- commons-fileupload框架源码解析(一)--实例
- commons-fileupload框架源码解析(二)--HTTP
- commons-fileupload框架源码解析(三)--ParseRequest
- commons-fileupload框架源码解析(四)--FileItemIterator
- commons-fileupload框架源码解析(五)--MultipartStream
- commons-fileupload框架源码解析(六)--ParameterParser
- commons-fileupload框架源码解析(七)--FileCleaningTracker
- commons-fileupload框架源码解析(八)--DeferredFileOutputStream
前言
在FileItemIteratorImpl上,其实在读取解析主体文本这一块,是交给了MultipartStream进行处理,FileItemIteratorImpl更准确的说,是将MultipartStream读取到的内容,封装成FileItemStream.所以要想知道commons-Fileupload是如何读取主体文本的,就需要深入了解MultipartStream的代码,而MultipartStream,也是这个框架的中最难深入,最容易混乱,我当时花最长的解读时间也是在MultipartStream,深有体会,尤其是在调试一步一步的每行代码时,因为MultipartStream由于直接操作的是字节,所以很难理解每一步在干什么,为什么要这样做。
另外,我是根据程序一步一步执行下去的方式,遇到那个方法就解释那个方法,这样可能会导致读者的混乱,所以,我建议下载这个框架源码,一边看我的博客,一步一步的调试,遇到不懂的方法,在本文中搜索一下位置,我已经尽力在代码块上写上备注,以便理解,如果单纯看我这篇文章,肯定是看得想吐。
HttpServletRequest.getInputStream
在解析源码之前,我们想看看HttpServletRequest.getInputStream里面有什么内容,因为MultipartStream的读取解析工作都是对HttpServletRequest.getInputStream的内容进行开展的,如果不了解HttpServletRequest.getInputStream里面的内容,光看源码,调试,是非常困难的事情。内容我以截图的方式弄出来
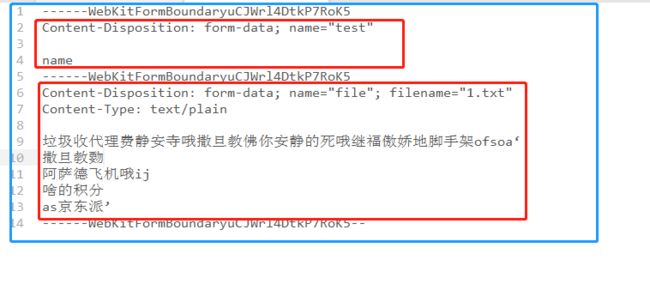
说明一下:
蓝色框就是主体内容
红色框的就是参数内容
------WebKitFormBoundaryuCJWrl4DtkP7RoK5就是分割线,主体文本的最后一条分割线后面会多两个'-'
源码
MultipartStream构造方法
public MultipartStream(InputStream input,
byte[] boundary,
int bufSize,//默认是4096字节
ProgressNotifier pNotifier) {
if (boundary == null) {
throw new IllegalArgumentException("boundary may not be null");
}
// We prepend CR/LF to the boundary to chop trailing CR/LF from
// body-data tokens.
this.boundaryLength = boundary.length + BOUNDARY_PREFIX.length;//各个数据内容之间的分隔界线的组成: CR+LF+两个'-'+从消息头Content-Type找到boundary的值
//因为在查找分割接线的操作是在缓存区buffer中进行查找到,所以bufSize必须起码能装得分割线的所有字节
if (bufSize < this.boundaryLength + 1) {
throw new IllegalArgumentException(
"The buffer size specified for the MultipartStream is too small");
}
this.input = input;//HttpServletRequest的流,流的数据就是主体文本
this.bufSize = Math.max(bufSize, boundaryLength * 2);//框架认为bufSize越大越好,毕竟这个读取主体内容的速度,和解析、查询效率
this.buffer = new byte[this.bufSize];
this.notifier = pNotifier;
this.boundary = new byte[this.boundaryLength];
this.boundaryTable = new int[this.boundaryLength + 1];//KMP算法的前缀表
this.keepRegion = this.boundary.length;//在buffer中预留的分割线字节数
//将成员变量boundary赋值,首先将BOUNDARY_PREFIX的元素复制到成员变量boundary的开头,再将参数boundary的元素复制成员变量boundary剩下的元素
//即\r\n------WebKitFormBoundary7MA4YWxkTrZu0gW
System.arraycopy(BOUNDARY_PREFIX, 0, this.boundary, 0,
BOUNDARY_PREFIX.length);
System.arraycopy(boundary, 0, this.boundary, BOUNDARY_PREFIX.length,
boundary.length);
computeBoundaryTable();//计算出分割线的KMP算法前缀表
head = 0;//读取buffer的开始位置,0<=head<=buffer.length
tail = 0;//读取buffer的结束位置,0<=head<=buffer.length
}
这里就是对需要用到的成员变量进行初始化,值得注意的是,MultipartStream在buffer中查询分割线boundary是采用KMP算法,不算KMP算法的读者,请先去了解一下KMP算法。computeBoundaryTable()就是用于计算KMP算法所需的boundary前缀表
SkipPreamble
在开始读取主体文本的第一步是调用skipPreamble方法,参照UploadFileBase.parseRequest(RequestContext)
public boolean skipPreamble() throws IOException {
// First delimiter may be not preceeded with a CRLF.
