前言
OpenCV知识总结来到了下一个难度高一点的,掩码操作和模糊效果,这是图像处理里面常见的操作。
如果遇到问题请在这里联系我:https://www.jianshu.com/p/67324fb69074
正文
掩码操作实际上思想上很简单:根据一个掩码矩阵(卷积核)重新计算图像中的每一个像素。掩码矩阵中的值表示近邻像素的值(包括自身像素的值)对新像素的值有多大的影响,从数学上观点看来,就是对掩码矩阵内每一个设置好权重,然后对对应的像素领域内做一个权加平均。
数学上解释
卷积是什么?用一个简单的公式来表示:
输出 = 输入 * 系统
本质上,卷积就是这种思想。卷积把万事万物看成一个输入,当万事万物的状态出现了变化,则会通过某种系统产生变化,变成另一种输出状态。而这个系统往往就在数学眼里就叫做卷积。
而在深度学习中,往往每一个卷积核是一个奇数的矩阵,做图像识别的时候会通过这个卷积核做一次过滤,筛选出必要的特征信息。
那么掩码操作在数学上是怎么回事?我们平常运用掩码做什么?在OpenCV中掩码最常见的操作就是增加图片对比度。对比度的概念是什么,在上一节聊过,通俗来讲就是能够增强像素之间的细节。我们可以对对每个像素做如下操作:
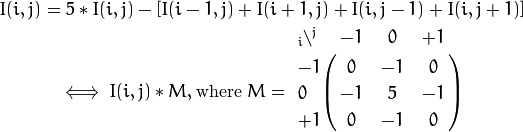
可能这幅图,理解起来比较困难。实际上流程如此:
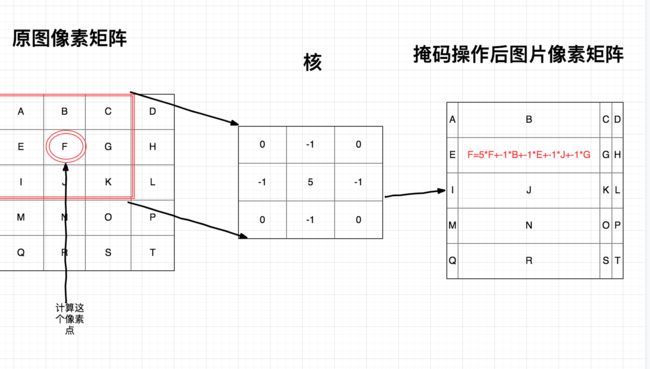
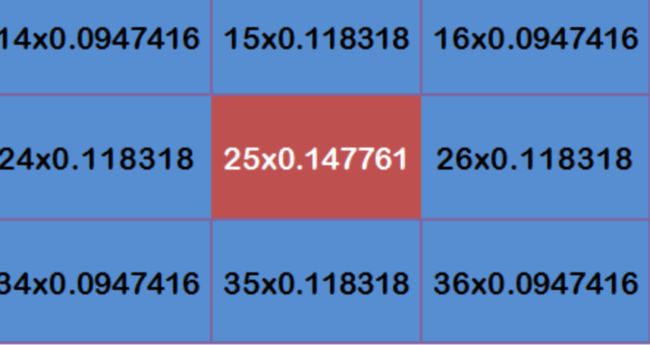
举个例子,就以计算出掩码矩阵之后的E的位置,能看到此时是原图中所有的像素都会取出和掩码矩阵一样大小的矩阵。也就是取出原图的红色那一块的领域,分别对E周边包括自己做了一次加权处理,最后赋值回E中。
并且进行如下的权加公式:
这样就能对原来的矩阵进行掩码处理。但是这么做发现没有,如果我们要对A做掩码处理就会发现掩码矩阵对应到原图的位置不存在。现在处理有两种,一种是不对边缘的像素做掩码处理,另一种是为周边的图像做一个padding处理,这种操作在深度学习的图像处理中很常见,通常设置0像素,或者拷贝对边的边缘像素。
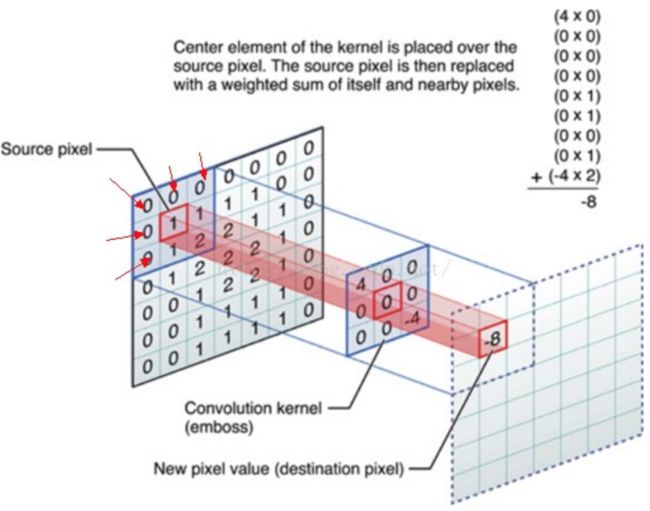
能看到这里处理和卷积处理不太一样,只是为了方便,把这种掩码滤波操作称为一种核,是自相关,并不是去计算卷积。
OpenCV的手写实现
Mat dst = Mat::zeros(src.size(), src.type());
int cols = (src.cols - 1) * src.channels();
int rows = src.rows;
int offsetx = src.channels();
for(int row = 1;row < rows - 1;row++){
//前一行
uchar* pre = src.ptr(row - 1);
//当前行
uchar* current = src.ptr(row);
//下一行
uchar* next = src.ptr(row+1);
//输出
uchar* out = dst.ptr(row);
//计算列以及里面的每一个颜色通道
/*
这种掩码是
0 -1 0
-1 5 -1
0 -1 0
*/
for(int col = offsetx;col < cols;col++){
//当前行
out[col] =saturate_cast(5 * current[col] -
(pre[col] + next[col] + current[col - offsetx] + current[col + offsetx])) ;
}
}
imshow("test",dst);
imshow("src", src);
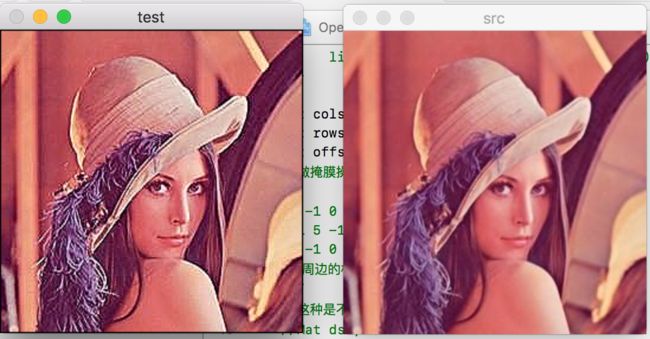
能看到此时这两张图片的对比度有很明显的区别。经过掩码矩阵之后,会发现原图会更加平滑一点,而掩码操作之后会导致整个图片最亮和最暗之间的差距拉大。
从数学公式上来看,当前像素权重为5,周边的点的权重是-1和0.能够发现会对当前的节点加深,同时把周围的像素值减掉,就增加了每一个像素点和周边像素差值,也就是对比度。
OpenCV中的滤波函数
当然在OpenCV中,有这么一个函数filter2D,处理掩码操作。
Mat kenrel = (Mat_(3,3)<< 0 ,-1 ,0, -1,5,-1,0,-1,0);
filter2D(src, dst, src.depth(), kenrel);
这里创建一个3*3的核。这个核实际上就是上图的那个。这样传递一个掩码矩阵和图像的深度就完成了掩码操作。
平滑操作
平滑也称为模糊,是一项高频率使用的操作。
平滑的作用有很多,其中一项就是降噪音。平滑处理和掩码操作有点相似,也是需要一个滤波器,我们最常用的滤波器就是线性滤波器。线性滤波处理的输出像素值是输出像素值的权加和:
其中,h(k,l)成为核,它仅仅只是一个权加系数。图形上的操作和上面的图相似。不妨把核当成一个滑动窗口,不断的沿着原图像素的行列扫动,扫动的过程中,不断的把路过像素都平滑处理。
均值(归一化)模糊
这里先介绍均值滤波器,它的核心如下:
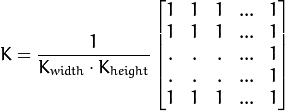
blur(src, dst, Size(121,121),Point(-1,-1));
这里的参数意思是,src:输入的图像,dst:经过均值模糊之后的输出图像,Size:是指这个滤波器的大小,Point是指整个图像模糊绕着哪个原点为半径的进行处理,传入(-1,-1)就是指图像中心,这样就能模糊整个图像。
其计算原理很简单就是,把核里面的所有权重设置为1,最后全部相加求平均值。最后赋值到原来的像素上。
高斯模糊
最有用的滤波器 (尽管不是最快的)。 高斯滤波是将输入数组的每一个像素点与 高斯内核 卷积将卷积和当作输出像素值。
高斯模糊实际上是一个二维的高斯核。回顾一下一维的高斯函数:
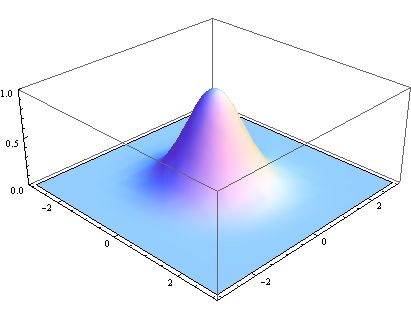
那么二维实际上就是,就是在原来的x,y轴的情况下,增加一个z轴的纬度,实际上看起来就像一座山一样。
二维的高斯函数可以表示为:
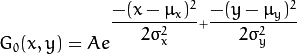
为了达到达到
其OpenCV的调用方式:
CV_EXPORTS_W void GaussianBlur( InputArray src, OutputArray dst, Size ksize,
