python爬虫入门
目录
- 一、相关原理
-
- 1.什么是爬虫
- 2.网络爬虫的分类
- 3.网络爬虫的使用范围
- 4.爬虫的基本架构
- 二、代码实现
-
- 1.环境配置
- 2.对南阳理工学院ACM题目网站练习题目数据的抓取和保存
-
- 2.1 分析网址
- 2.2 代码编写
- 3.爬取重庆交通大学新闻网站中近几年所有的信息通知的发布日期和标题全部
-
- 3.1 分析网页
- 3.2 代码编写
- 三、总结
- 参考资料
一、相关原理
1.什么是爬虫
- 网络爬虫英文名为Web Crawler或Web Spider。
- 它是一种自动浏览网页并采集所需要信息的程序。
- 爬虫从初始网页癿URL开始, 获取初始网页上癿URL; 在抓取网页癿过程中, 不断从当前页面上抽取新癿URL放入队列; 直到满足系统给定的停止条件。
- 它可以为搜索引擎从互联网中下载网页数据,是搜索引擎的重要组成部分。
互联网示意图:
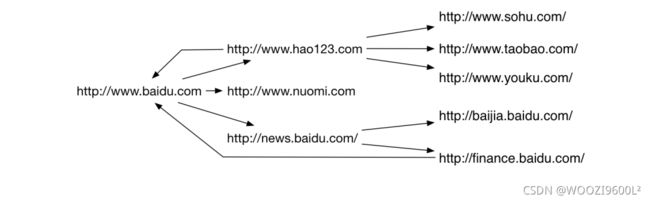
- 每个节点都是一个网页
- 每条边都是一个超链接
- 网络爬虫就是从这样一个网络图中抓取感兴趣的内容
网页的抓取策略:
通常来说,网页的抓取策略可以分为以下三类:
• 广度优先
• 最佳优先
• 深度优先
深度优先在很多情况下会寻致爬虫的陷入(trapped)问题,目前常见的是广度优先和最佳优先方法。
- 广度优先搜索策略是指在抓取过程中,在完成当前层次得搜索后,才进行下一层次的搜索。特点是,算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。也有很多研究将广度优先搜索策略应用于聚焦爬虫中。其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。
- 最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。它叧访问经过网页分析算法预测为“有用”的网页。特点是,最佳优先策略是一种局部最优搜索算法,在爬虫抓取路径上的很多相关网页可能被忽略。
- 深度优先搜索策略从起始网页开始,选择一个URL进入,分析这个网页中的URL,选择一个再进入。如此一个链接一个链接地抓取下去,直到处理完一条路线之后再处理下一条路线。 特点是,深度优先策略算法设计较为简单,但每深入一层,网页价值和PageRank都会相应地有所下降,相对与其他两种策略而言,此种策略很少被使用。
2.网络爬虫的分类
通常来说,网络爬虫可以分为以下几类:
• 通用网络爬虫
• 增量爬虫
• 垂直爬虫
• Deep Web 爬虫
- 通用网络爬虫又称全网爬虫( Scalable Web Crawler)爬行对象从一些种子URL扩充到整个Web,主要为门站点搜索引擎和大型Web服务提供商采集数据。通用网络爬虫根据预先设定的一个或若干初始种子URL开始,以此获得初始网页上的URL列表,在爬行过程中不断从URL队列中获一个的URL,进而访问并下载该页面。
