python---numpy详解
python—numpy详解
文章目录
-
- python---numpy详解
- 关于numpy
- Numpy的ndarray:一种多维数组对象
-
- 新建一个ndarray数组
- ndarray的数据类型
- Numpy数组的运算
- 基本的索引和切片
- 数组属性
- 通用函数
-
- 一元函数
- 二元函数
- 关于numpy.random
- 利用数组进行数据处理
-
- 数学统计方法
- 关于数组的不同复制的对比
关于numpy
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包。⼤多数提供科学计算的包都
是⽤NumPy的数组作为构建基础。
Numpy的ndarray:一种多维数组对象
NumPy最重要的⼀个特点就是其N维数组对象(即ndarray),该对象是⼀个快速⽽灵活的⼤数据集容
器。你可以利⽤这种数组对整块数据执⾏⼀些数学运算,其语法跟标量元素之间的运算⼀样。
可以直接对这种数组进行数学运算:
看看一个简单的例子:
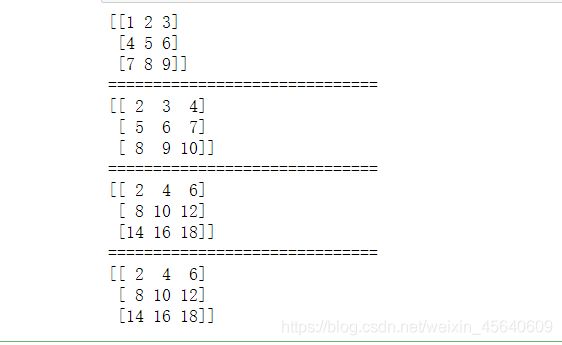
这里创建了一个数组对象(这里用了array函数,它接受一切序列型的对象),分别对数组对象整体加1,整体乘2,一个数组对象加一个数组对象:
import numpy as np
data = np.array([[1,2,3],[4,5,6],[7,8,9]])
data1 = data + 1
data2 = data * 2
data3 = data + data
print(data)
print('='*30)
print(data1)
print('='*30)
print(data2)
print('='*30)
print(data3)
结果为(这里我用jupyter编写的代码):
新建一个ndarray数组
- array:接受接受一切序列型的对象(前面例子说明了)
- zeros:创建指定长度或形状全0数组
import numpy as np
data = np.zeros(10)
data2 = np.zeros((3,6))
print(data)
print(data2)
结果:

3.ones创建指定长度或形状全1数组。(使用方法和zeros类似)
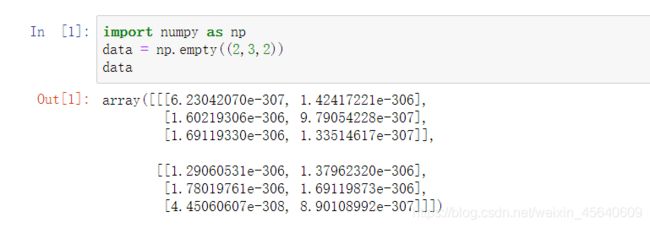
4.empty返回都是一些未初始化的垃圾值(无意义的值)
5. arange:是Python内置函数range的数组版

