大家好,这是专栏《TensorFlow2.0》的第五篇文章,我们对专栏《TensorFlow2.0》进行一个总结。
我们知道全新的TensorFlow2.0 Alpha已经于2019年3月被发布,新版本对TensorFLow的使用方式进行了重大改进,为了满足各位AI人对TensorFlow2.0的需求,我们推出了专栏《TensorFlow2.0》,前四篇文章带大家领略了全新的TensorFlow2.0的变化及具体的使用方法。今天就带大家总结下TensorFlow2.0的一些变化。
作者 | 汤兴旺
编辑 | 言有三
1 默认动态图机制
在tensorflow2.0中,动态图是默认的不需要自己主动启用它。
import tensorflow as tf
a = tf.constant([1,2,3])
b = tf.constant([4,5,6])
print(a+b)
上面的结果是tf.Tensor([5 7 9], shape=(3,), dtype=int32)
可以说有了动态图,计算是非常方便的了,再也不需要理解复杂的graph和Session了。
另外我们在对比看下Pytorch中是如何计算上面的结果的。
import torch
a = torch.Tensor([1,2,3])
b = torch.Tensor([4,5,6])
print(a+b)
可以发现TensorFlow2.0和Pytorch一样简单了,而且代码基本一样。
2 弃用collections
我们知道在TensorFlow1.X中可以通过集合 (collection) 来管理不同类别的资源。例如使用tf.add_to_collection 函数可以将资源加入一个或多个集合。使用tf.get_collection获取一个集合里面的所有资源。这些资源可以是张量、变量或者运行 Tensorflow程序所需要的资源。我们在训练神经网络时会大量使用集合管理技术。如通过tf.add_n(tf.get_collection("losses")获得总损失。
由于collection控制变量很不友好,在TensorFlow2.0中,弃用了collections,这样代码会更加清晰。
我们知道TensorFlow2.0非常依赖Keras API,因此如果你使用tf.keras,每个层都会处理自己的变量,当你需要获取可训练变量的列表,可直接查询每个层。
from tensorflow import keras
from tensorflow.keras import Sequential
model = Sequential([
keras.layers.Dense(100,activation="relu",input_shape=[2]),
keras.layers.Dense(100,activation="relu"),
keras.layers.Dense(1)
])
我们通过model.weights,就可以查询每一层的可训练的变量。结果如下面这种形式。
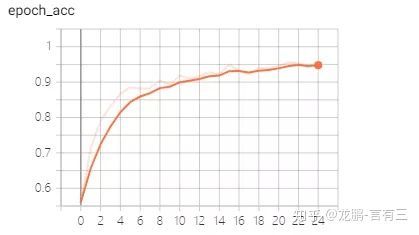
dtype=float32, numpy=array([[...]]), dtype=float32)>, 另外在TensorFlow2.0中,也删除了Variable_scopes和tf.get_variable(),需要用面向对象的方式来处理变量共享。 3 删除杂乱的API,重用Keras 之前TensorFlow1.X中包含了很多重复的API或者不推荐使用的 API,杂乱无章,例如可以使用 tf.layers或tf.keras.layers创建图层,这样会造成很多重复和混乱的代码。 如今TensorFlow 2.0正在摆脱tf.layers,重用Keras 层,可以说如果你使用TensorFlow2.0,那么使用Keras构建深度学习模型是你的不二选择。 详细介绍请看文后第二篇文章《以后我们再也离不开Kera了》。 另外tf.contrib的各种项目也已经被合并到Keras等核心API 中,或者移动到单独的项目中,还有一些将被删除。 可以说TensorFlow 2.0会更好地组织API,使编码更简洁。 4 学习TensorFlow2.0的建议 不管你是AI小白,还是已经学习很久的大神,对于TensorFlow2.0,我们或许都需要重新学,因为它的变化太多了。当你学习TensorFlow2.0时,有如下建议供你参考: 首先不要上来就是import tensorflow as tf。其实没有必要,我建议大家先把数据预处理先学会了。比如数据你怎么read,怎么数据增强。 这个可以查看文后第三篇文章《数据读取与使用方式》。 这篇文章介绍了Tensorflow2.0读取数据的二种方式,分别是Keras API和Dataset类对数据预处理。 另外对于数据导入方式,最好使用Dataset类,个人认为这个比较方便。一个简单的例子如下: import tensorflow as tf import tensorflow_datasets as tfds dataset, metadata = tfds.load('fashion_mnist', as_supervised=True, with_info=True) train_dataset, test_dataset = dataset['train'], dataset['test'] train_dataset = train_dataset.shuffle(100).batch(12).repeat() for img, label in train_dataset.take(1): img = img.numpy() print(img.shape) print(img) 从上面的代码我们可以看出在2.0中导入数据没有make_one_shot_iter() 这样的方法了。