mysql优化十:从架构角度全局理解mysql性能优化
从架构角度全局理解mysql性能优化
MySQL性能优化其实是个很大的课题,在优化上存在着一个调优金字塔的说法:
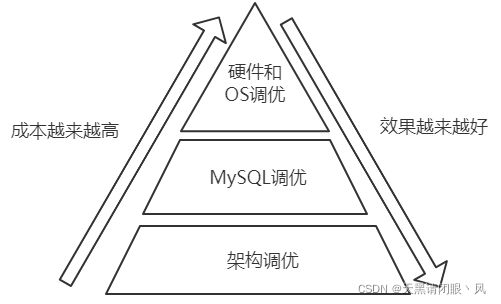
很明显从图上可以看出,越往上走,难度越来越高,收益却是越来越小的。比如硬件和 OS调优,需要对硬件和OS有着非常深刻的了解,例如磁盘阵列 (RAID)级别、是否可以分散磁盘IO、是否使用裸设备存放数据,使用哪种文件系统,还有操作系统的调度算法等等。
所以在进行优化时,首先需要关注和优化的应该是架构,如果架构不合理,即使是DBA 能做的事情其实是也是比较有限的。
对于架构调优,在系统设计时首先需要充分考虑业务的实际情况,是否可以把不适合数 据库做的事情放到数据仓库、搜索引擎或者缓存中去做;然后考虑写的并发量有多大, 是否需要采用分布式;最后考虑读的压力是否很大,是否需要读写分离。对于核心应用或者金融类的应用,需要额外考虑数据安全因素,数据是否不允许丢失。
对于MySQL调优,需要确认业务表结构设计是否合理,SQL语句优化是否足够,该添加的索引是否都添加了,是否可以剔除多余的索引等等。
最后对于系统、硬件上的调优系统瓶颈在哪里,哪些系统参数需要调整优 化,进程资源限制是否提到足够高;在硬件方面是否需要更换为具有更高I/O性能的存储硬件,是否需要升级内存、CPU、网络等。
知道了调优的方向,下面还是主要从mysql角度去优化。
优化SQL查询方法论
查询性能低下最基本的原因是访问的数据太多。大部分性能低下的查询都可以通过减少访问的数据量的方式进行优化。之前不论是对表优化,对sql优化还是索引优化,主要目的也是为了减少扫描的数据量。那么在做这些具体优化之前,我们需要从两个角度去考虑一下
- 业务层:是否请求了不需要的数据
- 查询不需要的记录
比如说每次查询了1000条数据,但是每次之取前100条数据,那么这900条就多余了 - 总是取出全部的列
写sql的时候是否写了select *,每次都取出全部的列,是无法使用到覆盖索引的 - 重复查询相同的数据
是否反复执行同一条sql,比如在for循环中执行sql,或者热点数据重复查询
- 执行层:是否在扫描额外的数据
最常见的就是分页查询,查1000页的数据,每页10条看似只返回了10条其实需要查10000条,然后去掉前面的9990条数据。
对于MySQL,最简单的衡量查询开销的三个指标如下:
- 响应时间
响应时间是两个部分之和:服务时间和排队时间。 服务时间是指数据库处理这个查询真正花了多长时间。 排队时间是指服务器因为等待某些资源而没有真正执行查询的时间—-可能是等I/O操作 完成,也可能是等待行锁,等等。 - 查询的行数和返回的行数
我们查询扫描的行数,和实际返回的数据,比如说的分页 limit 10000,10 像这种数据的利用率就非常低。这样的查询,这时MySQL需要查询10010条记录然后只返回最后10条,前面10 000条 记录都将被抛弃,这样的代价非常高。 - 扫描的行数和访问类型
有些访问方式可能需要扫描很多行才能返回一行结果,也有些访问方式可能无须扫描就能返回结果。在EXPLAIN语句中的type列反应了访问类型,一般我们都要达到range的级别
这些是写sql查询的方向,至于具体sql的优化,比如分页怎么优化,怎么使用索引这些在之前的优化中都有讲到,就不在重复了。
重构SQL查询的方法论
在优化有问题的查询时,目标应该是找到一个更优的获取结果的方法,而不是保证一定得从mysql中获取到和优化前一模一样的数据。比如说在多表关联的时候,查询效率慢,可以通过拆分成多个单表在通过业务代码进行整合到一起。就是说换一种写法,或者通过应用代码来达到最终的目的。
一个复杂查询还是多个简单查询
设计查询的时候一个需要考虑的重要问题是,是否需要将一个复杂的查询分成多个简单 的查询。在传统实现中,总是强调需要数据库层完成尽可能多的工作,这样做的逻辑在于以前总是认为网络通信、查询解析和优化是一件代价很高的事情。对于MySQL并不适用,MySQL 从设计上让连接和断开连接都很轻量级,在返回一个小的查 询结果方面很高效。现代的网络速度比以前要快很多,无论是带宽还是延迟,即使是一 个千兆网卡也能轻松满足每秒超过2000次的查询。 所以有时候,可以将一个复杂的大查询分解为多个小查询会效率更高。
