Pandas_05数据清洗(重复值、缺失值以及异常值的处理)
一、重复值处理
一般保留第一条重复数据,对其他重复数据进行移除。
-
判断重复值 df.duplicated
'''
df.duplicated(subset=None, keep='first')
参数说明:
subset:列标签,默认使用所有列,若只考虑用某些列来识别重复项,可指定列
keep,默认first,保留重复值的第一项,
也可以指定last,保留最后一项重复值数据
返回的是一个视图
'''
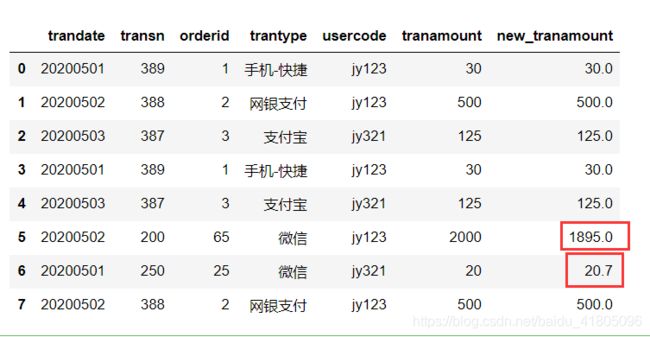
数据:
-
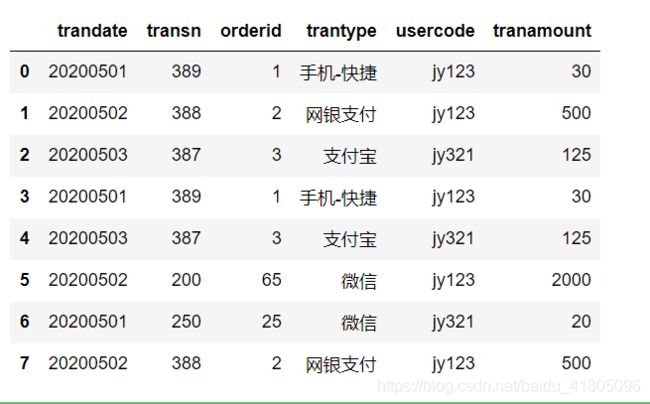
判断重复数据
tran_data.duplicated()
True为重复数据

取出重复数据:
tran_data[tran_data.duplicated()]
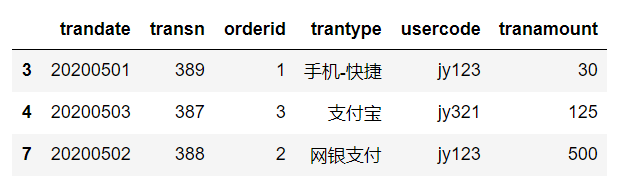
按照指定列判断重复数据
tran_data[tran_data.duplicated(subset='trantype')]
猜想:按照trantype列来判断重复值,默认相同数据第一项非重复值,那么可以锁定3,4,6,7为重复数据

执行代码后:(猜想得到验证)
-
删除重复数据 df.drop_duplicates
'''
df.drop_duplicates(subset=None, keep='first', inplace=False)
subset:默认全部列,可以指定特定列来判断重复数据
keep:保留重复数据的第一条数据
inplace:是否就地操作,默认False,返回一个视图
True,就地操作,直接在原数组数据上删除重复值
'''
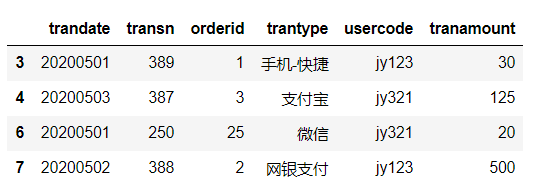
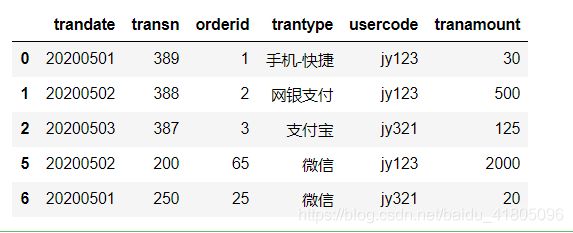
tran_data.drop_duplicates(inplace=True)
tran_data
删除后无重复数据:
二、缺失值处理
1、删除缺失值df.isnull()
2、替换法或插值法填充数据
1、删除缺失值
1.1、Series
data = pd.Series(['Linda',np.nan,'Jim',np.nan,'Hanna'])
data

- 判断缺失值(isnull,notnull)
判断数据是否是缺失值,是返回True
# 判断缺失值,效果同isna()
data.isnull()
