深度学习项目部署:使用TensorRT通过ONNX部署Pytorch项目
Tensor方案介绍
- 1 模型方案
-
- 1.1 部署流程
- 1.2 正确导出onnx
- 1.3 在C++中使用
-
- 1.3.1 构建阶段
- 1.3.2 反序列化模型
- 1.3.3 执行推理
- 2 使用TensorRT部署YOLOv5
-
- 2.1 下载YOLOv5源码
- 2.2 导出YOLOv5 onnx模型
- 2.3 在C++中使用
1 模型方案
TensorRT 的安装介绍可根据博文TensorRT安装及使用教程和windows安装tensorrt了解。
引用【1】
标题:TensorRT安装及使用教程
链接: https://blog.csdn.net/zong596568821xp/article/details/86077553
作者:ZONG_XP
引用【2】
标题: windows安装tensorrt
链接: https://zhuanlan.zhihu.com/p/339753895
作者: 知乎用户15Z1y4
1.1 部署流程
基于ONNX路线,调用C++、Python接口后交给Builder,最后生成引擎。

1.2 正确导出onnx
简单写了一个例子:
import torch
import torch.nn as nn
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=3,stride=1,padding=1,bias=True)
self.conv.weight.data.fill_(1)
self.conv.bias.data.fill_(1)
def forward(self,x):
x = self.conv(x)
return x.view(-1,int(x.numel()//x.size(0)))
model = Model().eval()
x = torch.full((1,1,3,3),1.0)
y = model(x)
torch.onnx.export(
model,(x,),"test.onnx",verbose=True
)
用netron导入生成的onnx文件,可在线查看网络结构和参数:
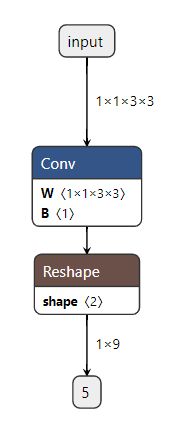
1.3 在C++中使用
首先将tensorRT路径下的include内的文件拷贝到cuda对应的include文件夹下,lib文件夹内的lib文件和dll文件分别拷贝到cuda对应的lib/x64文件夹下和bin文件夹下。
再配置VS环境,这里给出需要配置清单:
├── VC++目录
│├── 包含目录
%OPENCV_PATH%\opencv\build\include
%OPENCV_PATH%\opencv\build\include\opencv2
│├──库目录
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64
%OPENCV_PATH%\opencv\build\x64\vc15\lib
├──C/C++
│├──常规
││├──附加包含目录
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\include
├──链接器
│├──常规
││├──附加库目录
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64
│├──输入
││├──附加依赖项
c10.lib
libprotobuf.lib
mkldnn.lib
torch.lib
torch_cpu.lib
nvinfer.lib
nvinfer_plugin.lib
nvonnxparser.lib
nvparsers.lib
cudnn.lib
cublas.lib
cudart.lib
nvrtc.lib
opencv_world3416.lib
根据TensorRT官方开发者指南中的C++ API实例,开发流程大致如下:
1.3.1 构建阶段
首先创建builder,先实例化ILogger接口来捕获异常:
class Logger : public ILogger
{
void log(Severity severity, const char* msg) override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
但是按照官方文档来写会报错:重写虚函数的限制性异常规范比基类虚成员函数
看了官方的sample,logging.h里写的是
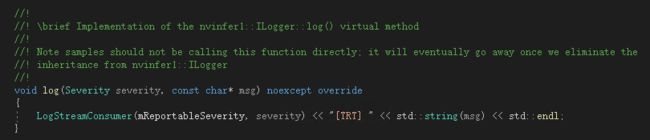
所以此处改成:
class Logger : public ILogger
{
//void log(Severity severity, const char* msg) override
void log(Severity severity, const char* msg) noexcept override
{
// suppress info-level messages
if (severity <= Severity::kWARNING)
std::cout << msg << std::endl;
}
} logger;
接着实例化builder:
IBuilder* builder = createInferBuilder(logger);
实例化builder后,优化模型的第一步是创建网络定义:
uint32_t flag = 1U <<static_cast<uint32_t>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH)
INetworkDefinition* network = builder->createNetworkV2(flag);
定义好网络以后,可以创建ONNX解析器来填充网络:
IParser* parser = createParser(*network, logger);
然后,读取模型文件并处理任何错误:
parser->parseFromFile(modelFile, ILogger::Severity::kWARNING);
for (int32_t i = 0; i < parser.getNbErrors(); ++i)
{
std::cout << parser->getError(i)->desc() << std::endl;
}
接着构建engine,创建一个构建配置,指定 TensorRT 应如何优化模型。
unsigned int maxBatchSize = 1;
builder->setMaxBatchSize(maxBatchSize);
IBuilderConfig* config = builder->createBuilderConfig();
此接口有许多属性,您可以设置这些属性以控制 TensorRT 如何优化网络。一个重要的属性是最大工作空间大小。层实现通常需要一个临时工作空间,并且此参数限制了网络中任何层可以使用的最大大小。如果提供的工作空间不足,TensorRT 可能无法找到层的实现。
config->setMaxWorkspaceSize(1U << 20);
指定好配置便可构建引擎,序列化模型,即把engine转换为可存储的格式以备后用。推理时,再简单的反序列化一下这个engine即可直接用来做推理。通常创建一个engine还是比较花时间的,可以使用这种序列化的方法避免每次重新创建engine:
IHostMemory* serializedModel = builder->buildSerializedNetwork(*network, *config);
序列化引擎包含必要的权重副本,解析器、网络定义、构建器配置和构建器不再需要,可以安全地删除:
delete parser;
delete network;
delete config;
delete builder;
1.3.2 反序列化模型
假设之前已经序列化了一个优化模型并希望执行推理:
IRuntime* runtime = createInferRuntime(logger);
ICudaEngine* engine = runtime->deserializeCudaEngine(modelData, modelSize);
1.3.3 执行推理
IExecutionContext *context = engine->createExecutionContext();
int32_t inputIndex = engine->getBindingIndex(INPUT_NAME);
int32_t outputIndex = engine->getBindingIndex(OUTPUT_NAME);
void* buffers[2];
buffers[inputIndex] = inputBuffer;
buffers[outputIndex] = outputBuffer;
context->enqueueV2(buffers, stream, nullptr);
这里是为了异步推理使用enqueueV2,如果希望同步推理,可以使用excuteV2
2 使用TensorRT部署YOLOv5
2.1 下载YOLOv5源码
下载https://github.com/ultralytics/yolov5master分支。
2.2 导出YOLOv5 onnx模型
打开export.py文件直接运行后生成yolov5s.onnx文件,打开后如图:
2.3 在C++中使用
加载导出的yolov5s.onnx并推理(项目完整代码在TensorRT部署yoloV5源码):
#include 运行结果:

如果报错C4996:
‘XXXX’: This function or variable may be unsafe. Consider using localtime_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.
在报错的文件中添加:
#pragma warning(disable:4996)
如果报错C2664:
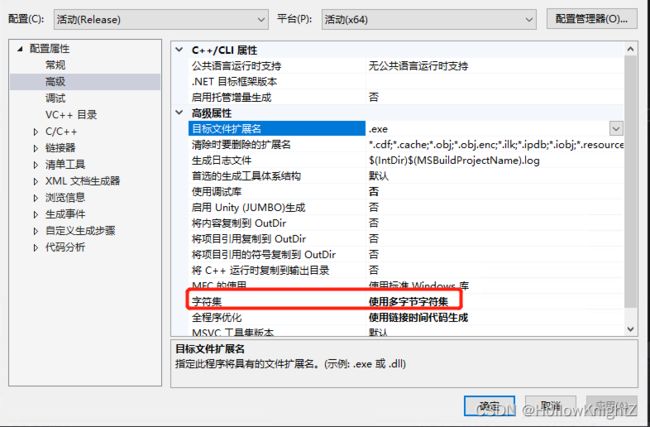
“HMODULE LoadLibraryW(LPCWSTR)”: 无法将参数 1 从“const _Elem *”转换为“LPCWSTR”
右键解决方案->属性->配置属性->高级->字符集
将"使用Unicode字符集"改成"使用多字节字符集"
TensorRT报错:
TensorRT was linked against cuBLAS/cuBLAS LT 11.6.3 but loaded cuBLAS/cuBLAS LT 11.5.1
通过查看博文https://blog.csdn.net/qq_41151162/article/details/118735414发现是cuda版本问题。
TensorRT报错:
Parameter check failed at: ...
导致这个的原因是预训练模型与网络结构不匹配,重新生成对应的预训练模型即可。