慕课《用Python玩转数据》之B站弹幕数据分析
慕课《用Python玩转数据》之B站弹幕数据分析
1.源代码
# -*- coding: utf-8 -*-
"""
Created on Wed May 13 17:01:29 2020
@author: 苏子都
"""
import requests
import re
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import datetime
import matplotlib.pyplot as plt
# from matplotlib.pyplot import MultipleLocator
from pyecharts import Pie
import webbrowser
from wordcloud import WordCloud
import jieba
plt.style.use('seaborn-dark') #设置绘图风格
barrage_list=[] #获取到弹幕的内容
def get_barrage():
"""
爬取弹幕
返回:
- barrage_all: 弹幕的详细信息,比如发送者、发送时间等
"""
url='https://api.bilibili.com/x/v1/dm/list.so?oid=7633504'
res=requests.get(url)
res.encoding='utf-8'
res_xml=res.content.decode('utf-8')
barrage_all=[] #除了弹幕内容的其他信息,包括弹幕发送者ID、发送弹幕的时间
#匹配出需要的内容,形式如战歌起!
pattern=re.compile('(.*?)' ) #匹配出xml文件里面的d标签,获取弹幕内容
global barrage_list
barrage_list=pattern.findall(res_xml)
html=res.text
soup=BeautifulSoup(html,'html.parser')
for target in soup.find_all('d'): #弹幕的详细信息包含在d标签里面的p标签,先筛选出所有d标签
value=target.get('p').split(',') #获取p标签里面的内容
#根据爬取到的弹幕的详细信息的格式,生成并保存得到的结果
barrage_all.append({'时间':value[0],'弹幕模式':value[1],'弹幕字号':value[2],'弹幕颜色':value[3],'时间戳':value[4],'弹幕池':value[5],'发送者ID':value[6],'历史弹幕':value[7]})
return barrage_all
def data_processing(barrage_df):
"""
数据处理
参数:
- barrage_df: 弹幕的所有信息,由弹幕详细信息和弹幕内容组成
"""
barrage_time=(barrage_df['时间'].astype(float)).astype(int)
time_list=[] #存储弹幕发在整个视频的哪一个时间
#将爬取到的“时间”,由秒数变为时分秒的形式
for a_time in barrage_time:
m,s=divmod(a_time,60)
h,m=divmod(m,60)
a_time=str(h)+':'+str(m)+':'+str(s)
time_list.append(a_time)
barrage_df['时间']=time_list
#将爬取到的“弹幕模式”,按照数值分割成离散的区间
barrage_type=barrage_df['弹幕模式'].astype(int)
areas=[0,3,4,5,6,7,8]
pattern=['滚动弹幕','底端弹幕','顶端弹幕','逆向弹幕','精准定位','高级弹幕']
barrage_df['弹幕模式']=pd.cut(barrage_type,areas,right=True,labels=pattern)
barrage_tool=barrage_df['弹幕池'].astype(int)
areas=[-1,0,1,2]
pattern=['普通池','字幕池','特殊池']
