R语言初级练习题-上
生信技能树线下培训课,R语言初级练习题作答记录
> getwd() #查看工作目录,
[1] "C:/Users/ads/Documents"#返回的是字符串
1.PNG
根据返回结果打开电脑目录,可以看到,与RStudio右下区块(右图),是一致的
> setwd("C:/Users/ads/Documents/homework/")
Error in setwd("C:/Users/ads/Documents/homework/") :
cannot change working directory
#报错是因为没有在电脑里新建这个文件夹
> setwd("C:/Users/ads/Documents/homework/")#设置工作目录
> a <- c(1,2,3)#赋值
> a
[1] 1 2 3
> typeof(a)#判断数据类型
[1] "double"#数值型
> a <- 1:10
> a
[1] 1 2 3 4 5 6 7 8 9 10
> typeof(a)
[1] "integer"#数值型
> a <- "good"
> a
[1] "good"
> typeof(a)
[1] "character"#字符型
> a <- TRUE
> typeof(a)
[1] "logical"#逻辑型
> a <- 1:10
> dim(a) <- c(2,5)#加维度,
> a
[,1] [,2] [,3] [,4] [,5]
[1,] 1 3 5 7 9
[2,] 2 4 6 8 10
> is.array(a)#"is"族判断函数,是否是数组
[1] TRUE
> is.data.frame(a)
[1] FALSE
> b <- as.data.frame(a)#"as"族转换函数,转换成数据框
> b
V1 V2 V3 V4 V5
1 1 3 5 7 9
2 2 4 6 8 10
> is.data.frame(b)
[1] TRUE
> b[c(1,3),]#[]作用取子集,逗号左边是行,右列
V1 V2 V3 V4 V5
1 1 3 5 7 9
NA NA NA NA NA NA#因为没有第三行
> b[,c(4,6)]
Error in `[.data.frame`(b, , c(4, 6)) : undefined columns selected#b里没有第6列,我以为会出现NA,结果报错了,下一条验证了下
> b[,c(4,5)]
V4 V5
1 7 9
2 8 10
> b$V1#用$符号会给出所有的列名选项,可以选择取列
[1] 1 2
> df1 <- data.frame(paste0("gene",1:3),paste0("sample",1:3),paste0("exp",c(20,22,29)))#建一个数据框,paste0的作用看下面结果
> df1#(⊙o⊙)…列名是啥玩意儿,data.frame的用法
paste0..gene...1.3. paste0..sample...1.3. paste0..exp...c.20..22..29..
1 gene1 sample1 exp20
2 gene2 sample2 exp22
3 gene3 sample3 exp29
> df1 <- data.frame(gene <- paste0("gene",1:3),sampel <- paste0("sample",1:3),exp <- c(20,22,29))
> df1#(⊙o⊙)…把赋值符号 <- 和等号 = 弄混了
gene....paste0..gene...1.3. sampel....paste0..sample...1.3. exp....c.20..22..29.
1 gene1 sample1 20
2 gene2 sample2 22
3 gene3 sample3 29
> df1 <- data.frame(gene=paste0("gene",1:3),sampel=paste0("sample",1:3),exp=c(20,22,29))#终成正果
> df1
gene sampel exp
1 gene1 sample1 20
2 gene2 sample2 22
3 gene3 sample3 29
> dim(df1)#看df1是几行几列,现在可以明白dim(a) <- c(2,5)为什么可以把一行1:10,改为两行
[1] 3 3
> nrow(df1)#行数
[1] 3
> ncol(df1)#列数
[1] 3
> rownames(df1)#行名
[1] "1" "2" "3"
> colnames(df1)#列名
[1] "gene" "sampel" "exp"
> data()#查看所有内置数据集
> ?rivers#这是个啥?答:Lengths of Major North American Rivers
> str(rivers)#显示数据集的基本信息
num [1:141] 735 320 325 392 524 ...#有141个数
> head(rivers)#查看前6行
[1] 735 320 325 392 524 450
> class(rivers)
[1] "numeric"
2.PNG
#########下载所给连接里的runinfo文件###########如上图
放在工作目录,可在R右下角的区块里看到它,双击,点 import ,就可以看到了
> library(readr) ##这几句到view都是在import的时候自动执行的
Warning message:
程辑包‘readr’是用R版本3.5.3 来建造的
> SraRunInfo <- read_csv("homework/SraRunInfo.csv")
Parsed with column specification:
cols(
.default = col_character(),
ReleaseDate = col_datetime(format = ""),
LoadDate = col_datetime(format = ""),
spots = col_double(),
bases = col_double(),
spots_with_mates = col_double(),
avgLength = col_double(),
size_MB = col_double(),
LibraryName = col_logical(),
InsertSize = col_double(),
InsertDev = col_double(),
Study_Pubmed_id = col_double(),
ProjectID = col_double(),
TaxID = col_double(),
g1k_pop_code = col_logical(),
source = col_logical(),
g1k_analysis_group = col_logical(),
Subject_ID = col_logical(),
Sex = col_logical(),
Disease = col_logical(),
Affection_Status = col_logical()
# ... with 4 more columns
)
See spec(...) for full column specifications.
