Lesson 4.3&4.4 梯度下降(Gradient Descent)基本原理与手动实现&随机梯度下降与小批量梯度下降
Lesson 4.3 梯度下降(Gradient Descent)基本原理与手动实现
在上一小节中,我们已经成功的构建了逻辑回归的损失函数,但由于逻辑回归模型本身的特殊性,我们在构造损失函数时无法采用类似SSE的计算思路(此时损失函数不是凸函数),因此最终的损失函数也无法用最小二乘法进行直接求解。当然,这其实也不仅仅是逻辑回归模型的“问题”,对于大多数机器学习模型来说,损失函数都无法直接利用最小二乘法进行求解。此时,就需要我们掌握一些可以针对更为一般函数形式进行最小值求解的优化方法。而在机器学习领域,最为基础、同时也最为通用的方法就是梯度下降算法。
本节我们将详细讨论梯度下降算法的基本原理和实现方法,并在此基础上尝试对逻辑回归损失函数进行求解。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
一、梯度下降基本原理与学习率
1.数据背景与最小二乘法求解
和此前介绍的极大似然估计法类似,梯度下降算法本身也属于数学理论推导相对复杂,但实际应用过程并不难理解的一种方法。因此,我们将先从一个简单的例子入手,通过和最小二乘法计算过程对比,来查看梯度下降的一般过程,然后我们再进行更加严谨的理论推导。
例如,有简单数据集表示如下:
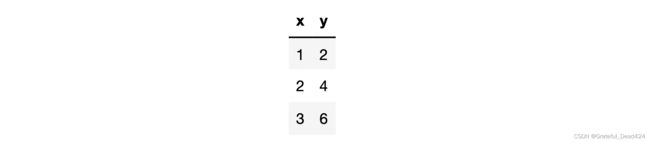
其中 x x x是数据集特征, y y y是数据集标签,假设,我们使用简单线性回归 y = w x y = wx y=wx对该组数据进行拟合,则此处我们可以构造损失函数如下:
SSELoss ( w ) = ( 2 − 1 ∗ w ) 2 + ( 4 − 2 ∗ w ) 2 + ( 6 − 3 ∗ w ) 2 = w 2 − 4 w + 4 + 4 w 2 − 16 w + 16 + 9 w 2 − 36 w + 36 = 14 w 2 − 56 w + 56 = 14 ( w 2 − 4 w + 4 ) = 14 ( w − 2 ) 2 \begin{aligned} \operatorname{SSELoss}(w) &=(2-1 * w)^{2}+(4-2 * w)^{2}+(6-3 * w)^{2} \\ &=w^{2}-4 w+4+4 w^{2}-16 w+16+9 w^{2}-36 w+36 \\ &=14 w^{2}-56 w+56 \\ &=14\left(w^{2}-4 w+4\right) \\ &=14(w-2)^{2} \end{aligned} SSELoss(w)=(2−1∗w)2+(4−2∗w)2+(6−3∗w)2=w2−4w+4+4w2−16w+16+9w2−36w+36=14w2−56w+56=14(w2−4w+4)=14(w−2)2
此时,损失函数 S S E L o s s ( w ) SSELoss(w) SSELoss(w)就是一个关于w的一元函数。围绕该损失函数进行最小值求解,可考虑使用最小二乘法进行计算,即令 S S E L o s s ( w ) SSELoss(w) SSELoss(w)导函数取值为0,此时有:
∂ S S E L o s s ( w ) ∂ ( w ) = 28 ( w − 2 ) = 0 \begin{aligned} \frac{\partial S S E L o s s(w)}{\partial(w)} &=28(w-2) \\ &=0 \end{aligned} ∂(w)∂SSELoss(w)=28(w−2)=0
因此, w w w的最优解为: w = 2 w=2 w=2
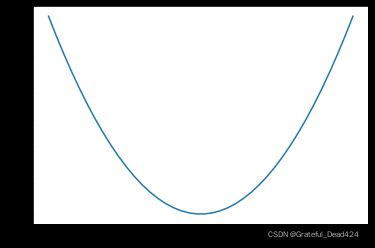
当然,我们也可以通过绘制一个图像来观察损失函数的基本情况:
x = np.linspace(-1, 5, 40)
SSELoss = 14 * np.power(x - 2, 2)
plt.plot(x, SSELoss)
2.一维梯度下降基本流程
当然,围绕上述形式非常简单的损失函数,我们也可以尝试使用梯度下降算法进行求解。首先梯度下降算法的目标仍然是求最小值,但和最小二乘法这种一步到位、通过解方程组直接求得最小值的方式不同,梯度下降是通过一种“迭代求解”的方式来进行最小值的求解,其整体求解过程可以粗略描述为,先随机选取一组参数初始值,然后沿着某个方向,一步一步移动到最小值点。例如:
show_trace(gd(lr = 0.01))
plt.plot(2, 0, 'ro')
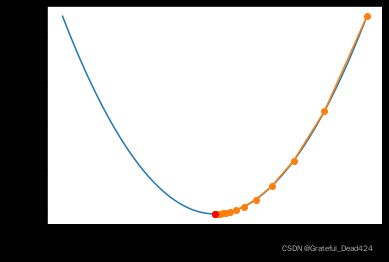
该图像的绘制函数会在稍后的内容中进行讲解
2.1 参数移动第一步
对照上述例子,我们可以将参数的第一次移动过程拆分为以下三步:
- Step 1.随机选取初始参数值
在上述例子中,参数只有一个,我们可以随机设置一个初始的参数值,例如我们令 w 0 = 10 w_0=10 w0=10。
- Step 2.基于 w 0 w_0 w0,确定参数移动方向
在上述例子中,由于参数组只有一个参数 w w w,因此参数的变化只有两个方向, w w w增加的方向和 w w w减少的方向。在梯度下降中,参数移动的目标是让损失函数取值减少,因此在上例中,由于 w w w初始取值为10,所以应该沿着 w w w减少的方向移动。
注意,如果损失函数包含多个参数的话,参数组变化方向就有多个,例如假设参数组包含两个参数 w = ( a , b ) w=(a,b) w=(a,b),则 w w w的变化就相当于是在 ( a , b ) (a, b) (a,b)这个二维平面上的点发生移动。
梯度的基本概念
当然,在实际计算过程中我们肯定无法通过观察来确定参数移动的方向,为确定更为一般情况下参数的移动方向,我们需要回顾Lesson 2中所介绍的关于梯度向量的相关概念。Lesson 2中我们曾提及,设 f ( x ) f(x) f(x)是一个关于 x x x的函数,其中 x x x是向量变元,并且 x = [ x 1 , x 2 , . . . , x n ] T x = [x_1, x_2,...,x_n]^T x=[x1,x2,...,xn]T
则 ∂ f ∂ x = [ ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ] T \frac{\partial f}{\partial x} = [\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n}]^T ∂x∂f=[∂x1∂f,∂x2∂f,...,∂xn∂f]T
而该表达式也被称为向量求导的梯度向量形式。
∇ x f ( x ) = ∂ f ∂ x = [ ∂ f ∂ x 1 , ∂ f ∂ x 2 , . . . , ∂ f ∂ x n ] T \nabla _xf(x) = \frac{\partial f}{\partial x} = [\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, ..., \frac{\partial f}{\partial x_n}]^T ∇xf(x)=∂x∂f=[∂x1∂f,∂x2∂f,...,∂xn∂f]T
进一步的,如果假设 f ( x ) f(x) f(x)是关于参数 x x x的损失函数,则 ∇ x f ( x ) \nabla _xf(x) ∇xf(x)就是损失函数的梯度向量,或者梯度表达式。而当损失函数的参数 x x x选定一组取值之后,我们就能计算梯度表达式的取值,该值也被称为损失函数在某组参数取值下的梯度。
例如,在上例中,损失函数 f ( w ) = 14 ( w − 2 ) 2 f(w) = 14(w-2)^2 f(w)=14(w−2)2
损失函数的梯度向量表示形式为: ∇ w f ( w ) = ∂ f ∂ w = 28 ( w − 2 ) \nabla _wf(w) = \frac{\partial f}{\partial w}=28(w-2) ∇wf(w)=∂w∂f=28(w−2)
具体来看,当 w 0 = 10 w_0=10 w0=10时,梯度计算结果为 ∇ w f ( w 0 ) = 28 ( 10 − 2 ) = 28 ∗ 8 = 224 \nabla _wf(w_0)=28(10-2)=28*8=224 ∇wf(w0)=28(10−2)=28∗8=224
在确定了梯度之后,接下来参数的移动方向也随之确定,在梯度下降算法中,参数的移动方向是梯度的负方向。
注意,这里有两点需要注意,其一是梯度的负方向,上述计算结果中,224既是梯度的取值,同时也代表着梯度的方向——正方向。而此时梯度的负方向则是取值减少的方向,和损失函数图像观测结果相同。其二是参数的移动是朝着梯度的负方向移动,也就是朝着数值减少的方向移动,而不是直接在原参数10的基础上减去224,这很明显是不合适的。
对于只包含一个变量的损失函数来说,梯度也就是函数某点的导数。
- Step 3.确定移动步长并进行移动
在确定移动的方向之后,接下来需要进一步确定移动距离。在梯度下降中,我们采用梯度乘以某个人工设置的参数作为每一步移动的距离,这个参数被称为步长或者学习率(Learning rate),例如在上述案例中,我们可以设置学习率为lr = 0.01,则从 w 0 w_0 w0进行移动的距离是 0.01 ∗ 224 = 2.24 0.01 * 224 = 2.24 0.01∗224=2.24,而又是朝向梯度的负方向进行移动,因此 w 0 w_0 w0最终移动到了 w 1 = 10 − 2.24 = 7.76 w_1 = 10-2.24 = 7.76 w1=10−2.24=7.76
相比于步长,将人工设置的参数称为学习率会更加贴切,该参数并不代表真实移动的距离,而是影响真实移动距离的一个“比率”,或者说是真实移动距离学习梯度值的“比率”。
至此,参数 w w w就完成了第一次移动, w 0 → w 1 w_0 \rightarrow w_1 w0→w1。
2.2 梯度下降的多轮迭代
当然, w w w从 w 0 w_0 w0移动到 w 1 w_1 w1其实只移动了一步,要最终抵达损失函数的最小值点 w = 2 w=2 w=2,还有很长一段距离,因此我们还需要移动多次。参数多次移动过程中的每一步其实都是在重复上述三个步骤。例如,当我们需要第二次移动 w w w时,过程如下:
w 2 = w 1 − l r ⋅ ∇ w f ( w 1 ) w_2 = w_1 - lr \cdot \nabla _wf(w_1) w2=w1−lr⋅∇wf(w1)
即 w 2 w_2 w2等于 w 1 w_1 w1沿着 w 1 w_1 w1的负梯度方向移动了 l r ⋅ ∇ w f ( w 1 ) lr\cdot\nabla _wf(w_1) lr⋅∇wf(w1)距离之后得到的结果。此时我们是在 w 1 w_1 w1的基础上,减去学习率和 w 1 w_1 w1梯度的乘积。
当然,依此类推,当从 w ( n − 1 ) w_{(n-1)} w(n−1)移动到 w n w_n wn时 w n w_n wn的计算公式如下:
w n = w ( n − 1 ) − l r ⋅ ∇ w f ( w ( n − 1 ) ) w_n = w_{(n-1)} - lr \cdot \nabla _wf(w_{(n-1)}) wn=w(n−1)−lr⋅∇wf(w(n−1))
并且,我们可以称从 w 0 w_0 w0移动到 w 1 w_1 w1是第一轮迭代,从 w 1 w_1 w1移动到 w 2 w_2 w2是第二轮迭代,从 w ( n − 1 ) w_{(n-1)} w(n−1)移动到 w n w_n wn是第n轮迭代。