barrage_df['弹幕池']=pd.cut(barrage_tool,areas,right=True,labels=pattern)
barrage_timestamp=barrage_df['时间戳'].astype(int)
timestamp_list=[] #存储弹幕发送的时间
#把爬取到的时间戳转换成字符串日期时间
for timestamp in barrage_timestamp:
timestamp_list.append(datetime.datetime.fromtimestamp(timestamp))
barrage_df['时间戳']=timestamp_list
barrage_df.to_csv('狐妖小红娘王权总篇集弹幕.csv',encoding='utf_8_sig')
def barrage_analyse_plt():
"""
根据爬取到本地的信息画图
"""
#解决画图时出现的中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
#因为爬取到的弹幕会包含整点发送的弹幕,此时以时间为轴画图会报错,所以需要以特定格式读取日期或时间,即代码中的parse_dates=['时间戳']
fox_demon=pd.read_csv('狐妖小红娘王权总篇集弹幕.csv',parse_dates=['时间戳'])
barrage_time=fox_demon['时间']
time_list=[] #弹幕在视频中的发送时间
#把弹幕在视频中的发送时间由时分秒的格式变为分钟数
for a_time in barrage_time:
h,m,s=a_time.strip().split(':')
temp=int(h)*60+int(m)+int(s)/60
time_list.append(temp)
time_df=pd.DataFrame(time_list)
'''
对时间进行分析并画密度图
'''
time_df.plot(kind='kde',label='弹幕密度') #采用DataFrame的plot方法实现可视化,画出密度图
plt.title('王权总篇弹幕密度')
plt.xlabel('时间/分')
plt.ylabel('百分比')
plt.legend(['弹幕密度'])
plt.xlim(0,) #限制x轴长度
# plt.xticks(np.arange(time_df.min(),time_df.max(),10))
plt.show()
'''
对弹幕颜色进行分析,并把较多的弹幕颜色作为绘图颜色画柱状图
'''
barrage_color=fox_demon['弹幕颜色'].value_counts() #统计用户发送的弹幕使用同一种颜色的数量
barrage_color=barrage_color.head(7) #选出前七种颜色
favorite_color=[] #弹幕颜色的十六进制颜色码
#将爬取到的十进制颜色码转换为十六进制颜色码
for a_color in barrage_color.index:
temp=hex(a_color)
temp='#'+temp[2:].upper()
while len(temp)<7:
temp=temp[0]+'0'+temp[1:]
favorite_color.append(temp)
fig,ax=plt.subplots()
#画柱状图,颜色为使用较多的弹幕颜色
plt.bar([1,2,3,4,5,6,7],barrage_color.values,color=favorite_color)
plt.title('王权总篇弹幕颜色使用数量前七名')
plt.xlabel('排名')
plt.ylabel('使用该颜色的弹幕数量')
plt.show()
# fig.savefig('temp.png',transparent=True)
'''
对时间戳进行分析,画出直方图,统计出各个时间段发送弹幕的数量
'''
barrage_date=fox_demon['时间戳'].dt.hour #抽取日期信息
bins=np.arange(0,25,1)-0.5
fig, ax=plt.subplots()
barrage_date.hist(bins=bins,grid=False,align='mid') #画出直方图,统计一天中各个时段的弹幕数量
