Ubuntu20.04下安装 NVIDIADriver-460、CUDA-10.0、cuDNN、tensorflow、pytorch
Ubuntu下安装 NVIDIADriver、CUDA、cuDNN、tensorflow、pytorch
1、安装NVIDIA驱动
首先,检测你的NVIDIA显卡型号和推荐的驱动程序的模型。
ubuntu-drivers devices
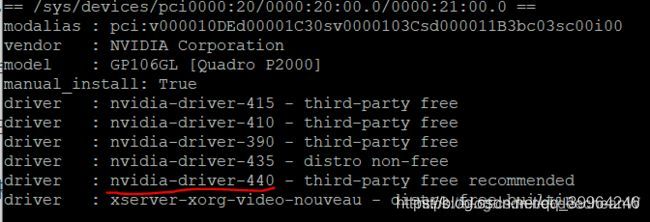
从返回信息可以看到,系统推荐的nvidia驱动版本是nvidia-driver-440。
在开始安装nvidia驱动之前,还有一些准备工作要做。
如果你曾安装过其他版本,卸载原有的NVIDIA驱动。
sudo apt-get remove –purge nvidia*
禁用自带的 nouveau nvidia驱动,通过命令创建一个文件。
sudo vim /etc/modprobe.d/blacklist-nouveau.conf
并添加如下内容:
blacklist nouveau
options nouveau modeset=0
执行以下命令,让改动生效。
sudo update-initramfs -u
确认下Nouveau是已经被你干掉,使用命令:
lsmod | grep nouveau
如果在返回信息里没有看到nouveau,则说明已经成功干掉nouveau。
安装nvidia driver
sudo apt-get install nvidia-driver-460
安装完成后,重启
sudo reboot
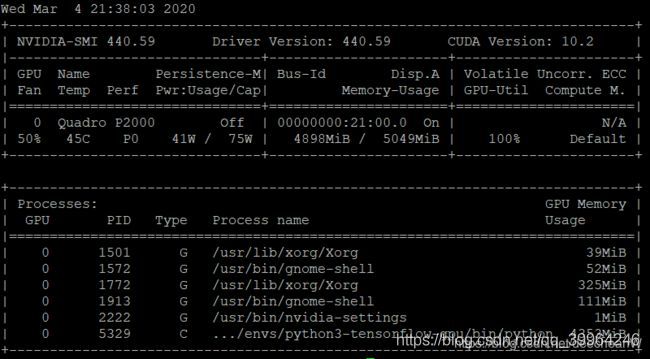
验证驱动是否安装成功,输入以下命令,如果可以看到下面画面,就说明驱动安装成功了。
nvidia-smi
2、安装CUDA
到NVIDIA官网中,找到CUDA下载。
Nivdia官网下载cuda
我下载的版本是CUDA Toolkit 10.2。
由于CUDA和nvidia-driver有依赖关系,所以选择下载的版本之前,要查看一下CUDA的release note里对nvidia-driver的版本要求。
版本要求
以下是CUDA 10.2的release note里提供的CUDA和nvidia driver的版本兼容关系。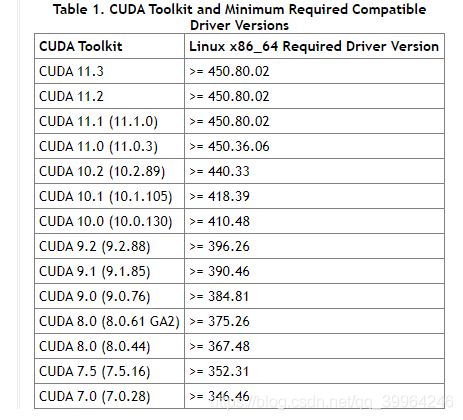
我安装的驱动版本是440.59,因此可以安装目前最新的CUDA 10.2.89。于是到 官网下载相应的版本。我的操作系统是Ubuntu 18.04,选择下载runfile。