out:
 判断数据是否是非缺失值,不是缺失值返回True
判断数据是否是非缺失值,不是缺失值返回True
# 判断非缺失值,效果同notna()
data.notnull()
out:

- 删除缺失值(dropna())
'''
data.dropna(axis=0, inplace=False, **kwargs)
返回移除缺失值后的数组
参数说明:
axis:默认0,按行的方向移除
'''
# 就地删除缺失值
data.dropna(inplace = True)
data
out:

1.2、DataFrame
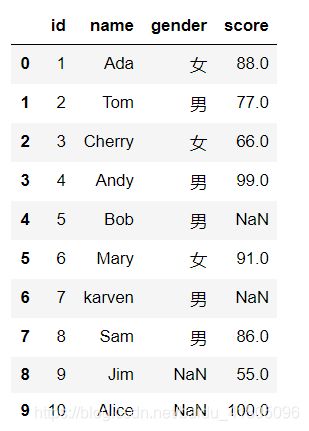
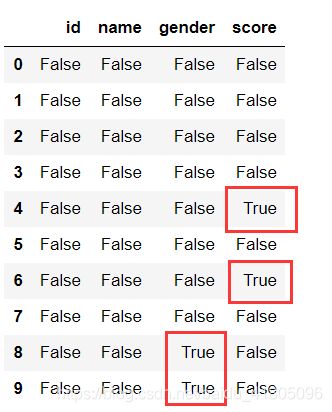
- 判断缺失数据
Test_data1.isna()
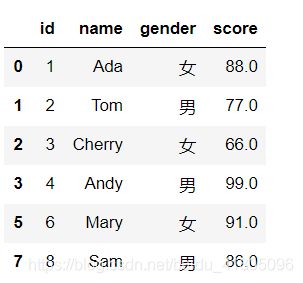
- 删除缺失值(dropna())
默认只要一行有一个缺失值即整行被删除
'''
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数说明:
axis:0 or 'index', 1 or 'columns'
0 or 'index':删除有缺失值的行
1 or 'columns':删除有缺失值的列
how:any or all,默认any
any:只要有一个缺失值,即执行删除操作
all:所有值为缺失值,即执行删除操作
subset:对特定的列进行缺失值删除处理(列表形式)
'''
Test_data1.dropna()
how =‘all’,当该行所有数据都为NaN,数据才会被删除
Test_data1.dropna(how ='all')
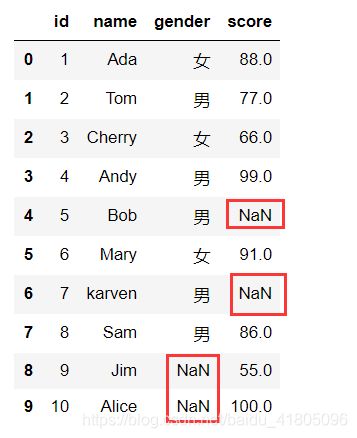
删除指定列有缺失值的行
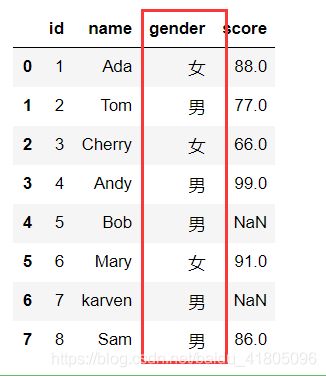
Test_data1.dropna(subset = ['gender'],how ='any')
2、填充缺失值
-
指定值填充
'''
Test_data1.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
常用参数说明:
value:用于填充的缺失值的标量值或字典对象
method:插值方式,{'backfill', 'bfill', 'pad', 'ffill', None}
默认为ffill.
