python速成下
第四章
首先是for循环,可以遍历一个链表
也可以遍历一个集合
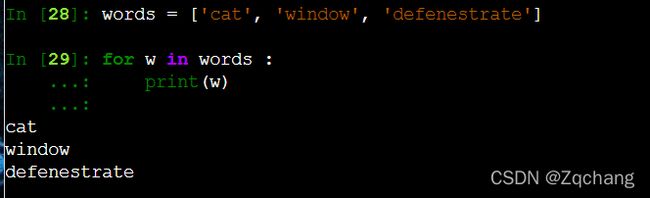
users = {‘Hans’: ‘active’, ‘Éléonore’: ‘inactive’, ‘景太郎’: ‘active’}
注意不同元素之间是用逗号隔开的,一对元素之间是用冒号隔开的
遍历一个集合可以有一个技巧,就是遍历它的关键字,这是第一种方式
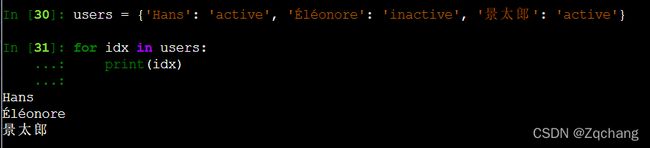
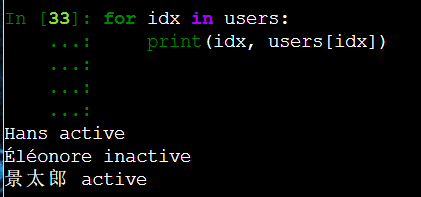
字典中有一个items() 函数以列表返回可遍历的(键, 值) 元组。
将字典中的键值对以元组存储,并将众多元组存在列表中。
这里就可以用users.items()
favorite_places = {'XiaoMing': 'TJL','XiaoQiang':'Amercia','Dongsheng':'Japan'}
print("数值:%s" % favorite_places.items())
for key,value in favorite_places.items():
print(key,value)
运行结果为
数值:dict_items([('XiaoQiang', 'Amercia'), ('Dongsheng', 'Japan'), ('XiaoMing', 'TJL')])
XiaoQiang Amercia
Dongsheng Japan
XiaoMing TJL
这里就是二元遍历,每个key, value对分别赋给两个元素,key赋给前边的,value赋给后边的
python中字典不能边遍历边修改,但是可以先复制一份,也就是遍历的其实是复制的东西,修改的是自己
遍历某个集合的同时修改该集合的内容,很难获取想要的结果。要在遍历时修改集合的内容,应该遍历该集合的副本或创建新的集合:
# Create a sample collection
users = {'Hans': 'active', 'Éléonore': 'inactive', '景太郎': 'active'}
# Strategy: Iterate over a copy
for user, status in users.copy().items():
if status == 'inactive':
del users[user]
# Strategy: Create a new collection
active_users = {}
for user, status in users.items():
if status == 'active':
active_users[user] = status
就不会发生读写冲突了
range函数会返回一个左闭右开的区间
range 还有一个函数,可以实现倒序,list(range(9, 0, -1))
这样就能输出一个公差为1的等差数列,从9到1,-1的位置放公差,左闭右开
for i in range(9, -1, -1):
print(i)
这个代码就可以输出从9到0, 但是注意,公差不可以省略
但是range可以只接受一个参数,比如,range(10)就等于range(0, 10)
for循环本身有一个else语句,它并不对应if, 而是直接对应for, 就是当for循环没有被break的时候,它循环结束,就会执行else里面的语句,反之,如果foe循环被break了的话,else就不会执行,同理,这个else也可以接while循环。也就是在python中,一个循环,如果被break了的话,就不会执行else语句,如果没有被break了的话,就会执行
