时间序列网络RNN,LSTM入门
文章目录
-
- RNN
- LSTM
- LSTM快速实战
-
- 进阶 双向LSTM+Attention文本分类
- GRU
RNN
解决问题示例:语句情感分析

传统方法问题:
- 长句子,参数过多 (改进:使用参数共享,每个单词的特征提取方式一致)
- 没有上下句的语境信息 (改进:需要长期的记忆模块)
改进的模型: h 0 h_0 h0为初始化数据
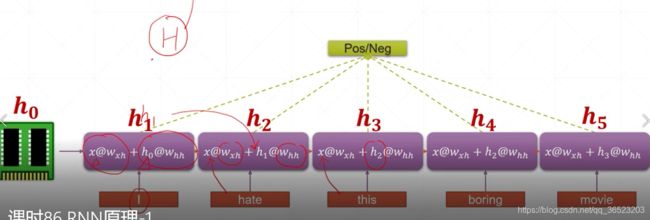
共享的参数: w h h w_{hh} whh和 w w h w_{wh} wwh;
最后输出可以是最后的节点,也可以将所有的记忆节点综合输出,比较灵活。
最后的实际模型为:
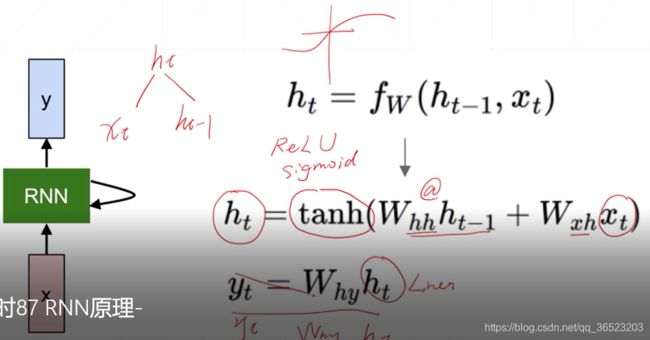
其中:
激活函数使用 t a n h ( ) tanh() tanh()函数
输出 y t y_t yt也可以将所有的 h t h_t ht t = 1... t t=1...t t=1...t以全连接层综合起来输出。
训练
BP though time
梯度求导公式:注意:梯度公式有累积项,所以会出现梯度爆炸的情况
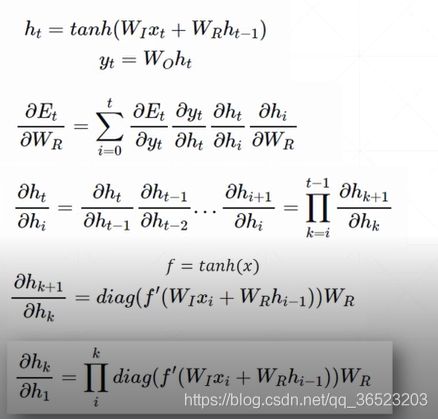
Pytorch调用RNN
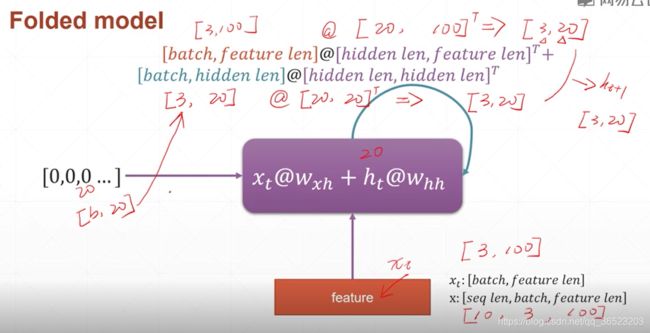
输入: x : [ s e q l e n , b a t c h , f e a t u r e l e n ] x:[seq len,batch,feature len] x:[seqlen,batch,featurelen],一次送一个单词 x t : [ b a t c h , f e a t u r e l e n ] x_t:[batch,feature len] xt:[batch,featurelen]
模型中反复的计算步骤: x t ∗ w w h + h t ∗ w h h x_t*w_{wh}+h_t*w_{hh} xt∗wwh+ht∗whh 其中, x t 是 输 入 特 征 x_t是输入特征 xt是输入特征, h t h_t ht是上一时刻的记忆内容
输入大小: [ b a t c h , f e a t u r e l e n ] [batch,feature len] [batch,featurelen],输出大小: [ b a t c h , h i d d e n l e n ] [batch,hidden len] [batch,hiddenlen]
梯度弥散和梯度爆炸
根据梯度的形式里面存在 w k w^k wk的形式,可以得到, w w w如果大于1,梯度爆炸,小于1,梯度弥散。梯度爆炸解决方法:对每一个梯度信息,进行clip(剪辑);梯度弥散解决方法:LSTM
LSTM

输入门: i t = σ ( W i ∗ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i*[h_{t-1},x_t]+b_i) it=σ(Wi∗[ht−1,xt]+bi)和新的信息 C t ′ = t a n h ( W c ∗ [ h t − 1 , x t ] + b c ) C'_{t}= tanh(W_c*[h_{t-1},x_t]+bc) Ct′=tanh(Wc∗[ht−1,xt]+bc) 输入门将信息综合: C t = f t ∗ C t − 1 + i t ∗ C y ′ C_t=f_t*C_{t-1}+i_t*C_y' Ct=ft∗Ct−1+it∗Cy′
遗忘门: f t = σ ( w f ∗ [ h t − 1 . x t ] + b f ) f_t=\sigma(w_f*[h_{t-1}.x_t]+b_f) ft=σ(wf∗[ht−1.xt]+bf)
输出门: o t = σ ( W o [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o[h_{t-1},x_t]+b_o) ot=σ(Wo[ht−1,xt]+bo) h t = o t ∗ t a n h ( C t ) h_t=o_t*tanh(C_t) ht=ot∗tanh(Ct)
公式角度理解:

为什么能够解决梯度弥散

可以发现:梯度项没有累积的项,而且是累加,出现全部大或者全部小的概率较小,防止了梯度爆炸和弥散
使用LSTM
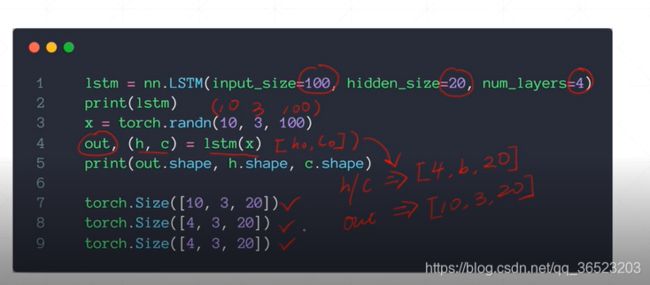
nn.LSTM
输入参数:input size(特征维度) hidden_size num_layers
forward:
out,(ht,ct)-lstm(x,[h0,c0]
输出:out (最后的输出,句子长度,batch,hiddensize)(h,c):中间的量(lstm层的个数,batch, hidden_size)
nn.LSTMCell
forward:
ht,ct=lstmcell(xt,[ht,ct])
xt:[batch,feature len]
ht:(batch,hidden len)
ct:(batch,hidden len)
out=ht[-1]
也可以用它组成多层,ht[-1]是下一层的xt
LSTM快速实战
1,框架使用Keras
目的:预测考试成绩
def create_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i:(i + look_back), 0]
dataX.append(a)
dataY.append(dataset[i + look_back, 0])
return np.array(dataX), np.array(dataY)
# fix random seed for reproducibility
np.random.seed(7)
df_train = pd.read_csv('./train_s1/exam_score.csv')
print(len(df_train))
df_test = pd.read_csv('./test_s1/submission_s1.csv')
course_class = pd.read_csv('./train_s1/course.csv')
student = pd.read_csv('./train_s1/student.csv')
sub_test = pd.read_csv('./test_s1/submission_s1.csv')
