阿里云机器学习——让人工智能触手可及
1.概述
近期,阿里云计划将旗下机器学习平台正式商业化发布。说到机器学习可能有些人会比较迷惑,但是提到人工智能,人们马上就联想到了刷脸支付、人机智能交互、商品智能推荐等场景,机器学习算法就是助力这些人工智能应用的底层算法。
最近几年,机器学习发展趋势火热,主要是我们在深度学习技术上取得了一定的进展,总结起来应该是三大因素:
- 数据:互联网上每天生成海量的数据,有图像、语音、视频、还有各类传感器产生的数据,例如各种定位信息、穿戴设备;非结构化的文本数据也是重要的组成部分。数据越多,深度学习越容易得到表现好的模型。
- 大规模分布式高性能计算能力的提升:这些年来,GPU高性能计算、分布式云计算等计算平台迅猛发展,让大规模的数据挖掘和数据建模成为可能,也为深度学习的飞跃创造了物质基础;阿里云的愿景之一就是成为和水电煤一样的基础设施。
- 算法上的创新:随着数据和计算能力的提升,算法本身也有了很大的进展,尤其在深度学习方面,譬如从脑神经学上得到的灵感,在激活函数上进行了稀疏性的处理,等等。
基于上述三点,人工智能又迎来了它的第二个春天。人工智能将以更快的速度进入我们的生产和生活中来,成为我们的眼睛,我们的耳朵,帮助我们更快捷地获取信息,辅助我们做出决策。阿里云机器学习平台产品也因此而产生,加速迭代过程,助力技术的发展。下面我们对照阿里云机器学习平台架构图对其功能进行介绍:
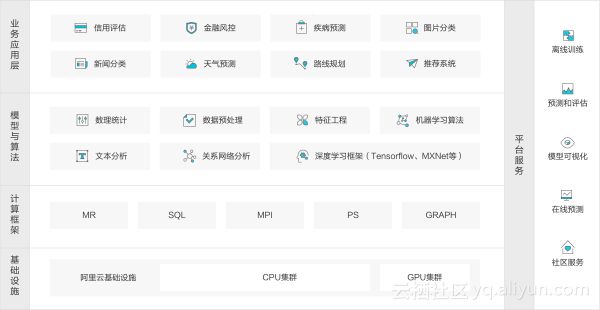
阿里云机器学习架构图
阿里云机器学习的平台的基础设施和计算框架建立在阿里云飞天计算平台之上,支持MR、SQL、MPI、PS、GRAPH共5种分布式计算框架,对于底层的CPU和GPU计算机群可以灵活地调用。另外,在模型与算法层,阿里云机器学习涵盖了数据预处理、特征工程、机器学习算法、深度学习框架、模型评估和预测等全套数据挖掘流程。

算法流程
在业务应用层,算法开发者可以基于阿里云机器学习平台轻松地搭建起例如疾病预测、金融风控、新闻分类等各种场景的应用。
2.关键技术特点
那么阿里云机器学习平台具备哪些关键技术特点呢?