>>> for n in range(2, 10):
... for x in range(2, n):
... if n % x == 0:
... print(n, 'equals', x, '*', n//x)
... break
... else:
... # loop fell through without finding a factor
... print(n, 'is a prime number')
continue跟C++一样
python行末可以不加分号,加不加都可以
pass语句
如果你写了一个for循环,然后没有任何东西需要执行,不能直接跳过,这样会报错,可以写上一个pass,就是啥也不执行
pass更多的时候是建在python里的函数定义上
因为python是通过缩进来判断函数是否写完,所以必须要写上一些语句,如果想不出来,就写pass
函数定义
python里面函数有一个默认返回值就是None
def f(a, b):
print(a+b)
f(3, 4)
python可以定义重名的函数,下一个会把上一个覆盖掉
python所有的传递都是传递的引用

它函数内数组a的值发生了变化之后,它函数外的数组也会发生变化
如果你传的是一个变量,函数内修改并不会影响函数外的值,但是如果你传的是一个数组,函数内改变,就会影响函数外的值
python函数中定于变量不用定义类型

python也是可以定义默认参数的
但是定义默认值必须是连续的,也就是,你想给第五个附上默认值,从第五个往后的参数都要有默认值,不然会报错
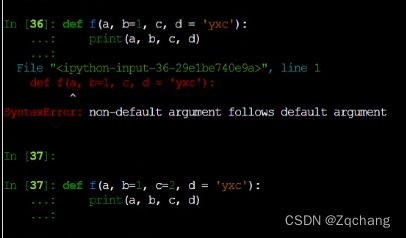
默认值就是,如果你不给它赋值的话,它就调用默认值,如果你给它赋值,他就会用你赋的值
python中赋值有个神奇的地方,就是你可以用等号赋值,如
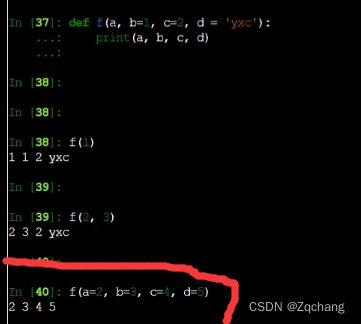
因为我们有变量名,所以,我们发现,它可以随便换顺序
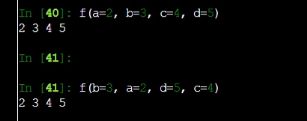
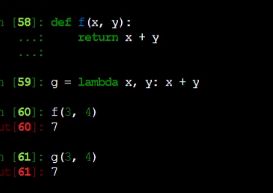
python中 ,可以直接把一个函数赋值给另一个东西,如
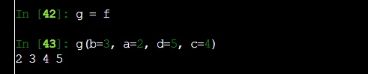
这就是将f函数,赋给了g,现在g的功能之类的就跟f一样了
python在调用函数的时候,它的参数,可以通过一个数组的形式来赋
有一个解包的概念,就是我们有一个数组a[1, 2, 3, 4], 如果我们分别想把a中的四个值,当作参数传给f的话,我们直接把a传进来就可以了,前面加上解包操作*就是f(a);注意这个不是C++里面的指针,他就专指解包
解包类似就是将1 2 3 4展开成四个逗号隔开的变量,然后赋给f,然后当作它参数来调用
也可以调用字典来赋值
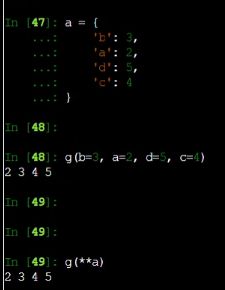
注意变量名要用字符串表示,解包一个字典是**, 解包一个数组是*
数组和字典中的元素个数要与参数个数相同
Lambda 表达式
lambda 关键字用于创建小巧的匿名函数。lambda a, b: a+b 函数返回两个参数的和。Lambda 函数可用于任何需要函数对象的地方。在语法上,匿名函数只能是单个表达式。在语义上,它只是常规函数定义的语法糖。与嵌套函数定义一样,lambda 函数可以引用包含作用域中的变量:
>>> def make_incrementor(n):
... return lambda x: x + n
...