print(len(student))
#all_know = pd.read_csv('/home/kesci/input/smart_edu7557/all_knowledge.csv')
student_list=student['student_id']
for i in student_list:
for k in range(1,9):
course='course'+str(k)
print(course)
col=[j for j in df_train.index if df_train.iloc[j]['student_id']==i and df_train.iloc[j]['course']==course]
score=df_train.loc[col]['score']
dataset=score.values
dataset=np.array(dataset)
dataset = dataset.astype('float32')
dataset=np.array(dataset).reshape(-1,1)
#数据归一化
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
# split into train and test sets
look_back = 6
train_size = int(len(dataset))
train = dataset[0:train_size,:]
predict=dataset[len(dataset)-look_back:len(dataset),:]
#use this function to prepare the train and test datasets for modeling
trainX, trainY = create_dataset(train, look_back)#生成数据集
predict_X=[]
predict_X.append(predict[:,0])
predict_X=np.array(predict_X)
# reshape input to be [samples, time steps, features]
trainX = np.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))
predict_X=np.reshape(predict_X, (predict_X.shape[0], 1, predict_X.shape[1]))
model = Sequential()
model.add(LSTM(16, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=1, verbose=2)
trainPredict = model.predict(trainX)
predict_y = model.predict(predict_X)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform([trainY])
predict_y =scaler.inverse_transform(predict_y)#预测出最后一次考试成绩
col=[j for j in sub_test.index if sub_test.iloc[j]['student_id']==i and sub_test.iloc[j]['course']==course]
sub_test.iloc[col]['pred'] = predict_y[0][0]
print(predict_y)
#查看训练得分
trainScore = math.sqrt(mean_squared_error(trainY[0], trainPredict[:,0]))
print('Train Score: %.2f RMSE' % (trainScore))
print(sub_test)
sub_test.to_csv('./submisson3.csv',index=None)
2,框架使用 pytorch
多特征分类
import torch
import pandas as pd
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms, utils
import numpy as np
from torch import optim,nn
import video_findhero#自己定义的一个数据加载的函数库
import random
import os
import operator
from functools import reduce
import torch.nn.functional as F
#数据大小[batch_size,seq_len,feature_len]
if torch.cuda.is_available():#检测是否使用GPU版本的pytorch
device=torch.device('cuda')
else:
device=torch.device('cpu')
#lstm两种:1.[seq_len,batch_size,feature_len],2,[batch_size,seq_len,feature_len]
#在pytorch相应的设置,对应不同的数据种类
class BiLSTMNet(nn.Module):#网络构建
def __init__(self, input_size,hidden_size,num_layers):
super(BiLSTMNet, self).__init__()
self.input_size=input_size
self.hidden_size=hidden_size
self.num_layers=num_layers
self.rnn = nn.LSTM(
self.input_size,
self.hidden_size,
num_layers=self.num_layers,
batch_first=True,#数据形式将默认的第一种改为[batch_size,seq_len.feature_len]
bidirectional=True#双层
)
self.out = nn.Sequential(
#也可以多几层
nn.Linear(self.hidden_size*self.num_layers, 1)
