极客算法训练笔记(二),数组没有那么简单
目录
- 为什么数组下标从0开始?
- 数组定义为什么这么下定义?
- 定义数组的三种方式
- 从 ArrayList 源码看数组增删改查
- 初始化
- 增加
- 删除
- 修改
- 查找
- 数组和容器数组时间复杂度数组插入,删除优化容器替代数组?
- 字节高频算法题:移动零
- 算法发散
❝
没有最完美的数据结构,只有最合适的数据结构。
❞
为什么数组下标从0开始?
这个问题上大学第一课C语言的时候我就疑惑,没有接触过计算机之前,数数都是从1开始的呀,一只羊两只羊三只羊,别睡着了。
参考原因如下:
- 高级语言爷爷级的C语言,就是从0开始,后面发展的语言都是沿用这个,降低学习成本;但是发展了这么多年,几个更加新的语言,Python等支持负数下标;
- 下标代表偏移量,
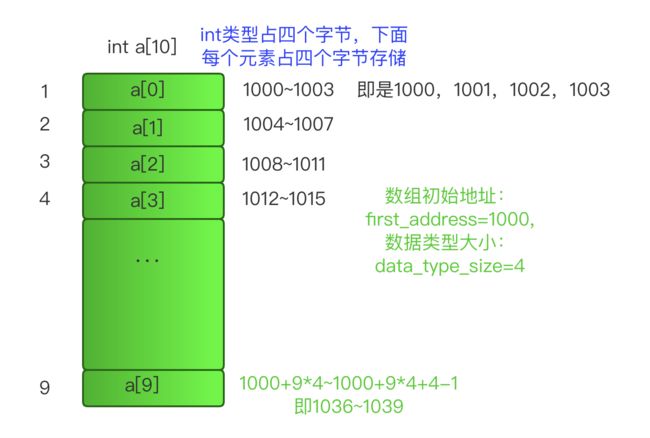
数组寻址
推导得到第i个元素地址公式:
a[i]_address = first_address + i * data_type_size
如果从1开始,推导得到第i个元素地址公式: a[i]_address = first_address + (i-1) * data_type_size
即多了一次-1操作,对于CPU来说,就是多了一次减法指令
数组定义
数组是一种线性表结构,它用一组连续的内存空间,来存储一组具有相同类型的数据。
「线性表」:具有像线一样性质的表。即线性表上的数据只有前后关系,数组,链表,队列,栈这样的都是前后关系的线性表结构,树和图这样的前后左右都有关系的即是非线性表结构。
为什么这么下定义?
一般下定义都是留下了最精炼的字来概括内容,就像一部好的电影没有一句废话,下面来分析一下数组定义。
「连续」:正是因为连续的内存空间,所以我们能推算出每个元素的地址,假设一个数组有五个元素,起始地址为00,那么后面元素地址一次为01,02,03,04,别人一问你第五个元素地址,你立马可以告诉她是04,这正是因为数组的内存空间是一段连续的空间。
然而如果这五个元素存放在链表里,那么你就不能立马告诉别人第五个元素的地址是04了,你要先找到第一个元素取得第二个元素的地址,然后取得第三个元素的地址,一直找下去找到最后一个元素,就是因为链表存储的空间不是连续的,链表元素里面除了数据本身还需要多存放下一个元素的地址,通过这种方式来找下一个元素,如果要同时知道链表前后是谁就需要双链表了。
注:正是因为数组需要连续的内存空间,所以定义数组的时候都需要指定数组的初始大小,要不然会报错。JAVA容器类ArrayList底层是Object[]数组实现的,数组指定的初始大小在JDK1.8之前是10,JDK1.8时候变成了0。
「相同类型」:试想一下,你一个数组,一会儿放个int类型,一会儿放个long类型,那么上面提到的内存连续也拯救不了你。你让计算机咋搞呢,int类型占四个字节,long类型占八个字节(64位操作系统下),计算机是把四个字节看成一个元素,还是八个字节当做一个元素呢,要知道所需存储空间不同地址不同呀,即使你内存连续都不能根据下标统一寻址了。
「因此,数组两大特性:」连续内存空间,相同类型元素。数组一切的一切,都是基于这两个的,基于这两大特性,数组实现了最大的优点:随机存取,我们很多时候使用数组都是贪图这个优点。
定义数组的三种方式
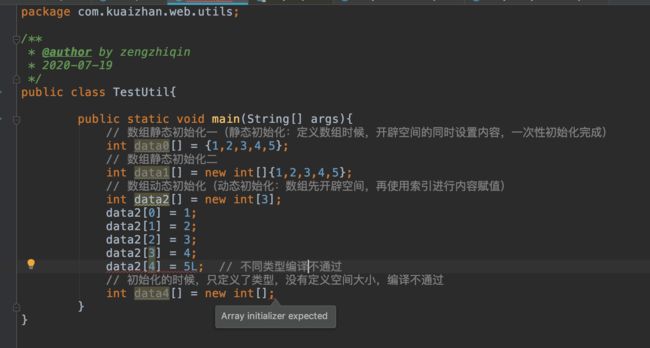
Talk is cheap,show me the code
初始化数组主要分为静态初始化和动态初始化,无论哪一种都需要指定数组大小:
静态初始化:定义数组时候,开辟空间的同时设置内容,一次性初始化完成;
动态初始化:数组先开辟空间,再使用索引进行内容赋值;
从 ArrayList 源码看数组增删改查
感觉纯粹看数组的增删改挺无趣的,我们每个人只要静下心来都可以实现数组的增删改查,极客算法里面通过看JAVA的 ArrayList 源码的方式来看数组增删改,我觉得挺不错的:
一来可以看看设计者们怎么封装的,感受感受优秀代码设计;
二来可以熟悉熟悉源码,更加清楚天天用的 ArrayList 底层实现,可以看到有什么值得平时注意的。
以下都是基于JDK1.8,选取ArrayList是因为这个我们平时用的最多。
集合Collection图谱
初始化
public class ArrayList extends AbstractList implements List, RandomAccess, Cloneable, Serializable {
// 序列化id
private static final long serialVersionUID = 8683452581122892189L;
// 默认初始的容量
private static final int DEFAULT_CAPACITY = 10;
// 一个空对象
private static final Object[] EMPTY_ELEMENTDATA = new Object[0];