迭代其实是一个数学意义上的概念,一般指以下计算流程:某次运算时初始条件是上一次运算的结果,而当前运算的结果则是下一次计算的初始条件。
而通过带入梯度值进行多轮迭代,最终使得损失函数的取值逐渐下降的算法,就被称为梯度下降。
2.梯度下降算法特性与学习率
首先,我们简单验证,经过上述梯度下降的一系列计算,最终能否有效降低损失函数的计算结果,即使得 w w w最终朝向最优值2靠拢。我们可以通过定义一个函数来帮助我们进行梯度下降迭代计算。
def gd(lr = 0.02, itera_times = 20, w = 10):
"""
梯度下降计算函数
:param lr: 学习率
:param itera_times:迭代次数
:param w:参数初始取值
:return results:每一轮迭代的参数计算结果列表
"""
results = [w]
for i in range(itera_times):
w -= lr * 28 * (w - 2) # 梯度计算公式
results.append(w)
return results
当我们在以0.02作为学习率,初始值为10,迭代20轮时参数每一轮迭代后参数的计算结果如下:
res = gd()
res
#[10,
# 5.52,
# 3.5488,
# 2.681472,
# 2.29984768,
# 2.1319329792,
# 2.058050510848,
# 2.02554222477312,
# 2.0112385789001728,
# 2.004944974716076,
# 2.0021757888750735,
# 2.0009573471050324,
# 2.000421232726214,
# 2.000185342399534,
# 2.000081550655795,
# 2.00003588228855,
# 2.000015788206962,
# 2.0000069468110633,
# 2.000003056596868,
# 2.000001344902622,
# 2.000000591757154]
我们发现,参数从10开始朝向2移动,并且迭代20轮时已经非常接近全域最优解2,此处也验证梯度下降确实能够帮助我们找到最优解。当然,我们也可以将上述参数移动过程和损失函数的函数图像绘制到一张画布上,具体功能可以通过如下函数实现:
def show_trace(res):
"""
梯度下降轨迹绘制函数
"""
f_line = np.arange(-6, 10, 0.1)
plt.plot(f_line, [14 * np.power(x-2, 2) for x in f_line])
plt.plot(res, [14 * np.power(x-2, 2) for x in res], '-o')
plt.xlabel('x')
plt.ylabel('Loss(x)')
show_trace(res)
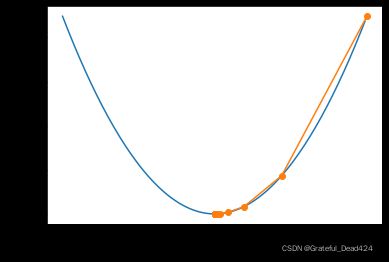
接下来,我们在此基础之上,详细讨论梯度下降算法的基本特性与超参数取值一般规范。
从图像上,我们发现,梯度下降的计算过程中,刚开始 w w w变化非常快,而随着逐渐接近最小值点 w w w的变化幅度逐渐减少,也就是说,梯度下降其实并不是一个等步长的移动过程。当然,根据梯度下降的计算公式, w ( n − 1 ) w_{(n-1)} w(n−1)和 w n w_{n} wn的差值是: ∣ w n − w ( n − 1 ) ∣ = ∣ l r ⋅ ∇ w f ( w ( n − 1 ) ) ∣ |w_n - w_{(n-1)}| = |lr \cdot \nabla _wf(w_{(n-1)})| ∣wn−w(n−1)∣=∣lr⋅∇wf(w(n−1))∣
而lr又是一个恒定的数值,那么也就是说,每个点的梯度值是不一样的(哪怕梯度方向一样),并且越靠近最小值点梯度值越小,当然这点从梯度计算公式也能看出: ∇ w f ( w ) = ∂ f ∂ w = 28 ( w − 2 ) \nabla _wf(w) = \frac{\partial f}{\partial w}=28(w-2) ∇wf(w)=∂w∂f=28(w−2)
当然,这也就等价说明,如果某点的梯度值相对较大,那么该点应该距离全域最小值较远。而梯度下降过程中实际也能够做到在远点迭代移动距离较大、近点迭代移动距离较小。当然,在学习率对移动距离进行修正时,学习率不宜设置过小,也不宜设置过大,例如当学习率设置过小时:
plt.subplot(121)
plt.title('lr=0.001')
show_trace(gd(lr=0.001))
plt.subplot(122)
plt.title('lr=0.01')
show_trace(gd(lr=0.01))
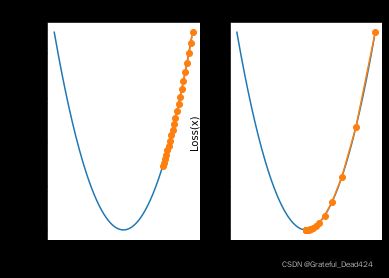
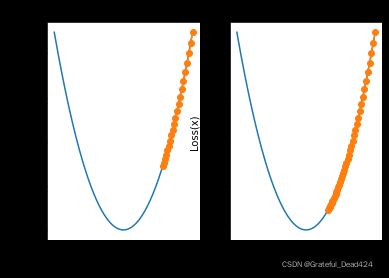
当学习率取值为0.001时,迭代20轮仍然距离最小值点差距较远,此时我们考虑进一步增加迭代次数:
plt.subplot(121)
plt.title('itera_times=20')
show_trace(gd(itera_times=20, lr=0.001))
plt.subplot(122)
plt.title('itera_times=40')
show_trace(gd(itera_times=40, lr=0.001))
plt.subplot(121)
plt.title('itera_times=60')
show_trace(gd(itera_times=60, lr=0.001))
plt.subplot(122)
plt.title('itera_times=80')
show_trace(gd(itera_times=80, lr=0.001))
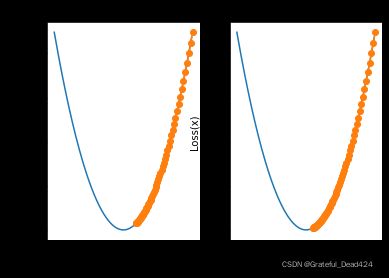
此处学习率为0.001取值的情况下,迭代次数增加了三倍但仍然没有收敛到2附近,需要迭代80次左右才能收敛至较好效果。而过多次的迭代会增加额外计算量,也就是说如果学习率取值较小,则会耗费更多的计算量。
接下来我们再来看当学习率取值过大时可能出现的状况。当我们将学习率设置为0.05时,迭代过程如下所示:
plt.subplot(121)
plt.title('lr=0.01')
show_trace(gd(lr=0.01))
plt.subplot(122)
plt.title('lr=0.05')
show_trace(gd(lr=0.05))
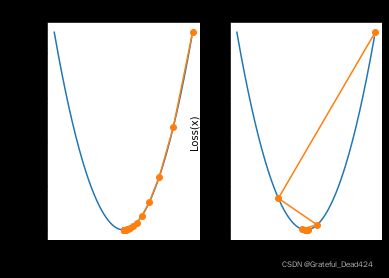
我们发现当学习率较大时,收敛过程并不平稳,当然小幅度不平稳并不影响最终收敛结果,但学习率继续增加,例如我们将学习率增加至0.08时,参数整体迭代过程不仅不会收敛,而且还会逐渐发散:
show_trace(gd(lr=0.08))
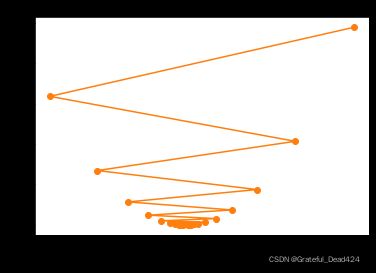
gd(lr=0.08)
#[10,
# -7.920000000000002,
# 14.300800000000006,
# -13.25299200000001,
# 20.913710080000012,
# -21.45300049920002,
# 31.081720619008028,
# -34.06133356756996,
# 46.71605362378676,
# -53.447906493495594,
# 70.75540405193455,
# -83.25670102439885,
# 107.71830927025458,
# -129.0907034951157,
# 164.55247233394346,
# -199.56506569408992,
# 251.94068146067156,
# -307.92644501123283,
# 386.30879181392874,
# -474.5429018492717,
# 592.9131982930971]
由此我们不难发现学习率取值是影响结果是否收敛、以及能否在有限次迭代次数中高效收敛的关键参数。学习率过大会导致结果发散,而学习率过小则又会导致模型无法收敛至最优结果。更多关于学习率参数调整策略,我们会在后续建模环节中逐步介绍。
不同损失函数选取方式或者数值处理方法对梯度下降过程中移动距离的影响相关讨论
这里需要知道的是,影响迭代收敛结果的是每一步移动的真实距离,而移动的真实距离又和学习率和梯度二者相关,有的时候我们可以通过一些数值处理手段等比例缩小梯度,此时学习率就可以稍微设置大些。例如此处如果我们采用MSE计算公式作为损失函数,则梯度计算公式就由原先的 28 ( w − 2 ) 28(w-2) 28(w−2)变为了 28 ( w − 2 ) 3 \frac{28(w-2)}{3} 328(w−2)(总共三条样本, M S E = S S E 3 MSE=\frac{SSE}{3} MSE=3SSE)。而此时就相当于梯度减少至原先的1/3,在学习率不变的情况下,每次移动的距离也将减少至原先的1/3。而在另外一种情况下,也就是例如数据归一化,即对带入的数据进行数值调整的一种方法(后续会介绍)。如果带入损失函数计算的数值大幅减少,则最终的梯度也会受其影响,数值也会有所减少,此时同样在学习率不变的情况下每次移动的距离也会减少。
移动距离衰减
此外,此处还有一个重要结论,那就是参数点越远离最小值点,参数点的梯度就相对较大,此时每次迭代移动的距离就相对较大,而如果参数点比较靠近最小值点,此时梯度取值较小,每次移动的距离就比较小。而当已经非常接近最小值点时,每次移动的距离就会变得非常小,因此我们其实无论增加多少轮迭代,只要参数不会发散,最终参数值点都不可能“跨过”最小值点。
二、梯度下降一般建模流程与多维梯度下降
1.多维梯度下降与损失函数可视化
一种更为一般的情况是,一个模型中包含多个参数,而损失函数就是这多个参数共同构成的函数。例如在Lesson 1中我们曾利用带截距项的简单线性回归 y = w x + b y=wx+b y=wx+b对下述数据进行拟合,并得出带有两个参数的损失函数:

S S E L o s s ( w , b ) = ( y 1 − y ^ 1 ) 2 + ( y 2 − y ^ 2 ) 2 = ( 2 − w − b ) 2 + ( 4 − 3 w − b ) 2 SSELoss(w, b) = (y_1 - ŷ_1)^2 + (y_2 - ŷ_2)^2 = (2 - w - b)^2 + (4 - 3w - b)^2 SSELoss(w,b)=(y1−y^1)2+(y2−y^2)2=(2−w−b)2+(4−3w−b)2
而此时损失函数图像就是包含两个变量的三维图像
from mpl_toolkits.mplot3d import Axes3D
x = np.arange(-1,3,0.05)
y = np.arange(-1,3,0.05)
w, b = np.meshgrid(x, y)
SSE = (2 - w - b) ** 2 + (4 - 3 * w - b) ** 2
ax = plt.axes(projection='3d')
ax.plot_surface(w, b, SSE, cmap='rainbow')
ax.contour(w, b, SSE, zdir='z', offset=0, cmap="rainbow") #生成z方向投影,投到x-y平面
plt.xlabel('w')
plt.ylabel('b')
plt.show()
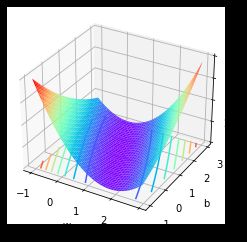