double sigmaX, double sigmaY = 0,
int borderType = BORDER_DEFAULT );
GaussianBlur(src, gaussian, Size(121,121), 2);
这里的参数意思是,src:输入的图像,dst:经过高斯模糊之后的输出图像,Size:是指这个滤波器的大小。sigmaX和sigmaY分别指代的是高斯模糊x轴上和y轴上的二维高斯函数的变化幅度。
换个形象的话说,用上图举个例子,就是确定这个高斯函数这个山的x方向的陡峭程度以及y轴方向的陡峭程度。
下面就高斯模糊,均值模糊和原图的比对
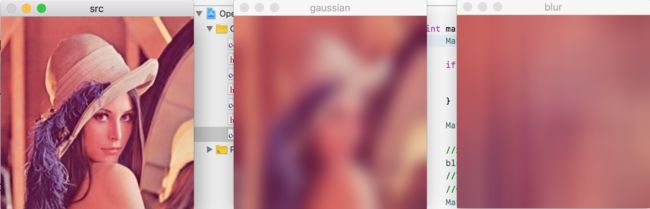
能看到,高斯模糊比起均值模糊保留了图像中相关的形状信息。
为什么会这样呢?原因很简单。因为在计算高斯模糊之前,会根据当前像素区域中所有的像素点进行一次,核的计算,越往中心的权重越高,权重如同小山一下,因此中心的像素权重像素一高了,虽然模糊但是还是保留了原来的形状。
但是当高斯模糊的矩阵大小和sigmaX,sigmaY相似的时候,整个高斯函数就不像山,而是想平原一样平坦。换句话说,整个高斯核中的权重就会,偏向一,就会导致和均值模糊类似效果。
GaussianBlur(src, gaussian, Size(121,121), 121);
高斯模糊计算流程:
图像中某一段图形的像素是如下分布,
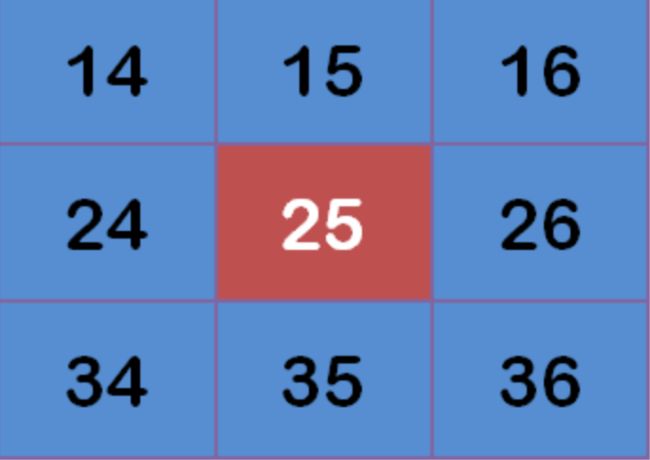
这个时候高斯模糊需要一个核去对每一个位置做滤波。此时不同于均值模糊,没有固定的核矩阵,而是通过上面这个矩阵,计算出高斯的核,最后再计算变化后的矩阵每一个对应的像素。
虽然原理是这样,但是实际上OpenCV为了迅速,在原生实现的时候,内部判断到核是小于7的大小,设置一套固定的高斯模糊矩阵。
static const float small_gaussian_tab[][SMALL_GAUSSIAN_SIZE] =
{
{1.f},
{0.25f, 0.5f, 0.25f},
{0.0625f, 0.25f, 0.375f, 0.25f, 0.0625f},
{0.03125f, 0.109375f, 0.21875f, 0.28125f, 0.21875f, 0.109375f, 0.03125f}
};
OpenCV filter滤波器源码解析
这样直接就结束,不是我文章的风格,作为一个程序员,还是有必要探索一下,为什么OpenCV计算速度会比我们自己手写的快。
为了让源码看的不那么辛苦,先聊聊OpenCV底层的设计思想。首先在OpenCV中,内置了几种计算方案,按照效率高低优先度依次的向后执行。
这种设计可以看成我们的平常开发的拦截器设计。当发现优先度高的计算模式发现可以使用的时候,OpenCV将会使用这种模式下的算法进行运算。
一般来说,OpenCV内置如下四个层级计算方案,按照优先顺序依次为:
| OpenCV计算方案 | 描述 |
|---|---|
| CV_IMPL_OCL(0x02) | OpenCL实际上是类似OpenGL一样借助显卡做并发计算 |
| CV_IMPL_IPP(0x04) | IPP库加速 |
| CV_IMPL_MT | 多线程处理 |
| CV_IMPL_PLAIN | OpenCV原生实现 |
能看到按照这个优先级不断的向下查找,找到当前OpenCV最快的计算环境。除了最后一个之外,其他三个都是并发计算。
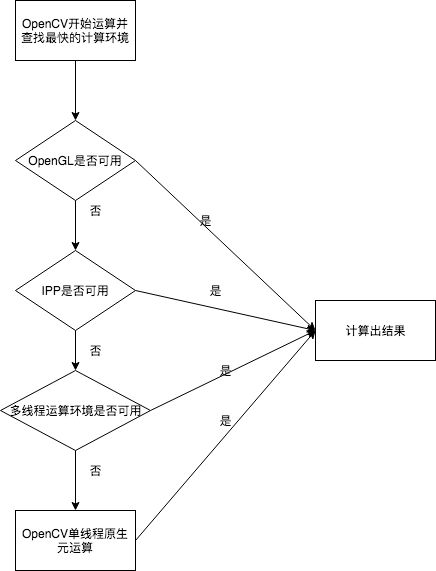
记住这个流程,我们查看OpenCV的源码就很轻松了。
先来看看filter2D的源码。
void filter2D(InputArray _src, OutputArray _dst, int ddepth,
InputArray _kernel, Point anchor0,
double delta, int borderType)
{
CV_INSTRUMENT_REGION();
CV_OCL_RUN(_dst.isUMat() && _src.dims() <= 2,
ocl_filter2D(_src, _dst, ddepth, _kernel, anchor0, delta, borderType))
Mat src = _src.getMat(), kernel = _kernel.getMat();
if( ddepth < 0 )
ddepth = src.depth();
_dst.create( src.size(), CV_MAKETYPE(ddepth, src.channels()) );
Mat dst = _dst.getMat();
Point anchor = normalizeAnchor(anchor0, kernel.size());
Point ofs;
Size wsz(src.cols, src.rows);
if( (borderType & BORDER_ISOLATED) == 0 )
src.locateROI( wsz, ofs );
hal::filter2D(src.type(), dst.type(), kernel.type(),
src.data, src.step, dst.data, dst.step,
dst.cols, dst.rows, wsz.width, wsz.height, ofs.x, ofs.y,
kernel.data, kernel.step, kernel.cols, kernel.rows,
anchor.x, anchor.y,
delta, borderType, src.isSubmatrix());
}
OpenCL执行原理
果不其然,在filter2D实现的第一步,就开始调用CV_OCL_RUN宏去调用OpenCL的显卡并发计算。
CV_OCL_RUN(_dst.isUMat() && _src.dims() <= 2,
ocl_filter2D(_src, _dst, ddepth, _kernel, anchor0, delta, borderType))
#define CV_OCL_RUN(condition, func) CV_OCL_RUN_(condition, func)
能看到,这里面发送了一个condition和一个方法到OpenCL中运行。但是如果,OpenCV在编译的时候,我们没有打开这个OpenCL的选项,没有OpenCL的环境的时候,它实际上就是一个没什么用处的宏:
