作者:Rance D. Necaise
出版社:John Wiley & Sons
发行时间:December 21st 2010
来源:下载的 pdf 版本
Goodreads:3.94 (16 Ratings)
豆瓣:7.0(44人评价)

Programming languages commonly provide data types as part of the language itself. These data types, known as primitives, come in two categories: simple and complex. The simple data types consist of values that are in the most basic form and cannot be decomposed into smaller parts. Integer and real types, for example, consist of single numeric values. The complex data types, on the other hand, are constructed of multiple components consisting of simple types or other complex types. In Python, objects, strings, lists, and dictionaries, which can contain multiple values, are all examples of complex types. The primitive types provided by a language may not be sufficient for solving large complex problems. Thus, most languages allow for the construction of additional data types, known as user-defined types since they are defined by the programmer and not the language. Some of these data types can themselves be very complex.
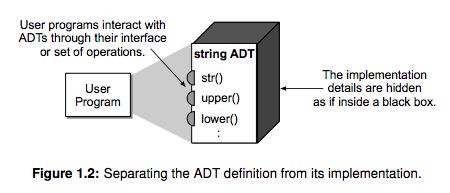
An abstract data type (or ADT) is a programmer-defined data type that specifies a set of data values and a collection of well-defined operations that can be performed on those values. Abstract data types are defined independent of their implementation, allowing us to focus on the use of the new data type instead of how it’s implemented. This separation is typically enforced by requiring interaction with the abstract data type through an interface or defined set of operations. This is known as information hiding. By hiding the implementation details and requiring ADTs to be accessed through an interface, we can work with an abstraction and focus on what functionality the ADT provides instead of how that functionality is implemented.
Abstract data types can be viewed like black boxes as illustrated in Figure 1.2. User programs interact with instances of the ADT by invoking one of the several operations defined by its interface. The set of operations can be grouped into four categories: �
- Constructors: Create and initialize new instances of the ADT. �
- Accessors: Return data contained in an instance without modifying it. �
- Mutators: Modify the contents of an ADT instance. �
- Iterators: Process individual data components sequentially.
There are many different terms used in computer science. Some of these can have different meanings among the various textbooks and programming languages. To aide the reader and to avoid confusion, we define some of the common terms we will be using throughout the text.
A collection is a group of values with no implied organization or relationship between the individual values. Sometimes we may restrict the elements to a specific data type such as a collection of integers or floating-point values.
A container is any data structure or abstract data type that stores and organizes a collection. The individual values of the collection are known as elements of the container and a container with no elements is said to be empty. The organization or arrangement of the elements can vary from one container to the next as can the operations available for accessing the elements. Python provides a number of built-in containers, which include strings, tuples, lists, dictionaries, and sets.
A sequence is a container in which the elements are arranged in linear order from front to back, with each element accessible by position. Throughout the text, we assume that access to the individual elements based on their position within the linear order is provided using the subscript operator. Python provides two immutable sequences, strings and tuples, and one mutable sequence, the list. In the next chapter, we introduce the array structure, which is also a commonly used mutable sequence.
A sorted sequence is one in which the position of the elements is based on a prescribed relationship between each element and its successor. For example, we can create a sorted sequence of integers in which the elements are arranged in ascending or increasing order from smallest to largest value.


Game of Life:
https://bitstorm.org/gameoflife/
Instead of counting the precise number of operations or steps, computer scientists are more interested in classifying an algorithm based on the order of magnitude as applied to execution time or space requirements. This classification approximates the actual number of required steps for execution or the actual storage requirements in terms of variable-sized data sets. The term big-O, which is derived from the expression “on the order of,” is used to specify an algorithm’s classification.
function f(n) indicates the rate of growth at which the run time of an algorithm increases as the input size, n, increases. To specify the time-complexity of an algorithm, which runs on the order of f(n), we use the notation
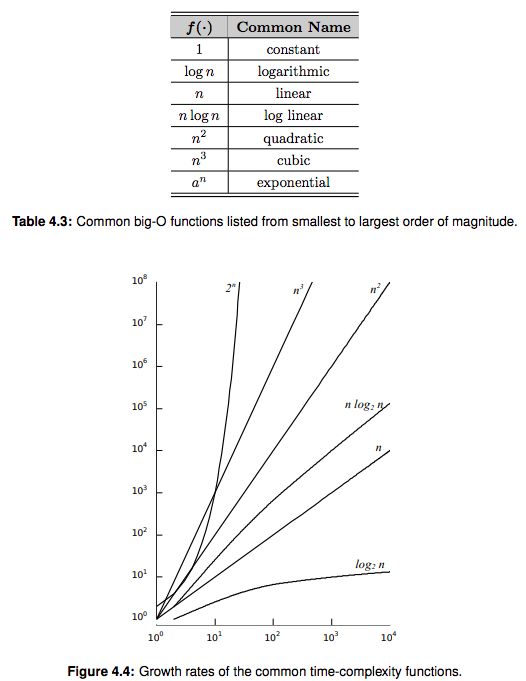
We will work with many different algorithms in this text, but most will have a time-complexity selected from among a common set of functions, which are listed in Table 4.3 and illustrated graphically in Figure 4.4.
Algorithms can be classified based on their big-O function. The various classes are commonly named based upon the dominant term. A logarithmic algorithm is