完成版本选择后,NVIDIA官网还很贴心的给出了linux下载安装包的命令行,和运行安装包的命令。
wget http://developer.download.nvidia.com/compute/cuda/10.2/Prod/local_installers/cuda_10.2.89_440.33.01_linux.run
sudo sh cuda_10.2.89_440.33.01_linux.run
此处需要主要的是在运行runfile之前,需要先安装gcc-multilib。
sudo apt install gcc-multilib
进入安装后,先要浏览一段很长的协议,按回车键往下滚到底,也可直接输入q进行安装
Do you accept the previously read EULA?
accept/decline/quit: accept
You are attempting to install on an unsupported configuration. Do you wish to continue?
(y)es/(n)o [ default is no ]: y
Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 387.26?
(y)es/(n)o/(q)uit: n
Install the CUDA 9.1 Toolkit?
(y)es/(n)o/(q)uit: y
Enter Toolkit Location
[ default is /usr/local/cuda-9.1 ]: 直接回车,安装到默认目录下
Do you want to install a symbolic link at /usr/local/cuda?
(y)es/(n)o/(q)uit: y
Install the CUDA 9.1 Samples?
(y)es/(n)o/(q)uit: y
Enter CUDA Samples Location
[ default is /home/ubuntu ]: 直接回车,安装到默认目录下
然后就一路到安装结束。安装介绍后,记得要输出路径。
配置环境变量:
gedit ~/.bashrc
在打开的文件最后添加以下语句并保存:
export PATH=/usr/local/cuda-10.2/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-10.2/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
更新环境变量配置
source ~/.bashrc
接下来验证一下CUDA是否安装正确。先输入以下命令试着看一下CUDA的版本。
nvcc -V
让人抓狂的事情又发生了,居然提示没有安装CUDA tool kit,并提示如果需安装请执行
sudo apt install nvidia-cuda-toolkit
可是,之前cuda的安装信息明明显示已经将toolkit安装到/usr/local/cuda-9.1了,而且路径也已经输出了。百思不得其解,索性按照提示执行上述命令。
于是,再安装了一遍cuda toolkit。 完成安装后再输入nvcc -V,这次终于看到版本信息了。显示目前安装的版本是release9.1,完全正确。

接下来,我们再尝试编译一个CUDA自带的sample来验证以下安装是否成功。
根据之前cuda的安装提示sample被安装到了/home/ubuntu目录下,此处ubuntu是我的登录用户名。查看该目录确实发现有一个NVIDIA_CUDA-9.1_Samples的目录,进入该目录并找到 1_Utilities/deviceQuery 例子,进行编译。
cd /home/ubuntu/NVIDIA_CUDA-9.1_Samples/1_Utilities/deviceQuery
make
执行了make之后,就应该可以看到如下的输出了,如果不行的话请确认以下g++是否安装了。

编译完成后执行deviceQuery
sudo ./deviceQuery
如果你可以看到以下类似的输出,那表面CUDA安装成功了。

安装cuDNN
cuDNN的官网地址如下,首先依旧是上官网查看以下适用版本和下载信息。
cuDNN下载官网
下载cuDNN首先得登录Nvidia Developer账户,如何么有就注册一个。另外,nvidia还支持用微信和QQ账号登陆。
下载前务必查询以下你的CUDA版本兼容的cuDNN,每个cuDNN都会有多下载包分别个支持不同CUDA版本的,务必要看仔细了。
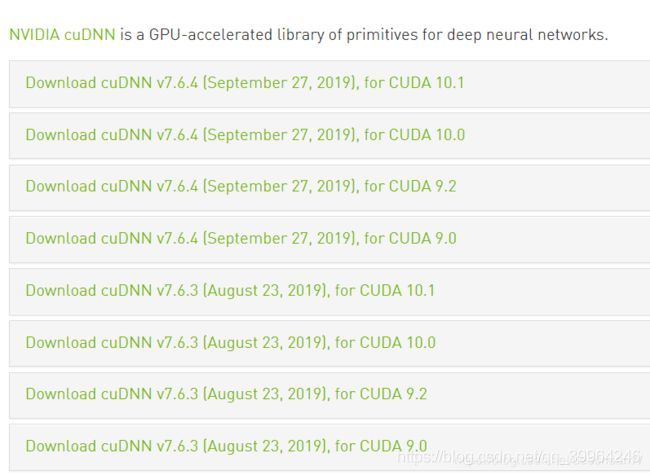
另外,兼容信息也可以在cuDNN的release note里的cuDNN Support Matrix章节有给出,以下是链接。
添加链接描述
下图是关于cuDNN的最新版本 v7.6.4-v7.6.5的兼容性信息,我第一台最新的工作站是Quadro P2000的显卡安装的是440的nvidia驱动和10.2的CUDA,因此安装最新的cuDNN版本没有问题。但是我另外一台老的Quadro K2200的显卡配390的驱动和9.1.85的CUDA就和目前最新的cuDNN不兼容。

继续查询,发现这个版本的CUDA和所有的7.1.4以上版本的cuDNN都不兼容。在一通搜索之后终于找到了这个v7.1.3,而且这个版本对Ubuntu支持只有deb文件,而且对Ubuntu的支持仅到16.04, 而我的Ubuntu是18.06。本着选择最接近的版本,下载了cuDNN v7.1.3 Developer Library for Ubuntu16.04 (Deb)。