#define CV_OCL_RUN_(condition, func, ...)
当有了OpenCL的环境,这个宏就会替换成这个:
#define CV_OCL_RUN_(condition, func, ...) \
{ \
if (cv::ocl::isOpenCLActivated() && (condition) && func) \
{ \
printf("%s: OpenCL implementation is running\n", CV_Func); \
fflush(stdout); \
CV_IMPL_ADD(CV_IMPL_OCL); \
return __VA_ARGS__; \
} \
else \
{ \
printf("%s: Plain implementation is running\n", CV_Func); \
fflush(stdout); \
} \
}
能清晰的看到,此时会判断当前的OpenCL是否还在活跃,活跃的状态,并且条件和方法符合规范,就会通过CV_IMPL_ADD,把方法添加到一个vector向量中,让OpenCL读取执行。
在这里面,OpenCV想要使用OpenCL进行计算,就需要这个Mat的类型是UMat,并且是纬度小于等于2.当不符合这两个条件将不会执行OpenCL。
UMat是专门给OpenCL规范计算而使用的矩阵。里面有很多和Mat相似的方法。
void addImpl(int flag, const char* func)
{
cv::AutoLock lock(getImplData().mutex);
getImplData().implFlags |= flag;
if(func) // use lazy collection if name was not specified
{
size_t index = getImplData().implCode.size();
if(!index || (getImplData().implCode[index-1] != flag || getImplData().implFun[index-1].compare(func))) // avoid duplicates
{
getImplData().implCode.push_back(flag);
getImplData().implFun.push_back(func);
}
}
}
此时可能是多线程处理,因此会添加一个智能锁,去保证数据的正确性。
具体的思路,将不作为重点,这边先看看OpenCV是传入了ocl_filter2D的方法,看看这个方法在OpenCL中的执行流程。
static bool ocl_filter2D( InputArray _src, OutputArray _dst, int ddepth,
InputArray _kernel, Point anchor,
double delta, int borderType )
{
//获取通道数和深度
int type = _src.type(), sdepth = CV_MAT_DEPTH(type), cn = CV_MAT_CN(type);
//如果传下来的深度小于0,则取原图的深度,否则取传下来的深度
ddepth = ddepth < 0 ? sdepth : ddepth;
//根据深度生成type,判断获取哪个深度原图和传下来更大,取最大
int dtype = CV_MAKE_TYPE(ddepth, cn), wdepth = std::max(std::max(sdepth, ddepth), CV_32F),
wtype = CV_MAKE_TYPE(wdepth, cn);
//通道数大于4说明不支持解析
if (cn > 4)
return false;
//获取核的大小
Size ksize = _kernel.size();
if (anchor.x < 0)
anchor.x = ksize.width / 2;
if (anchor.y < 0)
anchor.y = ksize.height / 2;
//使用哪一种滤波的边缘处理,
bool isolated = (borderType & BORDER_ISOLATED) != 0;
borderType &= ~BORDER_ISOLATED;
const cv::ocl::Device &device = cv::ocl::Device::getDefault();
//判断设备是否支持CV_64F的解析
bool doubleSupport = device.doubleFPConfig() > 0;
if (wdepth == CV_64F && !doubleSupport)
return false;
const char * const borderMap[] = { "BORDER_CONSTANT", "BORDER_REPLICATE", "BORDER_REFLECT",
"BORDER_WRAP", "BORDER_REFLECT_101" };
//获取核的大小
cv::Mat kernelMat = _kernel.getMat();
cv::Size sz = _src.size(), wholeSize;
size_t globalsize[2] = { (size_t)sz.width, (size_t)sz.height };
size_t localsize_general[2] = {0, 1};
size_t* localsize = NULL;
ocl::Kernel k;
UMat src = _src.getUMat();
//是否是不计算边缘的方式,不是则获取UMat矩阵头
if (!isolated)
{
Point ofs;
src.locateROI(wholeSize, ofs);
}
size_t tryWorkItems = device.maxWorkGroupSize();
if (device.isIntel() && 128 < tryWorkItems)
tryWorkItems = 128;
char cvt[2][40];
// For smaller filter kernels, there is a special kernel that is more
// efficient than the general one.