2.1人性化的操作界面
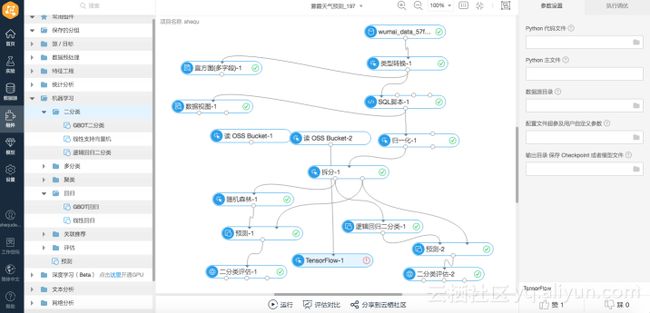
机器学习操作界面
阿里云机器学习平台让机器学习不再远不可及,在平台上没有繁琐的公式和复杂的代码逻辑,用户看到的是各种分门别类被封装好的算法组件。在搭架实验的过程中,只要拖拽组件就可以快速的拼接成一个workflow。操作体验类似于搭积木,真正做到让小白用户也可以轻松玩转机器学习。“过去半个月才能搭建的一套数据挖掘实验,利用阿里云机器学习平台3个小时就可能解决”。
同时,平台的每一个实验步骤都提供可视化的监控页面,数据挖掘工程师可以实时的掌握模型的训练情况,可视化的结果评估组件也极高的提升了模型调试效率。 在深度学习黑箱透明化方面,我们也在不断的研发集成各种可视化的工具,包括开源的TensorBoard和自研的工具,为客户提供更多可参考的信息,缩短模型优化的过程。
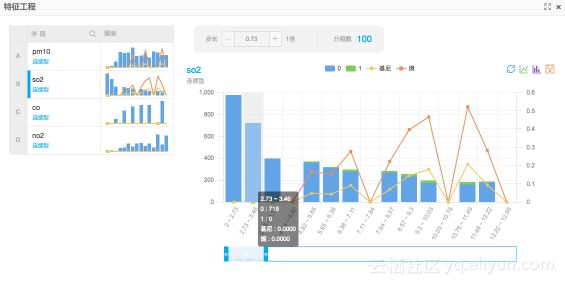
特征评估柱状图
2.2丰富的算法组件
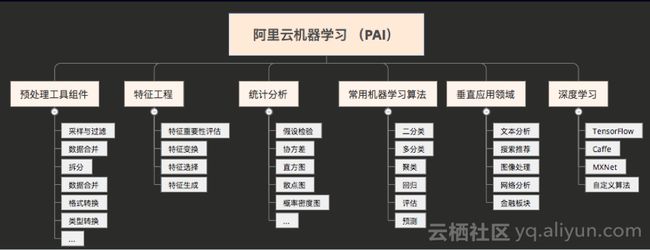
阿里云机器学习平台部分算法展示
阿里云机器学习平台提供100余种算法组件,涵盖了分类、回归、聚类等常用算法场景。另外平台还针对主流的算法应用场景,提供了偏向业务的算法,包含文本分析、关系分析、推荐3种类别。用户通过阿里云机器学习平台提供的算法,几乎可以解决任何场景的业务问题。特别值得说明的一点是,平台上的算法全部脱胎于阿里巴巴集团内部的业务实践,所有算法都经历过PB级数据和复杂业务场景的锤炼,具备成熟稳定的特点。
算法列表如下(包括所属类别和具体算法):
数据预处理
- 加权采样(weightedSample)
- 随机采样(randomSample)
- 过滤与映射(filterReflect)
- 分层采样(stratifiedSample)
- JOIN
- 合并列(appendColumns)
- UNION
- 增加序列号(appendId)
- 稠密转稀疏 tableToKV
- 拆分(split)
- 缺失值填充(fillMissingValues)
- 归一化(normalize)
- 标准化(standardize)
- 类型转换(typeConvert)
特征工程
- 主成分分析(PCA)
- 特征规范(featureNomalize)
- 特征离散(featureDiscret)
- 特征异常平滑(featureSoften)
- 特征尺度变换(featureScaleTransform)
- 随机森林特征重要性评估(randomForestFeatureImportance)
- GBDT特征重要性(GBDTFeatureImportance)
- 线性模型特征重要性(regression_feature_importance)
- 特征重要性过滤(featureFilter)
- 过滤式特征选择(filterFeatureSelect)
- 窗口变量统计(RFM)
- 特征编码(featureEncoding)
统计分析
- 百分位(percentile)
- 全表统计(fullTableSummary)