// 一个空对象,如果使用默认构造函数创建,则默认对象内容默认是该值
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = new Object[0];
// 当前数据对象存放地方,transient表明当前对象不参与序列化
transient Object[] elementData;
// 当前数组长度
private int size;
// 数组最大长度
private static final int MAX_ARRAY_SIZE = 2147483639;
// 方法开始
} 默认构造函数:
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
/** 也就是实现了 Object[] elementData;
elementData = new Object[0] ,即new了一个空的对象数组,数组长度是0 **/
}增加
ArrayList 添加了四种添加方法:
- add(E element)
- add(int i , E element)
- addAll(Collection)
- add(int index, E element)
数组末尾追加元素 add(E element)
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}ensureCapacityInternal() 确保添加的元素有地方存储,size+1,默认size为0,+1保证数组下标为size+1这个地方可以存储新元素,下面的 elementData[size++] = e 进行新的元素追加到数组并且上面的保证使其赋值不会数组越界;
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity)); } private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
} return minCapacity;
} private void ensureExplicitCapacity(int minCapacity) {
modCount++; // overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}minCapacity 为增加元素时所需最小长度数组容量大小;
下面第一次add时候,将当前elementData数组的长度用 Math.max 变为10,即第一次add时候 将数组长度 minCapacity 变为默认初始容量10;(jdk1.8以前都是直接初始化的时候指定this(10)直接指定默认容量大小)
非第一次add的时候,minCapacity 为原数组的长度+1:
如果所需的最小长度大于了现有数组长度,那么现在的数组容量肯定是不够的,需要进行扩容;
modCount 是从 abstractList 里面继承过来的值,用于迭代器Iterator的操作次数记录;
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 右移运算符等价于除以2,如果第一次是10,扩容之后的大小是15
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity; // 考虑边界问题,数组最大容量为2的31次方,int为四个字节,每个字节8位
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity); // minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity); } private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError(); return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE : MAX_ARRAY_SIZE; }扩容,如果添加元素所需最小容量minCapacity(即当前的数组已使用空间(size)加1)大于数组长度,则增大数组容量,扩大为原来的1.5倍。(右移一位相当于除以2)
数组最大容量为2的31次方,数组长度length属性是int,int为四个字节,每个字节8位,2G内存,没有人会丧心病狂搞这么大数组吧!
public static T[] copyOf(U[] original, int newLength, Class newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
} public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length); Arrays.copyOf追踪下去代码,确保有足够的容量之后,使用System.arraycopy 将旧数组拷贝到新的数组.