pad/ffill:前项填充,表示用前面行/列的值,填充当前行/列的空值,
backfill/bfill:后项填充,表示用后面行/列的值,填充当前行/列的空值。
axis:填充方向,0:纵向;1:横向。
limit: 针对前项填充和后项填充,可以连续填充的最大数量
'''
# 将空值填充为0
Test_data1.fillna(0)
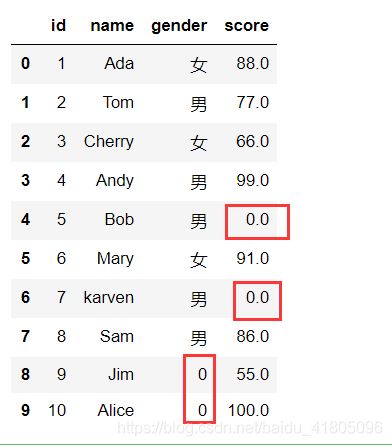
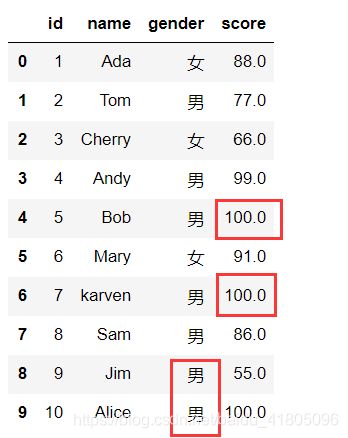
通过字典指定值填充空值(对不同的列进行不同值的填充)
Test_data1.fillna({'gender':'男','score':100})
一般来说,性别这样的特征数据,会采用众数填补–mode()
可以看出,在gender这一列,性别为男的数据出现的最多,所以众数为‘男’
Test_data1.gender.mode()

年龄这类的数据若有缺失值,一般采用均值来做填充
收入、分数一般用中位数来进行填充
下面来对这两列的空值进行填充:
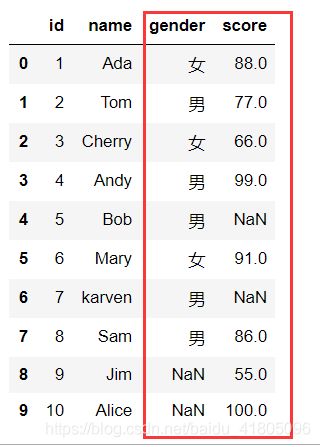
# 有时众数不止一个,我们取第一个出现最多的众数Test_data1.gender.mode()[0]
Test_data1.fillna(value = {'gender' : Test_data1.gender.mode()[0], \
'score': Test_data1.score.median()})
-
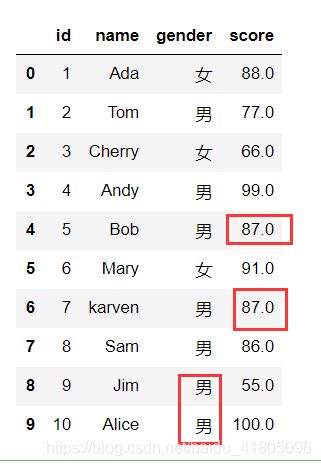
插值法填充
用上一个非空数据填充当前的空值数据
# 效果等同于Test_data1.fillna(method ='pad')
Test_data1.fillna(method ='ffill')
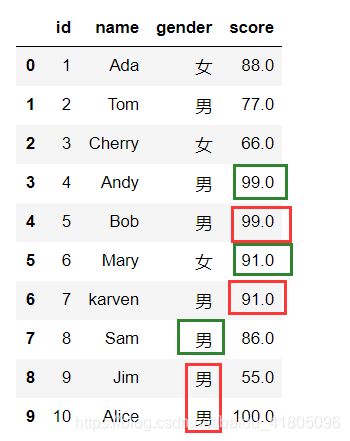
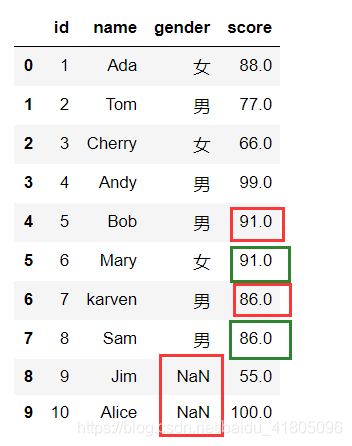
用下一个非空数据填充当前的空值数据
# 效果等同于Test_data1.fillna(method ='backfill')
Test_data1.fillna(method ='bfill')
可以看出gender列的空值填充后依然是空值,因为空值的下一列也是空值。
所以我们可以看出插值法的弊端,当第一项数据或者最后一项数据为空值,那么数据填充起来依然会有空值存在。
拓展:
1、统计空值个数
np.sum(Test_data1.isna())
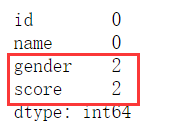
2、统计缺失率