>>> f = make_incrementor(42)
>>> f(0)
42
>>> f(1)
43
上例用 lambda 表达式返回函数。还可以把匿名函数用作传递的实参:
>>> pairs = [(1, 'one'), (2, 'two'), (3, 'three'), (4, 'four')]
>>> pairs.sort(key=lambda pair: pair[1])
>>> pairs
[(4, 'four'), (1, 'one'), (3, 'three'), (2, 'two')]
数据结构
1.列表(就是数组)
就是a[1, 2, 3, 4]特点就是,一个列表中的元素类型可以不一样,比如a[1, “see”, 2, [1]]
list.append(x)
在列表末尾添加一个元素,相当于 a[len(a):] = [x] 。
第二个比较常用的就是len这个函数,可以求列表长度
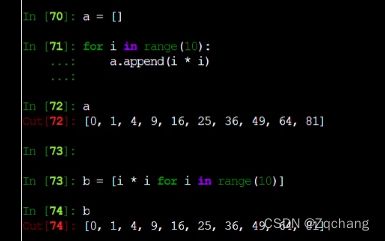
上图就是列表推导式
列表也可以嵌套,但是一般就嵌套两层
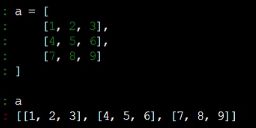
二维数组一般这样来定义
python的列表有点像向量,里面的每个数都是可以修改的
元组和列表区别就是元组不能改
元组用小括号定义,如b = (1, 2, 3)
它可以取值,比如b[0],但是不能修改
元组定义的时候也可以省去小括号,如b = 1, 2, 3
len()函数可以对所有的求长度,包括元组
元组可以被赋给一个变量
也可以有若干个变量来接受元组里面的值(列表也行)
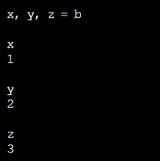
交换xy的时候,x, y = y, x其实就是利用元组,但是元组可以省去括号,就是这样了
元组也不能用append()加元素
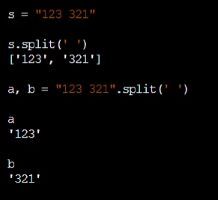
这也算是解包,这个操作还是用的比较多的
集合
集合跟C++里的set就是一个东西, 同样如果放入俩一样的,只留一个
a = set()
a.add(1)
定义和添加元素
也可以直接用大括号,大括号既可以表示集合,又可以表示字典。
区分 的时候注意后边存的元素是key value对还是一个单值
一般用来对数组做判重
print(a, end = ' ')
print(set(a), end = ' ')
但是这样输出出来是个集合,如果想对数组a进行去重,又不想变成集合怎么办
a = list(set(a))
print(a)
python中有个type函数,是用来求变量的类型的
字典的值是可以修改的
tel = {'tao':1, 'zi':2}
In [10]: tel['zi'] = 222
In [11]: tel
Out[11]: {'tao': 1, 'zi': 222}
python中对数组的实现
a = [3, 2, 1]
In [13]: sorted(a)
Out[13]: [1, 2, 3]
In [14]: a
Out[14]: [3, 2, 1]
In [15]: a = sorted(a)
In [16]: a
Out[16]: [1, 2, 3]
sorted并不会改变原数组的值,需要加上一个a = 才可以
或者简单点,直接a.sort()
字典还有如下的定义方式
dict() 构造函数可以直接用键值对序列创建字典:
>>>
>>> dict([('sape', 4139), ('guido', 4127), ('jack', 4098)])
{'sape': 4139, 'guido': 4127, 'jack': 4098}
字典推导式可以用任意键值表达式创建字典:
>>>
>>> {x: x**2 for x in (2, 4, 6)}
{2: 4, 4: 16, 6: 36}
关键字是比较简单的字符串时,直接用关键字参数指定键值对更便捷:
>>>
>>> dict(sape=4139, guido=4127, jack=4098)
{'sape': 4139, 'guido': 4127, 'jack': 4098}
a={
'a' : 1,
'b' : 2
}
print(a)
一般如果字典比较长的话,会这么定义