plt.title('王权总篇各个时段弹幕数量')
plt.xlabel('时间段')
plt.ylabel('弹幕数量')
#设置x轴间隔
# x_major_locator=MultipleLocator(1)
# ax.xaxis.set_major_locator(x_major_locator)
plt.xticks(np.arange(0,24,1))
plt.show()
'''
对发送者ID进行分析,画出柱状图,统计出本集发送弹幕较多的前十个用户ID
'''
barrage_userId=fox_demon['发送者ID'].value_counts() #统计同一个用户ID发送的弹幕数量
barrage_userId=barrage_userId.head(10)
fig,ax=plt.subplots()
plt.bar(barrage_userId.index,barrage_userId.values,color=('r','g','b','c','m','r','g','b','c','m'))
plt.title('王权总篇发送弹幕前十的用户ID情况')
plt.xlabel('用户B站ID')
plt.ylabel('弹幕数量')
plt.xticks(size='small',rotation=50,fontsize=15) #对x轴文字进行相应的设置
plt.show()
'''
对弹幕内容进行分析,画出饼图,统计出同一弹幕长度的信息
'''
barrage_comment=fox_demon['弹幕内容']
comment_len=[] #存放每条弹幕的长度
comment_cloud='' #所有弹幕合并为一个文本,方便绘制词云时进行分词
for comment in barrage_comment:
comment_len.append(str(len(comment))+'个字弹幕')
comment_cloud=comment_cloud+comment+'\n'
comment_len_sr=pd.Series(comment_len) #通过数组生成一个series,方便使用value_counts()函数统计相同内容次数
comment_len_count=comment_len_sr.value_counts()
#通过matplotlib绘制饼图,与之前的DataFrame绘图基本一致
fig,ax=plt.subplots()
plt.pie(comment_len_count.values,labels=comment_len_count.index,autopct='%0.2f%%')
plt.title('王权总篇弹幕长度')
plt.show()
# plt.legend(loc='right',ncol=5) #设置图例
#使用pyecharts库绘制饼图,由于使用matplotlib绘制出来的饼图图片比较小,显示不清晰,功能也不算太好,就使用pyecharts库再画一个饼图
pie=Pie('狐妖小红娘弹幕内容分析','弹幕长度',title_pos='left',width=1100,height=600)
pie.add(
"弹幕长度",
comment_len_count.index,
comment_len_count.values,
is_label_show=True,
is_more_utils=True,
legend_pos='right', #图例居右
legend_orient='vertical' #图例以垂直方式显示
)
pie.render('fox_demon.html') #在根目录下生成一个fox_demon.html的文件
webbrowser.open('fox_demon.html') #在浏览器中打开保存的文件
'''
根据弹幕内容,画出词云、“句”云
'''
text=' '.join(jieba.cut(comment_cloud)) #分词
color_mask=plt.imread('susu.jpg') #读取图片
cloud=WordCloud(
font_path=' C:\\Windows\\Fonts\\simsun.ttc', #设置绘制词云的字体
background_color='white',
mask=color_mask, #根据读取的图片绘制词云
