pytorch之BI-LSTM CRF(六)
1、计算CRF的条件概率
CRF计算条件概率 y 是标签序列, x输入的单词序列
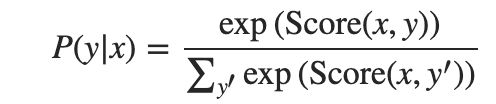
2、分数计算由对数函数确定
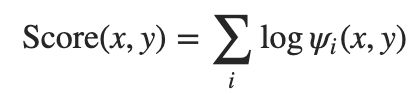
3、Bi-LSTM CRF中分数的确定
在Bi-LSTM CRF中,定义了两种状态: emission 和 transition状态;i位置的emission状态来自Bi-LSTM在时间步的隐藏状态 i。转换分数存储在|T|x|T|矩阵 P,T是标签集;Pj,k是标签k过渡到标签j的分数

4、实例
import torch
import torch.autograd as autograd
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(1)
def argmax(vec):
'''返回最大下标'''
_, idx = torch.max(vec, 1) #dim=1取行的最大值
return idx.item()
def prepare_sequence(seq, to_ix):
'''获取句子的编号'''
idxs = [to_ix[w] for w in seq]
return torch.tensor(idxs, dtype=torch.long)
def log_sum_exp(vec):
'''计算log(sum(exp(vec-max_score)))'''
max_score = vec[0, argmax(vec)]
max_score_broadcast = max_score.view(1, -1).expand(1, vec.size()[1]) #expand扩充tensor的第二维为vec.size()
return max_score + \
torch.log(torch.sum(torch.exp(vec - max_score_broadcast)))
class BiLSTM_CRF(nn.Module):
def __init__(self, vocab_size, tag_to_ix, embedding_dim, hidden_dim):
super(BiLSTM_CRF, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = vocab_size
self.tag_to_ix = tag_to_ix
self.tagset_size = len(tag_to_ix)
self.word_embeds = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, hidden_dim // 2,
num_layers=1, bidirectional=True)
# 从LSTM到标签的概率
self.hidden2tag = nn.Linear(hidden_dim, self.tagset_size)
# 定义从标签i到标签j的转移矩阵
self.transitions = nn.Parameter(
torch.randn(self.tagset_size, self.tagset_size))
#start标签和stop标签都无转移或被转移,设为负无穷
self.transitions.data[tag_to_ix[START_TAG], :] = -10000
self.transitions.data[:, tag_to_ix[STOP_TAG]] = -10000
self.hidden = self.init_hidden()
def init_hidden(self):
'''初始化隐层'''
return (torch.randn(2, 1, self.hidden_dim // 2),
torch.randn(2, 1, self.hidden_dim // 2))
def _forward_alg(self, feats):
#初始化前向传播分数
init_alphas = torch.full((1, self.tagset_size), -10000.)
init_alphas[0][self.tag_to_ix[START_TAG]] = 0.
# Wrap到变量中,以便自动反向传播
forward_var = init_alphas
# 通过句子迭代
for feat in feats:
alphas_t = [] # t时刻的前向张量
for next_tag in range(self.tagset_size):
# 传播emission score;不考虑前一个标签,分数不变
emit_score = feat[next_tag].view(1, -1).expand(1, self.tagset_size)
# 第i个实体的trans_score是从i过渡到next_tag的分数
trans_score = self.transitions[next_tag].view(1, -1)
# 第i个实体的next_tag_var是进行log-sum-exp之前的边的值(i-> next_tag)
next_tag_var = forward_var + trans_score + emit_score
# 此标签的前向变量是所有分数的log-sum-exp。
alphas_t.append(log_sum_exp(next_tag_var).view(1))
forward_var = torch.cat(alphas_t).view(1, -1)
#print('_forward_alg forward_var:',feat,forward_var)
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _get_lstm_features(self, sentence):
#获取lstm的参数
self.hidden = self.init_hidden()
embeds = self.word_embeds(sentence).view(len(sentence), 1, -1)
lstm_out, self.hidden = self.lstm(embeds, self.hidden)
lstm_out = lstm_out.view(len(sentence), self.hidden_dim)
lstm_feats = self.hidden2tag(lstm_out)
return lstm_feats
def _score_sentence(self, feats, tags):
#给出所提供标签序列的分数
score = torch.zeros(1)
tags = torch.cat([torch.tensor([self.tag_to_ix[START_TAG]], dtype=torch.long), tags])
for i, feat in enumerate(feats):
score = score + \
self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[-1]]
return score
def _viterbi_decode(self, feats):
backpointers = []
# 在日志空间中初始化viterbi变量
init_vvars = torch.full((1, self.tagset_size), -10000.)