不过,在应用设计的时候,如果一个查询能够胜任时还写成多个独立查询是不明智的。具体怎么运用不能一概而论,不能走极端说只用复杂查询或者只用简单查询。
切分查询
对于一个大数据量的查询来说,如果每次一条sql返回了好几万的数据量,就会导致查询性能低下,这时候考虑分而治之,将大的查询分成几个小的查询,每个查询功能一样,但只返回少量的结果集。在通过应用代码做处理。
一般来说,将每个SQL返回的记录控制在5000到10000是个比较好的权衡值。
分解关联查询
很多高性能的应用都会少的使用关联查询,而是将关联查询进行分解。乍一看,这样做并没有 什么好处,原本一条查询,这里却变成多条查询,返回的结果又是一模一样的。事实 上,用分解关联查询的方式重构查询有如下的优势:
- 让缓存更高效
每次join查询一张字典表或者高频数据的表。通过关联拆分,拆分成两条sql。这样可以将高频的数据或者字典表保存到缓存当中,这时就只需查询一张业务表,然后从缓存中获取数据在进行关联。这样提高了缓存的使用率 - 减少锁的竞争
高频的读写操作出现数据库的并发性可能性就会提高,在并发情况下为了保证数据的一致性、有效性就会加锁。大部分情况关联查询都会比单表查询慢,拆分关联查询降低并发性,也就减少锁的竞争。 - 更容易做到高性能和高扩展
如果在应用层面做数据的关联,把数据库的压力分担到应用层面上,在应用层面上解决性能问题。在应用层面可以更好的水平扩展,提过性能。比如说分布式,负载均衡,增加其他中间件进行辅助等。可扩展的方案就会比价多。 - 减少冗余数据的查询
在应用层访问高热频的表可能就访问一次,然后放入缓存,如果做关联查询,可能每次都需要查询高热频的表 - 相当于在应用中实现了哈希关联
在应用层做关联相当于实现了哈希关联,而不是使用MySQL的嵌套循环关 联。某些场景哈希关联的效率要高很多。
从MySQL执行全流程考虑性能优化
如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间,sql查询时间就是一系列的子任务完成的时间总和。优化sql就是优化sql执行过程中的子任务。
查询过程中需要在不同的地方花费时间,包括网络,CPU计算,生成统计信息和执行计划、锁等待(互斥等待)等操作,尤其是向底层存储引擎检索数据的调用操作,这些调用需要在内存操作,CPU操作和内存不足时导致的IO操作上消耗时间。根据存储引擎不同,可能还会产生大量的上下文切换以及系统调用。
当我们优化了表,优化了sql优化了索引后,发现查询还是慢,就要知道这个慢到底慢在了那里,一定是慢在了查询数据上吗。
查询执行的流程回顾
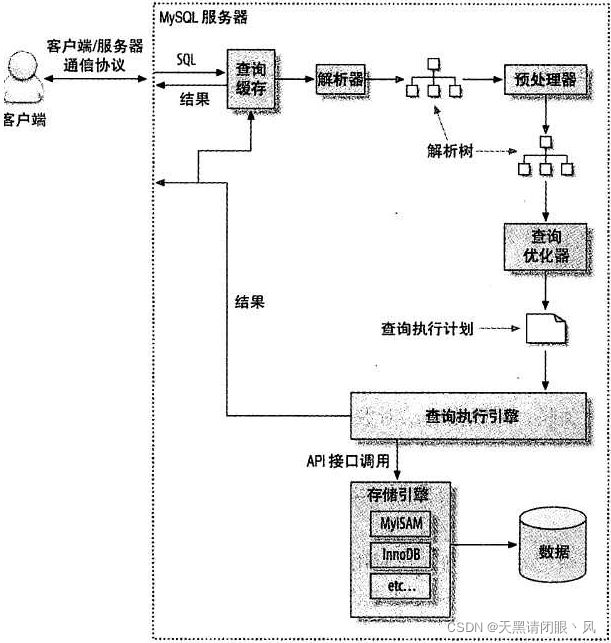
在优化七中讲到sql执行过程,这里在回顾一下。
- 客户端发送一条查询sql给mysql服务器。
- 服务器先检查查询缓存,如果命中了缓存,则立刻返回存储在缓存中的结果。否则 进入下一阶段(当然从MySQL8.0开始,这个部分就没有了)。
- 服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划。
- MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询。
- 将结果返回给客户端。
所以mysql的查询过程就从客户端到服务器端,在服务器上解析sql,优化sql,生成执行计划,调用存储引擎API,执行完将结果集返回给客户端。
其中“执行”可以认为是整 个生命周期中最重要的阶段,这其中包括了存储引擎的调用,检索数据以及数据处理,包括排序、分组等。
上面的每一步都比想象的复杂。所以这个时间慢在了那里就要具体去分析
MySQL客户端/服务器通信
有了解过TCP协议的知道TCP通信协议是全双工的。全双工意味着:客户端向服务器端发送数据的同时,服务器端也能向客户端发送数据。反过来也是一样。而mysql的通讯协议呢,一般来说,不需要去理解MySQL通信协议的内部实现细节,只需要大致理解通信协议是如何工作的。