> View(SraRunInfo)
> typeof(SraRunInfo)
[1] "list"
> dim(SraRunInfo)
[1] 768 47
###########下载连接里的samples文件###################
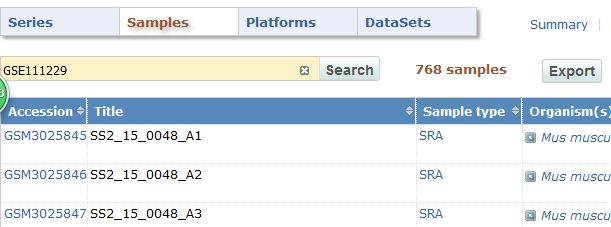
- 复制GSE号
- 点图片上 圆滚滚 的GEO 可以直接进入主页
- 在browse content下 点进 samples
- search & export 注意输出选全部结果,CSV文件

3.PNG
4.PNG
5.PNG
> read.csv("sample.csv")#我想读取这个表,我把它放在了homework文件夹,也就是在右下区块可以看到,然鹅。。。
Error in file(file, "rt") : cannot open the connection
In addition: Warning message:
In file(file, "rt") :
cannot open file 'sample.csv': No such file or directory
> read.csv("homework/sample.csv")#给出路径就好啦,这种跟上面import不同,是输出在屏幕的那种
#所以我的工作目录并不是homework??每一次打开RStudio都需重新设置?
#报错解决
> dim(sample.csv)
Error: object 'sample.csv' not found
> dim("sample.csv")
NULL#不懂
> sample <- read.csv("homework/sample.csv")
> dim(sample)
[1] 768 12
#报错解决,就是试一试
> dim(SraRunInfo)
[1] 768 47
> View(sample)
> ?merge#前俩参数是需要合并的两个表的名字,后面是根据哪一个相同的列合并所以需要先找两个表里相同的那一列,他们的列名可能是不一样的,在“by"后面写
> aaa <- merge(SraRunInfo,sample,by="Experiment",by="SRA.Accession")
Error in merge.data.frame(SraRunInfo, sample, by = "Experiment", by = "SRA.Accession") :
formal argument "by" matched by multiple actual arguments
#报错,R"你说的‘by’是哪个‘by’?",解决方法就是,打出“by.”然后会有选择,再选要的那个,就自动补全等号了
> aaa <- merge(SraRunInfo,sample,by.x ="Experiment",by.y = "SRA.Accession")
> bb <- head(aaa)#取个表头看看
> View(bb)
> dim(aaa)#行数还是768,列数正好是两者之和减去相同的那一列
[1] 768 58
> ?write#第一个参数是操作对象,后面是导出的路径和名字
> write.csv(aaa,file = 'homework')
Error in file(file, ifelse(append, "a", "w")) :
cannot open the connection
In addition: Warning message:
In file(file, ifelse(append, "a", "w")) :
cannot open file 'homework': Permission denied
> write.csv(aaa,file = 'homework/aaa.csv')
#在电脑和R的右下区块就可以看到了