并且,我们通过最小二乘法能够找出全域最小值点为(1,1),也就是当 w = 1 , b = 1 w=1,b=1 w=1,b=1时,能够让损失函数取值最小。当然,围绕该问题,我们也可以采用梯度下降进行最优解求解。
2.梯度下降计算流程
此处给出更加严谨的梯度下降实现步骤:
- Step 1.确定数据及模型
首先还是要明确数据和模型,然后才能进一步确定参数、梯度计算公式等变量。此处我们以 y = w x + b y=wx+b y=wx+b简单线性回归对上述简单数据集进行拟合,参数向量包含两个分量。
- Step 2.设置初始参数值
然后我们需要选取一组参数值,一种更加通用的方法,是给初始参数赋予一组随机数作为初始取值。由于参数包含两个分量,因此参数向量的初始值可以由如下过程确定:
np.random.seed(24)
w = np.random.randn(2, 1) # 参数都默认为列向量
w
#array([[ 1.32921217],
# [-0.77003345]])
- Step 3.根据损失函数求出梯度表达式
只有确定了梯度表达式,才能在后续每一轮迭代过程中快速计算梯度。线性回归的损失函数是围绕SSE及其衍生的指标所构建的损失函数,此处以MSE作为损失函数的构建指标,此处可借助已经定义好的SSELoss函数执行计算。
S S E L o s s ( w ^ ) = ∣ ∣ y − X w ^ ∣ ∣ 2 2 = ( y − X w ^ ) T ( y − X w ^ ) SSELoss(\hat w) = ||y - X\hat w||_2^2 = (y - X\hat w)^T(y - X\hat w) SSELoss(w^)=∣∣y−Xw^∣∣22=(y−Xw^)T(y−Xw^) M S E L o s s ( w ^ ) = ∣ ∣ y − X w ^ ∣ ∣ 2 2 m = ( y − X w ^ ) T ( y − X w ^ ) m MSELoss(\hat w) = \frac{||y - X\hat w||_2^2}{m} = \frac{(y - X\hat w)^T(y - X\hat w)}{m} MSELoss(w^)=m∣∣y−Xw^∣∣22=m(y−Xw^)T(y−Xw^)
其中m为训练数据总数。
def MSELoss(X, w, y):
"""
MSE指标计算函数
"""
SSE = SSELoss(X, w, y)
MSE = SSE / X.shape[0]
return MSE
此时数据为:
features = np.array([1, 3]).reshape(-1, 1)
features = np.concatenate((features, np.ones_like(features)), axis=1)
features
#array([[1, 1],
# [3, 1]])
labels = np.array([2, 4]).reshape(-1, 1)
labels
#array([[2],
# [4]])
# 计算w取值时SSE
SSELoss(features, w, labels)
#array([[2.68811092]])
# 计算w取值时MSE
MSELoss(features, w, labels)
#array([[1.34405546]])
而对于线性回归损失函数梯度表达式,则可根据Lesson 2中线性回归损失函数梯度求导结果得出: S S E L o s s ( w ^ ) ∂ w ^ = ∂ ∣ ∣ y − X w ^ ∣ ∣ 2 2 ∂ w ^ = ∂ ( y − X w ^ ) T ( y − X w ^ ) ∂ w ^ = ∂ ( y T − w ^ T X T ) ( y − X w ^ ) ∂ w ^ = ∂ ( y T y − w ^ T X T y − y T X w ^ + w ^ T X T X w ^ ) ∂ w ^ = 0 − X T y − X T y + X T X w ^ + ( X T X ) T w ^ = 0 − X T y − X T y + 2 X T X w ^ = 2 ( X T X w ^ − X T y ) = 2 X T ( X w ^ − y ) \begin{aligned} \frac{SSELoss(\hat w)}{\partial{\boldsymbol{\hat w}}} &= \frac{\partial{||\boldsymbol{y} - \boldsymbol{X\hat w}||_2}^2}{\partial{\boldsymbol{\hat w}}} \\ &= \frac{\partial(\boldsymbol{y} - \boldsymbol{X\hat w})^T(\boldsymbol{y} - \boldsymbol{X\hat w})}{\partial{\boldsymbol{\hat w}}} \\ & =\frac{\partial(\boldsymbol{y}^T - \boldsymbol{\hat w^T X^T})(\boldsymbol{y} - \boldsymbol{X\hat w})}{\partial{\boldsymbol{\hat w}}}\\ &=\frac{\partial(\boldsymbol{y}^T\boldsymbol{y} - \boldsymbol{\hat w^T X^Ty}-\boldsymbol{y}^T\boldsymbol{X \hat w} +\boldsymbol{\hat w^TX^T}\boldsymbol{X\hat w})}{\partial{\boldsymbol{\hat w}}}\\ & = 0 - \boldsymbol{X^Ty} - \boldsymbol{X^Ty}+X^TX\hat w+(X^TX)^T\hat w \\ &= 0 - \boldsymbol{X^Ty} - \boldsymbol{X^Ty} + 2\boldsymbol{X^TX\hat w}\\ &= 2(\boldsymbol{X^TX\hat w} - \boldsymbol{X^Ty}) \\ &= 2X^T(X\hat w -y) \end{aligned} ∂w^SSELoss(w^)=∂w^∂∣∣y−Xw^∣∣22=∂w^∂(y−Xw^)T(y−Xw^)=∂w^∂(yT−w^TXT)(y−Xw^)=∂w^∂(yTy−w^TXTy−yTXw^+w^TXTXw^)=0−XTy−XTy+XTXw^+(XTX)Tw^=0−XTy−XTy+2XTXw^=2(XTXw^−XTy)=2XT(Xw^−y)
此处我们使用MSE作为损失函数,则该损失函数的梯度表达式为:
M S E L o s s ( w ^ ) ∂ w ^ = 2 X T ( X w ^ − y ) m \frac{MSELoss(\hat w)}{\partial{\boldsymbol{\hat w}}} = \frac{2X^T(X\hat w -y)}{m} ∂w^MSELoss(w^)=m2XT(Xw^−y)
注:矩阵运算也是可以提取公因式的
据此我们可以定义线性回归的梯度计算函数
def lr_gd(X, w, y):
"""
线性回归梯度计算公式
"""
m = X.shape[0]
grad = 2 * X.T.dot((X.dot(w) - y)) / m
return grad
# 计算w取值时梯度
lr_gd(features, w, labels)
#array([[-3.78801208],
# [-2.22321821]])
该步骤其实也是在手动实现梯度下降计算过程中至关重要的一步,正如此前所介绍的,只有将方程组转化为矩阵形式,才能更好的利用程序进行计算。但值得注意的是,并不是所有的损失函数的梯度计算都能简单表示成矩阵运算形式。
- Step 4.执行梯度下降迭代
在给定梯度计算公式和参数初始值的情况下,我们就能够开始进行梯度下降迭代计算了。在梯度下降过程中,参数更新参照如下公式: w n = w ( n − 1 ) − l r ⋅ ∇ w f ( w ( n − 1 ) ) w_n = w_{(n-1)} - lr \cdot \nabla _wf(w_{(n-1)}) wn=w(n−1)−lr⋅∇wf(w(n−1))
则可定义相应函数:
def w_cal(X, w, y, gd_cal, lr = 0.02, itera_times = 20):
"""
梯度下降中参数更新函数
:param X: 训练数据特征
:param w: 初始参数取值
:param y: 训练数据标签
:param gd_cal:梯度计算公式
:param lr: 学习率
:param itera_times: 迭代次数
:return w:最终参数计算结果
"""
for i in range(itera_times):
w -= lr * gd_cal(X, w, y)
return w
接下来执行梯度下降计算,在学习率为0.1的情况下迭代100轮:
np.random.seed(24)
w = np.random.randn(2, 1) # 参数都默认为列向量
w
#array([[ 1.32921217],
# [-0.77003345]])
w = w_cal(features, w, labels, gd_cal = lr_gd, lr = 0.1, itera_times = 100)
w
#array([[1.02052278],
# [0.95045363]])
# 计算w取值时SSE
SSELoss(features, w, labels)
#array([[0.0009869]])
# 计算w取值时MSE
MSELoss(features, w, labels)
#array([[0.00049345]])
# 计算w取值时梯度
lr_gd(features, w, labels)
#array([[ 0.0070423 ],
# [-0.01700163]])
我们发现,最终参数结果逼近(1,1)点,也就是说整体计算过程能够在迭代多轮之后逼近全域最小值点。据此也验证了梯度下降本身的有效性。当然,此处是以二维梯度下降为例进行的展示,更高维度的梯度下降过程也是类似,并且可以借助NumPy当中数组的优秀性质来完成相关梯度的计算。
3.二维梯度下降过程的可视化展示
3.1 等高线图
为了方便后续其他梯度下降算法的性质展示,我们通过绘制损失函数的等高线图来观察二维梯度下降过程中参数点移动的过程。首先在上述迭代100次的过程中,我们可以记录每一次迭代的计算结果:
def w_cal_rec(X, w, y, gd_cal, lr = 0.02, itera_times = 20):
w_res = [np.copy(w)]
for i in range(itera_times):
w -= lr * gd_cal(X, w, y)
w_res.append(np.copy(w))
return w, w_res
np.random.seed(24)
w = np.random.randn(2, 1)
w, w_res = w_cal_rec(features, w, labels, gd_cal = lr_gd, lr = 0.1, itera_times = 100)
w_res
#[array([[ 1.32921217],
# [-0.77003345]]),
# array([[ 1.70801338],
# [-0.54771163]]),
# ...
# array([[1.02125203],
# [0.94869305]]),
# array([[1.02052278],
# [0.95045363]])]
# 所有点的横坐标
np.array(w_res)[:, 0]