- 增量网络爬虫( Incremental Web Crawler)是指对已下载网页采取增量式更新和只爬行新产生的或者已经发生变化网页的爬虫,它能够在定程度上保证所爬行的页面是尽可能新的页面。增量式爬虫有两个目标:保持本地页面集中存储的页面为最新页面和提高本地页面集中页面的质量。通用的商业搜索引擎如谷歌,百度等,本质上都属于增量爬虫。
- 垂直爬虫,又称为聚焦网络爬虫( Focused Crawler),或主题网络爬虫( Topical Crawler)。是指选择性地爬取那些与预先定义好的主题相关页面的网络爬虫。如Email地址,电子书,商品价格等。爬行策略实现的关键是评价页面内容和链接的重要性,不同的方法计算出的重要性不同,由此导致链接的访问顺序也不同。
- Deep Web爬虫 是那些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户提交一些关键词才能获得的 Web 页面。Deep Web 爬虫爬行过程中最重要部分就是表单填写,包含两种类型:基于领域知识的表单填写,基亍网页结构分析的表单填写。
3.网络爬虫的使用范围
- 作为搜索引擎的网页搜集器,抓取整个互联网,如谷歌,百度等;
- 作为垂直搜索引擎,抓取特定主题信息,如视频网站,招聘网站等。
- 作为测试网站前端的检测工具,用来评价网站前端代码的健壮性。
- 作为数据分析流程中的关键一步-数据采集。
- 对数据分析师来说,网络爬虫是进行数据采集的重要技术工具。
Robots协议
又称机器人协议或爬虫协议, 该协议就搜索引擎抓取网站内容的范围作了约定,包括网站是否希望被搜索引擎抓取,哪些内容不允许被抓取,网络爬虫据此“自觉地”抓取或者不抓取该网页内容。自推出以来 Robots协议已成为网站保护自有敏感数据和网民隐私的国际惯例。
- robots协议通过robots.txt实现
- robots.txt文件应该放置在网站根目录下。
- 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
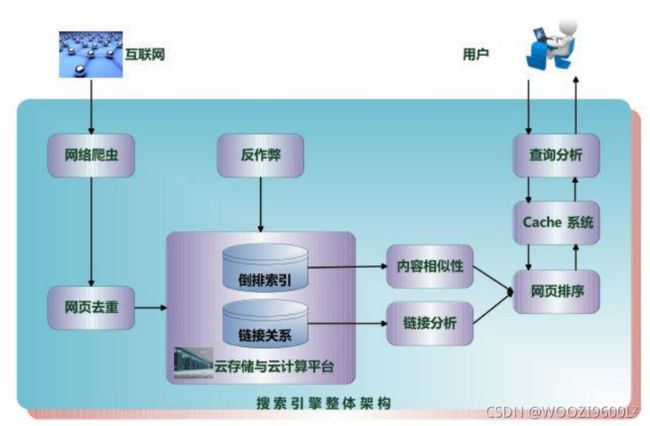
4.爬虫的基本架构
网络爬虫通常包含四个模块:
• URL管理模块
• 下载模块
• 解析模块
• 存储模块
爬虫框架:

二、代码实现
1.环境配置
打开Anaconda Prompt,创建虚拟环境
conda create -n crawler python=3.7
crawler为虚拟环境名称,python=3.7为python版本。
激活环境:
activate crawler
使用pip或conda命令下载将会用到的包:
pip install requests
pip install beautifulsoup4
pip install tqdm
pip install csv
2.对南阳理工学院ACM题目网站练习题目数据的抓取和保存
2.1 分析网址
目标地址: http://www.51mxd.cn/
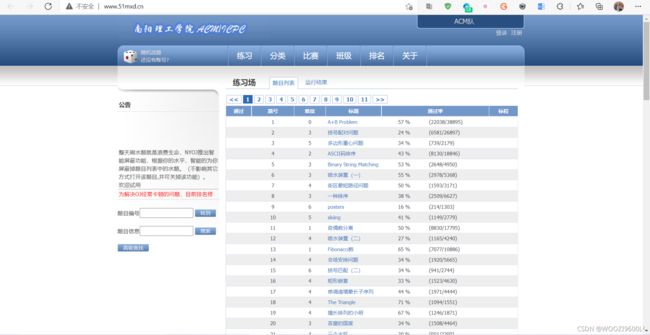
查看源代码:

找到目标爬取内容:
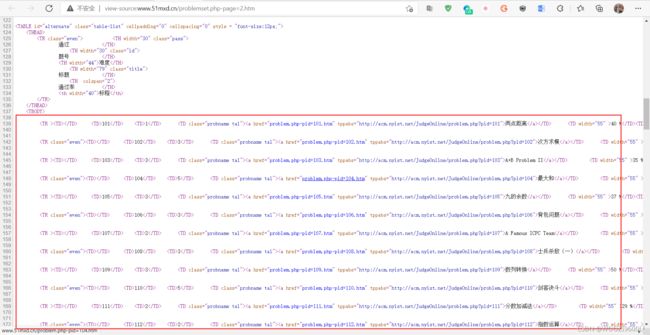