np.sum(Test_data1.isna())/len(Test_data1)

二、异常值处理
异常值:
偏离正常范围的值,不是错误值。
出现的频率很低,但是会对数据分析造成偏差
常采用盖帽法或者数据离散化进行处理。
1、异常值的判断
-
使用均值和标准差进行判断
也叫n个标准差法
均值±n个标准差内的数据叫做正常值
一般为2-3个标准差
计算均值和标准差
# 计算均值:(416.25)
tran_data['tranamount'].mean()
# 标准差 670.5368318423253
tran_data['tranamount'].std()
搭配any(),查看是否有超过上下限的数据,这种数据为异常值
top = tran_data['tranamount'].mean() + 2 * tran_data['tranamount'].std()
# 1757.3236636846507
bottom = tran_data['tranamount'].mean() - 2 * tran_data['tranamount'].std()
# -924.8236636846507
# 是否有超过下限的情况
any(tran_data.tranamount < bottom)
# False
# 是否有超过上限的情况
any(tran_data.tranamount > top)
# True
查看tranamount为正常值的数据
tran_data[tran_data['tranamount'].between(bottom,top)]
可以看出少了索引为5的那条数据,该数据tranamount为2000,超出上限1757.3236636846507
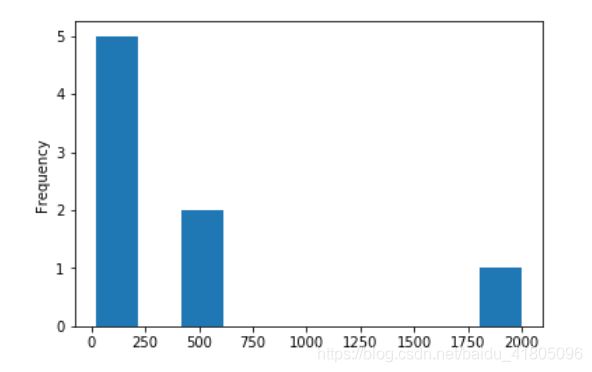
也可以画个直方图看一下数据的分布情况,感受一下:
tran_data.tranamount.plot(kind ='hist')
-
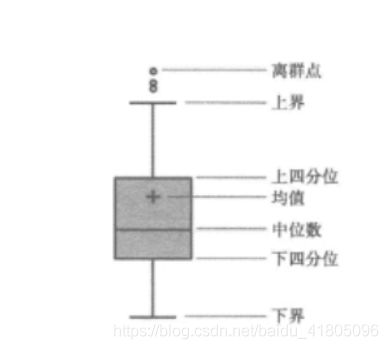
箱线法
上四分位数:取3/4位置的数
下四分位数:取1/4位置的数
分位差 = 上四分位数- 下四分位数上界 = 上四分位数 + 1.5分位差
下界= 下四分位数 - 1.5分位差
上界 、下界范围之内的数据叫做正常值,范围之外的叫做异常值。
计算上四分位数、下四分位数、分位差 、上界、下界
# 下四分位数
Q1 = tran_data.tranamount.quantile(0.25)
# 30.0
# 上四分位数
Q3 = tran_data.tranamount.quantile(0.75)
# 500.0
# 分位差
IQR = Q3 - Q1
# 470.0
# 上界
Q3 + 1.5 * IQR