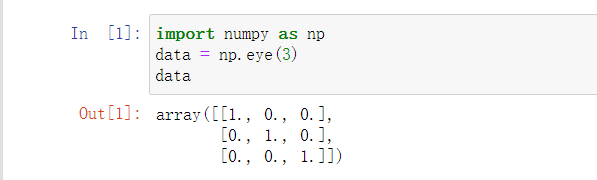
6.eye:创建一个正方的 N × N N\times N N×N单位矩阵
如下所示:
ndarray的数据类型
大致的数据类型是浮点数、复数、整数、布尔值、字符串,还是普通的Python对象。
dtype:dtype(数据类型)是⼀个特殊的对象,它含有ndarray将⼀块内存解释为特定数据类型所需的信息
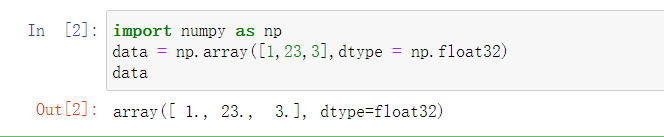
例:这里指定创建数组对象的类型也可以查看数组对象的类型
astype 将一个数组从一个dtype转化为另一个dtype
data = np.array([1,2,3])
print(data.dtype)
new_data = data.astype(np.float64)
print(new_data.dtype)
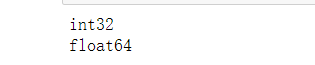
结果(从一个int32转化为float64):
Numpy数组的运算
前面我们已经看过两个数组可以相加
其实Numpy数组,它可以使你不⽤编写循环即可对数据执⾏批量运算。NumPy⽤户称其为⽮量化
(vectorization)。⼤⼩相等的数组之间的任何算术运算都会将运算应⽤到元素级
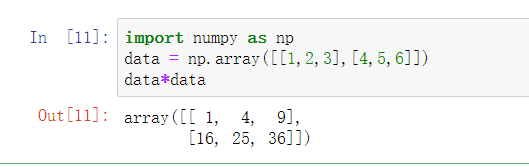
- 两个数组相乘
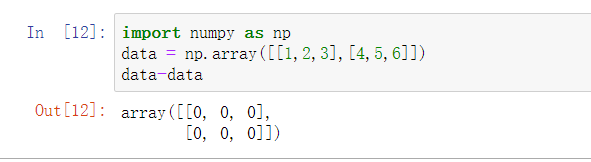
- 两个数组相减
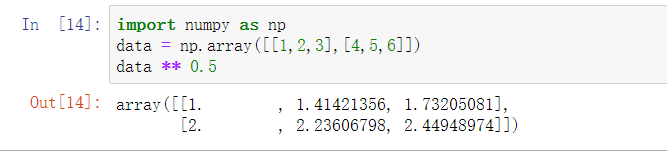
- 数组与与其他标量运算符

- ⼤⼩相同的数组之间的⽐较会⽣成布尔值数组:

基本的索引和切片
索引 :
这里展示的是一维数组和二维数组的索引
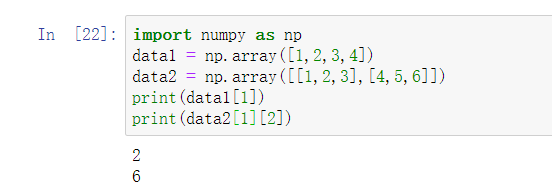
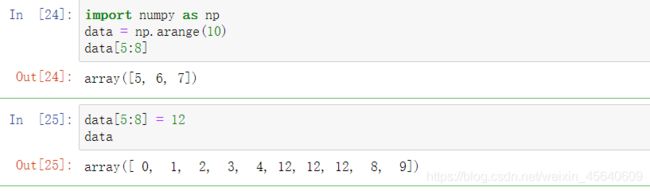
切片:。切片跟列表最重要的区别在于,数组切⽚是原始数组的视图。这意味着数据
不会被复制,视图上的任何修改都会直接反映到源数组上。
当对切片的部分进行赋值,可见将源数组也改变了
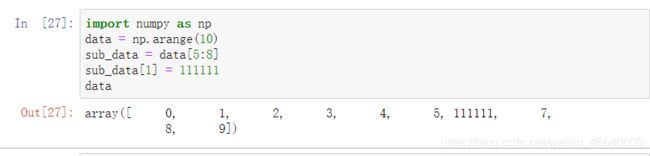
我们再来看个例子:
这里变动sub_data中的值, 原始数组中的值也发生了改变。
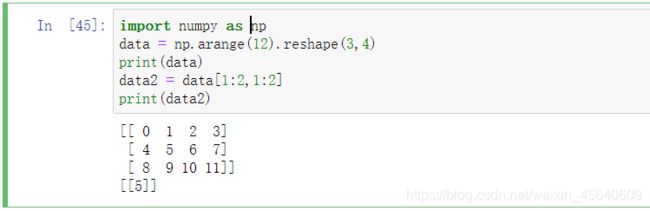
对多维数组的切片(这里以二维数组为例):
这里我们取了data的第一行
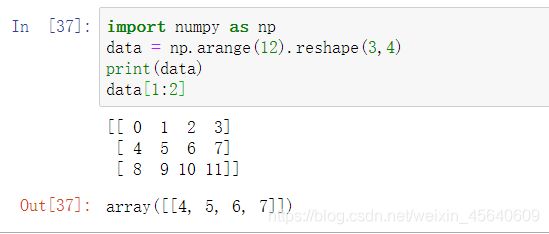
这里我同样对列也取了第一行,最后返回一个二维数组,不过它的元素只有5.
布尔型索引
这里创建了一个长度是4位的Unicode数据, 这里数组的比较运算也是矢量化的,所以结果产生一个布尔型数组,如图:
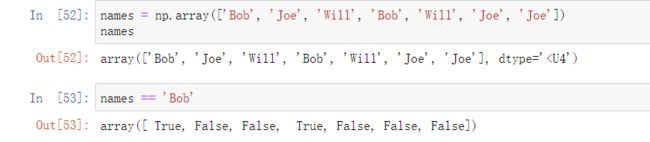
这个布尔型数组可以用来数组索引