在其中Ctrl + F 搜索该页的某一个题目(此处以最大和为例):
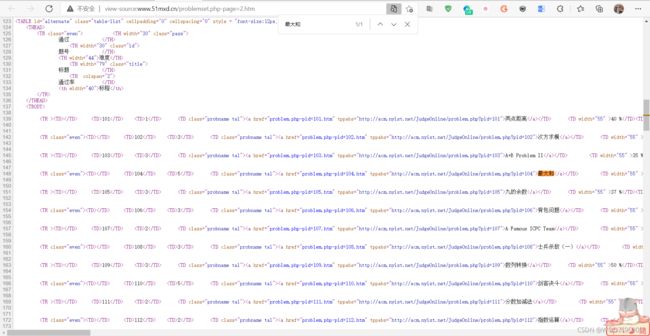
能够搜索到,说明此数据不是动态加载,可直接get该页面以获取。
按F12 打开开发者工具(或者右键选择检查),在元素(有的浏览器是Element)中点击箭头工具(如下图②所示),点击一个题目,可在元素中显示:

可发现,每一行信息都在一个标签中,每个小信息都在一个标签的字符串里面,在Element中Ctrl + F 搜索
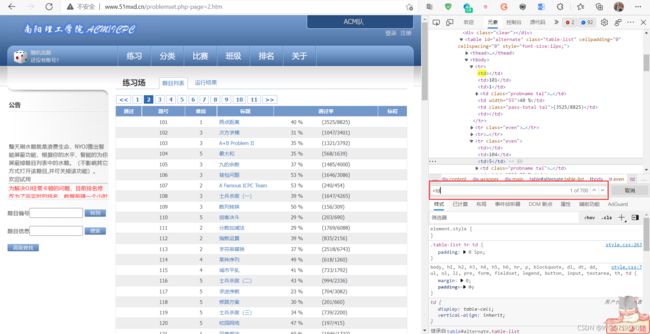
分析完成后,开始编写代码。
2.2 代码编写
# 导入相关包
import requests #基于urllib,采用Apache2Licensed开源协议的HTTP库
from bs4 import BeautifulSoup # 可以从HTML或XML文件中提取数据的python库
import csv # 保存为csv文件所需的包
from tqdm import tqdm # 显示下载进度的包
# 模拟浏览器访问
Headers = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'
# 表头,根据网页数据来定
csvHeaders = ['题号', '难度', '标题', '通过率', '通过数/总提交数']
# 题目数据
subjects = []
# 爬取题目
print('题目信息爬取中:\n')
#进度显示,爬取该网站的所有题目信息11页
for pages in tqdm(range(1, 11 + 1)):
r = requests.get(f'http://www.51mxd.cn/problemset.php-page={pages}.htm', Headers) # get请求第pages页
r.raise_for_status() # 判断异常
r.encoding = 'utf-8' # 编码格式
soup = BeautifulSoup(r.text, 'html.parser') # 创建BeautifulSoup对象,用于解析该html页面数据
td = soup.find_all('td') # 获取所有td标签
subject = [] # 存放某一个题目的所有信息
# 遍历所有td
for t in td:
if t.string is not None:
subject.append(t.string) # 获取td中的字符串
if len(subject) == 5: # 每5个为一个题目的信息
subjects.append(subject)
subject = []
# 存放题目
with open('NYOJ_Subjects.csv', 'w', newline='') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(csvHeaders) #写入表头
fileWriter.writerows(subjects) #写入数据
print('\n题目信息爬取完成!!!')