)
self.dropout=nn.Dropout(0.5)
def forward(self, x):
#x[batch_size,seq_len,feature_len]
r_out, (h_n, h_c) = self.rnn(x) # None 表示 hidden state 会用全0的 state
#print("输出的大小",r_out.shape,h_n.shape,h_c.shape)
#r_out:[batch_size,seq_len,hid_dim*2]
#h_n:[num_layers*2,batch_size,hid_dim]
#h_c:[num_layers*2,batch_size,hid_dim]
#[batch_size,num_layers*2,hid_dim]=>2 of[b,hid_dim]=>[b,hid_dim*2]
hidden=torch.cat([h_n[-4],h_n[-3],h_n[-2],h_n[-1]],dim=1)
#print("隐层的大小",hidden.shape)
out = self.out(hidden)#只考虑输出的最后一个
#print("输出层大小",out.shape)#
return out
def binary_acc(pred,label):#准确度计算
preds=torch.round(torch.sigmoid(pred))
correct=torch.eq(preds,label).float()
acc=correct.sum()/len(correct)
return acc
def evalate(net,testloader):#测试函数
avg_acc=[]
#rnn.eval()
for x,label in testloader:
x,label=x.to(device),label.to(device)
label = torch.tensor(label, dtype=torch.float32)#非常重要的数据类型转变
x = torch.tensor(x, dtype=torch.float32)
with torch.no_grad():
#[b,1]=>[b]
pred=net(x).squeeze(1)
acc=binary_acc(pred,label)
avg_acc.append(acc)
avg_acc=np.array(avg_acc).mean()
print('>>test:',avg_acc)
return avg_acc
def train(net,train_loader,val_loader,test_loader,criterion,optimizer):#训练函数
avg_acc=[]
best_acc,beste_poch=0,0
for epoch in range(1000):#训练次数
for i,(data,label) in enumerate(train_loader):
x,label=data.to(device),label.to(device)#[batch_size,seq_len,feature_len]
label = torch.tensor(label, dtype=torch.float32)#非常重要的数据类型转变
#print('数据形状:',x.shape,label.shape)
x = torch.tensor(x, dtype=torch.float32)
pred=net(x).squeeze(1)
#print("预测结果形状",pred,label)
#误差函数
loss=criterion(pred,label)
#准确度计算
acc=binary_acc(pred,label)
avg_acc.append(acc)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#做测评,保存最好的模型状态
if epoch%10 == 0:
val_acc=evalate(net,val_loader)
print('epoch:',epoch,'验证集准确度',val_acc)
if val_acc>best_acc:
best_epoch=epoch
best_acc=val_acc
torch.save(net.state_dict(),'best.mdl')
print('best acc:',best_acc,'best epoch:',best_epoch)
#加载模型,然后做测试
net.load_state_dict(torch.load('best.mdl'))
test_acc=evalate(net,test_loader)
print('test_acc',test_acc)
#定义数据集,将数据加载进来
class mydata(Dataset):
def __init__(self,mode):
super(mydata,self).__init__()
#执行yolov3部分,获取特征数据
label=[]
data=[]
#先读取精彩数据,设置label
root='./yolo_zhubo/highlight_csv/'
vediofiles=os.listdir(root)
timestep=15
for vediofile in vediofiles:
datax = np.loadtxt(open(root+vediofile,"rb"),delimiter=",",skiprows=0)
for i in range(len(datax)-timestep-1):
a=datax[i:i+timestep]
data.append(a)
label.append(1)
#再读取非精彩数据,设置label
root='./yolo_zhubo/normal_csv/'
vediofiles=os.listdir(root)
for vediofile in vediofiles:
datax = np.loadtxt(open(root+vediofile,"rb"),delimiter=",",skiprows=0)
for i in range(len(datax)-timestep-1):
a=datax[i:i+timestep]
data.append(a)
label.append(0)
data=np.array(data)
label=np.array(label)