MySQL客户端和服务器之间的通信协议是“半双工”的,这意味着,在任何一个时刻,要么是由服务器向客户端发送数据,要么是由客户端向服务器发送数据, 这两个动作不能同时发生。这种协议有点就是简单,但是限制就很多。一个明显的限制是,没法进行流量控制。一旦一端开始发生消息,另一端要接收完整个消息才能响应它。比如说有一个很长很大的sql,上百k,msyql不会接受了一部分就开始执行,等到另一部分接受了在执行另一部分。或者将几万条数据返回给客户端,客户端也不能说接受个2000条,先处理着,让mysql暂停传送,等处理完了在接着接受,默认情况下是做不到的,但可以通过jdbc的setFetchSize()之类的功能设置,如果采用这种方式设置,就相当于把压力放到了mysql这边。这也是在必要的时候一定要在查询中加上LIMIT限制的原因。
所以有些时候mysql检索几万条数据的时候很快,但是将几万条数据通过网络传输到客户端的时间可能要比检索的时间长。这时候去优化检索时间就显得意义不大。
生命周期中的查询优化处理
这个过程包括:解析SQL、预处理、生成SQL执行计划。这个 过程中任何错误(例如语法错误)都可能终止查询。在实际执行中,这几部分可能一起 执行也可能单独执行。
MySQL的查询优化器是一个非常复杂的部件,它使用了很多优化策略来生成一个最优的执行计划。内部是如何优化的就不深入学习,至于内部的优化规则,在下篇的优化中会讲到。
优化器是相当复杂性和智能的。建议大家“不要自以为比优化器更聪明”。如果没有必要,不要去干扰优化器的工作,让优化器按照它的方式工作。尽量按照优化器的提示去优化我们的表、索引和SQL语句,比如写查询,或者重新设计更优的库表结构,或者添
加更合适的索引。
所以尽可能的保持SQL语句的简洁,SQL语句变得很复杂的情况下,会拖累优化器的优化效率,如果在写sql的时候把优化器做的事情给做了,那么就减少了优化器去优化sql的这个时间。
执行查询过程
在解析和优化阶段,MySQL将生成查询对应的执行计划,MySQL的查询执行引擎则根据这 个执行计划来完成整个查询。相对于查询优化阶段,查询执行阶段不是那么复杂: MySQL 只是简单地根据执行计划给出的指令逐步执行。
返回结果给客户端
MySQL将结果集返回客户端是一个增量、逐步返回的过程。一旦服务器开始生成第一条 结果时,MySQL就可以开始向客户端逐步返回结果集了。
这样处理有两个好处﹔服务器端无须存储太多的结果,也就不会因为要返回太多结果而消耗太多内存。另外,这样的处理也让 MySQL客户端第一时间获得返回的结果。结果集中的每一行都会以一个满足MySQL客户端/服务器通信协议的封包发送,再通过TCP协议 进行传输,在TCP传输的过程中,可能对MySQL的封包进行缓存然后批量传输。
而且之前讲过,mysql读取数据是页为单位,哪怕只读取一条记录,也要读取记录所在的页。一个数据页就是16Kb,如果读取的数据页成千上万,mysql要把数据全部读取完在一次性返回的话,那么内存受不了,磁盘也受不了。所以mysql读取一条数据就返回一条数据。
查询状态
mysql每次执行查询任务都会创建一个线程。查询任务又可以分为上面这么多的子任务。所以说这个查询线程,要么处于接收sql的状态,要么处于分析优化sql的状态,要么处于执行查询数据过程的状态,要么处于处理返回结果集的状态。
这些状态表示了MySQL当 前正在做什么。在一个查询的生命周期中,状态会变化很多次。
通过SHOW PROCESSLIST;查询线程当前状态。线程状态有很多。可以参考官方文档https://dev.mysql.com/doc/refman/8.0/en/general-thread-states.html
找到对应自己数据库版本。
通过show profile分析SQL
通过上面的描述可知,当我们通过应用程序访问MySQL服务时,有时候性能不一定全部卡在语句的执行上。
当然通过慢查询日志定位那些执行效率较低的SQL语句时候我们常用的手段,但是:
- 慢查询日志在查询结束以后才记录,在应用反映执行效率出现问题的时候查询未必 执行完成;
- 有时候问题的产生不一定是语句的执行,有可能是其他原因导致的。慢查询日志并 不能定位问题。
那么这个时候可以通过show processlist查看线程处于哪个状态的时间最长,就可以对症下药。可以看看几个常见的线程状态。
以下这些状态从mysql8.0版本官网上摘录下来的。
- checking permissions
The thread is checking whether the server has the required privileges to execute the statement.