数组中间插入一个元素
public void add(int index, E element) {
// 判断index 是否有效
rangeCheckForAdd(index);
// 计数+1,并确认当前数组长度是否足够,和上面的追加一样
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index); // 将index 后面的数据都往后移一位
elementData[index] = element; // 设置目标数据
size++; } private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}需要插入的位置(index)后面的元素统统往后移动一位,然后将新值插入。
整个插入过程:
- 确保数插入的位置小于等于当前数组长度,并且不小于0,否则抛出异常;
- 确保数组此数组能放得下新的数据 所需长度minCapacity=size+1;
- 修改次数(modCount)标识自增1,如果当前数组所需长度大于当前的数组长度,则调用grow方法,增长数组;
- grow方法会将当前数组的长度变为原来容量的1.5倍;
- 确保有足够的容量之后,使用System.arraycopy 将需要插入的位置(index)后面的元素统统往后移动一位;
- 将新的数据内容存放到数组的指定位置(index)上;
删除
ArrayList 中提供了 五种删除数据的方式:
- remove(int i)
- remove(E element)
- removeRange(int start,int end)
- clear()
- removeAll(Collection c)
public E remove(int index) {
// 判断索引是否有效,范围检查
rangeCheck(index);
modCount++; // 获取对应数据
E oldValue = elementData(index);
// 判断删除数据位置
int numMoved = size - index - 1;
// 如果删除数据不是最后一位,则需要移动数组
// 先将index后面的元素往前面移动一位(调用System.arraycooy实现)
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
// 然后将最后一个元素置空,进行垃圾回收
elementData[--size] = null; return oldValue;
}修改
