Pytorch多机多卡分布式训练
被这东西刁难两天了,终于想办法解决掉了,来造福下人民群众。
关于Pytorch分布训练的话,大家一开始接触的往往是DataParallel,这个wrapper能够很方便的使用多张卡,而且将进程控制在一个。唯一的问题就在于,DataParallel只能满足一台机器上gpu的通信,而一台机器一般只能装8张卡,对于一些大任务,8张卡就很吃力了,这个时候我们就需要面对多机多卡分布式训练这个问题了,噩梦开始了。
官方pytorch(v1.0.10)在分布式上给出的api有这么几个比较重要的:
1. torch.nn.parallel.DistributedDataParallel :
这个从名字上就能看出来与DataParallel相类似,也是一个模型wrapper。这个包是实现多机多卡分布训练最核心东西,它可以帮助我们在不同机器的多个模型拷贝之间平均梯度。
2. torch.utils.data.distributed.DistributedSampler:
在多机多卡情况下分布式训练数据的读取也是一个问题,不同的卡读取到的数据应该是不同的。dataparallel的做法是直接将batch切分到不同的卡,这种方法对于多机来说不可取,因为多机之间直接进行数据传输会严重影响效率。于是有了利用sampler确保dataloader只会load到整个数据集的一个特定子集的做法。DistributedSampler就是做这件事的。它为每一个子进程划分出一部分数据集,以避免不同进程之间数据重复。
# 分布式训练示例
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
dataset = your_dataset()
datasampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size=batch_size_per_gpu, sampler=datasampler)
model = your_model()
model = DistributedDataPrallel(model, device_ids=[local_rank], output_device=local_rank)
其他部分就和正常训练代码无异了。
得提的几个点:
1、和dataparallel不同,dataparallel需要将batchsize设置成n倍的单卡batchsize,而distributedsampler使用的情况下,batchsize设置与单卡设置相同。
2、这里有几个新的参数:world size, rank, local rank, rank。world size指进程总数,在这里就是我们使用的卡数;rank指进程序号,local_rank指本地序号,两者的区别在于前者用于进程间通讯,后者用于本地设备分配。这个时候真正麻烦的地方来了:
想要使用DistributedDataParallel,得先完成多进程的初始化,就是这个:
torch.distributed.init_process_group()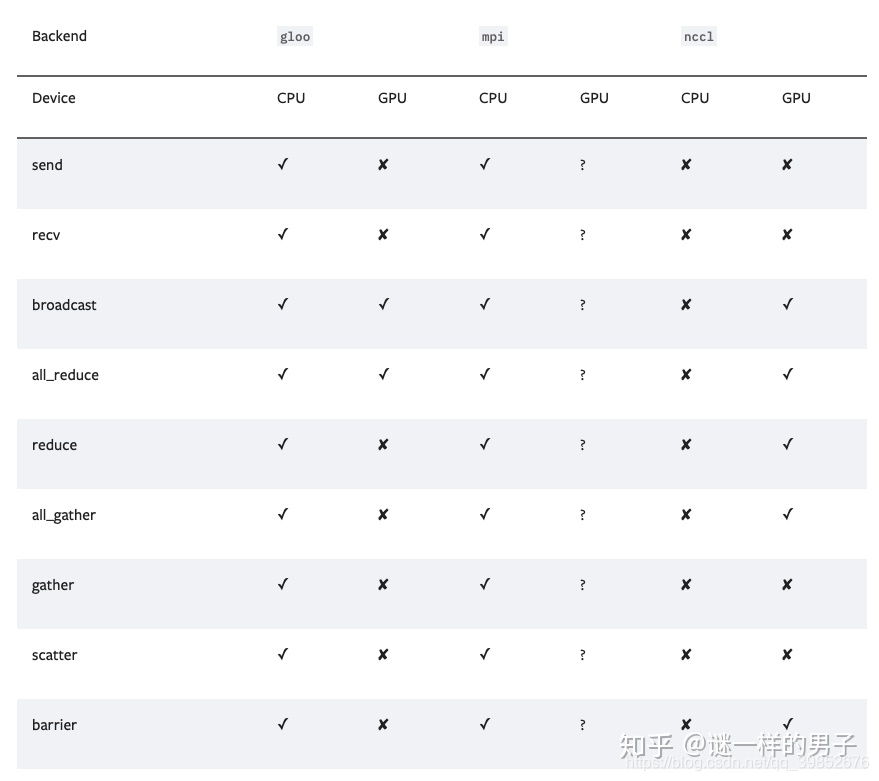
看官方的说明:
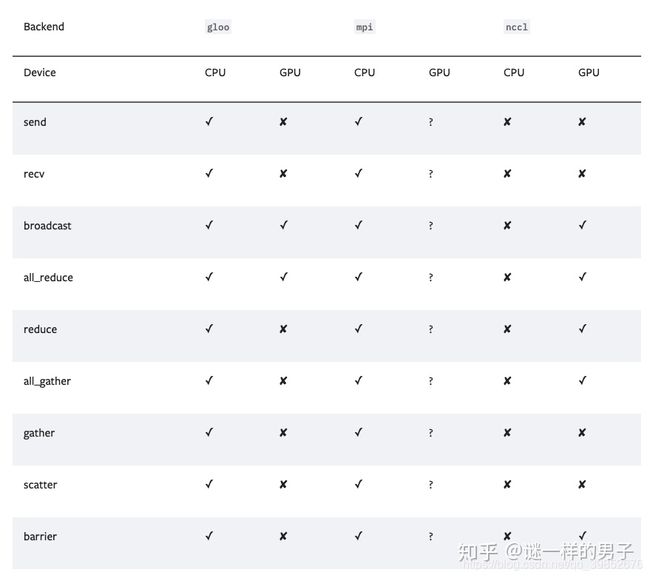
gloo基本只支持cpu,不考虑。mpi需要在本地重新编译pytorch,感兴趣的朋友可以试试。nccl对gpu支持良好还不需要重新编译,在下和官方都强烈推荐这个作为backend。
pytorch作者推荐的初始化方式:
我最后的实现也是利用这种方式。但我面临的问题是:如何在我们的slurm集群上完成这个初始化并进行训练,那么问题就变成了如何在slurm集群上把你分配到的ip写进程序里。两个办法:
- 1.srun指定-n 进程总数以及 --ntasks-per-node 每个节点进程数,这样就可以通过os.environ获得每个进程的节点ip信息,全局rank以及local
rank,有了这些就可以很方便很方便的完成初始化。推荐使用该方法(感谢评论区大佬指点) - 2.salloc,这个就相对霸道一些,直接指定几个节点自己拿来用,这样就很容易选出来通信用的节点,再随便给个端口,我们就能完成初始化。相比1还是麻烦不少。