max_words=2000,
max_font_size=1000
)
#绘制“句”云
cloud_sentence=WordCloud(
font_path=' C:\\Windows\\Fonts\\simsun.ttc',
background_color='white',
mask=color_mask,
max_words=500,
max_font_size=1000
)
wCloud=cloud.generate(text) #生成词云
wCloud_sentence=cloud_sentence.generate(comment_cloud)
wCloud.to_file('cloud.png')
wCloud_sentence.to_file('cloud_sentence.png')
fig,ax=plt.subplots()
plt.imshow(wCloud,interpolation='bilinear') #展示词云
plt.title('王权总篇弹幕词云')
plt.axis('off')
plt.show()
fig,ax=plt.subplots()
plt.imshow(wCloud_sentence,interpolation='bilinear')
plt.title('王权总篇弹幕句云')
plt.axis('off')
plt.show()
if __name__=='__main__':
barrage_df=pd.DataFrame(get_barrage()) #生成弹幕详细信息
barrage_df['弹幕内容']=barrage_list #合并弹幕内容和弹幕详细信息
#数据处理
data_processing(barrage_df)
#绘图
barrage_analyse_plt()
2.弹幕数据分析
2.1. 爬取
所要爬取的内容如下图:

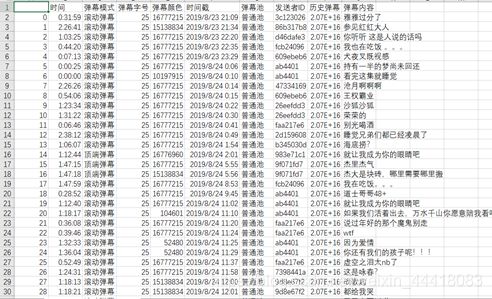
爬取并处理后得到的数据为:
2.2用户在本集中发送弹幕的时间分析
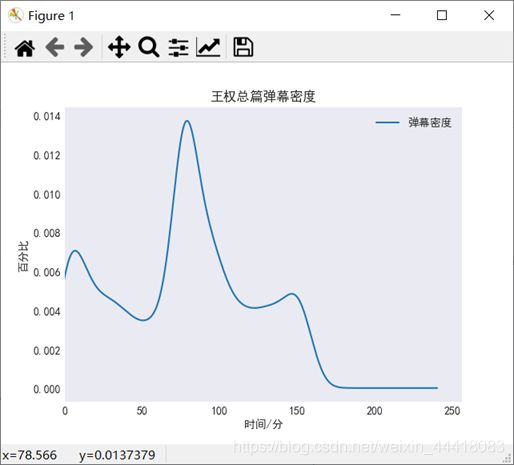
由上图可知,在视频一开始时便有比较多的弹幕,在视频的第80分钟这一时段便有本集最多的弹幕,这一分钟大约有本集1.4%的弹幕铺天盖地袭来,占据你的屏幕。如下图(PS:截图为每秒弹幕数量,与所统计的每分钟弹幕数量有区别,所以这一秒的弹幕数量会比较少,但这一分钟是全集最多的,统计秒数没有多大意义,毕竟整个视频接近一万秒)

2.3弹幕颜色分析

由上图可知,绝大多数用户使用白色的弹幕,约占所有用户的四分之三,红色、黄色和绿色也有使用。

2.4发送弹幕的时间段分析
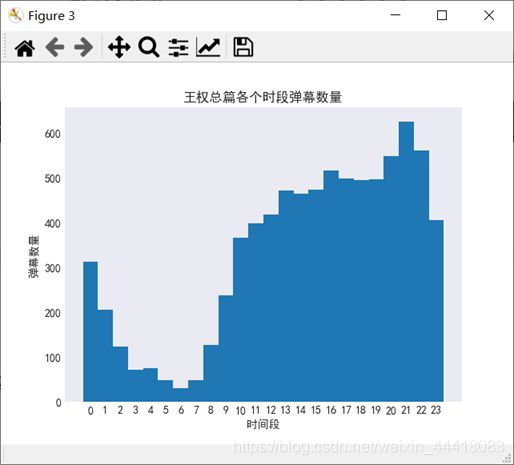
由上图可知,用户在一天中的21点至22点发送的弹幕数量最多,在午后至午夜这一时间段发送的弹幕比较多,可能是都起不来床也喜欢熬夜。
2.5用户ID分析

由上图可知,发送弹幕数量前十的用户基本都发送了30条以上的弹幕,发送弹幕最多的用户甚至发送了70条弹幕,这应该就是真爱粉了吧。
2.6 弹幕长度分析
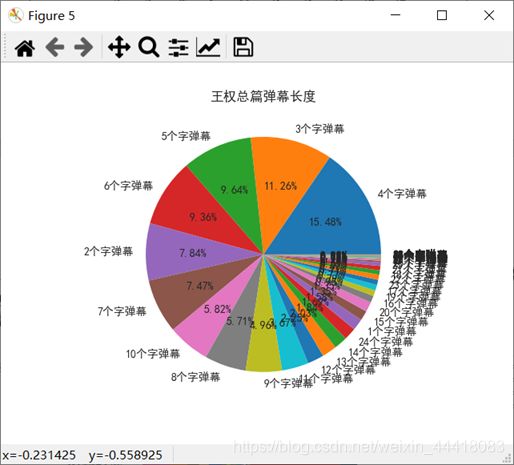

由上面两张图可知,绝大多数用户发送2-6个字的弹幕,其中4个字弹幕最多,约占所有弹幕的15.5%,也有用户发送了48个字超长的弹幕。
2.7弹幕词云、“句”云
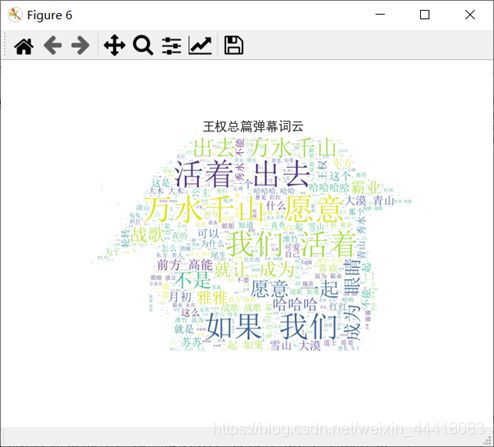
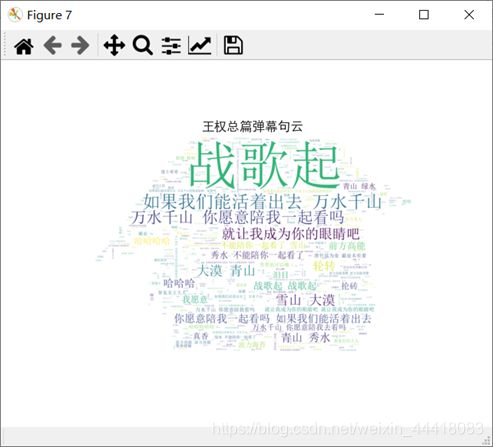
从上图的词云,可以看出本集弹幕的较多词语有“如果”、“我们”、“活着”、“出去”、“万水”、“千山”和“愿意”等等。由于B站的弹幕具有类似于“队列”的形式出现在屏幕之上,所以我就制作了“句”云,旨在画出弹幕里面的高频句子,从上图的“句”云,可以看出本集弹幕的较多弹幕内容有“战歌起”、“如果我们活着出去”、“万水千山”、“你愿意陪我一起看吗”和“就让我成为你的眼睛吧”等等。
3.写在后面
这个“爬虫”是通过B站视频的oid去爬取弹幕,所以如果要爬取其他的视频的弹幕,需要获取该视频的oid,爬取实质上是获取存储弹幕的XML文件的内容。博主普通学生一枚,暂时没有能力去同时连续爬取多个网页的弹幕,如有其他的不足,还请多多指教。