注意:布尔型数组的⻓度必须跟被索引的轴⻓度⼀致。
** 花式索引 **:花式索引(Fancy indexing)是⼀个NumPy术语,它指的是利⽤整数数组进⾏索引

数组属性
nidm:查看数组的维度
import numpy as np
data = np.array([[1,2,3],[4,5,6],[7,8,9]])
print(data.ndim)
#2 结果
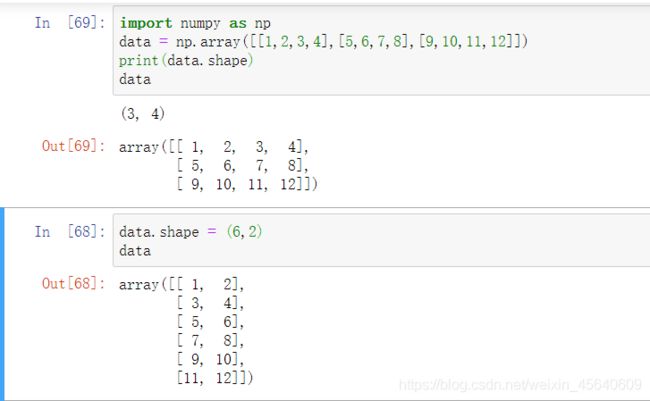
shape:返回一个包含数组维度的元组,它也可以用于调整数组大小
例如:
这里,我先打印了data.shape它返回一个元组(3,4)表示这个数组的维度,下面我又通过shape改变了这个数组的维度
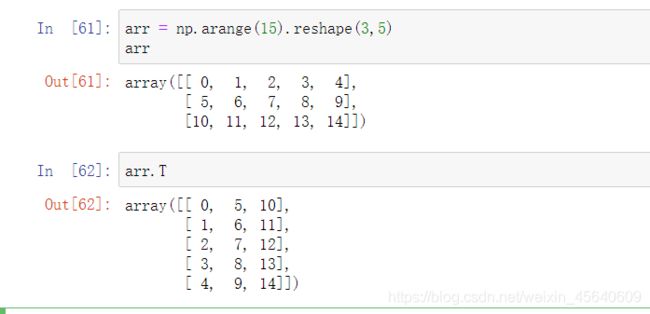
T:用于矩阵的转置
比如将一个 3 × 5 3\times 5 3×5转置成一个 5 × 3 5\times 3 5×3的矩阵
itemsize:这一数组属性返回数组中每个元素的字节单位长度。

通用函数
这里说的函数都是比较基础的
一元函数
arrange:前面例子已经说明多次了,这里就不在说明了
sqrt 和 exp:计算各元素开根号和计算各元素以 e e e为底的指数
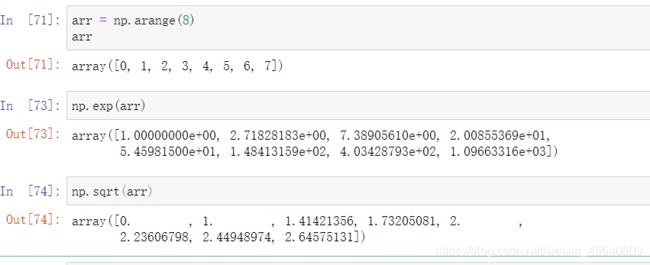
sqare:计算各元素的平方
log :计算各以底数为 e e e,类似log10,log2 ⋯ \cdots ⋯
三角函数 : cos,sin ⋯ \cdots ⋯
二元函数
dot:计算内积