# 1205.0
# 下界
Q1 - 1.5 * IQR
-675.0
判断是否有超出上下界的数据
# 是否有超出上界的数据
any(tran_data.tranamount > Q3 + 1.5 * IQR)
# True
# 是否有低于下界的数据
any(tran_data.tranamount < Q1 - 1.5 * IQR)
# False
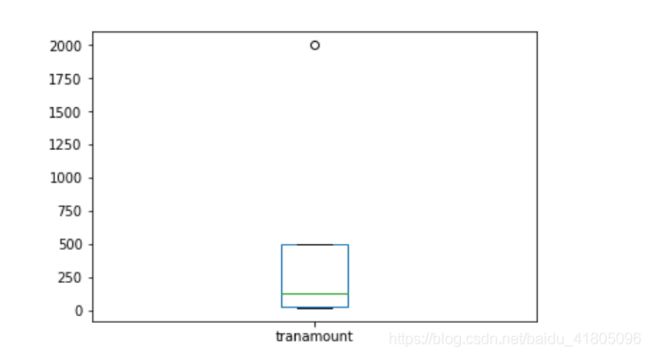
可以通过箱线图来观测一下数据:
tran_data.tranamount.plot(kind = 'box')
可以看出有超出上界的数据。
2、异常值的处理
方法一:
用小于上限最大值去替换超出上限的异常值
用大于下限最小值去替换低于下限的异常值
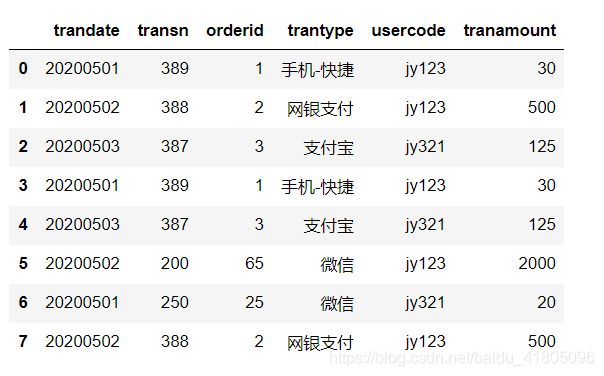
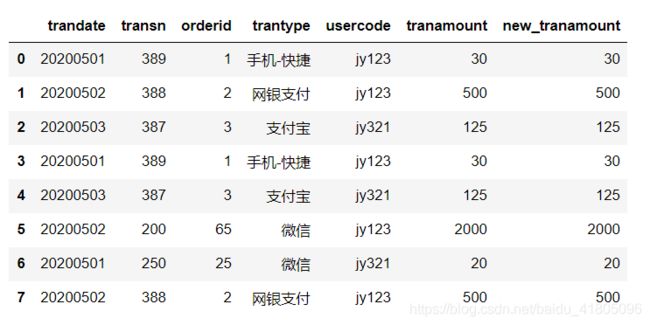
数据准备:
(新增一列new_tranamount数据,是为了替换异常值后做对比)
tran_data['new_tranamount'] = tran_data['tranamount']
tran_data
计算小于上限的最大值,作为替换值
UL = Q3 + 1.5 * IQR
# 低于上限的最大值
replace_value = tran_data.new_tranamount[tran_data.new_tranamount < UL].max()
# 500
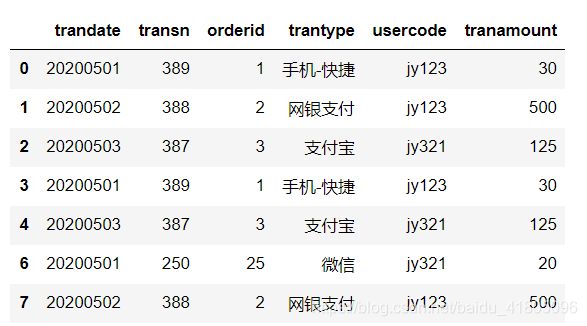
用替换值替换超出上限的数据:
tran_data.loc[tran_data.new_tranamount>UL,'new_tranamount'] = replace_value
tran_data
方法二:
低于百分之一分位数的数据用百分之一分位数替换
高于百分之九十九分位数的数据用百分之九十九分位数替换
 计算百分之一分位数、百分之九十九分位数
计算百分之一分位数、百分之九十九分位数
# 百分之一分位数
P1=tran_data.new_tranamount.quantile(0.01)
# 20.7
# 百分之九十九分位数
P99=tran_data.new_tranamount.quantile(0.99)
# 1894.9999999999998
进行替换
tran_data.loc[tran_data['new_tranamount']>P99,'new_tranamount'] = P99
tran_data.loc[tran_data['new_tranamount']<P1,'new_tranamount'] = P1