运行中:
运行完毕:
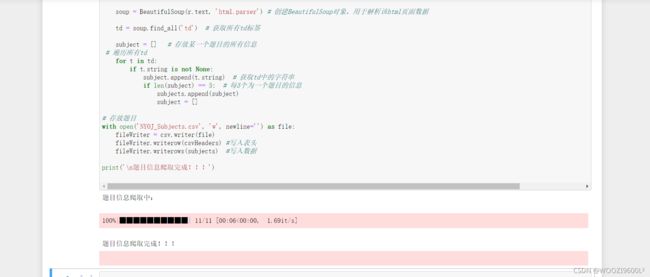
查看生成的csv文件:

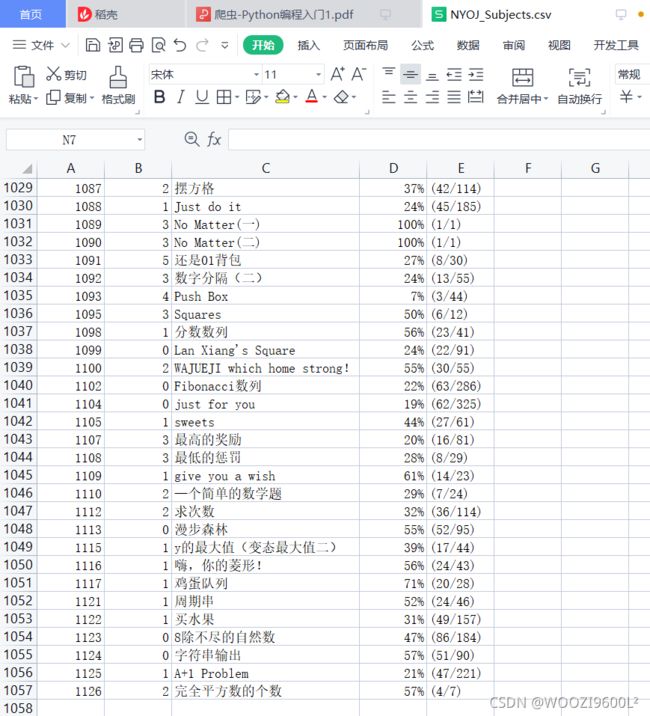
一共1126条数据,与原网页数量相同。
3.爬取重庆交通大学新闻网站中近几年所有的信息通知的发布日期和标题全部
3.1 分析网页
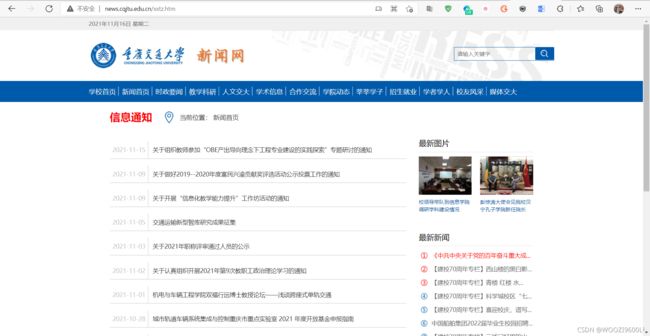
目标地址: http://news.cqjtu.edu.cn/xxtz.htm
第一页url为http://news.cqjtu.edu.cn/xxtz.htm,第二页为http://news.cqjtu.edu.cn/xxtz/65.htm,第三页为http://news.cqjtu.edu.cn/xxtz/64.htm…第66页为http://news.cqjtu.edu.cn/xxtz/1.htm
一共66页,由此可表示如下:
base_url = "http://news.cqjtu.edu.cn/xxtz/"
for i in range(1, 67):
if(i == 1):
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url ='http://news.cqjtu.edu.cn/xxtz/' + str(67 - i) + '.htm'
查看源代码,找到目标爬取内容:
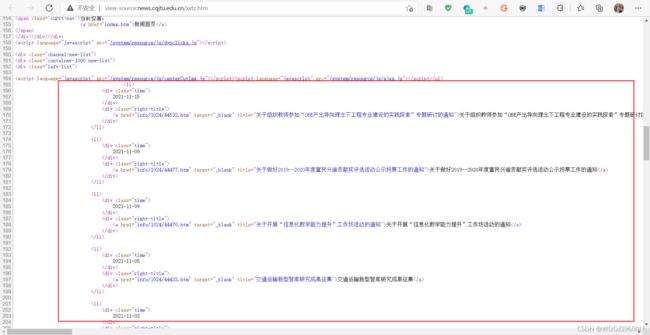
在其中Ctrl + F 搜索该页的某一个题目(此处以交通运输新型智库研究成果征集为例):
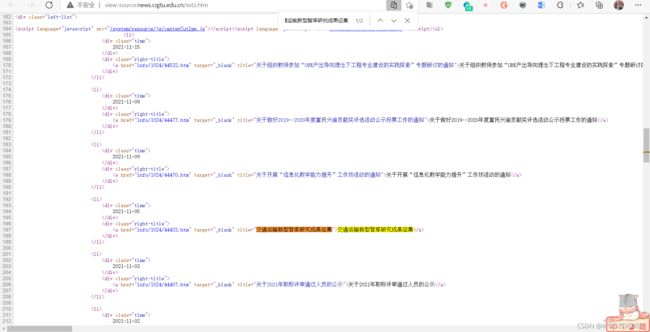
能够搜索到,说明此数据不是动态加载,可直接get该页面以获取。
F12 打开开发者工具(或者右键选择检查),在元素(有的浏览器是Element)中点击箭头工具(如下图②所示),点击一个题目,可在元素中显示:
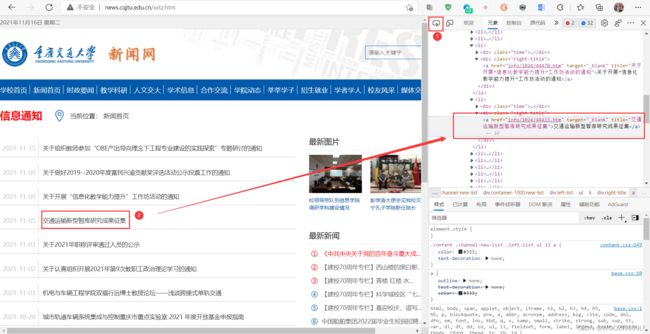
可发现,每一行信息都在一个
- 下,搜索得只有一个class="left-list"的元素,该元素下只有一个
- 。
分析完成后,开始编写代码。
3.2 代码编写
# 导入相关包
import requests #基于urllib,采用Apache2Licensed开源协议的HTTP库
from bs4 import BeautifulSoup # 可以从HTML或XML文件中提取数据的python库
import csv # 保存为csv文件所需的包
from tqdm import tqdm # 显示下载进度的包
# 获取每页内容
def get_one_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
try:
info_list_page = [] # 一页的所有信息
resp = requests.get(url, headers=headers)
resp.encoding = resp.status_code
page_text = resp.text
soup = BeautifulSoup(page_text, 'html.parser')
li_list = soup.select('.left-list > ul > li') # 找到所有li标签
for li in li_list:
divs = li.select('div')
date = divs[0].string.strip()
title = divs[1].a.string
info = [date, title]
info_list_page.append(info)
except Exception as e:
print('爬取' + url + '错误')
print(e)
return None
else:
resp.close()
return info_list_page
# 爬取所有数据
print('信息爬取中:\n')
info_list_all = []
base_url = 'http://news.cqjtu.edu.cn/xxtz/'
for i in tqdm(range(1, 66+1)):
if i == 1:
url = 'http://news.cqjtu.edu.cn/xxtz.htm'
else:
url = base_url + str(67 - i) + '.htm'
info_list_page = get_one_page(url)
info_list_all+= info_list_page
# 存入数据
with open('CQJTU_news.csv', 'w', newline='', encoding='utf-8') as file:
fileWriter = csv.writer(file)
fileWriter.writerow(['日期', '标题']) # 写入表头
fileWriter.writerows(info_list_all) # 写入数据
print('\n信息爬取完成!!!')
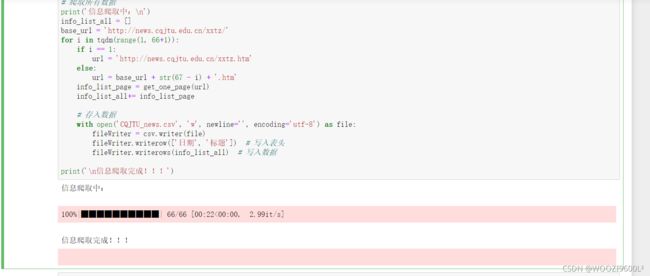

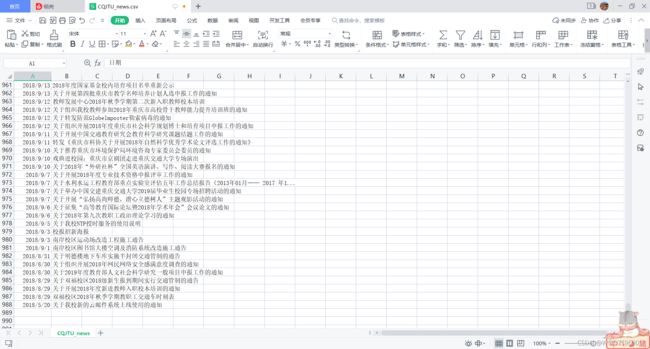
截止到运行代码的时间,共有987条新闻。
三、总结
爬取静态网页信息时,要查看网页源代码,分析要获取信息在什么标签,然后从标签中取出信息。因为信息较多,1页是显示不完的,就会有不同的url,所以要通过循环获取所有相关url不断获取信息才能得到所有的数据。通过爬虫能更快的获取我们想要得到的信息。
参考资料
爬虫-python入门1.pdf
Python爬虫练习(爬取OJ题目和学校信息通知)