#array([[1.32921217],
# [1.70801338],
# [1.61908465],
# ...
# [1.0220072 ],
# [1.02125203],
# [1.02052278]])
- 参数移动轨迹图
据此我们可以将所有点在迭代过程的移动轨迹绘制在图片上:
plt.plot(np.array(w_res)[:, 0], np.array(w_res)[:, 1], '-o', color='#ff7f0e')
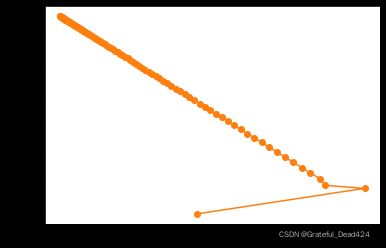
我们发现,参数在参数平面上的移动轨迹其实并不是一条直线。当然,我们也可以通过等高线图来观察参数点逼近(1,1)点的移动情况。
# 网格点坐标
x1, x2 = np.meshgrid(np.arange(1, 2, 0.001), np.arange(-1, 1, 0.001))
其中np.meshgrid生成两个序列,第一个序列根据输入的第一个参数按照列排列,第二个序列根据输入的第二个参数按行排列。该函数输出结果主要用于带网格的图像绘制情况。
np.meshgrid(np.arange(3), np.arange(1, 5))
#[array([[0, 1, 2],
# [0, 1, 2],
# [0, 1, 2],
# [0, 1, 2]]),
# array([[1, 1, 1],
# [2, 2, 2],
# [3, 3, 3],
# [4, 4, 4]])]
# 绘制等高线图
plt.contour(x1, x2, (2-x1-x2)**2+(4-3*x1-x2)**2)
# 绘制参数点移动轨迹图
plt.plot(np.array(w_res)[:, 0], np.array(w_res)[:, 1], '-o', color='#ff7f0e')
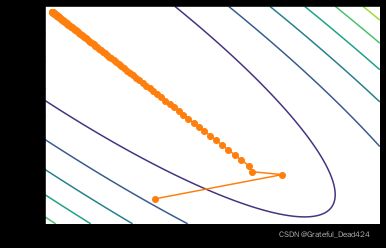
其中,等高线图要求输入网格的范围和间隔(即x1和x2),以及输入对应函数关系(即x1和x2二者作为自变量的函数表达式)。
3.2 损失函数取值变化图
从一个更加严谨的角度,我们可以绘制其损失函数变化曲线:
loss_value = np.array([MSELoss(features, np.array(w), labels) for w in w_res]).flatten()
loss_value
#array([1.34405546e+00, 5.18623852e-01, 4.63471078e-01, 4.31655465e-01,
# 4.02524386e-01, 3.75373031e-01, 3.50053485e-01, 3.26441796e-01,
# 3.04422755e-01, 2.83888935e-01, 2.64740155e-01, 2.46882992e-01,
# ...
# 8.62721840e-04, 8.04529820e-04, 7.50262948e-04, 6.99656466e-04,
# 6.52463476e-04, 6.08453732e-04, 5.67412517e-04, 5.29139601e-04,
# 4.93448257e-04])
plt.plot(np.arange(101), loss_value)
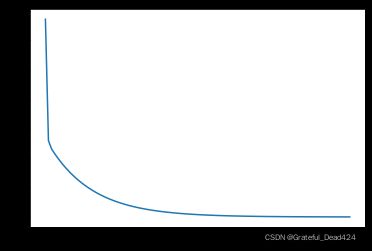
能够发现,在梯度下降过程中损失值是严格递减的。当然我们也可以将上述过程分装为一个函数:
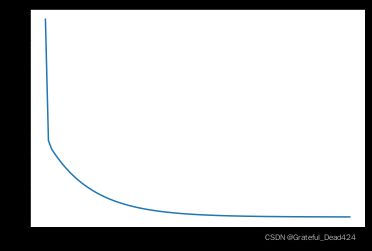
def loss_vis(X, w_res, y, loss_func):
loss_value = np.array([loss_func(X, np.array(w), y) for w in w_res]).flatten()
plt.plot(np.arange(len(loss_value)), loss_value)
# 验证函数是否可执行
loss_vis(features, w_res, labels, MSELoss)
4.线性回归的梯度下降求解过程
在掌握梯度下降基本原理即基本性质之后,我们可以尝试在手动创建的线性回归数据集上进行梯度下降方法的参数求解。还是围绕Lesson 3.3中的数据集进行线性回归参数求解,梯度下降求解过程仍然按照上述过程执行:
- Step 1.确定数据集和模型
仍然还是创建扰动项不大、基本满足 y = 2 x 1 − x 2 + 1 y=2x_1-x_2+1 y=2x1−x2+1规律的数据集。
# 设置随机数种子
np.random.seed(24)
# 扰动项取值为0.01
features, labels = arrayGenReg(delta=0.01)
- Step 2.设置初始参数
np.random.seed(24)
w = np.random.randn(3, 1)
w
#array([[ 1.32921217],
# [-0.77003345],
# [-0.31628036]])
- Step 3.构建损失函数与梯度表达式
# 计算w取值时SSE
SSELoss(features, w, labels)
#array([[2093.52940481]])
# 计算w取值时MSE
MSELoss(features, w, labels)
#array([[2.0935294]])
# 计算w取值时梯度
lr_gd(features, w, labels)
#array([[-1.15082596],
# [ 0.3808195 ],
# [-2.52877477]])
- Step 4.执行梯度下降计算
接下来,借助此前所定义的参数更新函数进行梯度下降参数求解:
w = w_cal(features, w, labels, gd_cal = lr_gd, lr = 0.1, itera_times = 100)
w
#array([[ 1.99961892],
# [-0.99985281],
# [ 0.99970541]])
# 计算w取值时SSE
SSELoss(features, w, labels)
#array([[0.09300731]])
# 计算w取值时MSE
MSELoss(features, w, labels)
#array([[9.30073138e-05]])
至此,我们就完成了梯度下降算法的手动实现过程。
三、梯度下降算法评价
1.梯度下降算法优势
本节我们以线性回归的损失函数构建了梯度表达式来进行梯度下降的计算,尽管线性回归的损失函数可以用最小二乘法直接进行求解,但梯度下降算法在某些场景下仍然具备一定优势,这些优势主要体现在两个方面,其一是相比大规模数值矩阵运算,梯度下降所遵循的迭代求解效率更高(尽管大规模矩阵运算也可以通过分块矩阵的划分来减少每一次计算的数据量),其二则是对于某些最小二乘法无法计算全域唯一最优解的情况,梯度下降仍然能够有效进行最小值点(或者解空间)的寻找。
数值解和解析解
对于通过严格数学公式计算得出的结果,类似最小二乘法计算结果,也被称为解析解。而由某种计算方法或者计算流程得出的结果,例如梯度下降算得的结果,也被称为数值解。
2.梯度下降算法局限
但是,对于上述梯度下降算法还是存在一定的局限性。当损失函数不是凸函数时,也就是有可能存在局部最小值或者鞍点时,梯度下降并不一定能够准确找到全域最小值。
2.1 局部最小值点(local minimun)陷阱
所谓局部最小值,指的是该点左右两端取值都大于该点,但是该点不是全域最小值点。例如函数: f ( x ) = x ⋅ c o s ( π x ) f(x)=x\cdot cos(\pi x) f(x)=x⋅cos(πx)
该函数函数图像如下:
x = np.arange(-1, 2, 0.1)
y = x * np.cos(np.pi * x)
fig = plt.plot(x, y)[0]
fig.axes.annotate('local minimun', xytext=(-0.77, -1),
arrowprops=dict(arrowstyle='->'), xy=(-0.3, -0.25))
fig.axes.annotate('global minimun', xytext=(0.6, 0.8),
arrowprops=dict(arrowstyle='->'), xy=(1.1, -0.95))
plt.xlabel('x')
plt.ylabel('x·cos(pi·x)')
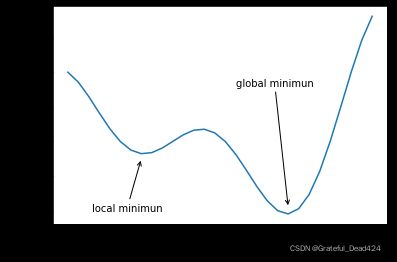
注,其中plt.plot(x, y)[0]是返回图像对象,axes.annotate是在图像上添加文字或图形,xytext是文字起始坐标,xy是图形起始坐标。
根据此前所介绍的梯度下降的距离衰减理论,由于局部最小值点梯度也是零,因此如果参数点陷入局部最小值,则不可能跨过局部最小值抵达全域最小值点。假设 f ( x ) = x ⋅ c o s ( π x ) f(x)=x\cdot cos(\pi x) f(x)=x⋅cos(πx)就是此时的损失函数,并且此时存在唯一的参数x,则梯度下降迭代计算有如下过程。
注,此处我们在未知数据、模型和评估指标的情况下,直接给出了损失函数。
首先是由损失函数到梯度计算表达式的过程,由于损失函数只有一个参数,所以梯度表达式为 f ′ ( x ) = ( x ⋅ c o s ( π x ) ) ′ = c o s ( π x ) + x ⋅ ( − s i n ( π x ) ) ⋅ π f'(x) = (x\cdot cos(\pi x))' = cos(\pi x) + x\cdot (-sin(\pi x)) \cdot \pi f′(x)=(x⋅cos(πx))′=cos(πx)+x⋅(−sin(πx))⋅π
我们可以定义该函数的函数表达式函数及导函数函数表达式。
def f_1(x):
return (x*np.cos(np.pi*x))
f_1(-1)
#1.0
def f_gd_1(x):
return (np.cos(np.pi*x)-x*np.pi*(np.sin(np.pi*x)))
f_gd_1(-1)
#-1.0000000000000004
以及相应的梯度更新函数
def gd_1(lr = 0.02, itera_times = 20, w = -1):
"""
梯度下降计算函数
:param lr: 学习率
:param itera_times:迭代次数
:param w:参数初始取值
:return results:每一轮迭代的参数计算结果列表
"""
results = [w]
for i in range(itera_times):
w -= lr * f_gd_1(w) # 梯度计算公式
results.append(w)
return results
当我们在以0.02作为学习率,参数初始值为-1,迭代5000轮时参数每一轮迭代后参数的计算结果如下:
res = gd_1(itera_times = 5000)
res[-1]
#-0.2738526868008511
我们发现,参数最终在停留在-0.27附近。当然,对于上述一维梯度下降,我们也可以绘制对应参数变化的轨迹图来进行观察。
def show_trace_1(res):
"""
梯度下降轨迹绘制函数
"""
f_line = np.arange(-1, 2, 0.01)
plt.plot(f_line, [f_1(x) for x in f_line])