//判断其核的大小是否小于5,在很小的核,有更快的方式处理滤波
UMat kernalDataUMat;
if (device.isIntel() && (device.type() & ocl::Device::TYPE_GPU) &&
((ksize.width < 5 && ksize.height < 5) ||
(ksize.width == 5 && ksize.height == 5 && cn == 1)))
{
//把核化为行向量
kernelMat = kernelMat.reshape(0, 1);
String kerStr = ocl::kernelToStr(kernelMat, CV_32F);
int h = isolated ? sz.height : wholeSize.height;
int w = isolated ? sz.width : wholeSize.width;
//小于核说明有问题,不计算
if (w < ksize.width || h < ksize.height)
return false;
//判断当前的通道数字不为1则pxLoadNumPixels为1,如果通道数为1,则对着原图的宽度对4除余,0则为4,大于0则取1
// Figure out what vector size to use for loading the pixels.
int pxLoadNumPixels = cn != 1 || sz.width % 4 ? 1 : 4;
//乘以通道数。也就是说当通道数大于1,实际上pxLoadVecSize为通道数
//等于1则判断是否能除尽4,除得尽则取4,否则取1
int pxLoadVecSize = cn * pxLoadNumPixels;
// Figure out how many pixels per work item to compute in X and Y
// directions. Too many and we run out of registers.
int pxPerWorkItemX = 1;
int pxPerWorkItemY = 1;
if (cn <= 2 && ksize.width <= 4 && ksize.height <= 4)
{
pxPerWorkItemX = sz.width % 8 ? sz.width % 4 ? sz.width % 2 ? 1 : 2 : 4 : 8;
pxPerWorkItemY = sz.height % 2 ? 1 : 2;
}
else if (cn < 4 || (ksize.width <= 4 && ksize.height <= 4))
{
pxPerWorkItemX = sz.width % 2 ? 1 : 2;
pxPerWorkItemY = sz.height % 2 ? 1 : 2;
}
globalsize[0] = sz.width / pxPerWorkItemX;
globalsize[1] = sz.height / pxPerWorkItemY;
// Need some padding in the private array for pixels
//pxPerWorkItemX + ksize.width - 1四舍五入到pxLoadNumPixels的倍数
int privDataWidth = ROUNDUP(pxPerWorkItemX + ksize.width - 1, pxLoadNumPixels);
// Make the global size a nice round number so the runtime can pick
// from reasonable choices for the workgroup size
//globalsize四舍五入为256的倍数
const int wgRound = 256;
globalsize[0] = ROUNDUP(globalsize[0], wgRound);
char build_options[1024];
//构建命令
sprintf(build_options, "-D cn=%d "
"-D ANCHOR_X=%d -D ANCHOR_Y=%d -D KERNEL_SIZE_X=%d -D KERNEL_SIZE_Y=%d "
"-D PX_LOAD_VEC_SIZE=%d -D PX_LOAD_NUM_PX=%d "
"-D PX_PER_WI_X=%d -D PX_PER_WI_Y=%d -D PRIV_DATA_WIDTH=%d -D %s -D %s "
"-D PX_LOAD_X_ITERATIONS=%d -D PX_LOAD_Y_ITERATIONS=%d "
"-D srcT=%s -D srcT1=%s -D dstT=%s -D dstT1=%s -D WT=%s -D WT1=%s "
"-D convertToWT=%s -D convertToDstT=%s %s",
cn, anchor.x, anchor.y, ksize.width, ksize.height,
pxLoadVecSize, pxLoadNumPixels,
pxPerWorkItemX, pxPerWorkItemY, privDataWidth, borderMap[borderType],
isolated ? "BORDER_ISOLATED" : "NO_BORDER_ISOLATED",
privDataWidth / pxLoadNumPixels, pxPerWorkItemY + ksize.height - 1,
ocl::typeToStr(type), ocl::typeToStr(sdepth), ocl::typeToStr(dtype),
ocl::typeToStr(ddepth), ocl::typeToStr(wtype), ocl::typeToStr(wdepth),
ocl::convertTypeStr(sdepth, wdepth, cn, cvt[0]),
ocl::convertTypeStr(wdepth, ddepth, cn, cvt[1]), kerStr.c_str());
if (!k.create("filter2DSmall", cv::ocl::imgproc::filter2DSmall_oclsrc, build_options))
return false;
}
else
{
//大核不展开成行向量
localsize = localsize_general;
std::vector kernelMatDataFloat;
int kernel_size_y2_aligned = _prepareKernelFilter2D(kernelMatDataFloat, kernelMat);
String kerStr = ocl::kernelToStr(kernelMatDataFloat, CV_32F);
for ( ; ; )
{
size_t BLOCK_SIZE = tryWorkItems;
while (BLOCK_SIZE > 32 && BLOCK_SIZE >= (size_t)ksize.width * 2 && BLOCK_SIZE > (size_t)sz.width * 2)
BLOCK_SIZE /= 2;
if ((size_t)ksize.width > BLOCK_SIZE)
return false;
int requiredTop = anchor.y;
int requiredLeft = (int)BLOCK_SIZE; // not this: anchor.x;
int requiredBottom = ksize.height - 1 - anchor.y;
int requiredRight = (int)BLOCK_SIZE; // not this: ksize.width - 1 - anchor.x;
int h = isolated ? sz.height : wholeSize.height;
int w = isolated ? sz.width : wholeSize.width;
bool extra_extrapolation = h < requiredTop || h < requiredBottom || w < requiredLeft || w < requiredRight;
if ((w < ksize.width) || (h < ksize.height))
return false;
String opts = format("-D LOCAL_SIZE=%d -D cn=%d "
"-D ANCHOR_X=%d -D ANCHOR_Y=%d -D KERNEL_SIZE_X=%d -D KERNEL_SIZE_Y=%d "
"-D KERNEL_SIZE_Y2_ALIGNED=%d -D %s -D %s -D %s%s%s "
"-D srcT=%s -D srcT1=%s -D dstT=%s -D dstT1=%s -D WT=%s -D WT1=%s "
"-D convertToWT=%s -D convertToDstT=%s",
(int)BLOCK_SIZE, cn, anchor.x, anchor.y,
ksize.width, ksize.height, kernel_size_y2_aligned, borderMap[borderType],
extra_extrapolation ? "EXTRA_EXTRAPOLATION" : "NO_EXTRA_EXTRAPOLATION",
isolated ? "BORDER_ISOLATED" : "NO_BORDER_ISOLATED",
doubleSupport ? " -D DOUBLE_SUPPORT" : "", kerStr.c_str(),
ocl::typeToStr(type), ocl::typeToStr(sdepth), ocl::typeToStr(dtype),
ocl::typeToStr(ddepth), ocl::typeToStr(wtype), ocl::typeToStr(wdepth),
ocl::convertTypeStr(sdepth, wdepth, cn, cvt[0]),
ocl::convertTypeStr(wdepth, ddepth, cn, cvt[1]));
localsize[0] = BLOCK_SIZE;
globalsize[0] = DIVUP(sz.width, BLOCK_SIZE - (ksize.width - 1)) * BLOCK_SIZE;
globalsize[1] = sz.height;
if (!k.create("filter2D", cv::ocl::imgproc::filter2D_oclsrc, opts))
return false;
size_t kernelWorkGroupSize = k.workGroupSize();
if (localsize[0] <= kernelWorkGroupSize)
break;
if (BLOCK_SIZE < kernelWorkGroupSize)
return false;
tryWorkItems = kernelWorkGroupSize;
}
}
_dst.create(sz, dtype);
UMat dst = _dst.getUMat();