在字典中循环时,用 items() 方法可同时取出键和对应的值:
>>>
>>> knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>> for k, v in knights.items():
... print(k, v)
...
gallahad the pure
robin the brave
对于同时遍历两个数组
a = [100, 11, 22]
b = ['a', 'b', 'c']
for i in range(len(a)):
print(a[i], b[i])
for i, j in zip(a, b):
print(i, j)
可以用这俩,如果两个数组长度不一致,zip自动按照长度小的那个,另一个需要自己手动设置成小的,大的会报错
如果想反转一个数组的话,比如a,要这么写a = a[::-1]
但是还是要注意的是,这里的a[::-1]只是输出了反转后的结果,并没有改变a数组,所以要a =
还可以直接用a.reverse(),这样a也就直接反转了,a数组此刻就是反转后的结果
模块
53:00开始
暂时用不到,先粗略看看,先粗略记笔记
模块主要是,我们写的东西太多了,不可能放在一个文件夹中国,所以分开存储
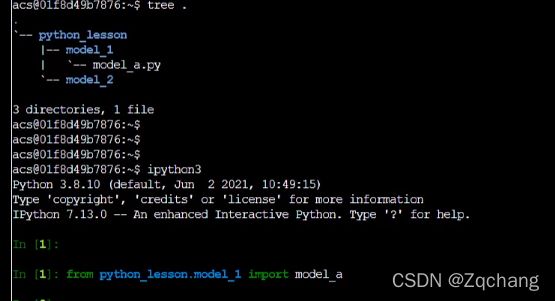
上面是结构,加上下面的引入之后,就可以调用我们其他文件里的函数了
![]()
这就是import一个模块
我们其实可以把一个函数import进来,可以不用import这个文件名
![]()
当然我们import的时候可以起个别名
![]()
这里的fib3就是fib的别名
python中有很多包,比如随机数,randint,它需要传入两个数

传入a, b,会随机返回a到b中的任意一个数,左右都闭的
输入输出
![]()
这里的04表示不足四位的都补0,这些在python中都可以用,可以格式化字符串
python里面的格式化字符串,不止可以用到print里面
也可以用到字符串里面,用到任意字符串出现的地方
形式如图
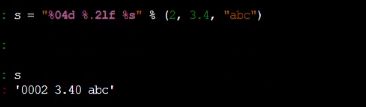
通过%基本上所有的C++里面的printf的格式化的方式都可以用
python读写文件
一定要写字符串,整数变字符串,直接str(i)就可以i就是一个整数
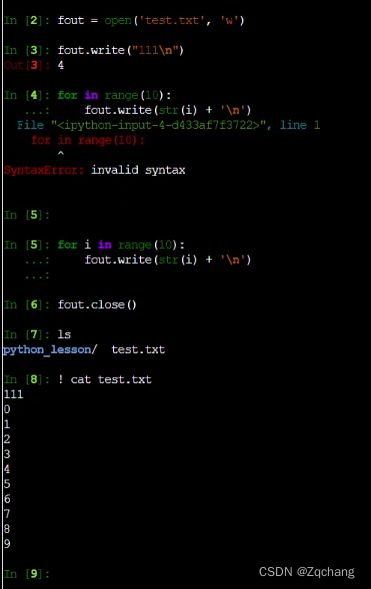
操作如图
ipython是可以执行shell命令的
比如执行echo命令,直接在前边加个!号,注意要记得关闭文件
一般读文件的时候会写成,with open(),如图
![]()
with一般不会出现数据丢失或者内存泄露的问题
这个操作就是打开一个文件,这个文件的名字叫fout,这个with可以不用单独写文件关闭
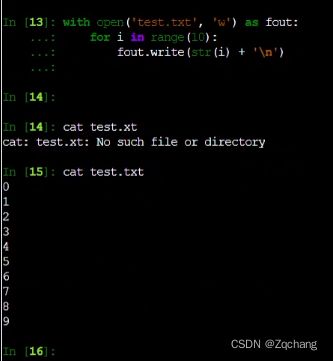
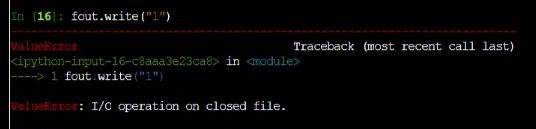
此时再写文件关闭的话,就会报错
如果要读文件的话
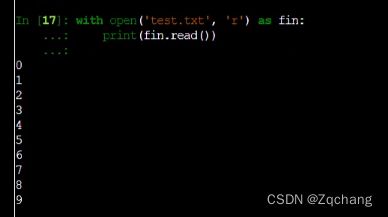
这个fin一般是用来读,fout一般是表示写入的文件,fin.read()一般就是指读取文件中所有的内容
fin.readlines()就是读取所有的行,返回的是一个列表

也可以逐行读
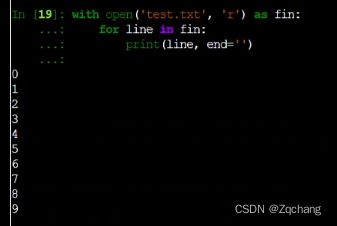
由于每行行末都已经有回车了,就去掉print自带的回车了
异常处理
>>> def divide(x, y):
... try:
... result = x / y
... except ZeroDivisionError:
... print("division by zero!")
... else:
... print("result is", result)
... finally:
... print("executing finally clause")
...
>>> divide(2, 1)
result is 2.0
executing finally clause
>>> divide(2, 0)
division by zero!