plt.plot(res, [f_1(x) for x in res], '-o')
plt.xlabel('x')
plt.ylabel('Loss(x)')
show_trace_1(res)
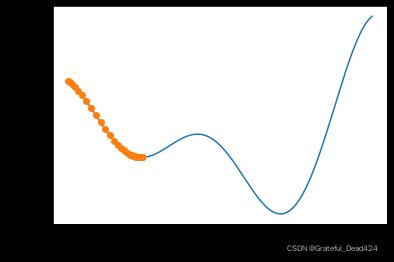
我们发现,参数最终停留在局部最小值附近,并且无法跨越该局部最小值点。而根据此前所介绍的梯度下降移动距离衰减理论,最终迭代5000轮之后该点梯度也应该是一个趋于0的值。当然,这也符合局部最小值的特点,导数为0。
f_gd_1(res[-1])
#-1.2212453270876722e-15
当然,对于梯度下降的局部最小值陷阱,根本原因还是在于梯度下降过程中参数移动的距离和梯度直接挂钩,而梯度下降的该特点不仅导致了局部最小值陷阱,还有另外一类更加常见的陷阱——鞍点陷阱。
2.2 鞍点(saddle point)陷阱
首先让我们来看下什么是鞍点。鞍点有许多严谨的学术定义,简单来理解鞍点是那些不是极值点但梯度为0的点。所谓极值,指的是那些连续函数上导数为0、并且所有两边单调性相反的点,极值包括局部最小值、最小值点、局部最大值和最大值点四类。而鞍点和极值点的区别在于导数为0单左右两边单调性相同,例如:
f ( x ) = x 3 f(x)=x^3 f(x)=x3
我们通过绘制该函数的函数图像来观察鞍点。
x = np.arange(-2, 2, 0.1)
y = np.power(x, 3)
fig = plt.plot(x, y)[0]
fig.axes.annotate('saddle point', xytext=(-0.52, -5),
arrowprops=dict(arrowstyle='->'), xy=(0, -0.2))
plt.xlabel('x')
plt.ylabel('x**3')
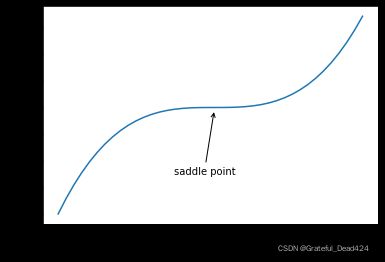
进一步的,我们来看下鞍点是如何影响梯度下降过程的。首先是由损失函数到梯度计算表达式的过程,由于损失函数只有一个参数,所以梯度表达式为:
f ′ ( x ) = 3 x 2 f'(x) = 3x^2 f′(x)=3x2
我们可以定义该函数、导函数的函数及轨迹绘制函数
# x**3函数
def f_2(x):
return np.power(x, 3)
f_2(-1)
#-1
# x**3导函数
def f_gd_2(x):
return (3*np.power(x, 2))
f_gd_2(-1)
#3
# 梯度更新函数
def gd_2(lr = 0.05, itera_times = 200, w = 1):
"""
梯度下降计算函数
:param lr: 学习率
:param itera_times:迭代次数
:param w:参数初始取值
:return results:每一轮迭代的参数计算结果列表
"""
results = [w]
for i in range(itera_times):
w -= lr * f_gd_2(w) # 梯度计算公式
results.append(w)
return results
当我们在以0.05作为学习率,参数初始值为1,迭代5000轮时参数每一轮迭代后参数的计算结果如下:
res = gd_2(itera_times=5000)
res[-1]
#0.0013297766246039373
def show_trace_2(res):
"""
梯度下降轨迹绘制函数
"""
f_line = np.arange(-1, 2, 0.01)
plt.plot(f_line, [f_2(x) for x in f_line])
plt.plot(res, [f_2(x) for x in res], '-o')
plt.xlabel('x')
plt.ylabel('Loss(x)')
show_trace_2(res)

同样,梯度下降无法跨越鞍点抵达更小值的点,并且我们判断5000次迭代后参数点的梯度已经非常小了:
f_gd_2(res[-1])
#5.304917614029122e-06
我们可以绘制一个包含了鞍点的二维图像进行观察:
x, y = np.mgrid[-1:1:31j,-1:1:31j]
z = x**2- y**2
ax = plt.axes(projection='3d')
ax.plot_wireframe(x, y, z,**{'rstride':2,'cstride':2})
ax.plot([0],[0],[0],'rx')
ticks =[-1,0,1]
plt.xticks(ticks)
plt.yticks(ticks)
ax.set_zticks(ticks)
plt.xlabel('x')
plt.ylabel('y')
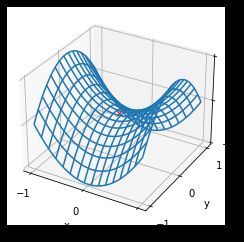
指的注意的是,在实际情况中,鞍点出现的频率高于局部最小值点。
3.梯度下降算法本质与改善方法
根据局部最小值和鞍点的讨论,我们不难发现梯度下降的本质作用其实是让参数点移动到梯度为0的点,当损失函数是严格意义的凸函数时,梯度为0的点就是全域最小值点,但如果损失函数不是凸函数,那么梯度为0的点就有可能是局部最小值点或者鞍点。此时受到局部最小值点或者鞍点梯度为0的影响,梯度下降无法从该点移出。尽管大多数线性模型的损失函数都是凸函数,但很多复杂机器学习模型所构建的损失函数都不一定是严格凸函数,要避免局部最小值点或者鞍点陷阱,我们就必须在梯度下降算法基础上进行改进。有一种最基础也是最通用的改进办法,就是每次在构建损失函数的时候代入一小部分数据,从而让参数有机会跳出陷阱,这就是所谓的随机梯度下降和小批量梯度下降。关于这两种改进办法的计算流程和实际效果,我们将在下一节课详细讨论。
Lesson 4.4 随机梯度下降与小批量梯度下降
在上一小节中,我们谈到关于梯度下降算法的计算流程与算法特性,从中我们知道,梯度下降能够通过多轮迭代计算最终收敛至一个梯度为0的点。当损失函数为凸函数时,由于全域最小值点是唯一一个梯度为0的点,因此梯度下降能够顺利收敛至全域最小值,但如果损失函数不是凸函数,则梯度下降算法容易陷入局部最小值点陷阱或者鞍点陷阱。此时我们就需要考虑在原有算法基础之上对其进行“改良”。梯度下降算法的改善形式有很多种,其中最为简单有效的方式是调整每次带入训练的样本数量,通过局部规律规律的不一致性来规避“非全域最小值但梯度为0”的陷阱。当然在调整每次带入样本数量这一基本思路下,根据实际带入数据的多少也衍生出了两种算法——随机梯度下降和小批量梯度下降。
# 科学计算模块
import numpy as np
import pandas as pd
# 绘图模块
import matplotlib as mpl
import matplotlib.pyplot as plt
# 自定义模块
from ML_basic_function import *
一、损失函数理论基础
首先,我们需要补充部分关于损失函数的相关理论。
- 训练数据不同、损失函数和模型参数都不同
有一个简单但又经常容易被遗忘的事实,那就是带入训练的数据不同,损失函数会有所不同,进而训练出来的模型参数会有所不同,即最终得到不同的模型结果。例如有数据集如下:

并且我们采用不带截距项的简单线性回归方程进行拟合: y = w x y=wx y=wx
此时,损失函数计算公式为: M S E L o s s ( w ) = ∑ i = 1 n ∣ ∣ y i − y ^ i ∣ ∣ 2 2 n MSELoss(w)=\frac{\sum_{i=1}^n||y_i-\hat y_i||_2^2}{n} MSELoss(w)=n∑i=1n∣∣yi−y^i∣∣22
当我们带入全部四条数据进行计算时,损失函数为:
Loss 4 ( w ) = ( 2 − w ) 2 + ( 5 − 3 w ) 2 + ( 4 − 6 w ) 2 + ( 3 − 8 w ) 2 4 = 110 w 2 − 130 w + 54 4 \begin{aligned} \operatorname{Loss}_{4}(w) &=\frac{(2-w)^{2}+(5-3 w)^{2}+(4-6 w)^{2}+(3-8 w)^{2}}{4} \\ &=\frac{110 w^{2}-130 w+54}{4} \end{aligned} Loss4(w)=4(2−w)2+(5−3w)2+(4−6w)2+(3−8w)2=4110w2−130w+54
对应的,我们通过求解该损失函数能够得到最优 w w w结果,令损失函数导函数为0即可得 w = 100 220 = 5 11 w=\frac{100}{220}=\frac{5}{11} w=220100=115,最终解得模型 y = 5 11 x y = \frac{5}{11}x y=115x
而如果我们带入其中一条数据进行计算,例如带入第一条数据进行计算,则损失函数计算公式为:
L o s s 1 ( w ) = ( 2 − w ) 2 = w 2 − 4 w + 4 Loss_1(w)=(2-w)^2 = w^2-4w+4 Loss1(w)=(2−w)2=w2−4w+4
此时解出最优参数结果为 w = 2 w=2 w=2,即训练得出模型为 y = 2 x y=2x y=2x。很明显,带入训练数据不同、损失函数不同、训练所得模型也不同。
- 损失函数其实是数据集规律的一种体现
由于模型其实是数据集规律的体现,而损失函数又是求解模型参数的基本函数,因此我们可以认定损失函数其实是一批数据所表现出规律的一种体现,并且不同数据的损失函数不同,我们就认定这几批数据对应的基本规律有所不同。如上述两个损失函数形态不同,其实也就代表着其背后的数据基本规律各不相同。
- 规律一致、损失函数也一致
但是,我们同时需要知道的是,有时数据看似不同,但实际上背后规律一致,此时损失函数其实也是一致的。从原理上讲,损失函数是指导求解全域最小值的方程,而如果多条(部分)数据规律一致,则构建出来的损失函数也将基本一致,至少是全域最小值点将保持一致,例如下述两条数据规律一致,都满足 y = 2 x y=2x y=2x这一基本规律

则围绕这两条数据分别构造损失函数,可得出如下结果:
M S E L o s s ( w ) 1 = ( 2 − w ) 2 MSELoss(w)_1 = (2-w)^2 MSELoss(w)1=(2−w)2 M S E L o s s ( w ) 2 = ( 4 − 2 w ) 2 = 4 ( 2 − w ) 2 MSELoss(w)_2 = (4-2w)^2 = 4(2-w)^2 MSELoss(w)2=(4−2w)2=4(2−w)2
而这两个损失函数,尽管看起来系数差距成一定比例,但这种差异其实并不影响实际梯度下降的计算过程,上述 M S E L o s s 1 MSELoss_1 MSELoss1和 M S E L o s s 2 MSELoss_2 MSELoss2的比例差距完全可以通过在迭代过程中设置负比例的学习率来确保最终参数迭代过程完全一致,例如我们可以令初始 w w w取值为0,则两个损失函数的迭代过程如下:
# 创建第一条数据
x1 = np.array([[1]])
y1 = np.array([[2]])
w1 = np.array([[0.]])
# 计算w1当前梯度
lr_gd(x1, w1, y1)
#array([[-4.]])
# 创建第二条数据
x2 = np.array([[2]])
y2 = np.array([[4]])
w2 = np.array([[0.]])
# 计算w2当前梯度
lr_gd(x2, w2, y2)
#array([[-16.]])