print(data.shape)
print(label.shape)
#将特征数据归一化
for c in range(15) :
#print(data[:,c,:].shape)
for i in range(9):
d = data[:,c,i]
MAX = d.max()
MIN = d.min()
data[:,c,i] = ((d - MIN) / (MAX - MIN)).tolist()
#print(data[c,:,i])
#产生随机数,作为训练样本和测试样本的索引值
num=range(len(data))
index=random.sample(num,len(data))
#得到打乱的样本数
self.data=data[index]
self.label=label[index]
print(self.data.shape,self.label.shape)
#np.savetxt('test.csv', self.label, delimiter = ',')
#数据形状[batch_size,seq_len,feature_size]
train_size=int(0.6*len(self.data))
val_size=int(0.8*len(self.data))
print(train_size,val_size)
if mode=='train':
self.data=self.data[:train_size]
self.label=self.label[:train_size]
elif mode=='val':
self.data=self.data[train_size:val_size]
self.label=self.label[train_size:val_size]
else:
self.data=self.data[val_size:]
self.label=self.label[val_size:]
def __len__(self):
return len(self.data)
def __getitem__(self,idx):
data=self.data[idx]
label=self.label[idx]
data=torch.tensor(data)
label=torch.tensor(label)
return data,label
def main():
#[batch_size,seq_len,feature_len]
feature_len=9
hidden_size=5
num_layers=4
torch.manual_seed(1234)
lr=0.01#学习率
#初始化数据 成功
traindata=mydata('train')
print(traindata.data.shape,traindata.label.shape)
valdata=mydata('val')
print(valdata.data.shape,valdata.label.shape)
testdata=mydata('test')
print(testdata.data.shape,testdata.label.shape)
#数据加载
train_Loader= DataLoader(traindata, batch_size=64, shuffle=True, num_workers=4)
val_Loader= DataLoader(valdata, batch_size=64, shuffle=True, num_workers=4)
test_Loader=DataLoader(testdata,batch_size=64, shuffle=True, num_workers=4)
#初始化模型
net=BiLSTMNet(feature_len,hidden_size,num_layers).to(device)
optimizer=optim.Adam(net.parameters(),lr=lr)#目前最好的优化器
criterion=nn.BCEWithLogitsLoss()#nn.CrossEntropyLoss()#可用于二分类,已经将sigmoid函数集成进去
train(net,train_Loader,val_Loader,test_Loader,criterion,optimizer)
if __name__== '__main__':
main()
进阶 双向LSTM+Attention文本分类
LSTM使用上边的模型基础上添加atten层
class BiLSTMNet_attn(nn.Module):#网络构建
def __init__(self, input_size,hidden_size,num_layers,attention_size):
super(BiLSTMNet_attn, self).__init__()
self.input_size=input_size
self.hidden_size=hidden_size
self.num_layers=num_layers
self.rnn = nn.LSTM(
self.input_size,
self.hidden_size,
num_layers=self.num_layers,
batch_first=True,#数据形式将默认的第一种改为[batch_size,seq_len.feature_len]
bidirectional=True#双层
)
self.attention_size=attention_size
if self.use_cuda:
self.w_omega = Variable(torch.zeros(self.hidden_size * self.layer_size, self.attention_size).cuda())
self.u_omega = Variable(torch.zeros(self.attention_size).cuda())
else:
self.w_omega = Variable(torch.zeros(self.hidden_size * self.layer_size, self.attention_size))
self.u_omega = Variable(torch.zeros(self.attention_size))
self.out = nn.Sequential(
#也可以多几层
nn.Linear(self.hidden_size*self.num_layers, 1)