这个简单,需要改哪个,直接 data[index] = 4 重新赋值就可以
查找
数组支持随机访问,根据下标随机访问的时间复杂度为O(1)。
但是这并不代表数组的查找时间复杂度是O(1),即使是排好序的数组,你用二分查找,时间复杂度也是O(logn),这是两个概念。
数组和容器
数组时间复杂度
如果在数组的末尾插入元素,那就不需要移动数据了,这时的时间复杂度为O(1)。
但如果在数组的开头插入元素,那所有的数据都需要依次往后移动一位,所以 最坏时间复杂度是O(n)。
因为我们在每个位置插入元素的概率是一样的,所以平均情况时间复杂度为(1+2+...n)/n=O(n)。
数组插入,删除优化
上面数组的插入和删除效率是很低的,正是因为数组是连续的空间内存,而插入和删除的时候改变了数组的空间内存,为了维护连续的内存空间所以要进行数组元素的移动。
具有这个特性,就要维护他,比如红黑树具有查找快速的特点,插入和删除的时候就必须要通过各种左旋右旋操作来维护红黑树的平衡,其实是一样的道理。
插入优化
如果数组中的数据是有序的,我们在某个位置插入一个新的元素时,就必须按照刚才的方法搬移插入位置之后的数据。
但是,我们开发中,如果数组中存储的数据并没有任何规律,数组只是被当作一个存储数据的集合。在这种情况下,如果要将某个数据插入到第i个位置,为了避免大规模的数据搬移,还有一个简单高效的办法就是,直接将第i位的数据搬移到数组元素的最后,把新的元素直接放入第i个位置(具体如下图)。
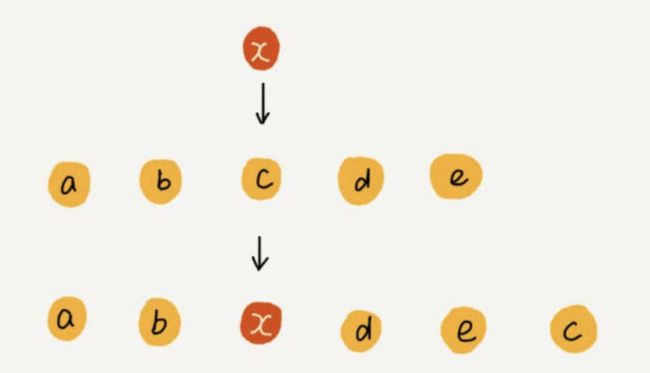
插入优化
利用这种处理技巧,在特定场景下,在第i个位置插入一个元素的时间复杂度立即降为了O(1),快排就用到了这个处理思想。
删除优化(标记清除算法)
标记清除算法 是JVM垃圾回收里面用到的核心算法,具体的可以看公众号《阿甘的码路》里面,有关垃圾回收机制相关的文章。
如果数组中数据不要求连续的情况下,我们将多次删除操作集中在一起执行,只做标记清除工作而不进行真正的删除,然后统一进行删除,删除的效率会提高很多不用进行数据多次的搬迁。
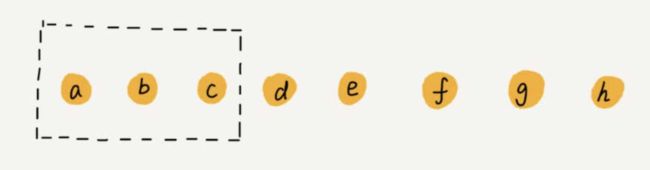
删除标记
容器替代数组?
容器优点:
- 动态扩容,程序员很舒服只需要一直add就好了不需要管数组大小是否足够
- 封装了很多细节,API丰富,将下标操作转化为英文add,remove等人类语言
容器缺点: 装箱拆箱有一定的性能损耗
数组优点:
- 多维数组直接用数组表示更加直观,如 int[3][4] arr 和 List
- 普通业务开发容器足够,底层开发例如网络框架这种对性能优化极致追求的代码用数组还是比较高效的。