然后即可计算在第一条数据创建的损失函数下梯度下降迭代运算过程
w_cal_rec(x1, w1, y1, gd_cal = lr_gd, lr = 0.1, itera_times = 10)
#(array([[1.78525164]]),
# [array([[0.]]),
# array([[0.4]]),
# array([[0.72]]),
# array([[0.976]]),
# array([[1.1808]]),
# array([[1.34464]]),
# array([[1.475712]]),
# array([[1.5805696]]),
# array([[1.66445568]]),
# array([[1.73156454]]),
# array([[1.78525164]])])
然后同样迭代10轮,将学习率调小至1/4,计算在第二条数据构建的损失函数下梯度下降迭代过程
w_cal_rec(x2, w2, y2, gd_cal = lr_gd, lr = 0.025, itera_times = 10)
#(array([[1.78525164]]),
# [array([[0.]]),
# array([[0.4]]),
# array([[0.72]]),
# array([[0.976]]),
# array([[1.1808]]),
# array([[1.34464]]),
# array([[1.475712]]),
# array([[1.5805696]]),
# array([[1.66445568]]),
# array([[1.73156454]]),
# array([[1.78525164]])])
不难发现,二者完全一致。也就是说损失函数的等比例差异其实完全可以通过学习率消除,而学习率又是人工设置的参数。因此从这个意义上来说,相同规律不同数据所创造的损失函数本质上还是“相同”的损失函数。当然,如果此时我们再构建一个由这两条数据共同构建的损失函数,则该损失函数和上述两个损失函数也是一致的。
值得注意的是,损失函数的该特性也将是影响随机梯度下降或者小批量梯度下降有效性的根本因素。
至此,我们再反观第一小节中的 L o s s ( w ) 4 Loss(w)_4 Loss(w)4和 L o s s ( w ) 1 Loss(w)_1 Loss(w)1,二者之所以会表现出差异,是因为 L o s s ( w ) 4 Loss(w)_4 Loss(w)4背后的四条数据所表现出的整体规律和 M S E L o s s ( w ) 1 MSELoss(w)_1 MSELoss(w)1后背的一条数据所表现出的规律不一致。
Loss 4 背后的数据集 \operatorname{Loss}_{4} \text { 背后的数据集 } Loss4 背后的数据集

L o s s 4 ( w ) = 110 w 2 − 130 w + 54 4 Loss_4(w) =\frac{110w^2-130w+54}{4} Loss4(w)=4110w2−130w+54
Loss 1 背后的数据集 \operatorname{Loss}_{1} \text { 背后的数据集 } Loss1 背后的数据集
 L o s s 1 ( w ) = ( 2 − w ) 2 = w 2 − 4 w + 4 Loss_1(w)=(2-w)^2 = w^2-4w+4 Loss1(w)=(2−w)2=w2−4w+4
L o s s 1 ( w ) = ( 2 − w ) 2 = w 2 − 4 w + 4 Loss_1(w)=(2-w)^2 = w^2-4w+4 Loss1(w)=(2−w)2=w2−4w+4
- 局部规律与整体规律
为了方便区分,我们将训练数据集所表现出来的规律称为训练数据的整体规律,而单独某条或者某几条数据所表现出来的规律称为局部规律。对于数据集1来说,第一条数据所表现出的局部规律和整个数据集所表现出来的规律并不一致,而对于数据集2来说,第一条数据、第二条数据和整个数据集表现出来的规律都一致。另外,我们也将训练数据集中的一部分数据称为训练数据的子数据集。
不过,在大多数实际获取到的数据中,由于存在各方面误差,很难出现类似数据集2的这种多条数据规律完全一致的情况,在大多数情况下训练数据集的子数据集往往都存在一定的规律差异,不仅是不同的子数据集之间存在差异,而且子数据集和训练数据集整体之间也存在一定的规律差异。
- 局部规律和整体规律的相对统一
尽管局部规律和整体规律并不一致,但局部规律和整体规律却是相对统一的。例如,我们还是以数据集1为例,并且以前两条数据构造第一个损失函数 L o s s 2 Loss_2 Loss2、后两条数据构造另一个损失函数 L o s s 3 Loss_3 Loss3,则有损失函数计算公式如下:
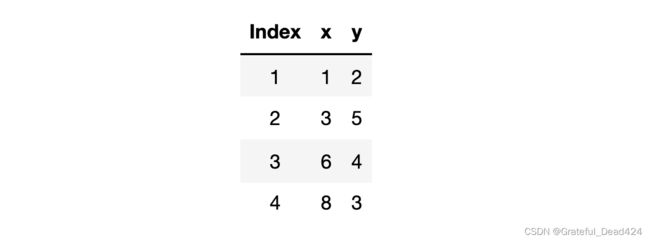
Loss 2 = ( 2 − 1 w ) 2 + ( 5 − 3 w ) 2 2 = w 2 − 4 w + 4 + 9 w 2 − 30 w + 25 2 = 10 w 2 − 34 w + 29 2 Loss 3 = ( 4 − 6 w ) 2 + ( 3 − 8 w ) 2 2 = 36 w 2 − 48 w + 16 + 64 w 2 − 48 w + 9 2 = 100 w 2 − 96 w + 25 2 \begin{aligned} \operatorname{Loss}_{2} &=\frac{(2-1 w)^{2}+(5-3 w)^{2}}{2} \\ &=\frac{w^{2}-4 w+4+9 w^{2}-30 w+25}{2} \\ &=\frac{10 w^{2}-34 w+29}{2} \\ \operatorname{Loss}_{3} &=\frac{(4-6 w)^{2}+(3-8 w)^{2}}{2} \\ &=\frac{36 w^{2}-48 w+16+64 w^{2}-48 w+9}{2} \\ &=\frac{100 w^{2}-96 w+25}{2} \end{aligned} Loss2Loss3=2(2−1w)2+(5−3w)2=2w2−4w+4+9w2−30w+25=210w2−34w+29=2(4−6w)2+(3−8w)2=236w2−48w+16+64w2−48w+9=2100w2−96w+25
而此时,整体损失函数其实就是上述二者的平均值:
L o s s 4 ( w ) = 110 w 2 − 130 w + 54 4 Loss_4(w) =\frac{110w^2-130w+54}{4} Loss4(w)=4110w2−130w+54
因此我们可以将其理解为:代表局部规律的损失函数其实也能够部分表示整体损失函数。
一种更加严谨的表述是,局部规律的损失函数平均来说是整体损失函数的一个良好的估计。
当然,局部规律彼此之间也是相对统一的。
- 梯度下降计算过程改善思路
据此,我们即可进一步讨论关于梯度下降的改善思路。
简单来说就是,梯度下降过程中每一次参数移动都是基于整体规律(全部数据集对应的损失函数)来进行每一次参数迭代,而无论是随机梯度下降(Stochastic Gradient Descent)还是小批量梯度下降(Mini-batch Gradient Descent),其实都是在利用局部规律(部分数据的损失函数)来进行每一次参数迭代,其中随机梯度下降每次参数迭代都挑选一条数据来构建损失函数,而小批量梯度下降则每次选择一个小批数据(训练数据集的子集)来进行迭代,例如总共100条数据等分成10个子集,每个子集包含10条数据,然后每次梯度下降带入其中一个子集的损失函数进行计算。按照这种划分方法,原始梯度下降算法也被称为BGD(Batch Gradient Descent,批量梯度下降)。当然不难发现,SGD和BGD其实都是小批量梯度下降的特例,即在小批量梯度下降中,当子集等于全集时,小批量梯度下降就是BGD,而当每个子集只有一条数据时,小批量梯度下降就是SGD。
值得注意的是,在某些深度学习计算框架(如PyTorch),小批量梯度下降也被划入SGD范畴。
这种修改思路本身其实不难理解,但如何通过这种方法来优化梯度下降过程,并使得其能够跳出局部最小值点呢?在这个过程中局部规律的不一致性又是如何发挥作用的?这就需要我们深入随机梯度下降和小批量梯度下降的具体计算流程当中来进行观察。
简单总结上述理论基础:
1.数据规律可以用损失函数表示,损失函数形态不同代表其背后构造损失函数的数据规律不同;
2.一般来说,对于一个数据集来说,局部规律之间和局部规律与整体规律之间就存在一定的差异,但也存在一定的统一性;
3.利用局部规律之间的“对立统一”的特性,我们就能够在参数移动过程中改变参数移动方向,从而避免局部最小值或者鞍点陷阱。
二、随机梯度下降(Stochastic Gradient Descent)
1.随机梯度下降计算流程
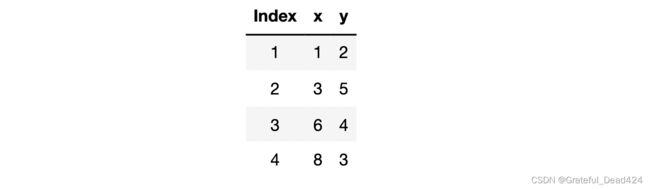
首先我们来讨论关于SGD的计算流程及使用过程中的注意事项。还是先从一个简单的例子入手,假设现有数据集如下:
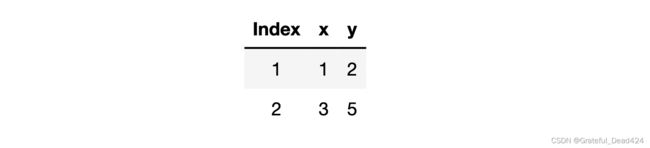
此时如果我们采用SGD进行参数点的更新迭代,则每次提取一条数据构造损失函数然后再进行计算,同样我们构建不带截距项的简单线性回归 y = w x y=wx y=wx进行建模,则第一条数据的损失函数为: L o s s 1 ( w ) = ( 2 − w ) 2 Loss_1(w) = (2-w)^2 Loss1(w)=(2−w)2
第二条数据的损失函数为 L o s s 2 ( w ) = ( 5 − 3 w ) 2 Loss_2(w)=(5-3w)^2 Loss2(w)=(5−3w)2
实际SGD执行过程中,首先我们会将数据集乱序处理,然后依次挑选每一条数据的损失函数进行参数更新计算。当然如果是进行了训练集和测试集的随机切分,则无需再次进行乱序处理,现假设上述数据就是乱序处理之后的结果,在给定初始参数 w 0 = 0 w_0=0 w0=0的情况下,我们可以根据如下过程进行参数迭代,首先进行参数和数据的定义
w = 0
x = np.array([[1], [3]])
x
#array([[1],
# [3]])
y = np.array([[2], [5]])
y
#array([[2],
# [5]])
然后即可开始第一轮迭代,带入第一条数据进行参数的第一次修改,实际计算过程等价于借助第一条数据的损失函数所计算出的梯度进行参数的修改,过程如下:
# 执行第一轮迭代
w = w_cal(x[0], w, y[0], lr_gd, lr = 0.02, itera_times = 1)
w
#0.08
紧接着,利用第二条数据的损失函数梯度进行参数的第二次修改
# 执行第二轮迭代
w = w_cal(x[1], w, y[1], lr_gd, lr = 0.02, itera_times = 1)
w
#0.6512
对比梯度下降计算过程
w = 0
w_cal(x, w, y, lr_gd, lr = 0.02, itera_times = 2)
#array([[0.612]])
至此,我们总共执行了两轮迭代,参数也就移动了两步。而全部数据只有条量,两轮迭代正好用了一轮全部数据,此时我们称为迭代了一轮epoch,即梯度下降过程遍历了一遍数据。在随机梯度下降和小批量梯度下降过程中,一般我们采用epoch指标来说明目前迭代进度。接下来我们尝试迭代40个epoch。
w = 0
epoch = 40
for j in range(epoch):
for i in range(2):
w = w_cal(x[i], w, y[i], lr_gd, lr = 0.02, itera_times = 1)
# 最终参数取值
w
#1.6887966746685015
当然,我们也可以将上述过程定义成一个函数:
def sgd_cal(X, w, y, gd_cal, epoch, lr = 0.02):
"""
随机梯度下降计算函数
:param X: 训练数据特征
:param w: 初始参数取值
:param y: 训练数据标签
:param gd_cal:梯度计算公式
:param epoch: 遍历数据集次数
:param lr: 学习率
:return w:最终参数计算结果
"""
m = X.shape[0]
n = X.shape[1]
for j in range(epoch):
for i in range(m):
w = w_cal(X[i].reshape(1, n), w, y[i].reshape(1, 1), gd_cal=gd_cal, lr=lr, itera_times = 1)
