of functional programming
- 函数式编程的早期历史
- 走进计算机文化史
- SICP
- Lambda Calculus and the Decision Problem