init_vvars[0][self.tag_to_ix[START_TAG]] = 0
# forward_var在步骤i中保存步骤i-1的viterbi变量
forward_var = init_vvars
for feat in feats:
bptrs_t = [] # 保留此步骤的反向指针
viterbivars_t = [] # 持有此步骤的维特比变量
for next_tag in range(self.tagset_size):
# next_tag_var [i]在上一步中保存标签i的viterbi变量,以及从标签i过渡到next_tag的分数。
# 我们不在此包括排放分数,因为最大值不取决于它们(我们在下面添加它们)
next_tag_var = forward_var + self.transitions[next_tag]
best_tag_id = argmax(next_tag_var)
bptrs_t.append(best_tag_id)
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
#现在添加排放分数,并将forward_var分配给我们刚刚计算的维特比变量集
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
backpointers.append(bptrs_t)
# Transition to STOP_TAG
terminal_var = forward_var + self.transitions[self.tag_to_ix[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# Follow the back pointers to decode the best path.
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag_to_ix[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
def neg_log_likelihood(self, sentence, tags):
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags)
return forward_score - gold_score
def forward(self, sentence): # dont confuse this with _forward_alg above.
# Get the emission scores from the BiLSTM
lstm_feats = self._get_lstm_features(sentence)
print("lstm_feats:",lstm_feats.size())
# Find the best path, given the features.
score, tag_seq = self._viterbi_decode(lstm_feats)
print("score:",score)
print("best_path:",tag_seq)
return score, tag_seq
START_TAG = ""
STOP_TAG = ""
EMBEDDING_DIM = 5
HIDDEN_DIM = 4
# Make up some training data
training_data = [(
"the wall street journal reported today that apple corporation made money".split(),
"B I I I O O O B I O O".split()
), (
"georgia tech is a university in georgia".split(),
"B I O O O O B".split()
)]
word_to_ix = {}
for sentence, tags in training_data:
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
tag_to_ix = {"B": 0, "I": 1, "O": 2, START_TAG: 3, STOP_TAG: 4}
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# Check predictions before training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
precheck_tags = torch.tensor([tag_to_ix[t] for t in training_data[0][1]], dtype=torch.long)
print("before training predict:",model(precheck_sent))
# Make sure prepare_sequence from earlier in the LSTM section is loaded
for epoch in range(
300): # again, normally you would NOT do 300 epochs, it is toy data
for sentence, tags in training_data:
# Step 1. Remember that Pytorch accumulates gradients.
# We need to clear them out before each instance
model.zero_grad()
# Step 2. Get our inputs ready for the network, that is,
# turn them into Tensors of word indices.
sentence_in = prepare_sequence(sentence, word_to_ix)
targets = torch.tensor([tag_to_ix[t] for t in tags], dtype=torch.long)
# Step 3. Run our forward pass.
loss = model.neg_log_likelihood(sentence_in, targets)
# Step 4. Compute the loss, gradients, and update the parameters by
# calling optimizer.step()
loss.backward()
optimizer.step()
# Check predictions after training
with torch.no_grad():
precheck_sent = prepare_sequence(training_data[0][0], word_to_ix)
print("after training predict:",model(precheck_sent))
参考网址:
https://zhuanlan.zhihu.com/p/29989121(原理篇;刘建平老师简单的线性CRF)
https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html#sphx-glr-beginner-nlp-advanced-tutorial-py (pytorch实战篇)