执行命令dkpg -i来安装deb包,这一次总算是一切顺利。
sudo pkdg -i
从 https://developer.nvidia.com/cudnn 下载cuDNN,需要注册登陆,也可以从我的网盘下载, 链接: https://pan.baidu.com/s/1CVFc6GWicpf7hYI9VqcBsw 密码: j927
下载解压:
tar -xvf cudnn-10.0-linux-x64-v7.6.5.32.tgz
1
将cuda/include/cudnn.h文件复制到usr/local/cuda/include文件夹,将cuda/lib64/下所有文件复制到/usr/local/cuda/lib64文件夹中,并添加读取权限:
sudo cp ./cuda/lib64/* /usr/local/cuda-10.0/lib64
sudo cp ./cuda/include/cudnn.h /usr/local/cuda/include
sudo chmod a+r /usr/local/cuda-10.0/include/cudnn.h /usr/local/cuda-10.0/lib64/libcudnn*
好了,大功告成,输入命令检验:
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A
验证
找到cuda-install-samples-10.2.sh文件,后面/home/archy是你自己的路径。
/usr/local/cuda-10.2/bin/cuda-install-samples-10.2.sh /home/archy/
结果显示如下:
Copying samples to /home/archy/NVIDIA_CUDA-10.2_Samples now...
Finished copying samples.
在home主目录下,找到/NVIDIA_CUDA-10.2_Samples/1_Utilities/deviceQuery,执行命令make &&./deviceQuery
cd NVIDIA_CUDA-10.2_Samples/1_Utilities/deviceQuery
make &&./deviceQuery
显示以下结果:
Detected 1 CUDA Capable device(s)
Device 0: "GeForce RTX 2080 Ti"
CUDA Driver Version / Runtime Version 11.0 / 10.2
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 11011 MBytes (11546329088 bytes)
(68) Multiprocessors, ( 64) CUDA Cores/MP: 4352 CUDA Cores
GPU Max Clock rate: 1635 MHz (1.63 GHz)
Memory Clock rate: 7000 Mhz
Memory Bus Width: 352-bit
L2 Cache Size: 5767168 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 3 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 101 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.0, CUDA Runtime Version = 10.2, NumDevs = 1
Result = PASS
验证其他例子的时候发现会提示:
#error -- unsupported GNU version! gcc versions later than 8 are not supported!
输入命令查看
ls /usr/local/cuda/bin/
是否包括gcc 和g++两个文件夹。
bin2c cuobjdump nvdisasm
computeprof fatbinary nvlink
crt nsight nv-nsight-cu
cudafe++ nsight_ee_plugins_manage.sh nv-nsight-cu-cli
cuda-gdb nsight-sys nvprof
cuda-gdbserver nsys nvprune
cuda-install-samples-10.2.sh nsys-exporter nvvp
cuda-memcheck nvcc ptxas
cuda-uninstaller nvcc.profile
如果向上面一样没有gcc和g++,建立软链接,如下操作:
sudo ln -s /usr/bin/gcc-7 /usr/local/cuda/bin/gcc
sudo ln -s /usr/bin/g++-7 /usr/local/cuda/bin/g++
操作后显示有g++ 和gcc了,如图:
bin2c fatbinary nvdisasm
computeprof g++ nvlink
crt gcc nv-nsight-cu
cudafe++ nsight nv-nsight-cu-cli
cuda-gdb nsight_ee_plugins_manage.sh nvprof
cuda-gdbserver nsight-sys nvprune
cuda-install-samples-10.2.sh nsys nvvp
cuda-memcheck nsys-exporter ptxas
cuda-uninstaller nvcc
cuobjdump nvcc.profile
若操作失误,建立错误gcc或g++,使用sudo rm g++删除重新执行上述命令即可。
踩坑记录
安装最新版本的CUDA,基本没有什么问题。然而,再装另外两台工作站是,却踩坑了。
重启后nvidia驱动消失
当我完成所有安装和设置并重启,结果却发现nvidia-smi运行失败了。系统提示
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.