int srcOffsetX = (int)((src.offset % src.step) / src.elemSize());
int srcOffsetY = (int)(src.offset / src.step);
int srcEndX = (isolated ? (srcOffsetX + sz.width) : wholeSize.width);
int srcEndY = (isolated ? (srcOffsetY + sz.height) : wholeSize.height);
k.args(ocl::KernelArg::PtrReadOnly(src), (int)src.step, srcOffsetX, srcOffsetY,
srcEndX, srcEndY, ocl::KernelArg::WriteOnly(dst), (float)delta);
return k.run(2, globalsize, localsize, false);
}
OpenCL会把命令最后发送到显卡处理。
进入到hal中进一步处理
Mat src = _src.getMat(), kernel = _kernel.getMat();
if( ddepth < 0 )
ddepth = src.depth();
_dst.create( src.size(), CV_MAKETYPE(ddepth, src.channels()) );
Mat dst = _dst.getMat();
Point anchor = normalizeAnchor(anchor0, kernel.size());
Point ofs;
Size wsz(src.cols, src.rows);
if( (borderType & BORDER_ISOLATED) == 0 )
src.locateROI( wsz, ofs );
hal::filter2D(src.type(), dst.type(), kernel.type(),
src.data, src.step, dst.data, dst.step,
dst.cols, dst.rows, wsz.width, wsz.height, ofs.x, ofs.y,
kernel.data, kernel.step, kernel.cols, kernel.rows,
anchor.x, anchor.y,
delta, borderType, src.isSubmatrix());
实际上这一步和上面的方法有点相似。本质上都是获取需要模糊的区域,如果是(-1,-1),则取中心点,接着判断当前滤波对边缘的处理(BORDER_ISOLATED 不去获取Point为圆心设置的模糊之外的区域)。
enum BorderTypes {
BORDER_CONSTANT = 0, //!< `iiiiii|abcdefgh|iiiiiii` with some specified `i`
BORDER_REPLICATE = 1, //!< `aaaaaa|abcdefgh|hhhhhhh`
BORDER_REFLECT = 2, //!< `fedcba|abcdefgh|hgfedcb`
BORDER_WRAP = 3, //!< `cdefgh|abcdefgh|abcdefg`
BORDER_REFLECT_101 = 4, //!< `gfedcb|abcdefgh|gfedcba`
BORDER_TRANSPARENT = 5, //!< `uvwxyz|abcdefgh|ijklmno`
BORDER_REFLECT101 = BORDER_REFLECT_101, //!< same as BORDER_REFLECT_101
BORDER_DEFAULT = BORDER_REFLECT_101, //!< same as BORDER_REFLECT_101
BORDER_ISOLATED = 16 //!< do not look outside of ROI
};
能看到这个枚举已经解释很清楚了,默认的边缘处理是复制二个和倒数第二个填充边缘。
最后进入到hal的filter2D进一步操作。
void filter2D(int stype, int dtype, int kernel_type,
uchar * src_data, size_t src_step,
uchar * dst_data, size_t dst_step,
int width, int height,
int full_width, int full_height,
int offset_x, int offset_y,
uchar * kernel_data, size_t kernel_step,
int kernel_width, int kernel_height,
int anchor_x, int anchor_y,
double delta, int borderType,
bool isSubmatrix)
{
//判断到是可分离滤波,则原来的替代filter2d
bool res;
res = replacementFilter2D(stype, dtype, kernel_type,
src_data, src_step,
dst_data, dst_step,
width, height,
full_width, full_height,
offset_x, offset_y,
kernel_data, kernel_step,
kernel_width, kernel_height,
anchor_x, anchor_y,
delta, borderType, isSubmatrix);
if (res)
return;
//使用IPP处理filter2D
CV_IPP_RUN_FAST(ippFilter2D(stype, dtype, kernel_type,
src_data, src_step,
dst_data, dst_step,
width, height,
full_width, full_height,
offset_x, offset_y,
kernel_data, kernel_step,
kernel_width, kernel_height,
anchor_x, anchor_y,
delta, borderType, isSubmatrix))
//使用dft算法处理filter2D
res = dftFilter2D(stype, dtype, kernel_type,
src_data, src_step,
dst_data, dst_step,
width, height,
full_width, full_height,
offset_x, offset_y,
kernel_data, kernel_step,
kernel_width, kernel_height,
anchor_x, anchor_y,
delta, borderType);
if (res)
return;
//最后再进行效率最低的filter2D的原生操作
ocvFilter2D(stype, dtype, kernel_type,
src_data, src_step,
dst_data, dst_step,
width, height,
full_width, full_height,
offset_x, offset_y,
kernel_data, kernel_step,
kernel_width, kernel_height,
anchor_x, anchor_y,
delta, borderType);
}
能看到这里有四种方式:
- 1.判断是否是可分离的滤波,是则使用replacementFilter2D代替之后的算法。
- 2.使用IPP库并行计算
- 3.尝试着使用dft算法处理滤波
- 4.最后再是效率最差的滤波算法
在情况1中,一般的情况replacementFilter2D返回的是一个没有实现的错误码,第二种情况是Intel的并行计算库,没有任何研究,跳过。我们来看看第三种情况和第四种情况
filter2D的dft算法
static bool dftFilter2D(int stype, int dtype, int kernel_type,
uchar * src_data, size_t src_step,
uchar * dst_data, size_t dst_step,
int width, int height,
int full_width, int full_height,
int offset_x, int offset_y,
uchar * kernel_data, size_t kernel_step,
int kernel_width, int kernel_height,
int anchor_x, int anchor_y,
double delta, int borderType)
{
{
int sdepth = CV_MAT_DEPTH(stype);
int ddepth = CV_MAT_DEPTH(dtype);
int dft_filter_size = checkHardwareSupport(CV_CPU_SSE3) && ((sdepth == CV_8U && (ddepth == CV_8U || ddepth == CV_16S)) || (sdepth == CV_32F && ddepth == CV_32F)) ? 130 : 50;
if (kernel_width * kernel_height < dft_filter_size)
return false;
// detect roi case
if( (offset_x != 0) || (offset_y != 0) )
{
return false;
}
if( (width != full_width) || (height != full_height) )
{
return false;
}
}
Point anchor = Point(anchor_x, anchor_y);
Mat kernel = Mat(Size(kernel_width, kernel_height), kernel_type, kernel_data, kernel_step);
Mat src(Size(width, height), stype, src_data, src_step);
Mat dst(Size(width, height), dtype, dst_data, dst_step);
Mat temp;
int src_channels = CV_MAT_CN(stype);
int dst_channels = CV_MAT_CN(dtype);
int ddepth = CV_MAT_DEPTH(dtype);
// crossCorr doesn't accept non-zero delta with multiple channels
if (src_channels != 1 && delta != 0) {
// The semantics of filter2D require that the delta be applied
// as floating-point math. So wee need an intermediate Mat
// with a float datatype. If the dest is already floats,
// we just use that.