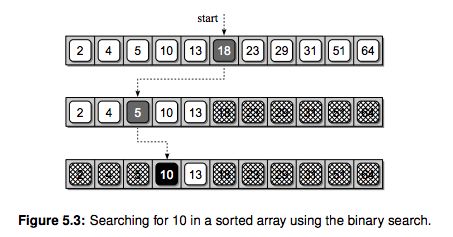
The binary search algorithm works in a similar fashion to the process described above and can be applied to a sorted sequence. The algorithm starts by examining the middle item of the sorted sequence, resulting in one of three possible conditions: the middle item is the target value, the target value is less than the middle item, or the target is larger than the middle item. Since the sequence is ordered, we can eliminate half the values in the list when the target value is not found at the middle position.
Consider the task of searching for value 10 in the sorted array from Figure 5.2. We first determine which element contains the middle entry. As illustrated in Figure 5.3, the middle entry contains 18, which is greater than our target of 10. Thus, we can discard the upper half of the array from consideration since 10 cannot possibly be in that part. Having eliminated the upper half, we repeat the process on the lower half of the array. We then find the middle item of the lower half and compare its value to the target. Since that entry, which contains 5, is less than the target, we can eliminate the lower fourth of the array. The process is repeated on the remaining items. Upon finding value 10 in the middle entry from among those remaining, the process terminates successfully. If we had not found the target, the process would continue until either the target value was found or we had eliminated all values from consideration

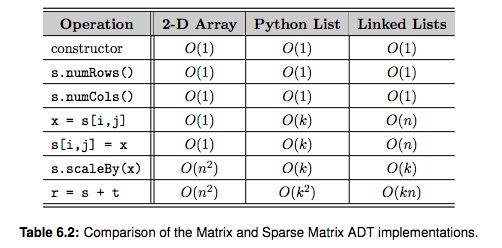
The Sparse Matrix ADT implemented as an array of linked lists can be evaluated for any of the three cases: best, average, and worst. The analysis, which is left as an exercise, depends on the relationship between the total number of non-zero elements, k, and the number of columns, n, in the matrix.
Infix expressions can be easily converted by hand to postfix notation. The expression A + B - C would be written as AB+C- in postfix form. The evaluation of this expression would involve first adding A and B and then subtracting C from that result. We will examine the evaluation of postfix expressions later; for now we focus on the conversion from infix to postfix.


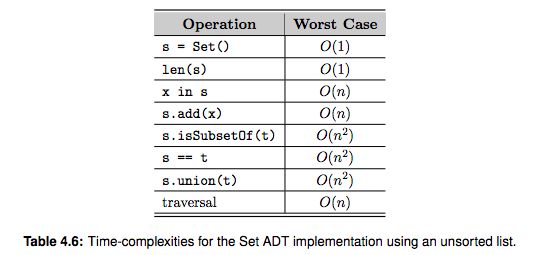
When a collision occurs, we have to probe the hash table to find another available slot. In the previous section, we reviewed several probing techniques that can be used to help reduce the number of collisions. But we can eliminate collisions entirely if we allow multiple keys to share the same table entry. To accommodate multiple keys, linked lists can be used to store the individual keys that map to the same entry. The linked lists are commonly referred to as chains and this technique of collision resolution is known as separate chaining.


This does not mean, however, that the sorting operation cannot be done faster than O(n log n). It simply means that we cannot achieve this with a comparison sort. In the next section, we examine a distribution sort algorithm that works in linear time. Distribution sort algorithms use techniques other than comparisons among the keys themselves to sort the sequence of keys. While these distribution algorithms are fast, they are not general purpose sorting algorithms. In other words, they cannot be applied to just any sequence of keys. Typically, these algorithms are used when the keys have certain characteristics and for specific types of applications.
Radix sort is a fast distribution sorting algorithm that orders keys by examining the individual components of the keys instead of comparing the keys themselves. For example, when sorting integer keys, the individual digits of the keys are compared from least significant to most significant. This is a special purpose sorting algorithm but can be used to sort many types of keys, including positive integers, strings, and floating-point values.
The radix sort algorithm also known as bin sort can be traced back to the time of punch cards and card readers. Card readers contained a number of bins in which punch cards could be placed after being read by the card reader. To sort values punched on cards the cards were first separated into 10 different bins based on the value in the ones column of each value. The cards would then be collected such that the cards in the bin representing zero would be placed on top, followed by the cards in the bin for one, and so on through nine. The cards were then sorted again, but this time by the tens column. The process continued until the cards were sorted by each digit in the largest value. The final result was a stack of punch cards with values sorted from smallest to largest.

