数据驱动分析实践八 - 提升模型
数据驱动分析实践八
提升模型
当我们在处理增长相关的问题时,一个非常重要的关键因素就是效率。第一,我们需要提高时间效率,这意味着快速的构思、实践、学习和迭代;第二就是成本,在同样的预算、时间和付出下获得做大收益。
用户分段可以帮助提升转化率和降低成本。但是想想一下假如需要推行一个营销活动,你也确定了目标用户分段,你是否需要把优惠给其中的每一个客户?
一般情况下,答案是否定的。在你的目标用户组中,肯定存在一些客户无论是否有优惠策略都会购买的。按照这种思路,我们来总结一下这些用户分段:
- 方案响应者:优惠方案会使这些客户购买
- 方案无响应者:是否购买和优惠方案无关
- 控制响应者:即使没有优惠方案也会购买
- 控制非响应者:如果没有优惠方案就不会购买
我们的目标应该是针对方案响应者(TR,Treadment Responder)和控制非响应者(CN,Control Non Responder)。对于这两个组中的客户,如果你不提供优惠策略,他们就不会购买。另外你需要避免针对方案无响应者(TN,Treatment Non Responder)和控制响应者(CR,Control Responder),因为给与这些客户优惠策略不会为你带来好处。
所以我们需要分辨这四个组的客户,方法就是提升模型(Uplift Modeling),它有两个步骤:
预测每个客户属于哪一个组;一般来说,这一步需要建立一个多分类。
计算提升分数,公式如下:
= + − − =+−− UpliftScore=PTR+PCN−PTN−PCR
分数越高说明提升能力越高
提升模型
现在我们就用python来实施这个模型。
导入必要的库
from __future__ import division
from datetime import datetime, timedelta,date
import pandas as pd
%matplotlib inline
from sklearn.metrics import classification_report,confusion_matrix
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
from sklearn.cluster import KMeans
import chart_studio.plotly as py
import plotly.offline as pyoff
import plotly.graph_objs as go
import sklearn
import xgboost as xgb
from sklearn.model_selection import KFold, cross_val_score, train_test_split
import warnings
warnings.filterwarnings("ignore")
#initiate plotly
pyoff.init_notebook_mode()
定义和封装所需的功能函数
#function to order clusters
def order_cluster(cluster_field_name, target_field_name,df,ascending):
new_cluster_field_name = 'new_' + cluster_field_name
df_new = df.groupby(cluster_field_name)[target_field_name].mean().reset_index()
df_new = df_new.sort_values(by=target_field_name,ascending=ascending).reset_index(drop=True)
df_new['index'] = df_new.index
df_final = pd.merge(df,df_new[[cluster_field_name,'index']], on=cluster_field_name)
df_final = df_final.drop([cluster_field_name],axis=1)
df_final = df_final.rename(columns={"index":cluster_field_name})
return df_final
#function for calculating the uplift
def calc_uplift(df):
avg_order_value = 25
#calculate conversions for each offer type
base_conv = df[df.offer == 'No Offer']['conversion'].mean()
disc_conv = df[df.offer == 'Discount']['conversion'].mean()
bogo_conv = df[df.offer == 'Buy One Get One']['conversion'].mean()
#calculate conversion uplift for discount and bogo
disc_conv_uplift = disc_conv - base_conv
bogo_conv_uplift = bogo_conv - base_conv
#calculate order uplift
disc_order_uplift = disc_conv_uplift * len(df[df.offer == 'Discount']['conversion'])
bogo_order_uplift = bogo_conv_uplift * len(df[df.offer == 'Buy One Get One']['conversion'])
#calculate revenue uplift