)
self.dropout=nn.Dropout(0.5)
def attention_net(self,lstm_output):
#print(lstm_output.size()) = (squence_length, batch_size, hidden_size*layer_size)
output_reshape = torch.Tensor.reshape(lstm_output, [-1, self.hidden_size*self.layer_size])
#print(output_reshape.size()) = (squence_length * batch_size, hidden_size*layer_size)
attn_tanh = torch.tanh(torch.mm(output_reshape, self.w_omega))
#print(attn_tanh.size()) = (squence_length * batch_size, attention_size)
attn_hidden_layer = torch.mm(attn_tanh, torch.Tensor.reshape(self.u_omega, [-1, 1]))
#print(attn_hidden_layer.size()) = (squence_length * batch_size, 1)
exps = torch.Tensor.reshape(torch.exp(attn_hidden_layer), [-1, self.sequence_length])
#print(exps.size()) = (batch_size, squence_length)
alphas = exps / torch.Tensor.reshape(torch.sum(exps, 1), [-1, 1])
#print(alphas.size()) = (batch_size, squence_length)
alphas_reshape = torch.Tensor.reshape(alphas, [-1, self.sequence_length, 1])
#print(alphas_reshape.size()) = (batch_size, squence_length, 1)
state = lstm_output.permute(1, 0, 2)
#print(state.size()) = (batch_size, squence_length, hidden_size*layer_size)
attn_output = torch.sum(state * alphas_reshape, 1)
#print(attn_output.size()) = (batch_size, hidden_size*layer_size)
return attn_output
def forward(self, x):
#x[batch_size,seq_len,feature_len]
r_out, (h_n, h_c) = self.rnn(x) # None 表示 hidden state 会用全0的 state
#print("输出的大小",r_out.shape,h_n.shape,h_c.shape)
#r_out:[batch_size,seq_len,hid_dim*2]
#h_n:[num_layers*2,batch_size,hid_dim]
#h_c:[num_layers*2,batch_size,hid_dim]
#[batch_size,num_layers*2,hid_dim]=>2 of[b,hid_dim]=>[b,hid_dim*2]
hidden=torch.cat([h_n[-4],h_n[-3],h_n[-2],h_n[-1]],dim=1)
atten_output=self.attention_net(hidden)
#print("隐层的大小",hidden.shape)
out = self.out(hidden)#只考虑输出的最后一个
#print("输出层大小",out.shape)#
return out
注意力模型的公式如下:
M = t a n h ( H ) M=tanh(H) M=tanh(H),H为lstm的输出或者输出层合并
α = s o f t m a x ( w T M ) \alpha=softmax(w^T M) α=softmax(wTM)
r = H α T r=H\alpha ^T r=HαT
代码中的softmax手写的,也可以直接调用torch中的softmax,这里是让大家清楚这里的形状变化。
GRU

GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
GRU和LSTM在很多情况下实际表现上相差无几,那么为什么我们要使用新人GRU(2014年提出)而不是相对经受了更多考验的LSTM(1997提出)呢。
总的来说效果差不多,但是计算更容易收敛,计算要求低。
GRU计算结构
计算更快和计算的结构方式有关,参数更少。
输入:和RNN一样,t时刻的输入和上一时刻的隐藏层输出
内部结构,主要包含两个门:重置门和更新门
重置门的计算过程: h ′ = t a n h ( w , [ x t , r ∗ h t − 1 ] ) h'=tanh(w,[x^t,r*h^{t-1}]) h′=tanh(w,[xt,r∗ht−1]),r可以控制h的更新
更新门的计算过程: h t = ( 1 − z ) ∗ h t − 1 + z ∗ h ′ h^t=(1-z)*h^{t-1}+z*h' ht=(1−z)∗ht−1+z∗h′,其中门控信号 z z z的范围为0~1。门控信号越接近1,代表”记忆“下来的数据越多;而越接近0则代表”遗忘“的越多。GRU很聪明的一点就在于,我们使用了同一个门控 [公式] 就同时可以进行遗忘和选择记忆(LSTM则要使用多个门控)。
内部思想与LSTM类似,重置门和更新门存在线性结构关系。
h ′ h' h′可以看成对应的实际上可以看成对应于LSTM中的hidden state;上一个节点传下来的 h t − 1 h^{t-1} ht−1 则对应于LSTM中的cell state。1-z对应的则是LSTM中的 z f z^f zfforget gate,那么 z我们似乎就可以看成是选择门 z i z^i zi