- 皮尔森系数(pearsonCoefficient)
- 直方图(多字段)(histogram)
- 离散值特征分析(enumFeaturesAanalysis)
- 数据视图(data_view)
- 协方差(cov) 切问
- 经验概率密度图(pdf)
- 箱线图( boxPlot)
- 散点图(scatter_diagram)
- Quantile
- 相关系数矩阵(corrcoef)
- 卡方拟合性检验(ChiSquare)
- 卡方独立性检验(ChiSquare)
- 单样本T检验(Ttest)
- 双样本T检验(Ttest)
机器学习
- 线性支持向量机(linearSVM)
- 逻辑回归二分类(binaryLogisticRegression)
- GBDT二分类(GBDTbinaryClassification)
- K近邻(knn)
- 逻辑回归多分类(logicRegressionMultiClassification)
- 随机森林(randomForest)
- 朴素贝叶斯(naiveBayes)
- K均值聚类(kmeans)
- 线性回归(linearRegression)
- GBDT回归(GBDTregression)
- 混淆矩阵(confusionMartix)
- 多分类评估(multiClassificationEvaluation)
- 二分类评估(binaryClassificationEvaluation)
- 回归模型评估(regressionModelEvaluation)
- 聚类模型评估(clusterEvaluation)
- 预测(prediction)
文本分析
- TF-IDF
- PLDA
- Word2Vec
- split Word
- 三元组转kv
- 字符串相似度
- 字符串相似度-topN
- 停用词过滤
- 文本摘要(TextSummarization)
- 关键词提取(keywords_extraction)
- 句子拆分( SplitSentences)
- ngram-count
- 语义向量距离(semanticVectorDistance)
- doc2vec
网络分析
- K-Core
- 单源最短路径(SSSP)
- PageRank
- 标签传播聚类(LabelPropagationClustering)
- 标签传播分类(LabelPropagationClassification)
- Modularity
- 最大联通子图(maximalConnectedComponent)
- 点聚类系数(nodeDensity)
- 边聚类系数(edgeDensity)
- 计数三角形(triangleCount)
- 树深度(treeDepth)
2.3提供业内主流深度学习架构
阿里云机器学习平台内置业内主流的深度学习架构:Tensorflow、MXNet、Caffee。
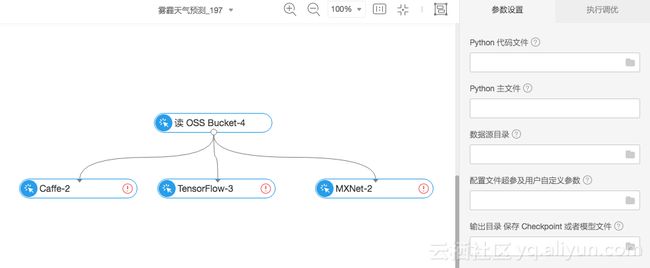
深度学习架构
对于不同的架构提供一致性的可视化操作环境,用户只需要将业务代码以及训练数据上传到OSS,即可通过配置路径完成深度学习网络模型的训练。整个计算架构都针对不同的深度学习框架进行了深入的优化,同时也提供了模型的一键部署成API的功能,完美解决了模型与业务衔接的问题。