//去掉前面的‘\n’和‘\r’这两个字节,因为第一个分割线前面没有回车换行符,无法与成员变量boundary中的数据相匹配
System.arraycopy(boundary, 2, boundary, 0, boundary.length - 2);
boundaryLength = boundary.length - 2;
computeBoundaryTable();//计算出分割线的KMP算法前缀表
try {
// Discard all data up to the delimiter.
//丢掉第一个分隔界线符前数据,一般是没有的,如果有就是一些注释数据的数据
// 按照MIME规范,消息头和消息体之间的分隔界线前面可以有一些作为注释信息的内容
discardBodyData();
// Read boundary - if succeeded, the stream contains an
// encapsulation.
return readBoundary();
} catch (MalformedStreamException e) {
return false;
} finally {
// Restore delimiter.
//成员变量boundary恢复回原来的样子,并重新计算成员变量boundary的KMP算法前缀表
System.arraycopy(boundary, 0, boundary, 2, boundary.length - 2);
boundaryLength = boundary.length;
boundary[0] = CR;
boundary[1] = LF;
computeBoundaryTable();//计算出分割线的KMP算法前缀表
}
}
在这里,我先不急着去说明skipPreamble的作用,而是先进入discardBodyData()看看
discardBodyData
public int discardBodyData() throws MalformedStreamException, IOException {
return readBodyData(null);//
}
从方法名中,可以看出该方法用于丢弃没有的数据,如,按 照MIME规范,消息头和消息体之间的分隔界线前面可以有一些作为注释信息的内容。其实现的方式是调用readBodyData(OutputStream)。
readBodyData(OutputStream)
public int readBodyData(OutputStream output)
throws MalformedStreamException, IOException {
//Streams.copy(InputStrea,OutputStream,closeOuputStream):将输入流数据传到输出流中,如果输入流为null,
// 则只进行对输入流的读取,而不会讲读取的数据传给输出流,closeOuptStream表示是否关闭输出流
// 这返回已经写入的字节数,如果传入的是输出流为null的话,则这里表示已经读取的字节数
return (int) Streams.copy(newInputStream(), output, false); // N.B. Streams.copy closes the input stream
}
这里要注意一下,readBodyData返回的是已经写入的字节数,但是如果传入的输出流为null,则返回已经读取的字节数。事实上,从源码可以看到,Streams.copy计算数量是在对每次输入流读取的字节数累加的,而不是对每次输输出流输出的字节数累加,所以,Streams.copy更准确的说返回的是已经读取的字节数。
在readBoyData中,我们看到调用了newInputStream()
newInputStream
ItemInputStream newInputStream() {
return new ItemInputStream();
}
又是内部类,交给ItemInputStream,ItemInputStream是继承了InputStream的MultipartStream内部了,实现读取主体文本中的参数内容的相关操作,这里我需要先说明一下ItemInputStream是如何读取主体文本中的参数内容。
ItemInputStream读取参数内容的操作解析
从图1可以看出,主体文本的组成就是分割线+参数内容,所以我们要准确地读取到参数内容,需要确定好分割线的起始位置,分割线的长度。但是在读取过程,因为主体文本一般都比较大,只能通过一个缓存区buffer来分段读取,也就造成了一个问题,无法确定那里是分割线,因为buffer有可能完全将分割线的字节读取了,也有可能只读取了分割线的部分字节,也有可能完全没有读取到分割线的字节,所以MultipartStream定义了三个成员变量:buffer读取的开始位置head,buffer读取的最后一个位置tail,还有保留分割线字节数pad,在读取buffer的数据时,以head作为开始读取的游标,以tail做为读取buffer的结束位置,而pad,会在buffer中没有找到分割线时候,保留buffer的最后pad个的字节,在下一次的从主体内容的流中读取到buffer的时候,会先将原buffer中最后pad个字节放到buffer的前面,再填充剩下的buffer字节,从而精确的读到参数内容。
具体实现,来看源码:
ItemInputStream构造方法
ItemInputStream() {
findSeparator();
}