int corrDepth = ddepth;
if ((ddepth == CV_32F || ddepth == CV_64F) && src_data != dst_data) {
temp = Mat(Size(width, height), dtype, dst_data, dst_step);
} else {
corrDepth = ddepth == CV_64F ? CV_64F : CV_32F;
temp.create(Size(width, height), CV_MAKETYPE(corrDepth, dst_channels));
}
crossCorr(src, kernel, temp, anchor, 0, borderType);
add(temp, delta, temp);
if (temp.data != dst_data) {
temp.convertTo(dst, dst.type());
}
} else {
if (src_data != dst_data)
temp = Mat(Size(width, height), dtype, dst_data, dst_step);
else
temp.create(Size(width, height), dtype);
crossCorr(src, kernel, temp, anchor, delta, borderType);
if (temp.data != dst_data)
temp.copyTo(dst);
}
return true;
}
当然这里面判断能够使用dft的判断首先要当前必须要整张图做滤波处理,其次是不能是(0,0)的点为圆心做滤波。最后要判断当前当前的cpu指令是否支持,支持则允许核的宽高最高为130以内使用原生实现,否则只支持核的宽高为50以内使用原生实现。
能看到这里面的核心就是调用crossCorr,处理核以及原图的矩阵(使用了快速傅立叶处理相关性计算)。最后从同add添加到目标Mat中,由于add的delta函数为0,因此就和替代的效果一致。
OpenCV普通实现
static void ocvFilter2D(int stype, int dtype, int kernel_type,
uchar * src_data, size_t src_step,
uchar * dst_data, size_t dst_step,
int width, int height,
int full_width, int full_height,
int offset_x, int offset_y,
uchar * kernel_data, size_t kernel_step,
int kernel_width, int kernel_height,
int anchor_x, int anchor_y,
double delta, int borderType)
{
int borderTypeValue = borderType & ~BORDER_ISOLATED;
Mat kernel = Mat(Size(kernel_width, kernel_height), kernel_type, kernel_data, kernel_step);
Ptr f = createLinearFilter(stype, dtype, kernel, Point(anchor_x, anchor_y), delta,
borderTypeValue);
Mat src(Size(width, height), stype, src_data, src_step);
Mat dst(Size(width, height), dtype, dst_data, dst_step);
f->apply(src, dst, Size(full_width, full_height), Point(offset_x, offset_y));
}
能看到此时,先初始化一个FilterEngine(线性滤波引擎),接着使用apply调用滤波引擎的执行方法。
我们来看看线性引擎的创建:
Ptr createLinearFilter(
int _srcType, int _dstType,
InputArray filter_kernel,
Point _anchor, double _delta,
int _rowBorderType, int _columnBorderType,
const Scalar& _borderValue)
{
Mat _kernel = filter_kernel.getMat();
_srcType = CV_MAT_TYPE(_srcType);
_dstType = CV_MAT_TYPE(_dstType);
int cn = CV_MAT_CN(_srcType);
CV_Assert( cn == CV_MAT_CN(_dstType) );
Mat kernel = _kernel;
int bits = 0;
....
Ptr _filter2D = getLinearFilter(_srcType, _dstType,
kernel, _anchor, _delta, bits);
return makePtr(_filter2D, Ptr(),
Ptr(), _srcType, _dstType, _srcType,
_rowBorderType, _columnBorderType, _borderValue );
}
实际上在这个过程中通过makePtr创建一个sharedptr的指针指向FilterEngine,其原理和Android的智能指针相似。
这个引擎不是关键关键的是getLinearFilter,这个方法创建了一个线性滤波器的实际操作对象。
我们来看看这个结构体:
能看到这里面会根据次数传进来的目标矩阵和原始矩阵的位深创建不同的滤波操作者。
Ptr getLinearFilter(
int srcType, int dstType,
const Mat& _kernel, Point anchor,
double delta, int bits)
{
CV_INSTRUMENT_REGION();
int sdepth = CV_MAT_DEPTH(srcType), ddepth = CV_MAT_DEPTH(dstType);
int cn = CV_MAT_CN(srcType), kdepth = _kernel.depth();
CV_Assert( cn == CV_MAT_CN(dstType) && ddepth >= sdepth );
anchor = normalizeAnchor(anchor, _kernel.size());
/*if( sdepth == CV_8U && ddepth == CV_8U && kdepth == CV_32S )
return makePtr, FilterVec_8u> >
(_kernel, anchor, delta, FixedPtCastEx(bits),
FilterVec_8u(_kernel, bits, delta));
if( sdepth == CV_8U && ddepth == CV_16S && kdepth == CV_32S )
return makePtr, FilterVec_8u16s> >
(_kernel, anchor, delta, FixedPtCastEx(bits),
FilterVec_8u16s(_kernel, bits, delta));*/
kdepth = sdepth == CV_64F || ddepth == CV_64F ? CV_64F : CV_32F;
Mat kernel;
if( _kernel.type() == kdepth )
kernel = _kernel;
else
_kernel.convertTo(kernel, kdepth, _kernel.type() == CV_32S ? 1./(1 << bits) : 1.);
if( sdepth == CV_8U && ddepth == CV_8U )
return makePtr, FilterVec_8u> >
(kernel, anchor, delta, Cast(), FilterVec_8u(kernel, 0, delta));
if( sdepth == CV_8U && ddepth == CV_16U )
return makePtr, FilterNoVec> >(kernel, anchor, delta);
//根据位深创建不同的滤波操作者
...