disc_rev_uplift = disc_order_uplift * avg_order_value
bogo_rev_uplift = bogo_order_uplift * avg_order_value
print('Discount Conversion Uplift: {0}%'.format(np.round(disc_conv_uplift*100,2)))
print('Discount Order Uplift: {0}'.format(np.round(disc_order_uplift,2)))
print('Discount Revenue Uplift: ${0}'.format(np.round(disc_rev_uplift,2)))
print('Revenue Uplift Per Targeted Customer: ${0}\n'\
.format(np.round(disc_rev_uplift/len(df[df.offer == 'Discount']['conversion']),2)))
if len(df[df.offer == 'Buy One Get One']['conversion']) > 0:
print('-------------- \n')
print('BOGO Conversion Uplift: {0}%'.format(np.round(bogo_conv_uplift*100,2)))
print('BOGO Order Uplift: {0}'.format(np.round(bogo_order_uplift,2)))
print('BOGO Revenue Uplift: ${0}'.format(np.round(bogo_rev_uplift,2)))
print('BOGO Revenue Uplift Per Targeted Customer: ${0}\n'\
.format(np.round(bogo_rev_uplift/len(df[df.offer == 'Buy One Get One']['conversion']),2)))
导入数据
使用的上一篇文章同样的数据。
#import the data
df_data = pd.read_csv('response_data.csv')
#print first 10 rows
df_data.head(10)
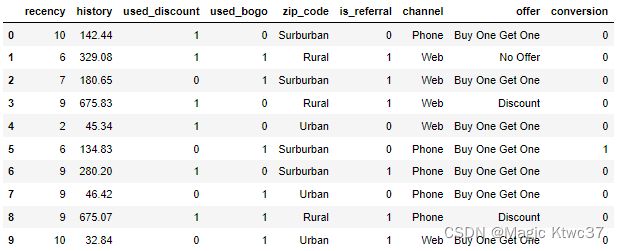
回想上一篇中的内容,我们的数据中包含收到打折策略和买一送一的客户和他们如何响应。我们还有一个控制组没有接收任何优惠策略。
数据字段解释如下:
- recency:上一次购买距今的月数
- history:历史购买价值($)
- used_discount/used_bogo:客户是否使用过折扣和买一送一优惠策略
- zip_code:区域
- if_referal:客户是否是从导流渠道获得
- channel:用户接入方式
- offer:给用户的优惠策略
应用模型之前,我们先计算一下现在的提升评分作为参考基准。
calc_uplift(df_data)

打折转化率提升为7.66%,买一送一提升为4.52%。 下面我们将建立提升模型。
多分类模型
数据中的标签是客户是否转化(0 或者 1),我们需要创建四个分组TR\TN\CR\CN。我们知道客户接受打折或者买一送一(bogo)是优惠方案接受者(Treatment),其他的是控制者(Control),我们新建一个列来标识这一点。
df_data['campaign_group'] = 'treatment'
df_data.loc[df_data.offer == 'No Offer', 'campaign_group'] = 'control'
现在我们创建新的标签。
df_data['target_class'] = 0 #CN
df_data.loc[(df_data.campaign_group == 'control') & (df_data.conversion > 0),'target_class'] = 1 #CR
df_data.loc[(df_data.campaign_group == 'treatment') & (df_data.conversion == 0),'target_class'] = 2 #TN
df_data.loc[(df_data.campaign_group == 'treatment') & (df_data.conversion > 0),'target_class'] = 3 #TR
0 -> Control Non-Responders
1 -> Control Responders
2 -> Treatment Non-Responders
3 -> Treatment Responders
模型训练之前,我们还需要做一点特征工程的工作。我们会从history来创建聚类,使用get_dummies把分类变量转化为数值。
#creating the clusters
kmeans = KMeans(n_clusters=5)
kmeans.fit(df_data[['history']])
df_data['history_cluster'] = kmeans.predict(df_data[['history']])#order the clusters
df_data = order_cluster('history_cluster', 'history',df_data,True)#creating a new dataframe as model and dropping columns that defines the label
df_model = df_data.drop(['offer','campaign_group','conversion'],axis=1)#convert categorical columns