return w
验证函数输出结果
w = 0
sgd_cal(x, w, y, lr_gd, epoch=40, lr=0.02)
#array([[1.68879667]])
那么,1.688是否是全域最小值点呢?此时我们也可以对比梯度下降围绕上述问题计算所得结果:
# 梯度下降计算过程
w = 0
w = w_cal(x, w, y, lr_gd, lr = 0.02, itera_times = 100)
w
#array([[1.7]])
而整体损失函数为 L o s s ( w ) = w 2 − 4 w + 4 + 9 w 2 − 30 w + 25 = 10 w 2 − 34 w + 29 Loss(w)=w^2-4w+4+9w^2-30w+25=10w^2-34w+29 Loss(w)=w2−4w+4+9w2−30w+25=10w2−34w+29
对应梯度计算公式为 ∇ w L o s s ( w ) = 20 w − 34 \nabla _wLoss(w)=20w-34 ∇wLoss(w)=20w−34
因此,全域最小值点应为 w = 34 20 = 1.7 w=\frac{34}{20}=1.7 w=2034=1.7
也就是说明,随机梯度下降尽管有效,但其实无法像批量梯度下降一样收敛至全域最优解,随机梯度下降只能收敛到全域最小值点附近。要弄清楚这背后的原因以及找出优化的方法,我们需要进一步探究随机梯度下降的算法特性。
2.随机梯度下降的算法特性
- 迭代结果震荡特性
尽管从执行流程上来看,SGD只是将梯度下降的“每次带入全部数据进行计算”改成了“每次带入一条数据进行计算”,但实际上,这么做会极大程度影响参数每一次移动的方向,从而使得参数最终无法收敛至全域最优解,但同时这么一来却也使得参数迭代过程能够跨越局部最小值点。
还是回顾上述例子中参数的迭代过程,在第一轮epoch的第一次迭代时,参数点从0出发,实际上是根据第一条数据的损失函数最小值点前进的。第一条数据的损失函数及图像如下: L o s s 1 ( w ) = ( 2 − w ) 2 Loss_1(w) = (2-w)^2 Loss1(w)=(2−w)2
x1 = np.arange(1.5, 2.5, 0.01)
y1 = np.power(2-x1, 2)
plt.plot(x1, y1)
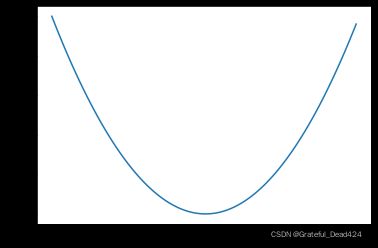
也就是朝向 w = 2 w=2 w=2这个点前进的。而第二次迭代时,参数点则是朝向第二条数据对应的损失函数最小值方向前进的。第二条数据的损失函数及图像如下所示: L o s s 2 ( w ) = ( 5 − 3 w ) 2 Loss_2(w)=(5-3w)^2 Loss2(w)=(5−3w)2
y2 = np.power(5-3*x1, 2)
plt.plot(x1, y1, label='x1')
plt.plot(x1, y2, label='x2')
plt.legend(loc = 1)
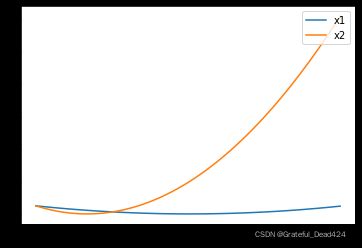
第二条数据损失函数的极小值点为 5 3 = 1.667 \frac{5}{3}=1.667 35=1.667,两条数据的损失函数极小值点并不一致,并且全域最小值点就位于1.667和2之间。因此,在实际迭代过程中,当参数点位于两个极小值点左侧时,即参数小于1.667时候,无论是遵照哪一条数据的损失函数进行梯度下降,都能朝向全域最小值点前进。但当参数点迭代至1.667和2之间时,这时参数的迭代就会陷入“进退两难”的境地,当带入第一条数据进行梯度下降时,算法执行过程会要求参数点往后退,退到1.667这个点;而如果带入第二条数据进行梯度下降时,算法执行过程会要求参数点往前走,走到2这个点。我们可以详细参数点移动过程观察。
不同的损失函数“要求”不同的迭代方向。
w = 0
epoch = 40
for j in range(epoch):
for i in range(2):
w = w_cal(x[i], w, y[i], lr_gd, lr = 0.02, itera_times = 1)
print(w)
#0.08
#0.6512
#0.705152
#1.05129728
#...
#1.6887966710099307
#1.7012448041695334
#1.6887966746685015
- 结果震荡与逃离局部最小值点
我们发现,最终参数是在1.7和1.68这两个点之间来回震荡,也就是陷入了“进退两难”的境地。在考虑如何改善这个问题之前,我们先来看下这种参数点在迭代过程中方向不定带来的影响。从上述w的迭代过程我们发现,参数方向出现不一致的情况出现在当参数位于两个极小值点之间时,而并不受到全域最小值点1.7的影响,或者说并“不”受到整体损失函数梯度为0的点影响。那么我们合理推测,就将有可能出现一种情况,那就是整体损失函数存在局部最小值,但某条数据在该点的梯度不为0。那么,当参数迭代至全域局部最小值点时正好带入该条数据进行梯度下降,由于该条数据在该点梯度不为0,因此参数就将顺利跨过局部最小值点。假设现在全部训练数据的损失函数为 y = x ⋅ c o s ( π x ) y=x\cdot cos(\pi x) y=x⋅cos(πx),而某条数据的损失函数为 y = ( x − 0.7 ) 2 y=(x-0.7)^2 y=(x−0.7)2,则当参数在0.35附近时,带入该条数据进行梯度下降时就能顺利跨过0.35局部最小值点。
x1 = np.arange(-1, 2, 0.1)
y1 = x1 * np.cos(np.pi * x1)
y2 = np.power(x1-0.7, 2)
plt.plot(x1, y1, label='y=x*cos(pi*x)')
plt.plot(x1, y2, label='y=(x-0.7)**2')
plt.legend(loc = 1)
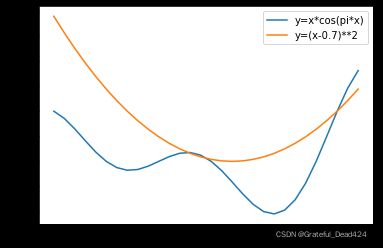
而这种帮助跨越局部最小值点或者鞍点的优秀性质,使得随机梯度下降成为比梯度下降应用更广的优化算法。当然要做到这点,最为核心的一点是局部数据的损失函数和全部数据的损失函数不一致,及局部规律和全局规律不一致。也就是说本质上来看我们是利用这种不同数据之间规律的差异性来帮助参数点逃脱局部最小值陷阱。
总结上述过程:SGD的计算本质是借助局部规律(而不是整体规律)来更新参数,而局部规律不一致性能够让参数在移动过程中保持灵活的移动方向,并因此能够逃离局部最小值点或鞍点陷阱,但方向不一致的代价是最终无法收敛到一个稳定的点,要改进这一问题则需要借助额外优化手段。
当然,小批量梯度下降也有该性质。并且在机器学习领域,很多时候我们都会借助局部规律不一致性来拓展算法性能,例如集成算法中的随机森林。
- 震荡迭代与损失函数波动
当然,这种参数迭代方向的不确定性的另一方面影响,就是容易会造成整体损失函数在收敛过程不断波动。其实这并不难理解,只要参数的行进方向不是和全部数据的损失函数的梯度递减方向保持一致,只要参数在中途发生方向的调整,就会导致由全部数据构造的损失函数计算结果的震荡。例如在上述例子迭代过程中,我们可以观察整体MSE变化情况
w = 1.5
MSE_l = [MSELoss(x, w, y)]
for j in range(20):
for i in range(2):
w = w_cal(x[i], w, y[i], lr_gd, lr = 0.02, itera_times = 1)
MSE_l.append(MSELoss(x, w, y))
MSE_l
#[array([[0.25]]),
# array([[0.212]]),
# array([[0.1308992]]),
# array([[0.11062326]]),
# ...
# array([[0.0506296]]),
# array([[0.05000753]]),
# array([[0.05062882]])]
plt.plot(list(np.arange(41)), np.array(MSE_l).flatten())
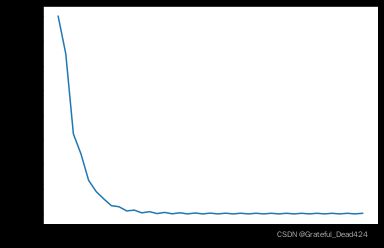
- 等高线图观察SGD迭代过程
当然上述例子损失函数波动并不明显,但在很多复杂模型运算过程中,受到每次迭代的方向不一致的影响,损失函数还是会受到较大影响。当然,这种影响我们还可以通过观察参数点逼近全域最小值点过程中的进行路径来体会,例如我们借助Lesson 4.3中定义的数据及轨迹绘制函数来进行简单实验。

np.random.seed(24)
w = np.random.randn(2, 1) # 参数都默认为列向量
w
#array([[ 1.32921217],
# [-0.77003345]])
features = np.array([1, 3]).reshape(-1, 1)
features = np.concatenate((features, np.ones_like(features)), axis=1)
features
#array([[1, 1],
# [3, 1]])
labels = np.array([2,4]),reshape(-1,1)
labels
#array([[2],
# [4]])
# 随机梯度下降参数点运行轨迹
w_res = [np.copy(w)]
for i in range(40):
w_res.append(np.copy(sgd_cal(features, w, labels, lr_gd, epoch=1, lr=0.1)))
w_res[-1]
#array([[1.00686032],
# [0.96947505]])
np.random.seed(24)
w1 = np.random.randn(2, 1) # 参数都默认为列向量
w1
#array([[ 1.32921217],
# [-0.77003345]])
# 梯度下降参数点运行轨迹
w1, w_res_1 = w_cal_rec(features, w1, labels, gd_cal = lr_gd, lr = 0.1, itera_times = 100)
w_res_1[-1]
#array([[1.02052278],
# [0.95045363]])
# 网格点坐标
x1, x2 = np.meshgrid(np.arange(1, 2, 0.001), np.arange(-1, 1, 0.001))
# 绘制等高线图
plt.contour(x1, x2, (2-x1-x2)**2+(4-3*x1-x2)**2)
# 绘制参数点移动轨迹图
plt.plot(np.array(w_res)[:, 0], np.array(w_res)[:, 1], '-o', color='#ff7f0e', label='SGD')
plt.plot(np.array(w_res_1)[:, 0], np.array(w_res_1)[:, 1], '-o', color='#1f77b4', label='BGD')
plt.legend(loc = 1)

能够看出,在参数迭代过程中,随机梯度下降的方向不一致将对迭代过程造成较大影响。正所谓“成于斯者毁于斯”,我们借助随机性去帮助算法跨越局部最小值陷阱,但却引出了其他的麻烦——关于如何解决这些“麻烦”,就是我们后续要讨论的围绕随机梯度下降算法的优化算法。
3.随机梯度下降求解线性回归
接下来,我们尝试使用随机梯度下降求解线性回归问题。
- Step 1.确定数据集和模型
仍然还是创建扰动项不大、基本满足 y = 2 x 1 − x 2 + 1 y=2x_1-x_2+1 y=2x1−x2+1规律的数据集。
# 设置随机数种子
np.random.seed(24)
# 扰动项取值为0.01
features, labels = arrayGenReg(delta=0.01)
- Step 2.设置初始参数
np.random.seed(24)
w = np.random.randn(3, 1)
w
#array([[ 1.32921217],
# [-0.77003345],
# [-0.31628036]])
# 计算w取值时SSE
SSELoss(features, w, labels)
#array([[2093.52940481]])
# 计算w取值时MSE
MSELoss(features, w, labels)
#array([[2.0935294]])
- Step 3.执行梯度下降计算