在深度学习架构底层计算资源方面,平台提供了GPU的多卡灵活调度功能,只需要在界面填写需要的GPU资源数量,就可以将计算任务下发到对应的分布式计算机群上,免除运维烦恼。
2.4超大规模计算能力
得益于底层的飞天计算引擎,阿里云机器学习平台支持超大规模的分布式计算,每日处理PB级的计算任务请求。除了底层强悍的计算资源保证,在分布式计算架构优化方面,阿里云机器学习平台也做足工作。以参数服务器(PS)为例:
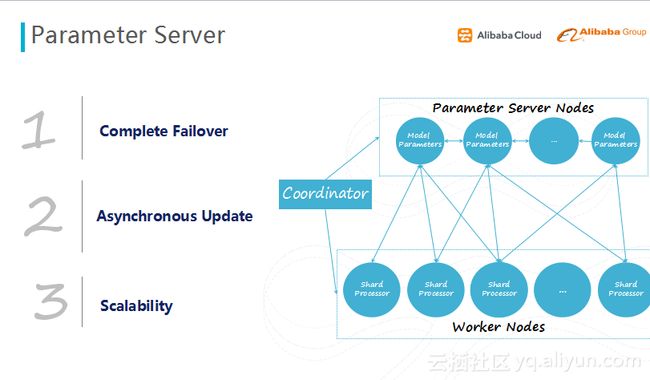
参数服务器
参数服务器主要思想是:不仅仅是进行数据并行,同时将模型分片,将大的模型分为多个子集,每个参数服务器只存一个子集,全部的参数服务器聚合在一起拼凑成一个完整的模型。该系统主要的创新点在于失败重试的功能,在分布式系统上,上百个节点协同工作时,经常会出现一个或几个节点挂掉的情况,如果没有失败重试机制,任务就会有一定的几率失败,需要重新提交任务到集群调度。
失败重试是将每个节点的状态备份到相邻(前后)的节点,当个别节点死掉后,重启一个新的节点,同时从原节点相邻的节点获取所存储的状态,理论上可以实现任务的100%完成。还有一个功能是异步迭代,无需等待全部节点完成任务,当大部分节点完成任务时,就可以直接更新对应的模型,这样可以不需要等待慢机的结果,从而摆脱慢机的影响,提升效率。
2.5在线预测服务能力
在PAI平台上,我们提供了丰富的算法实现,由CPU和GPU组成的计算集群也提供了超强的分布式计算能力,同时我们还提供模型在线预测服务,让数据与算法和计算能力的结合,可以直接输出强大的人工智能服务,方便地应用于各行各业。数据驱动下得到的模型,可以一键部署到云端作为一个API的应用服务。可以想见在不久的将来,云市场上会出现大量的PAI平台支撑的数据智能服务,助力万众创新的商业化和产业化,直接创造社会价值。
3.典型案例
3.1阿里巴巴集团内部案例
下面介绍在阿里内部的三个应用场景。
应用一:推荐系统
第一个应用是推荐系统,主要是参数服务器在推荐系统内的应用。当在淘宝购物时,经查询显示的商品一般都是非常个性化的推荐,它是基于商品的信息和用户的个人信息以及行为信息三者的特征提取。这个过程中形成的特征一般都是很大,在没有参数服务器时,采用的是MPI实现方法,MPI中所有的模型都存在于一个节点上,受限于自身物理内存上限,它只能处理2000万个特征;通过使用参数服务器,我们可以把更大模型(比如说百亿个特征的模型),分散到数十个乃至于上百个参数服务器上,打破了规模的瓶颈,实现了模型性能上的提升。
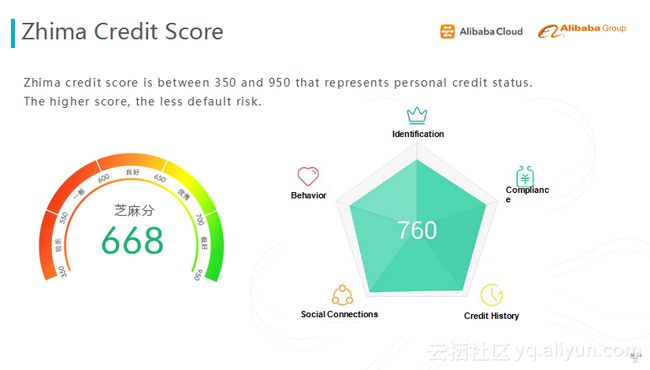
应用二:芝麻信用分
第二个应用是芝麻信用分。芝麻信用分是通过个人的数据来评估你个人信用。做芝麻信用分时,我们将个人信息分成了五大纬度:身份特质、履约能力、信用历史、朋友圈状况和个人行为进行评估信用等级。