add:将数组中对应的元素相加
subtract: 从第一个数组中减去第二个数组中的元素
multiply:数组元素相乘
divide、floor_divide: 除法或向下圆整除法(丢弃余数)
power: 对第一个数组中的元素 A A A,根据第二个数组中的相应元素 B B B,计算 A B A^B AB
maximum.fmax:元素级的最大值计算。
fmax将忽略NaN
minimum、fmin: 元素级的最小值计算。fmin将忽略NaN
mod:元素级的求模计算(除法的余数)
copysign:将第二个数组中的值的符号复制给第一个数组中的值
关于numpy.random
- numpy.random.rand(a1,a2, ⋯ \cdots ⋯,an):生成一个[0,1)之间的随机浮点数或N维浮点数组
例子:

- numpy.random.randn(a1,a2, ⋯ \cdots ⋯,an):生成一个浮点数或N维浮点数组,范围:正态分布的随机样本数

- numpy.random.randint(low, high, size):在指定范围返回随机的整数,size用来确定维度
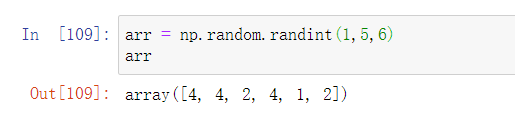
- numpy.random.choice(a):从序列中获取元素,若a只是一个整数,则从range(a)中选择

利用数组进行数据处理
NumPy数组使你可以将许多种数据处理任务表述为简洁的数组表达式(否则需要编写循环)。⽤数组
表达式代替循环的做法,通常被称为⽮量化。
np.meshgrid函数:
接受两个⼀维数组,并产⽣两个⼆维矩阵
效果:

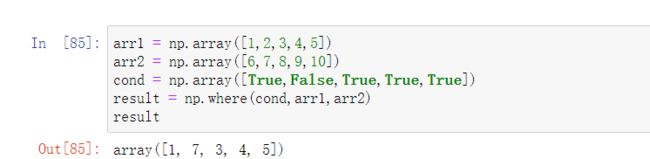
numpy.where函数
三元表达式x if condition else y的⽮量化版本。
看例子,若cond中元素为真, 那么就选择arr1的元素
数学统计方法
sum :对数组中全部或某轴向的元素求和。零长度的数组的sum为0

mean:算术平均数。零长度的数组的mean为NaN

std、var:分别为标准差和方差,自由度可调(默认为n)

min、max:最大值和最小值

argmin、argmax:分别为最大和最小元素的索引

sort():就地排序,可以接受轴的编号

关于数组的不同复制的对比
先看一个例子:
这里让b=a,其实在内存解析上把a的指向地址赋给b,就是b也指向和a指向相同的地址,b发生改变, a当然也要改变

view() : view相当于传引用,view和原始数据共享一份数据,修改一个会影响另一个。
这里a和b的指向地址不同,但是它们指向的数组用的是同样的值。b指向数组中的值改变,a中也改变
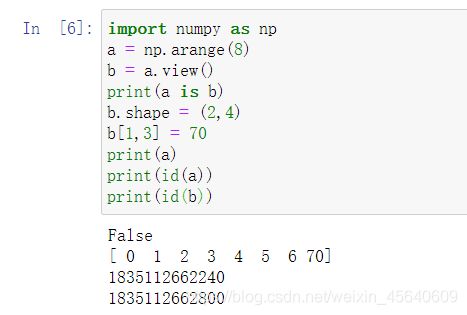
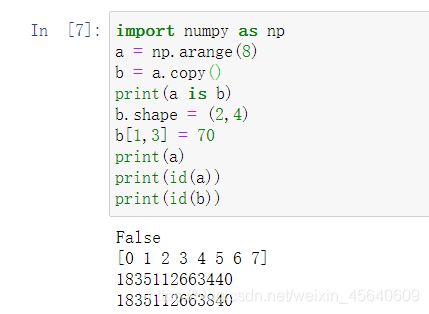
copy(): copy()和view()就不一样了,a,b两者就不会相互影响了
说明:参考书籍《利用python进行数据分析》
附上资源:链接:https://pan.baidu.com/s/1ftY0tirS7lyAG4uV-cIu_g
提取码:l5xs (无效在评论区说下)
喜欢就点个赞吧