调用了查询分割线的方法,我们再进去看看
ItemInputStream.findSeparator()
private void findSeparator() {
pos = MultipartStream.this.findSeparator();
if (pos == -1) {//缓冲区buffer中没有包含分隔界线
//读取的数据量是否大于保留区的大小,来决定保留到下一次buffer缓冲区中的字节个数
if (tail - head > keepRegion) {
pad = keepRegion;//大于保留区,取保留区大小
} else {
pad = tail - head;//小于保留区,取所有数据量
}
}
}
当在buffer中,没有找到分割线,pad将会被赋值,keepRegion就是分割线的字节数。来看看MutlitpartStream.findSeparator的实现
protected int findSeparator() {
int bufferPos = this.head;
int tablePos = 0;
//KMP算法
while (bufferPos < this.tail) {
while (tablePos >= 0 && buffer[bufferPos] != boundary[tablePos]) {
tablePos = boundaryTable[tablePos];
}
bufferPos++;
tablePos++;
if (tablePos == boundaryLength) {
return bufferPos - boundaryLength;//通过减去分割线的长度就能得到分割线在buffer的起始位置
}
}
return -1;
}
可以看到,是buffer中进行查找分割线,而查询的起始位置是head,使用的查询方法是KMP算法,而返回的就是分割线的在buffer中的起始位置
ItemInputStream.read(Byte[],int,int)
@Override
public int read(byte[] b, int off, int len) throws IOException {
if (closed) {//判断流是否已经关闭
throw new FileItemStream.ItemSkippedException();
}
if (len == 0) {
return 0;
}
int res = available();//返回有效字节数
if (res == 0) {
res = makeAvailable();//读取更多字节到buffer中,并返回有效字节数
if (res == 0) {
return -1;
}
}
res = Math.min(res, len);
System.arraycopy(buffer, head, b, off, res);
head += res;
total += res;
return res;
}
先用available来查看buffer有没有数据可以读取,如果没有通过makeAvailable从主体文本inputStream中读取进buffer中。我们先进去看看available
public int available() throws IOException {
if (pos == -1) {//未找到分割线
//buffer中的有效字节数=buffer中可读的最后一个字节位置-buffer中已读的字节数head-减去去保留区后的数据量pad
return tail - head - pad;
}
//找到分割线的情况下:buffer中的有效字节数=buffer中分割线的开始位置-buffer中已读的字节数head
return pos - head;//返回分割线前面的数据量
}
该方法就是返回在buffer中还可以读的字节数,即buffer中的有效字节数。
ItemInputStream.makeAvailable
private int makeAvailable() throws IOException {
if (pos != -1) {
return 0;//在buffer中找到了分割线,就意味着已经读取完一个参数内容,所以没必要读取下去。
}
// Move the data to the beginning of the buffer.
//total 是统计已处理的字节数
// tail-head-pad一般情况下都会是得出的结果都是0,因为head在调用read的相关方法的时候会累加已读去的字节数,使得head越来越逼近tail
// 当时又不会超过tail-pad的范围
total += tail - head - pad;
//将上一次buffer缓冲区中的未处理的数据转移到下一次buffer缓冲区的开始位置
System.arraycopy(buffer, tail - pad, buffer, 0, pad);
// Refill buffer with new data.
head = 0;
tail = pad;//因为这个时候的buffer已经将上一次pad个字节放到buffer的开头,所以tail要从pad开始,再通过下面的循环累加下去。
for (;;) {
int bytesRead = input.read(buffer, tail, bufSize - tail);//再读取buffer缓冲区剩下的数据量
if (bytesRead == -1) {
// The last pad amount is left in the buffer.