CV_Error_( CV_StsNotImplemented,
("Unsupported combination of source format (=%d), and destination format (=%d)",
srcType, dstType));
}
假设,我们现在原图和目标图都是8位位深的矩阵,我们只需要关注下面这个构造函数。
return makePtr, FilterVec_8u> >
(kernel, anchor, delta, Cast(), FilterVec_8u(kernel, 0, delta));
Fliter2D结构体
template struct Filter2D : public BaseFilter
{
typedef typename CastOp::type1 KT;
typedef typename CastOp::rtype DT;
Filter2D( const Mat& _kernel, Point _anchor,
double _delta, const CastOp& _castOp=CastOp(),
const VecOp& _vecOp=VecOp() )
{
anchor = _anchor;
ksize = _kernel.size();
delta = saturate_cast(_delta);
castOp0 = _castOp;
vecOp = _vecOp;
CV_Assert( _kernel.type() == DataType::type );
preprocess2DKernel( _kernel, coords, coeffs );
ptrs.resize( coords.size() );
}
void operator()(const uchar** src, uchar* dst, int dststep, int count, int width, int cn) CV_OVERRIDE
{
KT _delta = delta;
//拿到所有权重不为0的像素点位置
const Point* pt = &coords[0];
//拿到所有的像素值
const KT* kf = (const KT*)&coeffs[0];
const ST** kp = (const ST**)&ptrs[0];
int i, k, nz = (int)coords.size();
CastOp castOp = castOp0;
width *= cn;
for( ; count > 0; count--, dst += dststep, src++ )
{
DT* D = (DT*)dst;
//把原图每一次需要计算的点
for( k = 0; k < nz; k++ )
kp[k] = (const ST*)src[pt[k].y] + pt[k].x*cn;
i = vecOp((const uchar**)kp, dst, width);
#if CV_ENABLE_UNROLLED
for( ; i <= width - 4; i += 4 )
{
KT s0 = _delta, s1 = _delta, s2 = _delta, s3 = _delta;
for( k = 0; k < nz; k++ )
{
const ST* sptr = kp[k] + i;
KT f = kf[k];
s0 += f*sptr[0];
s1 += f*sptr[1];
s2 += f*sptr[2];
s3 += f*sptr[3];
}
D[i] = castOp(s0); D[i+1] = castOp(s1);
D[i+2] = castOp(s2); D[i+3] = castOp(s3);
}
#endif
for( ; i < width; i++ )
{
KT s0 = _delta;
for( k = 0; k < nz; k++ )
s0 += kf[k]*kp[k][i];
D[i] = castOp(s0);
}
}
}
std::vector coords;
std::vector coeffs;
std::vector ptrs;
KT delta;
CastOp castOp0;
VecOp vecOp;
};
Fliter2D结构体持有着模糊中心点,核,原/目标矩阵, 可以猜测到实际上正在做操作的就是这个结构体。
在preprocess2DKernel方法中,Fliter2D把核的相关信息存储到coords,coeffs中
uchar* _coeffs = &coeffs[0];
for( i = k = 0; i < kernel.rows; i++ )
{
const uchar* krow = kernel.ptr(i);
for( j = 0; j < kernel.cols; j++ )
{
if( ktype == CV_8U )
{
uchar val = krow[j];
if( val == 0 )
continue;
coords[k] = Point(j,i);
_coeffs[k++] = val;
}
...
可以看到此时会判断当前的核矩阵中type是什么,接着再把矩阵中每一个不为0的位置设置进coords,像素数值设置到_coeffs。此时相当于把核矩阵展开成一个向量。
滤波引擎的执行流程
void FilterEngine__apply(FilterEngine& this_, const Mat& src, Mat& dst, const Size& wsz, const Point& ofs)
{
CV_INSTRUMENT_REGION();
CV_DbgAssert(src.type() == this_.srcType && dst.type() == this_.dstType);
FilterEngine__start(this_, wsz, src.size(), ofs);
int y = this_.startY - ofs.y;
FilterEngine__proceed(this_,
src.ptr() + y*src.step,
(int)src.step,
this_.endY - this_.startY,
dst.ptr(),
(int)dst.step );
}
能看到此时滤波引擎会先调用FilterEngine__start,再调用FilterEngine__proceed执行计算。
实际上在FilterEngine__start中计算的是本次循环,需要计算的边界。
FilterEngine__proceed中才是正式计算,做dst循环,最后把具体操作丢给线性引擎生成的Fliter2D的方法中。
fliter运作原理
了解这两个东西我们直接抽出核心看看fliter是如何运作:
for(;; dst += dststep*i, dy += i)
{
//计算每一列的矩阵中有多少像素,以及步长是多少
int dcount = bufRows - ay - this_.startY - this_.rowCount + this_.roi.y;
dcount = dcount > 0 ? dcount : bufRows - kheight + 1;
dcount = std::min(dcount, count);
count -= dcount;
//获取到目标的矩阵的一行的像素长度,则开始循环原矩阵的像素
for( ; dcount-- > 0; src += srcstep )
{
//计算每一行像素开始读取的起点
int bi = (this_.startY - this_.startY0 + this_.rowCount) % bufRows;
uchar* brow = alignPtr(&this_.ringBuf[0], VEC_ALIGN) + bi*this_.bufStep;
uchar* row = isSep ? &this_.srcRow[0] : brow;
if (++this_.rowCount > bufRows)
{
--this_.rowCount;
++this_.startY;
}
//拷贝数据到row的起点+边缘,长度为添加的像素的一行-左边padding-右边padding
memcpy( row + _dx1*esz, src, (width1 - _dx2 - _dx1)*esz );
//如果设置边缘
if( makeBorder )
{
if( btab_esz*(int)sizeof(int) == esz )
{
const int* isrc = (const int*)src;
int* irow = (int*)row;
for( i = 0; i < _dx1*btab_esz; i++ )
irow[i] = isrc[btab[i]];
for( i = 0; i < _dx2*btab_esz; i++ )
irow[i + (width1 - _dx2)*btab_esz] = isrc[btab[i+_dx1*btab_esz]];
}
else
{
//由于上面计算的去掉了边缘,这里要加上需要的边缘,分别复制到左右两侧
for( i = 0; i < _dx1*esz; i++ )
row[i] = src[btab[i]];
for( i = 0; i < _dx2*esz; i++ )
row[i + (width1 - _dx2)*esz] = src[btab[i+_dx1*esz]];
}
}
//如果是可分离的滤波则调用rowFilter分离处理每行的数据
if( isSep )
(*this_.rowFilter)(row, brow, width, CV_MAT_CN(this_.srcType));
}
//准备好每一行之后数据空间,是时候计算每一列的数据,算出要循环多少列