df_model = pd.get_dummies(df_model)
应用模型并得到每一个分组的概率。
#create feature set and labels
X = df_model.drop(['target_class'],axis=1)
y = df_model.target_class#splitting train and test groups
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=56)#fitting the model and predicting the probabilities
xgb_model = xgb.XGBClassifier().fit(X_train, y_train)
class_probs = xgb_model.predict_proba(X_test)
class_probs[0]
array([0.33018395, 0.01280369, 0.597153 , 0.05985933], dtype=float32)
对于这个客户来说,概率如下,
CN: 32% CR: 2% TN: 58.9% TR: 6.9%
所以这个客户的提升分数为
0.32 + 0.069 − 0.02 − 0.589 = − 0.22 0.32+0.069−0.02−0.589=−0.22 0.32+0.069−0.02−0.589=−0.22
我们对所有客户计算提升分数
#probabilities for all customers
overall_proba = xgb_model.predict_proba(df_model.drop(['target_class'],axis=1))#assign probabilities to 4 different columns
df_model['proba_CN'] = overall_proba[:,0]
df_model['proba_CR'] = overall_proba[:,1]
df_model['proba_TN'] = overall_proba[:,2]
df_model['proba_TR'] = overall_proba[:,3]#calculate uplift score for all customers
df_model['uplift_score'] = df_model.eval('proba_CN + proba_TR - proba_TN - proba_CR')#assign it back to main dataframe
df_data['uplift_score'] = df_model['uplift_score']
df_data.head()
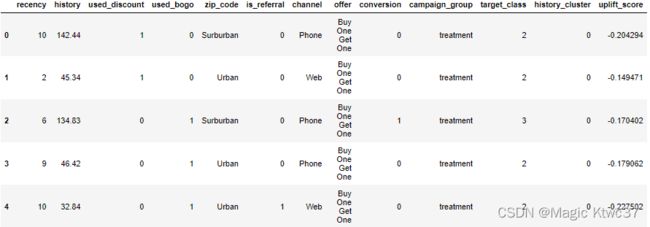
现在到了一个最重要的时刻,这个模型真的可以工作吗?实际上,评价提升模型的性能有一点困难。我们要检查提升是如何改变提升的分数的,主要针对分位数。
模型评价
我们会建立两个不同的组,把他们与我们的参考基准进行比较,
- 高提升分数:客户的提升分数 > 3分位数
- 低提升分数:客户的提升分数 < 2分位数
我们将会比较 - 转换率提升
- 收益提升(每个目标客户)
打折的参考基准如下:
Total Targeted Customer Count: 21307
Discount Conversion Uplift: 7.66%
Discount Order Uplift: 1631.89
Discount Revenue Uplift: 40797.35
Revenue Uplift Per Targeted Customer: 1.91
创建第一个组:
df_data_lift = df_data.copy()
uplift_q_75 = df_data_lift.uplift_score.quantile(0.75)
df_data_lift = df_data_lift[(df_data_lift.offer != 'Buy One Get One') & (df_data_lift.uplift_score > uplift_q_75)].reset_index(drop=True)#calculate the uplift
calc_uplift(df_data_lift)
Discount Conversion Uplift: 12.55%
Discount Order Uplift: 661.51
Discount Revenue Uplift: $16537.67
Revenue Uplift Per Targeted Customer: $3.14
结果不错,每个用户的收益提升了57%。
再检查一下低分组
df_data_lift = df_data.copy()
uplift_q_5 = df_data_lift.uplift_score.quantile(0.5)
df_data_lift = df_data_lift[(df_data_lift.offer != 'Buy One Get One') & (df_data_lift.uplift_score < uplift_q_5)].reset_index(drop=True)#calculate the uplift
calc_uplift(df_data_lift)
Discount Conversion Uplift: 5.45%
Discount Order Uplift: 588.78
Discount Revenue Uplift: $14719.42
Revenue Uplift Per Targeted Customer: $1.36
符合预期,每个目标用户的收益下降到了1.36。
总结
通过应用这个模型,我们可以是我们的营销策略更加高效,主要是依靠:
基于提升分数来锁定目标客户组
基于提升分数来尝试不同的优惠策略
下一篇文章,我们将讨论数据驱动增长的一个核心元素:A/B测试。
未完待续,…