这个方法已经被弃用了,直接用 take(1)。 当你学会了读取数据和数据增强后,你就需要学会如何使用TensorFlow2.0构建网络模型,在TensorFlow2.0中搭建网络模型主要使用的就是Keras高级API。 如果你想要学会这个本领,可以参考文后的第四篇文章《如何搭建网络模型》。 在这篇文章我们详细介绍了如何使用Keras API搭建线性模型VGG16和非线性模型Resnet。如果你是AI小白,想要更好的掌握TensorFlow2.0,建议你使用TensorFlow2.0完成搭建VGG、GoogLeNet、Resnet等模型,这样对你掌握深度学习框架和网络结构更有帮助。 当你完成了数据读取和模型搭建后,现在你需要做的就是训练模型和可视化了。一个简单的示例如下: import tensorflow as tf from tensorflow.keras.callbacks import TensorBoard from tensorflow.keras.optimizers import SGD from tensorflow.keras.preprocessing.image import ImageDataGenerator model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(12, (3,3), activation='relu', input_shape=(48, 48, 3),strides=(2, 2), padding='same'), tf.keras.layers.BatchNormalization(axis=3), tf.keras.layers.Conv2D(24, (3,3), activation='relu',strides=(2, 2), padding='same'), tf.keras.layers.BatchNormalization(axis=3), tf.keras.layers.Conv2D(48, (3,3), activation='relu',strides=(2, 2), padding='same'), tf.keras.layers.BatchNormalization(axis=3), tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ]) model.compile(loss='binary_crossentropy', optimizer = SGD(lr=0.001, decay=1e-6, momentum=0.9), metrics=['acc']) train_datagen = ImageDataGenerator(rescale=1/255, shear_range=0.2,zoom_range=0.2, horizontal_flip=True) validation_datagen = ImageDataGenerator(rescale=1/255) train_generator = train_datagen.flow_from_directory( r"D://Learning//tensorflow_2.0//data//train", # 训练集的根目录 target_size=(48, 48), # 所有图像的分辨率将被调整为48x48 batch_size=32, # 每次读取32个图像 # 类别模式设为二分类 class_mode='binary') # 对验证集做同样的操作 validation_generator = validation_datagen.flow_from_directory( r"D://Learning//tensorflow_2.0//data//val", target_size=(48, 48), batch_size=16, class_mode='binary') history = model.fit_generator( train_generator, steps_per_epoch=28, epochs=500, verbose=1, validation_data = validation_generator, callbacks=[TensorBoard(log_dir=(r"D:\Learning\logs"))], validation_steps=6) 上面简单示例的数据集是我们框架系列文章一直所用的表情二分类数据集。从上面的代码我们可以看出从数据读取到模型定义再到训练和可视化基本用的都是Keras 高级API,这里不再赘述。需要下载数据集的请移步github。 acc和loss可视化结果如下两图,可以看出效果还是比较可以的,上面的代码已经同步到有三AI的GitHub项目,如下第一个。 5 TensorFlow2.0优秀的github 1、https://github.com/tangxingwang/yousan.ai 1、https://github.com/czy36mengfei/tensorflow2_tutorials_chinese 3、https://github.com/jinfagang/yolov3_tf2 总结 本期我们总结了TensorFlow2.0的变化及使用方法,而且还介绍了学习它的方法和一些比较好的Github。希望您尽快能掌握它! 往期 有三AI一周年了,说说我们的初衷,生态和愿景 【TensorFlow2.0】TensorFlow2.0专栏上线,你来吗? 【TensorFlow2.0】以后我们再也离不开Keras了? 【TensorFlow2.0】数据读取与使用方式 【TensorFlow2.0】如何搭建网络模型? 如果想加入我们,后台留言吧 转载文章请后台联系 侵权必究 技术交流请移步知识星球 更多请关注知乎专栏《有三AI学院》和公众号《有三AI》