int max_i = std::min(bufRows, this_.roi.height - (this_.dstY + dy) + (kheight - 1));
for( i = 0; i < max_i; i++ )
{
//行的边缘处理了,需要处理列的边缘。这里计算需要开始计算的列的起点
int srcY = borderInterpolate(this_.dstY + dy + i + this_.roi.y - ay,
this_.wholeSize.height, this_.columnBorderType);
if( srcY < 0 ) // can happen only with constant border type
brows[i] = alignPtr(&this_.constBorderRow[0], VEC_ALIGN);
else
{
CV_Assert(srcY >= this_.startY);
if( srcY >= this_.startY + this_.rowCount)
break;
int bi = (srcY - this_.startY0) % bufRows;
brows[i] = alignPtr(&this_.ringBuf[0], VEC_ALIGN) + bi*this_.bufStep;
}
}
if( i < kheight )
break;
i -= kheight - 1;
//开始调用filter2D构造函数中operate()
if (isSep)
(*this_.columnFilter)((const uchar**)brows, dst, dststep, i, this_.roi.width*cn);
else
(*this_.filter2D)((const uchar**)brows, dst, dststep, i, this_.roi.width, cn);
}
从上面Fliter2D结构体小结,实际上这里的核心操作如下:
i = vecOp((const uchar**)kp, dst, width);
而vecOp在此时指的是FilterVec_8u结构体,我们同样去看看这个构造体做了什么:
int operator()(const uchar** src, uchar* dst, int width) const
{
CV_INSTRUMENT_REGION();
CV_DbgAssert(_nz > 0);
//这个也是把核转化为行向量
const float* kf = (const float*)&coeffs[0];
int i = 0, k, nz = _nz;
v_float32 d4 = vx_setall_f32(delta);
v_float32 f0 = vx_setall_f32(kf[0]);
//循环宽度,长度是width-16,步数是16
for( ; i <= width - v_uint8::nlanes; i += v_uint8::nlanes )
{
v_uint16 xl, xh;
//读取原图中需要处理像素的开始位置,并且把数据分为上下高低两个16位
v_expand(vx_load(src[0] + i), xl, xh);
v_uint32 x0, x1, x2, x3;
//高低16位再次分成上下两个8位
v_expand(xl, x0, x1);
v_expand(xh, x2, x3);
//v_muladd这里做的事情是s0 = x0*f0+d4
//f0:核心矩阵的第一个元素,d4就是一个额外线性权重
v_float32 s0 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x0)), f0, d4);
v_float32 s1 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x1)), f0, d4);
v_float32 s2 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x2)), f0, d4);
v_float32 s3 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x3)), f0, d4);
for( k = 1; k < nz; k++ )
{
v_float32 f = vx_setall_f32(kf[k]);
v_expand(vx_load(src[k] + i), xl, xh);
v_expand(xl, x0, x1);
v_expand(xh, x2, x3);
//计算第一个之后,基于第一个重新计算s0 = x0 * f + s0
s0 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x0)), f, s0);
s1 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x1)), f, s1);
s2 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x2)), f, s2);
s3 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x3)), f, s3);
}
v_store(dst + i, v_pack_u(v_pack(v_round(s0), v_round(s1)), v_pack(v_round(s2), v_round(s3))));
}
//如果发现i在宽度width - 16内,说明还没有循环完原图,但是核的步数太大而没走到
//处理剩余的数据,按照16位不断的前进处理
if( i <= width - v_uint16::nlanes )
{
v_uint32 x0, x1;
v_expand(vx_load_expand(src[0] + i), x0, x1);
v_float32 s0 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x0)), f0, d4);
v_float32 s1 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x1)), f0, d4);
for( k = 1; k < nz; k++ )
{
v_float32 f = vx_setall_f32(kf[k]);
v_expand(vx_load_expand(src[k] + i), x0, x1);
s0 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x0)), f, s0);
s1 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(x1)), f, s1);
}
v_pack_u_store(dst + i, v_pack(v_round(s0), v_round(s1)));
i += v_uint16::nlanes;
}
#if CV_SIMD_WIDTH > 16
while( i <= width - v_int32x4::nlanes )
#else
//发现处理完之后,i还在width-4内,说明16的步数太大,再度按照步数4处理数据
if( i <= width - v_int32x4::nlanes )
#endif
{
v_float32x4 s0 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(v_load_expand_q(src[0] + i))), v_setall_f32(kf[0]), v_setall_f32(delta));
for( k = 1; k < nz; k++ )
s0 = v_muladd(v_cvt_f32(v_reinterpret_as_s32(v_load_expand_q(src[k] + i))), v_setall_f32(kf[k]), s0);
v_int32x4 s32 = v_round(s0);
v_int16x8 s16 = v_pack(s32, s32);
*(unaligned_int*)(dst + i) = v_reinterpret_as_s32(v_pack_u(s16, s16)).get0();
i += v_int32x4::nlanes;
}
return i;
}
主要的流程在注释已经解释了。这里再度总结一下:
其核心逻辑如下,把原图和核转化一个行向量,如下图
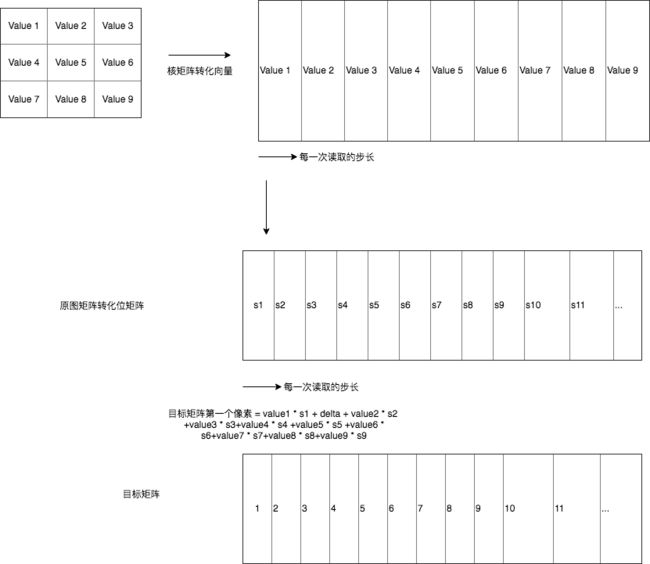
但是,fliter2d担心核心每一步走的太大。因此当走完循环,则会检查此时i指针是否已经走完一行中所有的数据(一行的数据量-16),没有则按照16位的步数再处理剩下,接着再检查(一行的数据量-4),还在这个范围,说明这个时候还有数据没有处理,则按照4位的前进处理。
可以看到opencv的确实比我们的demo严谨很多。
总结
这个掩码以及平滑操作,实际上是计算机图像学中的基础。经过对opencv的源码解析,相信各位对掩码操作有更加深刻的理解。
但是,这里我并有写高斯模糊的源码解析也没有对dst(离散傅立叶变换)进行解析,因为其核心和fliter相似,也是计算自相关。
可惜的是,篇幅原因,第二个是本人对dst虽然有一定的了解,但是要提炼成文字还需要一定火候以及更加深刻的理解。相信不久的将来,我会和大家解析我没有解析在大核情况下,使用dst(离散傅立叶变换)的opencv原理。
这也是第一次让我看源码感到十分吃力,明明我的主张就是源码在手天下我有的态度,看来我的数学基础还需要进一步补充。