关于获取节点信息的详细代码:
import os
os.environ['SLURM_NTASKS'] #可用作world size
os.environ['SLURM_NODEID'] #node id
os.environ['SLURM_PROCID'] #可用作全局rank
os.environ['SLURM_LOCALID'] #local_rank
os.environ['SLURM_STEP_NODELIST'] #从中取得一个ip作为通讯ip
贴段差不多能跑的代码吧:
import torch
torch.multiprocessing.set_start_method('spawn')
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel
import os
def dist_init(host_addr, rank, local_rank, world_size, port=23456):
host_addr_full = 'tcp://' + host_addr + ':' + str(port)
torch.distributed.init_process_group("nccl", init_method=host_addr_full,
rank=rank, world_size=world_size)
num_gpus = torch.cuda.device_count()
torch.cuda.set_device(local_rank)
assert torch.distributed.is_initialized()
rank = int(os.environ['SLURM_PROCID'])
local_rank = int(os.environ['SLURM_LOCALID'])
world_size = int(os.environ['SLURM_NTASKS'])
# get_ip函数自己写一下 不同服务器这个字符串形式不一样
# 保证所有task拿到的是同一个ip就成
ip = get_ip(os.environ['SLURM_STEP_NODELIST'])
dist_init(ip, rank, local_rank, world_size)
# 接下来是写dataset和dataloader,这个网上有很多教程
# 我这给的也只是个形式,按自己需求写好就ok
dataset = your_dataset() #主要是把这写好
datasampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size=batch_size_per_gpu, sampler=source_sampler)
model = your_model() #也是按自己的模型写
model = DistributedDataPrallel(model, device_ids=[local_rank], output_device=local_rank)
# 此后训练流程与普通模型无异
照上面写好train.py之后(叫啥都行,这儿就叫train.py吧),slrum指令写这样:
# 这里是3台机器,每台机器8张卡的样子
srun -n24 --gres=gpu:8 --ntasks-per-node=8 python train.py
以下是关于方法2的补充,1已经足够用了,保留这部分只是为了文章完整。
然而,事情并没有这么简单。
如果一次salloc多个节点,那么接下来的srun指令默认是每个节点执行一个拷贝,也就是说,我们的rank是无法保证两个节点上是不一样的。怎么办?
需要多少个节点,就开多少个窗口,每个窗口salloc一个节点,就能解决上面的问题。
最后,如何方便的得到多个rank不一样的进程,其实pytorch已经有模块可以很好的解决这个问题:
链接
采用torch.distributed.launch模块可以很容易为每个进程得到不一样的localrank,再在不同的节点指定不同的rank初始值,slurm群组上就可以开心的pytorch多机分布式训练啦。
链接