循环链表
链表的两头连接,形成了一个环状链表,称为循环链表。

实际应用:约瑟夫环问题
约瑟夫环问题,是一个经典的循环链表问题,题意是:已知 n 个人(以编号1,2,3,…,n分别表示)围坐在一张圆桌周围,从编号为 k 的人开始顺时针报数,数到 m 的那个人出列;他的下一个人又从 1 还是顺时针开始报数,数到 m 的那个人又出列;依次重复下去,要求找到最后出列的那个人。
例如有 5 个人,要求从编号为 3 的人开始,数到 2 的那个人出列:
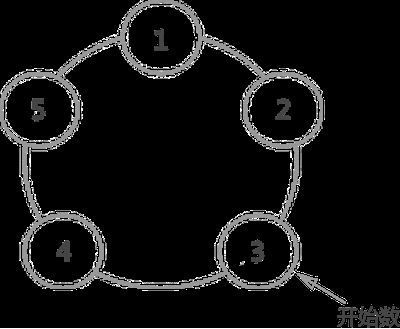
出列顺序依次为:
编号为 3 的人开始数 1,然后 4 数 2,所以 4 先出列;
4 出列后,从 5 开始数 1,1 数 2,所以 1 出列;
1 出列后,从 2 开始数 1,3 数 2,所以 3 出列;
3 出列后,从 5 开始数 1,2 数 2,所以 2 出列;
最后只剩下 5 自己,所以 5 出列。
#include
typedef struct node{
int number;
struct node * next;
}person;
person * initLink(int n){
person * head=(person*)malloc(sizeof(person));
head->number=1;
head->next=NULL;
person * cyclic=head;
int i;
for (i=2; i<=n; i++) {
person * body=(person*)malloc(sizeof(person));
body->number=i;
body->next=NULL;
cyclic->next=body;
cyclic=cyclic->next;
}
cyclic->next=head;//首尾相连
return head;
}
void findAndKillK(person * head,int k,int m){
person * tail=head;
//找到链表第一个结点的上一个结点,为删除操作做准备
while (tail->next!=head) {
tail=tail->next;
}
person * p=head;
//找到编号为k的人
while (p->number!=k) {
tail=p;
p=p->next;
}
//从编号为k的人开始,只有符合p->next==p时,说明链表中除了p结点,所有编号都出列了,
while (p->next!=p) {
int i;
//找到从p报数1开始,报m的人,并且还要知道数m-1de人的位置tail,方便做删除操作。
for (i=1; inext;
}
tail->next=p->next;//从链表上将p结点摘下来
printf("出列人的编号为:%d\n",p->number);
free(p);
p=tail->next;//继续使用p指针指向出列编号的下一个编号,游戏继续
}
printf("出列人的编号为:%d\n",p->number);
free(p);
}
int main() {
printf("输入圆桌上的人数n:");
int n;
scanf("%d",&n);
person * head=initLink(n);
printf("从第k人开始报数(k>1且k<%d):",n);
int k;
scanf("%d",&k);
printf("数到m的人出列:");
int m;
scanf("%d",&m);
findAndKillK(head, k, m);
return 0;
}

循环链表和动态链表唯一不同在于它的首尾连接,这也注定了在使用循环链表时,附带的最多的操作就是遍历链表。在遍历的过程中,尤其要注意循环链表虽然首尾相连,但并不表示该链表没有第一个节点和最后一个结点。所以,不要随意改变头指针的指向。
双向(循环)链表
整个链表只能单方向从表头访问到表尾,这种结构的链表统称为 “单向链表”或“单链表”。
如果算法中需要频繁地找某结点的前趋结点,单链表的解决方式是遍历整个链表,增加算法的时间复杂度,影响整体效率。
为了快速便捷地解决这类问题,在单向链表的基础上,给各个结点额外配备一个指针变量,用于指向每个结点的直接前趋元素。这样的链表被称为“双向链表”或者“双链表”。
双链表中的结点
双向链表中的结点有两个指针域,一个指向直接前趋,一个指向直接后继。(链表中第一个结点的前趋结点为NULL,最后一个结点的后继结点为NULL)