在去年,我们利用DNN深度学习模型,尝试做芝麻信用分评分模型。输入是用户原始的特征,基于专家知识将上千维的特征分为五部分,每部分对应评分的维度。我们通过一个本地结构化的深度学习网络,来捕捉相应方面的评分。由于业务对解释性的需求,我们改变了模型的结构,在最上面的隐层,一共有五个神经原,每个神经原的输出都对应着它五个维度上面值的变化;再往下一层,是改变维度分数的因子层;用这种本地结构化的方式,维持模型的可解释性。
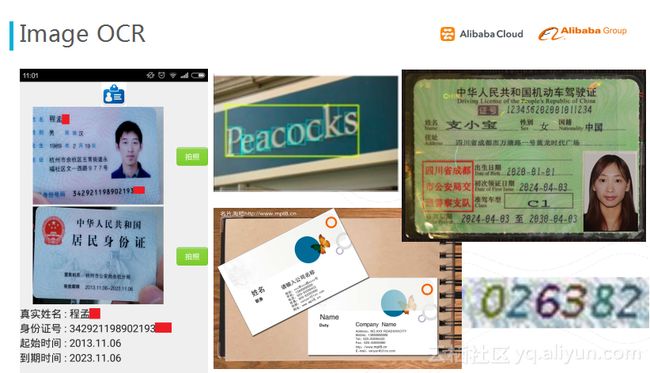
应用三:光学文字识别
最后一个应用是图象上面的光学文字的识别(OCR)。我们主要做强模板类、证件类的文字识别,以及自然场景下文字的识别。强模板服务(身份证识别)在数加平台上也提供了相应的入口,目前可以达到身份证单字准确率99.6%以上、整体的准确率93%。在识别中用到的是CNN模型,但其实整个流程特别长,不是深度学习一个建模就能解决的问题,包括版面分析、文字行的检测、切割等等技术。在CNN训练中,我们采用了多机多卡分布式算法产品,之前利用一千万个图像训练CNN模型,大约需要耗时70个小时,迭代速度非常缓慢;采用分布式8卡产品之后,不到十个小时就可以完成模型训练。目前OCR的服务已经成为了一个受欢迎的阿里云市场上的API,尤其是证件类的识别,准确率高,种类齐全,成为了一种可以在商业场景中广泛使用的数据服务。
3.2外部业务案例
在对外服务方面,阿里云机器学习平台已经在金融、地产、教育、医疗、天气等行业发挥作用——其中比较典型的案例是明源云在地产行业的应用,明源旗下的云采购平台利用阿里云机器学习平台搭建了一套销售CRM系统,这套系统包含数据的预处理、特征工程、机器学习、评估、预测以及调度。阿里云机器学习平台帮助明源精确的定位潜在用户,提高其销售份额接近百分之百。去年11月,阿里云在CBS大会上,发表了《Nonlinear Machine Learning Approach by Cloud Computing to Short-Term Precipitation Forecasting》的报告, 结合广东省气象局提供的大规模气象观测数据,我们使用阿里云机器学习平台对临近预报(0-3小时内)的降雨量进行建模预测。无论数据清洗、特征工程,还是非线性机器学习算法训练以及结果评估,均是由大规模可视化机器学习平台PAI来完成开发。最大优势在于用户无需掌握过多的底层算法知识,也无需要编写任何代码,只需在PAI中拖拽已有的组件即可完成一键式的程序运行,以本次广东省气象降水预测为例,建模流程如下图所示:
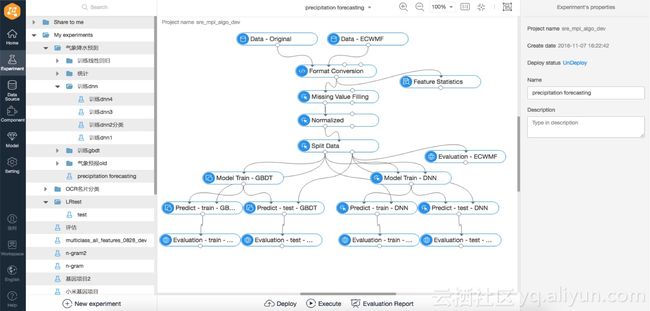
利用PAI建模的效果已经优于业界常用的方法,一定程度上再次论证了机器学习在气象领域,尤其是临近降雨上的优势。未来,我们会继续尝试引入更多的气象相关数据到阿里云上,比如卫星云图,雷达回波等数据,在时间维度上,也会引入更长历史的数据,充分发挥大数据的作用。同时,在方法创新上,我们会引入更多的模型研究工作,比如多站点的LSTM建模,时间维度上的高斯过程建模等等。为了鼓励公众在天气预报上的创新,不论是数据,算法,还是应用,阿里云未来会筹建气象app store,方便大家在线贡献,发布以及搜索感兴趣的应用。
阿里云机器学习平台作为人工智能的载体和源发动力,正在逐渐颠覆各行各业的生产模式。