python常见面试题整理
文章目录
- 前言
- 1 关于*arg, **kwargs,我们为什么要使用它们?
- 2 装饰器
- 3 垃圾回收机制
- 4 多线程
- 5 模块os sys的不同之处
- 6 lambda表示式的作用
- 7 pass关键字的作用
- 8 Python是如何进行类型转换的?
- 9 浅拷贝和深拷贝
- 10 __new__和__init__的区别
- 11 Python中单下划线和双下划线分别是什么?
- 12 python自省(反射)
前言
看到知乎上一篇比较好的python面试题,本人在面试的过程中,被问到了不少,因此转载过来,作为笔记。与原文相比,略有改动。
1 关于*arg, **kwargs,我们为什么要使用它们?
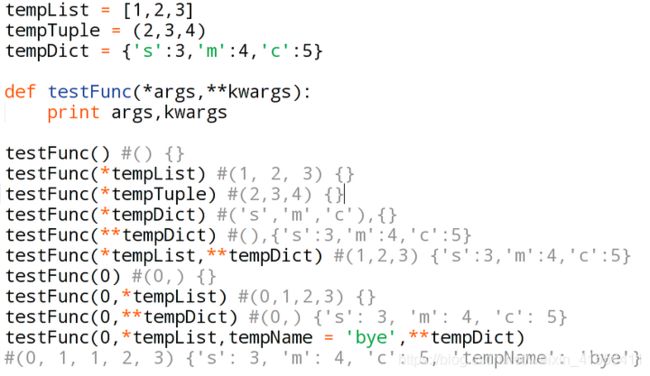
如果我们不确定往一个函数中传入多少参数,或者我们希望以元组(tuple)或者列表(list)的形式传参数的时候,我们可以使用args(单星号)。如果我们不知道往函数中传递多少个关键词参数或者想传入字典的值作为关键词参数的时候我们可以使用**kwargs(双星号),args、kwargs两个标识符是约定俗成的用法。另一种答法:当函数的参数前面有一个星号号的时候表示这是一个可变的位置参数,两个星号表示这个是一个可变的关键词参数。星号*把序列或者集合解包(unpack)成位置参数,两个星号把字典解包成关键词参数。 代码辅助理解:
2 装饰器
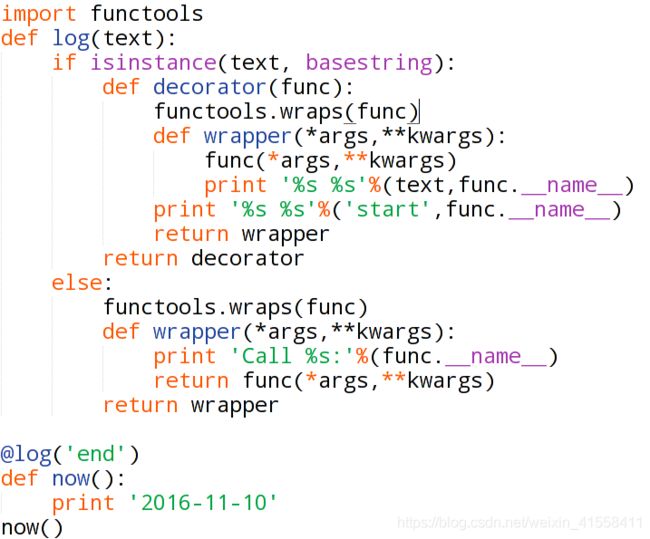
装饰器本质上是一个Python函数,它可以让其它函数在不作任何变动的情况下增加额外功能,装饰器的返回值也是一个函数对象。它经常用于有切面需求的场景。比如:插入日志、性能测试、事务处理、缓存、权限校验等。有了装饰器我们就可以抽离出大量的与函数功能无关的雷同代码进行重用。
有关于具体的装饰器的用法看这里:装饰器 - 廖雪峰的官方网站
3 垃圾回收机制
Python中的垃圾回收是以引用计数为主,标记-清除和分代收集为辅。 引用计数:Python在内存中存储每个对象的引用计数,如果计数变成0,该对象就会消失,分配给该对象的内存就会释放出来。 标记-清除:一些容器对象,比如list、dict、tuple,instance等可能会出现引用循环,对于这些循环,垃圾回收器会定时回收这些循环(对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边)。分代收集:Python把内存根据对象存活时间划分为三代,对象创建之后,垃圾回收器会分配它们所属的代。每个对象都会被分配一个代,而被分配更年轻的代是被优先处理的,因此越晚创建的对象越容易被回收。
如果你想要深入了解Python的GC机制,点击这里:[转载]Python垃圾回收机制–完美讲解!
4 多线程
Python并不支持真正意义上的多线程,Python提供了多线程包。Python中有一个叫Global Interpreter Lock(GIL)的东西,它能确保你的代码中永远只有一个线程在执行。经过GIL的处理,会增加执行的开销。这就意味着如果你先要提高代码执行效率,使用threading不是一个明智的选择,当然如果你的代码是IO密集型,多线程可以明显提高效率,相反如果你的代码是CPU密集型的这种情况下多线程大部分是鸡肋。 想要深入详细了解多线程,点击这里:详解Python中的多线程编程_python
想了解一下IO密集和CPU密集可以点击这里:CPU-bound(计算密集型) 和I/O bound(I/O密集型)
5 模块os sys的不同之处
官方文档: os模板提供了一种方便的使用操作系统函数的方法sys模板可供访问由解释器使用或维护的变量和与解释器交互的函数
另一种回答:os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口。sys模块负责程序与Python解释器的交互,提供了一系列的函数和变量用户操作Python运行时的环境。一些常用的方法:


一些常用的用法示例:
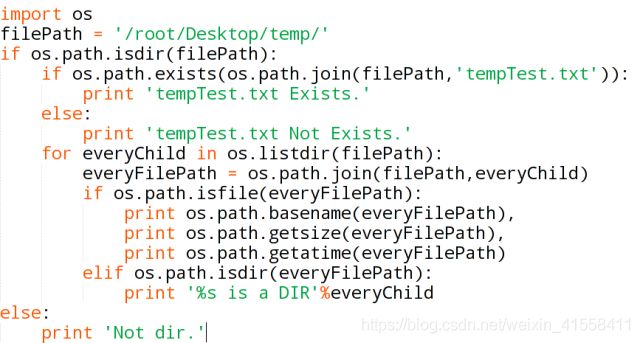
想要了解更详细的使用请访问:os和sys模块 - 君醉
6 lambda表示式的作用
简单来说,lambda表达式通常是当你需要使用一个函数,但是又不想费脑袋去命名一个函数的时候使用,也就是通常所说的匿名函数。lambda表达式一般的形式是:关键词lambda后面紧接一个或多个参数,紧接一个冒号“:”,紧接一个表达式。lambda表达式是一个表达式不是一个语句。

想更加详细的了解Python中的Lamdba表达式可以点击这里:Lambda 表达式有何用处?如何使用? - Python
7 pass关键字的作用
pass语句不会执行任何操作,一般作为占位符或者创建占位程序
8 Python是如何进行类型转换的?
Python提供了将变量或值从一种类型转换为另一种类型的内置方法。

9 浅拷贝和深拷贝
首先,我们知道Python3中,有6个标准的数据类型,他们又分为可变和不可变。
不可变数据(3个):
- Number(数字)
- String(字符串)
- Tuple(元组)
可变数据(3个): - List(列表)
- Dictionary(字典)
- Set(集合)
浅拷贝
copy模块里面的copy方法实现
1、对于 不可 变类型 Number String Tuple,浅复制仅仅是地址指向,不会开辟新空间。
2、对于 可 变类型 List、Dictionary、Set,浅复制会开辟新的空间地址(仅仅是最顶层开辟了新的空间,里层的元素地址还是一样的),进行浅拷贝
3、浅拷贝后,改变原始对象中为可变类型的元素的值,会同时影响拷贝对象的;改变原始对象中为不可变类型的元素的值,只有原始类型受影响。(操作拷贝对象对原始对象的也是同理)
深拷贝
copy模块里面的deepcopy方法实现
1、浅拷贝,除了顶层拷贝,还对子元素也进行了拷贝(本质上递归浅拷贝)
2、经过深拷贝后,原始对象和拷贝对象所有的元素地址都没有相同的了
浅拷贝
1、对于 不可 变类型 Number String Tuple,浅复制仅仅是地址指向,不会开辟新空间。
2、对于 可 变类型 List、Dictionary、Set,浅复制会开辟新的空间地址(仅仅是最顶层开辟了新的空间,里层的元素地址还是一样的),进行浅拷贝
3、浅拷贝后,改变原始对象中为可变类型的元素的值,会同时影响拷贝对象的;改变原始对象中为不可变类型的元素的值,只有原始类型受影响。 (操作拷贝对象对原始对象的也是同理)
import copy
origin = [1, [1, 2, 3]]
shallowcopy_origin = copy.copy(origin)
deepcopy_origin = copy.deepcopy(origin)
origin[0] = 2
origin[1][0] = 3
print("修改后的原始变量:",end='')
print(origin)
print("浅拷贝对象:", end='')
print(shallowcopy_origin)
print("深拷贝对象:",end='')
print(deepcopy_origin)
输出如下:
修改后的原始变量:[2, [3, 2, 3]]
浅拷贝对象:[1, [3, 2, 3]]
深拷贝对象:[1, [1, 2, 3]]
10 __new__和__init__的区别
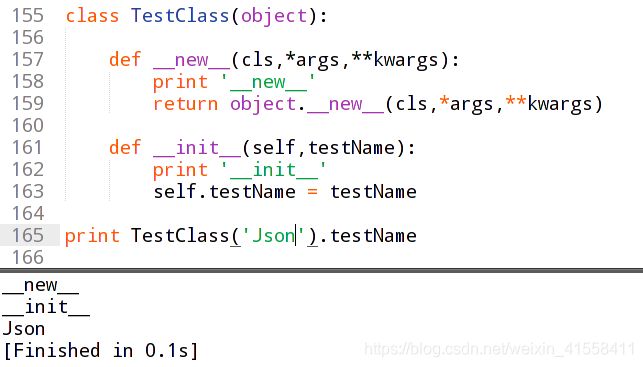
- __init__为初始化方法,__new__方法是真正的构造函数。
- __new__是实例创建之前被调用,它的任务是创建并返回该实例,是静态方法__init__是实例创建之后被调用的,然后设置对象属性的一些初始值。
总结:__new__方法在__init__方法之前被调用,并且__new__方法的返回值将传递给__init__方法作为第一个参数,最后__init__给这个实例设置一些参数。
想要更加详细的了解这两个方法,请点击:Python中的__new__及其用法
11 Python中单下划线和双下划线分别是什么?
- __name__:一种约定,Python内部的名字,用来与用户自定义的名字区分开,防止冲突。
- _name:一种约定,用来指定变量私有
- __name:解释器用_classname__name来代替这个名字用以区别和其他类相同的命名
想要更加详细的了解这两者的区别,请点击:Python中的下划线(译文)
12 python自省(反射)
自省就是面向对象的语言所写的程序在运行时,所能知道对象的类型。简单一句话就是运行时能够获得对象的类型。比如:type()、dir()、getattr()、hasattr()、isinstance()

想要完整的理解Python自省,请点击:Python自省(反射)指南