结点的具体构成:
typedef struct line{
struct line * prior; //指向直接前趋
int data;
struct line * next; //指向直接后继
}line;
创建双向链表并初始化
双向链表创建的过程中,每一个结点需要初始化数据域和两个指针域,一个指向直接前趋结点,另一个指向直接后继结点。
创建一个双向链表line(1,2,3):
line* initLine(line * head){
head=(line*)malloc(sizeof(line));//创建链表第一个结点(首元结点)
head->prior=NULL;
head->next=NULL;
head->data=1;
line * list=head;
int i;
for (i=2; i<=3; i++) {
//创建并初始化一个新结点
line * body=(line*)malloc(sizeof(line));
body->prior=NULL;
body->next=NULL;
body->data=i;
list->next=body;//直接前趋结点的next指针指向新结点
body->prior=list;//新结点指向直接前趋结点
list=list->next;
}
return head;
}
双向链表中插入结点
比如在(1,2,3)中插入一个结点 4,变成(1,4,2,3)。
实现效果图:
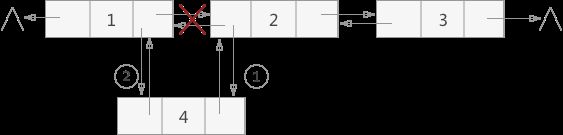
在双向链表中插入数据时,首先完成图中标注为 1 的两步操作,然后完成标注为 2 的两步操作;反之,如果先完成 2,就无法通过头指针访问结点 2,需要额外增设指针,虽然能实现,但较前一种麻烦。
line * insertLine(line * head,int data,int add){
//新建数据域为data的结点
line * temp=(line*)malloc(sizeof(line));
temp->data=data;
temp->prior=NULL;
temp->next=NULL;
//插入到链表头,要特殊考虑
if (add==1) {
temp->next=head;
head->prior=temp;
head=temp;
}else{
line * body=head;
//找到要插入位置的前一个结点
int i;
for (i=1; inext;
}
//判断条件为真,说明插入位置为链表尾
if (body->next==NULL) {
body->next=temp;
temp->prior=body;
}else{
body->next->prior=temp;
temp->next=body->next;
body->next=temp;
temp->prior=body;
}
}
return head;
}
双向链表中删除节点
双链表删除结点时,直接遍历链表,找到要删除的结点,然后利用该结点的两个指针域完成删除操作。
在(1,4,2,3)中删除结点 2:
//删除结点的函数,data为要删除结点的数据域的值
line * delLine(line * head,int data){
line * temp=head;
//遍历链表
while (temp) {
//判断当前结点中数据域和data是否相等,若相等,摘除该结点
if (temp->data==data) {
temp->prior->next=temp->next;
temp->next->prior=temp->prior;
free(temp);
return head;
}
temp=temp->next;
}
printf("链表中无该数据元素");
return head;
}
双向链表中的查找和更改操作
双向链表的查找操作和单链表的实现方法完全一样,从链表的头结点或者首元结点开始遍历,这里不做过多解释。
更改链表中某结点的数据域的操作是在查找的基础上完成的。通过遍历找到存储有该数据元素的结点后,直接更改其数据域就可以。
代码整合
#include
#include
typedef struct line{
struct line * prior;
int data;
struct line * next;
}line;
line* initLine(line * head);
line * insertLine(line * head,int data,int add);
line * delLine(line * head,int data);
void display(line * head);
int main() {
line * head=NULL;
head=initLine(head);
head=insertLine(head, 4, 2);
display(head);
head=delLine(head, 2);
display(head);
return 0;
}
line* initLine(line * head){
head=(line*)malloc(sizeof(line));
head->prior=NULL;
head->next=NULL;
head->data=1;
line * list=head;
int i;
for (i=2; i<=3; i++) {
line * body=(line*)malloc(sizeof(line));
body->prior=NULL;
body->next=NULL;
body->data=i;
list->next=body;
body->prior=list;
list=list->next;
}
return head;
}
line * insertLine(line * head,int data,int add){
//新建数据域为data的结点
line * temp=(line*)malloc(sizeof(line));
temp->data=data;
temp->prior=NULL;
temp->next=NULL;
//插入到链表头,要特殊考虑
if (add==1) {
temp->next=head;
head->prior=temp;
head=temp;
}else{
line * body=head;
//找到要插入位置的前一个结点
int i;
for (i=1; inext;
}
//判断条件为真,说明插入位置为链表尾
if (body->next==NULL) {
body->next=temp;
temp->prior=body;
}else{
body->next->prior=temp;
temp->next=body->next;
body->next=temp;
temp->prior=body;
}
}
return head;
}
line * delLine(line * head,int data){
line * temp=head;
//遍历链表
while (temp) {
//判断当前结点中数据域和data是否相等,若相等,摘除该结点
if (temp->data==data) {
temp->prior->next=temp->next;
temp->next->prior=temp->prior;
free(temp);
return head;
}
temp=temp->next;
}
printf("链表中无该数据元素");
return head;
}
//输出链表的功能函数
void display(line * head){
line * temp=head;
while (temp) {
if (temp->next==NULL) {
printf("%d\n",temp->data);
}else{
printf("%d->",temp->data);
}
temp=temp->next;
}
}
如果问题中需要频繁的调取当前结点的前趋结点,那使用双向链表的数据结构为最佳。
双向循环链表
其实就是双向链表和循环链表的结合体
例如:约瑟夫环问题其实还可以这样玩:如果顺时针报数,有人出列后,顺时针找出出列位置的下一个人,开始反方向(也就是逆时针)报数,有人出列后,逆时针找出出列位置的下一个人,开始顺时针报数。依次重复,直至最后一个出列。
有兴趣可以自行尝试,这里就不再分析了,因为本质就是双向链表和循环链表。