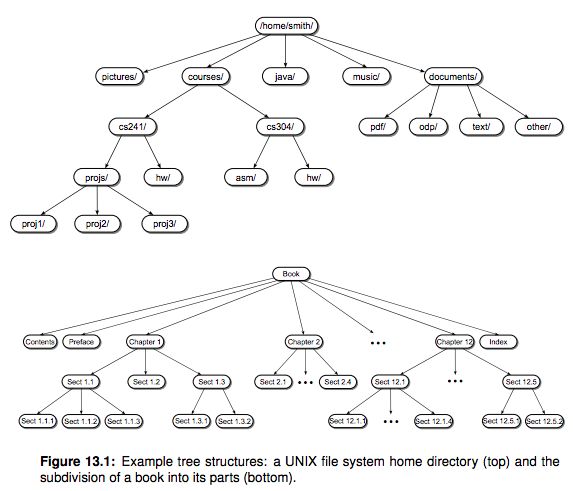
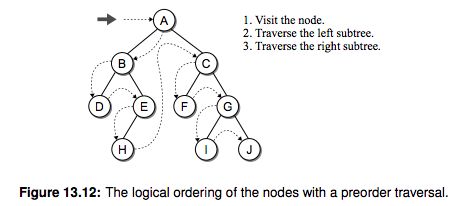
A tree structure consists of nodes and edges that organize data in a hierarchical fashion. The relationships between data elements in a tree are similar to those of a family tree: “child,” “parent,” “ancestor,” etc. The data elements are stored in nodes and pairs of nodes are connected by edges. The edges represent the relationship between the nodes that are linked with arrows or directed edges to form a hierarchical structure resembling an upside-down tree complete with branches, leaves, and even a root.
Formally, we can define a tree as a set of nodes that either is empty or has a node called the root that is connected by edges to zero or more subtrees to form a hierarchical structure. Each subtree is itself by definition a tree.
A classic example of a tree structure is the representation of directories and subdirectories in a file system. The top tree in Figure 13.1 illustrates the hierarchical nature of a student’s home directory in the UNIX file system. Trees can be used to represent structured data, which results in the subdivision of data into smaller and smaller parts. A simple example of this use is the division of a book into its various parts of chapters, sections, and subsections, as illustrated by the bottom tree in Figure 13.1. Trees are also used for making decisions. One that you are most likely familiar with is the phone, or menu, tree. When you call customer service for most businesses today, you are greeted with an automated menu that you have to traverse. The various menus are nodes in a tree and the menu options from which you can choose are branches to other nodes.
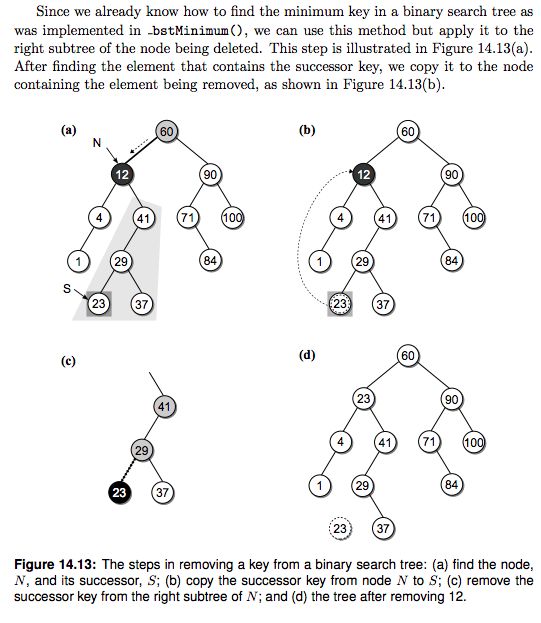
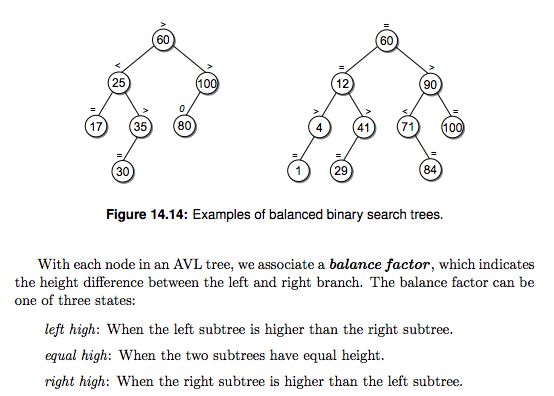
The AVL tree, which was invented by G. M. Adel’son-Velskii and Y. M. Landis in 1962, improves on the binary search tree by always guaranteeing the tree is height balanced, which allows for more efficient operations. A binary tree is balanced if the heights of the left and right subtrees of every node differ by at most 1. Figure 14.14 illustrates two examples of AVL trees.