网上查了一下,发现大部分人都说是因为重启后Ubuntu的内核版本改变了。要将内核版本改回去,问题即可解决。
具体办法如下
CUDA 9.1是个大坑
我一早就知道nvidia driver,CUDA和cuDNN有依赖关系。但是我还是低估了这个问题的严重性。 重要事情说三遍:
千万不要装CUDA9.1!
千万不要装CUDA9.1!
千万不要装CUDA9.1!
cuDNN可以支持的CUDA9.1的版本特别的有限,其次tensorflow可以支持CUDA9.1的最高版本是1.13,而tensorflow1.13仅可以运行中python 3.6及以下版本。这个问题,几乎导致我重装了开发环境。
我最终选择安装CUDA9.0,但在重装过程中,我发现如果不卸载之前安装的CUDA9.1版本,cuDNN和tensorflow会误认之前的CUDA版本,所以必须移除。卸载CUDA的命令:
cd /usr/local/cuda-9.1/bin
sudo ./uninstall_cuda_9.1.pl
CUDA依赖包无法安装问题
我的那块Quadro K220显卡匹配的驱动是nvidia-driver-390.46,可以支持的CUDA版本是9.1,但我最终选择的是9.0。官网下载CUDA安装包,依旧选择runfile, 然后进入安装。
然而却安装失败了,报不支持的编译错误, 但提示可以使用 --override 选项跳过这个步骤。
Error: unsupported compiler: 7.3.0. Use --override to override this check.
于是再次尝试…
sudo sh cuda_9.1.85_440.33.01_linux.run --override
于是得到如下错误信息,而且
Installing the CUDA Toolkit in /usr/local/cuda-9.1 …
Missing recommended library: libGLU.so
Missing recommended library: libX11.so
Missing recommended library: libXi.so
Missing recommended library: libXmu.so
Missing recommended library: libGL.so
在网上查了一下,原因是缺少相关的依赖库,安装相应库就解决了:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
可以按照依赖库也失败了,提示依旧是缺少依赖库。在网上查了这个问题许久,也没有找到解决问题的方法,
[Tensorflow] Ubuntu下NVIDIA Driver+CUDA+cuDNN 安装踩坑总结_第11张图片
后来,在网上看到用aptitude install可以解决这个问题。aptitude是和apt-get一样的linux下的包管理工具,但在依赖包处理上比apt-get更好。
先用apt-get来安装一个aptitude。
sudo apt-get install aptitude
再用aptitude来安装依赖包。
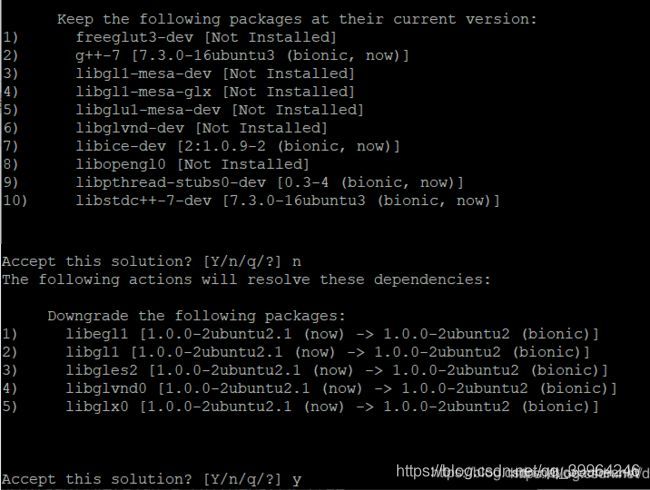
sudo aptitude install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev
这里需要主要的是安装过程中会有提示选择,第一个提示是Keep the following package as their current version, 需要选择n,第二个提示The follow action will resolve the dependencies. , 选择y。
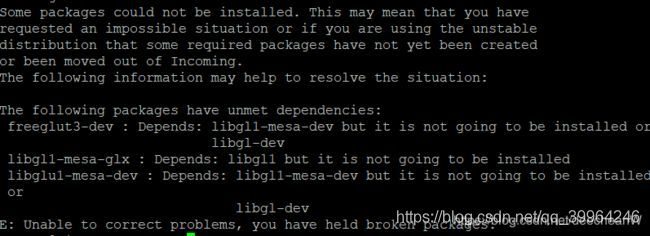
完成安装后,再次安装CUDA,记得加上–override选项,这次就不在报错了。
当我完成所有安装和设置并重启,结果却发现nvidia-smi运行失败了。系统提示
NVIDIA-SMI has failed because it couldn’t communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
在这里插入图片描述
在anaconda里安装CUDA Toolkit和cuDNN
解决 nvcc -V 显示的cuda版本不正确
假设你刚安装了新的CUDA版本,以CUDA-10.1为例,安装完成后用nvcc -V查看,输出的仍然是之前的老版本CUDA。
~$ which nvcc<br>/usr/bin/nvcc
查看系统默认调用的nvcc命令的位置,
~$ cat /usr/bin/nvcc
exec /usr/lib/nvidia-cuda-toolkit/bin/nvcc
这是指向了系统默认的nvidia-cuda-toolkit位置,将其更改为刚安装的cuda:
~$ sudo vi /usr/bin/nvcc
exec /usr/local/cuda/bin/nvcc
保存更改后,nvcc -V命令得到CUDA-10.1版本
安装pytorch
见链接
如何把windows下的字体复制到linux
链接