线程正在检查服务器是否具有执行该语句所需的权限。 - statistics
The server is calculating statistics to develop a query execution plan. If a thread is in this state for a long time, the server is probably disk-bound performing other work.
服务器正在计算统计数据以开发查询执行计划。如果线程长时间处于这种状态,则服务器可能是在磁盘上执行其他工作。 - Creating tmp table
The thread is creating a temporary table in memory or on disk. If the table is created in memory but later is converted to an on-disk table, the state during that operation is Copying to tmp table on disk.
线程正在内存或磁盘上创建临时表。如果表是在内存中创建的,但是后来被转换为磁盘上的表,则该操作期间的状态是copy to tmp table on disk。 - Sending data
Prior to MySQL 8.0.17: The thread is reading and processing rows for a SELECT statement, and sending data to the client. Because operations occurring during this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query. MySQL 8.0.17 and later: This state is no longer indicated separately, but rather is included in the Executing state.
在MySQL 8.0.17之前:线程正在读取和处理一个SELECT语句的行,并将数据发送给客户端。由于在此状态期间发生的操作往往会执行大量磁盘访问(读取),因此它通常是给定查询生命周期中运行时间最长的状态。MySQL 8.0.17及更高版本:这个状态不再单独表示,而是包含在执行状态中。
通过show profile分析
对于每个线程到底时间花在哪里,可以通过show profile来分析。
首先检查当前MySQL是否支持profileselect @@have_profiling;

默认profiling是关闭的,可以通过set语句在 Session级别开启 profiling:
select @@profiling;查看 profile 是否开启 开启为1 不开启为0
set profiling=1;
执行需要分析的sql
select count(*) from order_exp;
show profiles;
这两条sql同时执行,查看sql对应的id,比如我要分析select count(*) from order_exp;这条sql。执行完后

对应记录id为3
执行show profile for query 3;
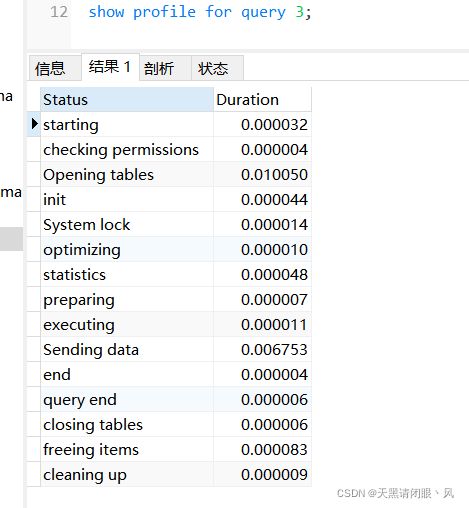
这些就是sql对应线程状态所花费的时间。
也可以通过show profile all for query 3; 查询具体状态的时间花在哪里
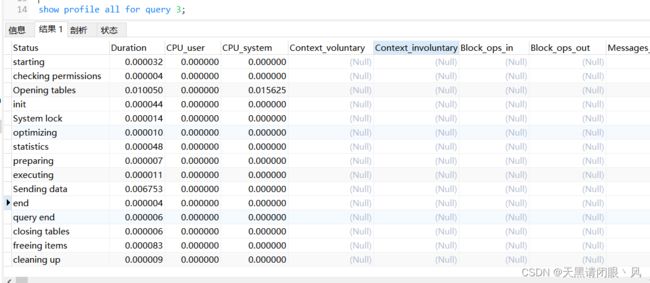
列的含义从官网中查看
https://dev.mysql.com/doc/refman/5.7/en/show-profile.html