// Boundary can't be in there so signal an error
// condition.
final String msg = "Stream ended unexpectedly";
throw new MalformedStreamException(msg);
}
if (notifier != null) {
notifier.noteBytesRead(bytesRead);
}
tail += bytesRead;
findSeparator();//再次查找看看有没有分割线在buffer中,并确定保留的字节数pad的值
int av = available();
if (av > 0 || pos != -1) {
return av;//返回有效的字节数
}
}
}
该方法就是从主体文本中读取剩下的字节给buffer重新填充,填充之前,会先将上一次buffer的保留字节数挪到这次buffer的前面,然后将读取主体文本的字节填充到buffer剩下的元素。该方法还会调用findSeparator确定好分割线的开始位置,并返回调用available返回有效的字节数。
readBoundary
回到MultipartStream.skipPreamble方法上,除了调用discardBodayDat之外,还调用了readBoundary
public boolean readBoundary()
throws FileUploadIOException, MalformedStreamException {
byte[] marker = new byte[2];
boolean nextChunk = false;
head += boundaryLength;//通过对head游标加上分割线长度,使得head游标跳过分割线的数据,
try {
//虽然已经跳过了分割线的数据字节,但是分割线后面还跟着一个回车换行,通过readByte逐个读取处理
//然后判断是否真的是回车换行还是两个'-',
// 如果是回车换行,表示分隔界线是下一个分区的开始标记,返回true
// 如果是两个'-',返回false,表示已经到了文本体的末尾
marker[0] = readByte();
if (marker[0] == LF) {
// Work around IE5 Mac bug with input type=image.
// Because the boundary delimiter, not including the trailing
// CRLF, must not appear within any file (RFC 2046, section
// 5.1.1), we know the missing CR is due to a buggy browser
// rather than a file containing something similar to a
// boundary.
//IE5 Mac 的bug。
return true;
}
marker[1] = readByte();
if (arrayequals(marker, STREAM_TERMINATOR, 2)) {
nextChunk = false;
} else if (arrayequals(marker, FIELD_SEPARATOR, 2)) {
nextChunk = true;
} else {
throw new MalformedStreamException(
"Unexpected characters follow a boundary");
}
} catch (FileUploadIOException e) {
// wraps a SizeException, re-throw as it will be unwrapped later
throw e;
} catch (IOException e) {
throw new MalformedStreamException("Stream ended unexpectedly");
}
return nextChunk;
}
通过head游标跳过分割线的数据和分割线与下个参数内容的数据开始位置的回车换行,还检验是否存在下一个分区数据,和是否已经到文本体结尾
并返回是否存在下一个参数内容,返回true存在下一个分区数据,返回false,说明已经到文本体结尾
public byte readByte() throws IOException {
// Buffer depleted ?//
if (head == tail) {//这个情况一般会出现在一开始读取数据的时候,head==0,tail==0
head = 0;
// Refill.
tail = input.read(buffer, head, bufSize);//标记1
if (tail == -1) {
// No more data available.
throw new IOException("No more data is available");
}
if (notifier != null) {
notifier.noteBytesRead(tail);
}
}
return buffer[head++];
}
一般情况下调用skipPremble的时候,也只有一开始的读取主体文本的时候,head==tail才会成立,也就是说,readByte才是真正开始读取主体文本数据的方法。该方法一般情况下,都是直接通过head++直接取出buffer的时候,还有一点需要注意的是,标记1的位置,input是HttpServletRequest的主体文本的字节流InputStream,而不是内部ItemInputStream。
readHeaders
public String readHeaders() throws FileUploadIOException, MalformedStreamException {
int i = 0;
byte b;
// to support multi-byte characters
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int size = 0;
//该循环,会读取完该分区的所有消息头数据字节直到读取完两个回车换行结束
while (i < HEADER_SEPARATOR.length) {
try {
b = readByte();
} catch (FileUploadIOException e) {
// wraps a SizeException, re-throw as it will be unwrapped later
throw e;
} catch (IOException e) {
throw new MalformedStreamException("Stream ended unexpectedly");
}
if (++size > HEADER_PART_SIZE_MAX) {
throw new MalformedStreamException(
format("Header section has more than %s bytes (maybe it is not properly terminated)",
Integer.valueOf(HEADER_PART_SIZE_MAX)));
}
if (b == HEADER_SEPARATOR[i]) {
i++;
} else {
i = 0;
}
baos.write(b);
}
//将获取到的字节根据字符串headerEncoding转换成字符串
String headers = null;
if (headerEncoding != null) {
try {
headers = baos.toString(headerEncoding);
} catch (UnsupportedEncodingException e) {
// Fall back to platform default if specified encoding is not
// supported.
headers = baos.toString();
}
} else {
headers = baos.toString();
}
return headers;
}
读取分区里的消息头部分,返回消息头以及消息头与值之间的两个回车换行,即:Content-Disposition: form-data; name="test"\r\n\r\n