python模块-cProfile和line_profiler(性能分析器)
一、cProfile介绍
- cProfile自python2.5以来就是标准版Python解释器默认的性能分析器。
- 其他版本的python,比如PyPy里没有cProfile的。
- cProfile是一种确定性分析器,只测量CPU时间,并不关心内存消耗和其他与内存相关联的信息。
二、支持的API
(一)run(command, filename=None, sort=-1)
第一种情况:
import cProfile
import re
cProfile.run('re.compile("aaa")')
- 第一行:189个函数调用被监控,其中184个是原生调用(不涉及递归)
- ncalls:函数被调用的次数。如果这一列有两个值,就表示有递归调用,第二个值是原生调用次数,第一个值是总调用次数。
- tottime:函数内部消耗的总时间。(可以帮助优化)
- percall:是tottime除以ncalls,一个函数每次调用平均消耗时间。
- cumtime:之前所有子函数消费时间的累计和。
- filename:lineno(function):被分析函数所在文件名、行号、函数名。
第二种情况:
import cProfile
import re
cProfile.run('re.compile("aaa|bbb")', 'stats', 'cumtime')如果你去运行该代码,你会发现没有结果输出,但是生成了一个stats文件,里面是二进制数据。想读取文件,请见后面内容。
(二)runctx(command, globals, locals, filename=None)
run和runtx之间的区别:globals和locals是两个字典参数。
import cProfile
def runRe():
import re
cProfile.run('re.compile("aaa|bbb")')
runRe()运行结果:

import cProfile
# 这样才对
def runRe():
import re
cProfile.runctx('re.compile("aaa|bbb")', None, locals())
runRe()(三)Profile(custom_timer=None, time_unit=0.0, subcalls=True, builtins=True)
- custom_timer:是一个自定义参数,可以通过与默认函数不同的方式测量时间。
- 如果custom_timer返回的是一个整数,time_unit是单位时间换成秒数。
返回方法
- enable():开始收集性能分析数据。
- disable():停止收集性能分析数据。
- create_stats():停止收集数据,并为已经收集数据创建stats对象。
- print_stats(sort=-1):创建一个stats对象,打印结果。
- dump_stats(filename):把当前性能分析的内容写入一个文件。
- run(command):和之前的一样。
- runctx(command, golabls, locals):和以前一样。
- runcall(func, *args, **kwargs):收集被调用函数func的性能分析信息。
from cProfile import Profile
def runRe():
import re
re.compile("aaa|bbb")
prof = Profile()
prof.enable()
runRe()
prof.create_stats()
prof.print_stats()三、pstats模块和Stats类
(一)介绍
- pstats模块为开发者提供了Stats类,可以读取和操作stats文件。
- Stats类的构造器可以接受cProfile.Profile类型的参数,可以不用文件名称作为数据源。
(二)API
- strip_dirs():删除报告中所有函数文件名的路径信息,这个方法改变stats实例内部的顺序,任何运行该方法的实例都将随机排列项目的顺序。如果两个项目是相同的,那么这两个项目就可以合并。
- add(*filenames):将文件名对应的文件的信息加载到当前的stats对象中。
- dump_stats(filename):这个方法将加载的Stats类的数据保存为一个文件。
- sort_stats(*keys):通过一系列条件依次对所有项目进行排序,从而调整stats对象。
| 准则 | 含义 | 升序/降序排列 |
|---|---|---|
| calls | 调用次数 | 降序 |
| cumulative | 累计时间 | 降序 |
| cumtime | 累计时间 | 降序 |
| file | 文件名 | 升序 |
| filename}文件名 | 升序 | |
| module | 模块名 | 升序 |
| ncalls | 调用总次数 | 降序 |
| pcalls | 原始调用书 | 降序 |
| line | 行号 | 升序 |
| name | 函数名 | 升序 |
| nfl | 函数名/文件名/行号组合 | 降序 |
| stdname | 标准名称 | 升序 |
| time | 函数内部运行时间 | 降序 |
| tottime | 函数内部运行总时间 | 降序 |
- reverse_order():这个方法回逆反原来参数的排序。
- print_stats(*restrictions):这个方法把信息打印到STDOUT
- print_callees(*restrictions):打印一列调用其他函数的函数。
import pstats
p = pstats.Stats('stats')
p.strip_dirs().sort_stats(-1).print_stats()from cProfile import Profile
import pstats
def runRe():
import re
re.compile("aaa|bbb")
prof = Profile()
prof.enable()
runRe()
prof.create_stats()
p = pstats.Stats(prof)
p.print_callees()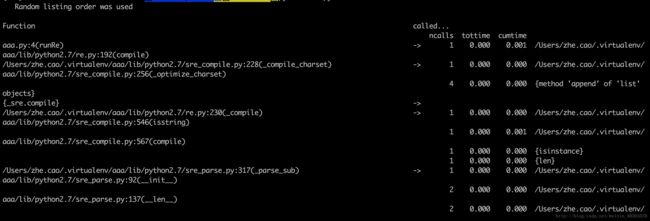
四、line_profiler
(一)简介
- 这个性能分析器和cProfile不同,他能帮你一行一行的分析性能。
- 如果瓶颈问题在某一行中,这样就需要line_profiler解决了。
- 建议使用kernprof工具
(二)安装
pip install line_profiler在安装过程中遇到问题,比如文件缺失,说明没有安装相关依赖,在Ubuntu中
sudo apt-get install python-dev libxml2-dev libxslt-dev(三)kernprof
@profile
def fib(n):
# 文件名aaa.py
a, b = 0, 1
for i in range(0, n):
a, b = b, a+b
return a
fib(5)终端:kernprof -l aaa.pykernprof默认情况下会把分析结果写入aaa.py.lprof文件,不过可以用-v显示在命令行里。
kernprof -l -v aaa.py
- Line:文件中的行号。
- Hits:性能分析时代码执行的次数。
- Time:一段代码执行的总时间,由计数器决定。
- Per Hit:执行一段代码平均消耗时间。
- % Time:执行一段代码时间消耗比例。
(四)实例
line_profiler和cProfile一样:也提供了run,runctx,runcall,enable,disable方法,但是后两个并不安全,可以用dump_stats(filename)方法把stats加载到文件中,也可以用print_stats([stream])昂发打印结果。
# coding=utf-8
import line_profiler
import sys
def bbb():
for i in range(0, 3):
print i**2
print 'end'
profile = line_profiler.LineProfiler(bbb) # 把函数传递到性能分析器
profile.enable() # 开始分析
bbb()
profile.disable() # 停止分析
profile.print_stats(sys.stdout) # 打印出性能分析结果