executing finally clause
>>> divide("2", "1")
executing finally clause
Traceback (most recent call last):
File "" , line 1, in <module>
File "" , line 3, in divide
TypeError: unsupported operand type(s) for /: 'str' and 'str'
如上所示,任何情况下都会执行 finally 子句。except 子句不处理两个字符串相除触发的 TypeError,因此会在 finally 子句执行后被重新触发。
在实际应用程序中,finally 子句对于释放外部资源(例如文件或者网络连接)非常有用,无论是否成功使用资源。
可以先直接按照下面这么写
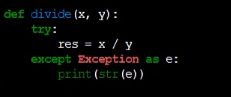
大意就是要捕获一个错误,有时候会出现502错误,就是程序发生了异常,如果不想让用户看到502错误的话,如果发现异常,就直接把异常捕获掉,它就不会出现502了,而是会跳到一个404页面
比如
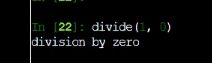
这时候就不会报出来错误,只是返回一句话,除0是操作系统级别的中断,层次很高
这个意思就是,如果我try这个代码段发生了异常的话,我就直接输出这段内容,程序不报错,这时候代码还会继续向后执行,如果不捕获掉这个错误,这个代码就报错然后不执行了
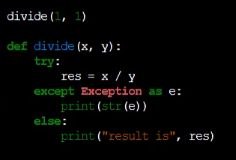
这个的意思是如果try代码发生异常,执行第一句话,如果不发生异常就执行第二句话
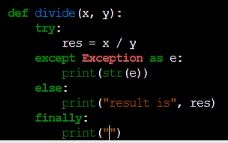
finally, 它的意思是我不管有没有发生异常,我都会执行这句话,一般是用来关闭数据库啥的,因为不管有没有异常都需要关闭数据库,否则会造成数据泄露、
类
"""A simple example class"""
i = 12345 #定义在这里其实是个静态变量,就是所有这个类的对象都会公用这一个变量
def f(self):
return 'hello world'
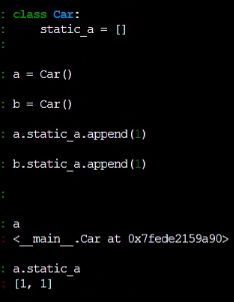
如图,每个都加1,实际上就变成了[1, 1]
实例化操作(“调用”类对象)会创建一个空对象。 许多类喜欢创建带有特定初始状态的自定义实例。 为此类定义可能包含一个名为 __init__() 的特殊方法,就像这样:
def __init__(self):
self.data = []
这个init就类似C++里面定义class的构造函数,这里的参数名self一定要加
我们在创造这个类的时候就会默认执行这个函数
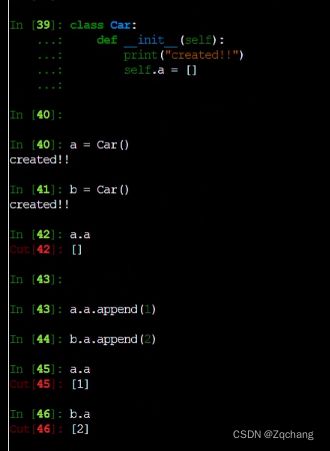
如图,在函数内,定义一下成员变量,self是python里面的一个关键字,可以认为就是我对象内部的东西,
python的类特比通灵活,比如,上图 ,类中没有x,但是却可以用
![]()
也可以在类中定义一些成员函数
所有的成员函数都要加一个变量名self, 具体如图
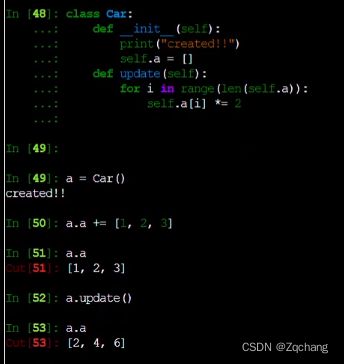
构造函数中是可以传参数的,栗子如下图,两种传参方式
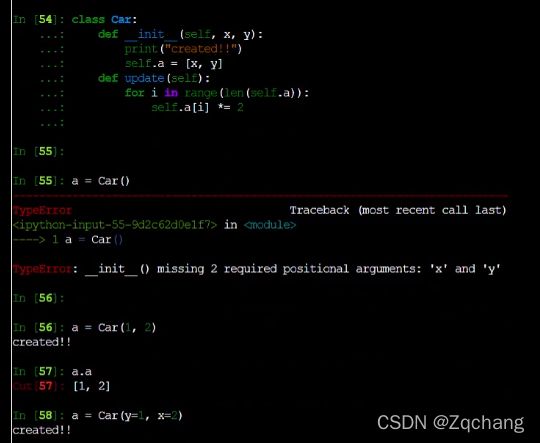
也可以用解包的方式传参,可以把类当成个函数来用
python的类也是可以继承的
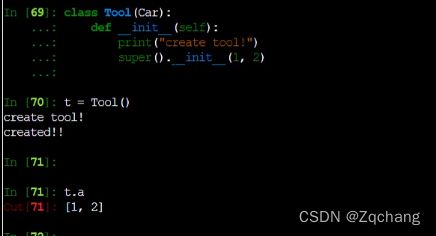
不过python中的继承要有一个明显的调用基类的构造函数,否则它会把基类构造出来,但是不会调用构造函数,class中有一个super函数,这个函数的作用就是找到这个函数的基类,然后调用它,基类直接放在括号里就可以