接下来,借助此前所定义的参数更新函数进行梯度下降参数求解:
w = sgd_cal(features, w, labels, lr_gd, epoch=40, lr=0.02)
w
#array([[ 1.99749114],
# [-0.99773197],
# [ 0.99780476]])
# 计算w取值时SSE
SSELoss(features, w, labels)
#array([[0.1048047]])
# 计算w取值时MSE
MSELoss(features, w, labels)
#array([[0.0001048]])
至此,我们就完成了随机梯度下降求解损失函数的完整流程。
4.随机梯度下降算法评价
根据上述讨论和实现,我们基本掌握了随机梯度下降求解损失函数的基本思路与实现方法,相比梯度下降,随机梯度下降由于引入了一定的随机性,借助局部规律不一致性来跳出局部最小值点陷阱,可以说是一项重大进步。而由于在大多数复杂模型中损失函数都不一定是严格意义凸函数,因此随机梯度下降也有着比梯度下降更广泛的应用场景。
不过,值得一提的是,随机梯度下降的计算过程还是“过于”随机了,在很多复杂模型中,这种随机性所造成的迭代收敛上的麻烦几乎和这种随机性所带来的益处不相上下,比如迭代需要更多次数、最终收敛结果不稳定等等,要对其进行改善,我们能够想到的一个最为基础的办法就是在确保一定程度随机性的基础上增加一些算法的稳定性。即尝试适度修正每次迭代所带入的样本量,也就是合理设置每次迭代参数所带入的数据量,一方面我们还是希望借助局部规律的不确定性来规避局部最小值陷阱,同时我们也希望一定程度控制住迭代过程随机性,来减少随机性所带来的麻烦。而这种每次迭代过程带入若干条样本的梯度下降算法,就被称为小批量梯度下降。
当然,如果每条数据都和整体数据的规律基本一致,例如(1,2)、(2,4)这种数据集,那么其实随机梯度下降收敛效率会更高,毕竟计算一条数据就相当于计算了一个数据集。但此时因为不同数据彼此之间并不存在局部规律的不一致性,所以随机梯度下降也无法帮助跳过局部最小值点。
三、小批量梯度下降(Mini-batch Gradient Descent)
所谓小批量梯度下降,其实就是对随机梯度下降过程稍作修改——每次不在是带入一条数据进行计算,而是带入batch_size条数据进行计算,当然batch_size是一个人工设置的超参数。通过这么一个微小的变化,算法在实际性能上将发生根本性变化。而小批量梯度下降,目前也是梯度下降算法家族中最为通用的算法。
更多关于梯度下降、随机梯度下降及小批量梯度下降的算法性能比较及算法优化,详见Lesson 4.4。
1.小批量梯度下降计算流程
还是一样,我们先通过简单的一个实例来观察小批量梯度下降的计算流程。还是以开篇数据集为例:
当我们在执行小批量梯度下降时,我们会先将训练数据进行“小批量”的切分,例如我们可以将上述数据集切分成两个mini-batch,前两条数据为第一批,后两条数据为第二批。然后按照类似随机梯度下降的计算过程来进行计算。
- 数据切分
x = np.array([1, 3, 6, 8]).reshape(-1, 1)
x
#array([[1],
# [3],
# [6],
# [8]])
y = np.array([2, 5, 4, 3]).reshape(-1, 1)
y
#array([[2],
# [5],
# [4],
# [3]])
x1 = x[:2]
x2 = x[2:4]
y1 = y[:2]
y2 = y[2:4]
- 第一轮(epoch)迭代
在数据集切分完成后,接下来我们开始进行参数更新。和随机梯度下降一样,当我们遍历一次数据集之后,就称为一轮epoch迭代完成。此时我们将数据集划分为两批,两批依次带入训练完之后就相当于第一轮epoch迭代完成。
w = 0
w = w_cal(x1, w, y1, lr_gd, lr = 0.02, itera_times = 1)
w = w_cal(x2, w, y2, lr_gd, lr = 0.02, itera_times = 1)
w
#array([[0.62]])
- 多轮(epoch)迭代
当然,如果希望针对更为一般的数据集进行可手动调节batch_size的小批量梯度下降计算,我们可以将上述sgd_cal进行修改,将小批量梯度下降和随机梯度下降整合至一个函数中。具体计算函数如下:
def sgd_cal(X, w, y, gd_cal, epoch, batch_size=1, lr=0.02, shuffle=True, random_state=24):
"""
随机梯度下降和小批量梯度下降计算函数
:param X: 训练数据特征
:param w: 初始参数取值
:param y: 训练数据标签
:param gd_cal:梯度计算公式
:param epoch: 遍历数据集次数
:batch_size: 每一个小批包含数据集的数量
:param lr: 学习率
:shuffle:是否在每个epoch开始前对数据集进行乱序处理
:random_state:随机数种子值
:return w:最终参数计算结果
"""
m = X.shape[0]
n = X.shape[1]
batch_num = np.ceil(m / batch_size)
X = np.copy(X)
y = np.copy(y)
for j in range(epoch):
if shuffle: #提升模型的泛化能力
np.random.seed(random_state)
np.random.shuffle(X)
np.random.seed(random_state)
np.random.shuffle(y)
for i in range(np.int(batch_num)):
w = w_cal(X[i*batch_size: np.min([(i+1)*batch_size, m])],
w,
y[i*batch_size: np.min([(i+1)*batch_size, m])],
gd_cal=gd_cal,
lr=lr,
itera_times=1)
return w
此处需要注意,首先是借助np.ceil函数计算切分成几批。这里需要注意,如果最后一批剩余数据不足batch_size数量,则也可以将其化为一批。例如以x为例,每三条数据分为一批时,总共可以分成两批
np.ceil(4 / 3)
#2.0
并且,在具体执行计算时,在切分过程中需要确定数据集切分的上界
for i in range(2): # 总共切分两批
print(x[i*3: np.min([(i+1)*3, 4])]) # 每一批三条数据,总数据量为4
#[[1]
# [3]
# [6]]
#[[8]]
同时,需要注意的是,为了确保模型本身的泛化能力,一般来说我们需要在每一轮epoch开始前对数据集进行乱序处理。至此我们就完成了小批量梯度下降的计算函数,我们可以简单检验计算过程:
# 初始参数为0,两条数据为1批,迭代1轮epoch
w = 0
sgd_cal(x, w, y, lr_gd, epoch=1, batch_size=2, lr=0.02, shuffle=False)
#array([[0.62]])
# 初始参数为0,两条数据为1批,迭代10轮epoch
w = 0
sgd_cal(x, w, y, lr_gd, epoch=10, batch_size=2, lr=0.02)
#array([[0.67407761]])
# 初始参数为0,两条数据为1批,迭代10轮epoch
w = 0
sgd_cal(x, w, y, lr_gd, epoch=10, batch_size=2, lr=0.02)
#array([[0.52203531]])
# 对比梯度下降计算过程
w = 0
w_cal(x, w, y, lr_gd, lr = 0.02, itera_times = 10)
#array([[0.56363636]])
并且,如果将每一批数据的数据量设置为样本总数时,计算过程就相当于梯度下降
w = 0
sgd_cal(x, w, y, lr_gd, epoch=10, batch_size=4, lr=0.02)
#array([[0.56363636]])
当然,如果将每一批数据的数据量设置为1,其计算过程就相当于随机梯度下降
w = 0
for j in range(10):
for i in range(4):
w = w_cal(x[i], w, y[i], lr_gd, lr = 0.002, itera_times = 1)
w
#0.5347526106195503
w = 0
w = sgd_cal(x, w, y, lr_gd, epoch=10, batch_size=1, lr=0.002, shuffle=False)
w
#array([[0.53475261]])
2.小批量梯度下降算法特性
尽管小批量梯度下降每次带入了更多的数据进行参数训练,但其算法特性和随机梯度下降还是比较类似的,在训练阶段,每次训练实际上是利用某批数据的综合规律(综合损失函数)来进行参数训练,同时,小批量梯度下降也是借助不同批次数据的规律不一致性帮助参数跳出局部最小值陷阱,并且,由于规律不一致性,小批量梯度下降最终收敛结果也会呈现小幅震荡,只不过在所有的“随机不确定性”的方面,小批量梯度下降都比随机梯度下降显得更加稳健。当然,在必要时,我们也会将小批量梯度下降转化为梯度下降或者随机梯度下降。更多的算法选择和优化理论我们将在下一小节进行详细讨论。
3.小批量梯度下降求解线性回归
最后,我们尝试使用小批量梯度下降求解线性回归问题,我们将采用更加正式的流程来进行计算。
首先,我们仍然还是创建扰动项不大、基本满足 y = 2 x 1 − x 2 + 1 y=2x_1-x_2+1 y=2x1−x2+1规律的数据集。
# 设置随机数种子
np.random.seed(24)
# 扰动项取值为0.01
features, labels = arrayGenReg(delta=0.01)
然后进行数据集切分
Xtrain, Xtest, ytrain, ytest = array_split(features, labels, rate=0.7, random_state=24)
Xtrain.shape
(700, 3)
接下来进行初始参数的设置
np.random.seed(24)
w = np.random.randn(3, 1)
w
#array([[ 1.32921217],
# [-0.77003345],
# [-0.31628036]])
然后借助小批量梯度下降进行参数求解
w = sgd_cal(Xtrain, w, ytrain, lr_gd, batch_size=100, epoch=40, lr=0.02)
w
#array([[ 1.99975664],
# [-0.99985539],
# [ 0.99932797]])
计算训练误差和测试误差
# 训练误差
MSELoss(Xtrain, w, ytrain)
#array([[9.43517576e-05]])
# 测试误差
MSELoss(Xtest, w, ytest)
#array([[9.01449168e-05]])
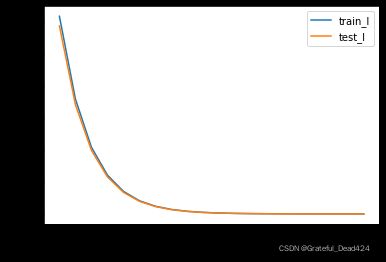
对于求解数值解的算法来说,观察其迭代过程是进行后续优化的第一步,因此我们可以编写如下过程来观察伴随迭代进行,模型训练误差和测试误差如何变化。
np.random.seed(24)
w = np.random.randn(3, 1)
trainLoss_l = []
testLoss_l = []
epoch = 20
for i in range(epoch):
w = sgd_cal(Xtrain, w, ytrain, lr_gd, batch_size=100, epoch=1, lr=0.02)
trainLoss_l.append(MSELoss(Xtrain, w, ytrain))
testLoss_l.append(MSELoss(Xtest, w, ytest))
plt.plot(list(range(epoch)), np.array(trainLoss_l).flatten(), label='train_l')
plt.plot(list(range(epoch)), np.array(testLoss_l).flatten(), label='test_l')
plt.xlabel('epochs')
plt.ylabel('MSE')
plt.legend(loc = 1)