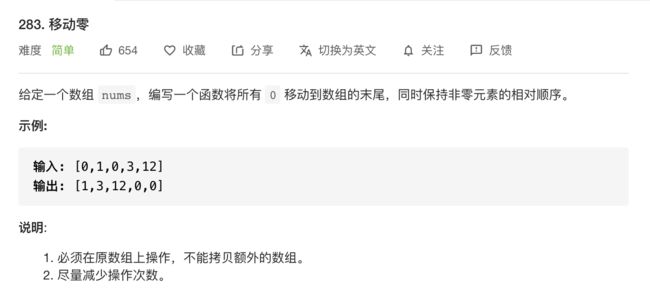
字节高频算法题:移动零
移动零题目
审题: 保持非零元素相对顺序,指的是元素在数组里面的相对顺序,而不是让保证元素相对大小。
思路:
- 遍历,遇0删除,列表最后添加0
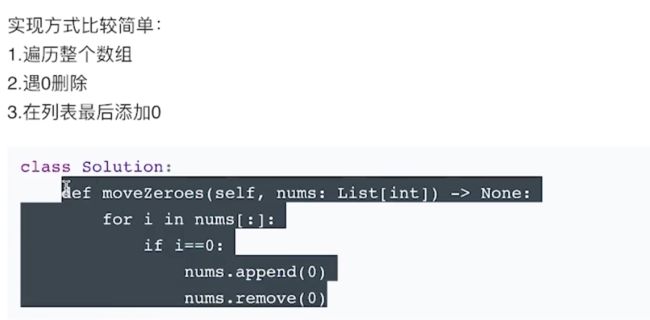
python实现
这里使用的Python的 api 还是很方便的,代码也很清晰明了,思路简单。JAVA就做不到这样add然后remove,集合的实现方式不一样,不信的话可以进行实现,你会发现有很多报错。
缺点: 空间复杂度很高,每次remove其实都需要移动此元素后面所有的元素。
- 两次遍历
创建两个指针i和j,第一次遍历的时候指针j用来记录当前有多少非0元素。即遍历的时候每遇到一个非0元素就将其往数组左边挪,第一次遍历完后,j指针的下标就指向了最后一个非0元素下标。
第二次遍历的时候,起始位置就从j开始到结束,将剩下的这段区域内的元素全部置为0。

两次遍历
时间复杂度:O(n)
空间复杂度:O(1)
- 最优解
在原数组上面进行操作,所有的非0元素往前移动,0自然在后面了
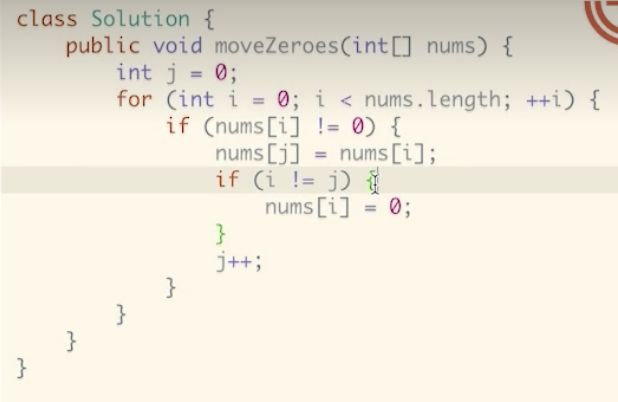
最优解
- j记录要填入的非零元素位置,遇到非0元素就挪动到j位置上;
- 遍历整个数组,遇到nums[i]==0 时候不处理;如果非0的时候,则把nums[i]的非0元素和nums[j]上的0元素互换,调换位置;
- j始终指向的是下一个非0元素;
很抽象,移动零最优解图解如下:
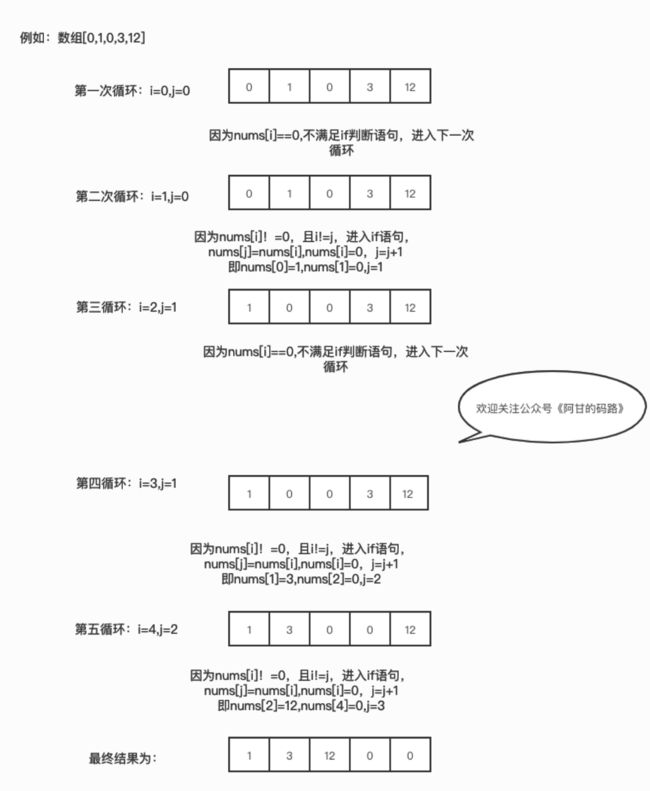
移动零最优解图解
省了一次遍历,借鉴了快排的思路:
快排:快速排序首先要确定一个待分割的元素做中间点x,然后把所有小于等于x的元素放到x的左边,大于x的元素放到其右边;
移动零:我们可以用0当做这个中间点,把不等于0(注意题目没说不能有负数)的放到中间点的左边,等于0的放到其右边。
- 从右往左开始遍历,所有的0元素往后移动,和上面的思路一样,读者如果可以根据上面的解法自己实现这种方式,那么这道算法算是理解了。
算法发散

爬楼梯
看到就头痛,
- 暴力破解?能暴力解决的问题绝不和平
- 递归?
参考资料:
- 数据结构与算法之美
- 大话数据结构
- 极客时间算法训练营视频讲解
睡觉了,明天还要搬砖,朋友有好的方法可以留言,下期图解此题~
欢迎批评指正,有收获的朋友点个在看或者分享鼓励一下吧,十分感谢~
公众号《阿甘的码路》关注我,一起成长