在上一个文章中分析BufferAsyncEmitter时,说到BufferAsyncEmitter使用了SpscLinkedArrayQueue队列来缓存数据。当时在文末时,只是简单的提了一句,并没有详细介绍SpscLinkedArrayQueue队列的原理,在本文,将详细介绍SpscLinkedArrayQueue队列的神奇之处。
1.数据结构
在分析SpscLinkedArrayQueue队列之前,我们先来了解一下SpscLinkedArrayQueue的第一个神奇之处,它神奇的数据结构。
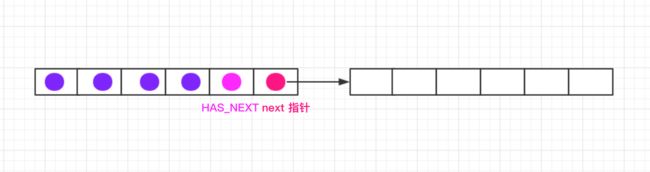
SpscLinkedArrayQueue的数据结构主要神奇在它既不是传统的数组,又不是传统的链表,而是数组+链表。我说的好像过于玄乎了,还是具体来看看吧。
在
SpscLinkedArrayQueue内部维持着类似于上面的数据结构,链表的每个节点是一个数组,而每个节点数组,最后两位不是用来存储数据,而是倒数第二位用来存储一个标记对象,倒数第一位用来存储下一个节点引用。
在整个数据结构中,
SpscLinkedArrayQueue是不会遍历链表的,而是用一个producerBuffer或者consumerBuffer对象用来指向当前的节点。所以这里存在一个问题,一旦前一个节点被填充满了,producerBuffer就指向了下一个节点,同时一旦前一个节点被消费完毕,consumerBuffer也指向下一个节点,此时前一个节点不会被SpscLinkedArrayQueue复用,而是安安静静的等待自己被GC回收。
实际上,上面图中的
HASH_NEXT不是在固定的位置,也就是说,它不一定在倒数第二位,这种情况待会我们在下面分析时,会详细的解释。但是next指针绝对在该数组的最后一位,这个是毋庸置疑的。
2.成员变量
了解了SpscLinkedArrayQueue的数据结构,我们开始正式来分析SpscLinkedArrayQueue,当然,我们还是从它的成员变量开始,来看看它成员变量有哪些,分别表示什么含义。
| 变量名 | 类型 | 含义 |
|---|---|---|
| producerIndex | AtomicLong | 这个用来表示当前生产者生成数据的index,实际上这个变量不是指生成数据的index,而是要跟相应的mask计算才是,此变量只增不减。(对哦,你没有看错,只增不减) |
| producerLookAheadStep | int | 这个变量用来表示生产者可以往前看的数量,默认为容量的1/4,最大为4096。 |
| producerLookAhead | long | 这个变量用来表示index最大的值,也就是说在扩容之前,index能达到的最大值。 |
| producerMask | int | 这个变量用跟index计算offset,这个offset才是真正的位置。默认值二进制全为1,也就是2^n - 1。 |
| producerBuffer | AtomicReferenceArray | 表示生产者生成的数据放入的节点。这个变量是链表的一个节点。 |
| consumerMask | int | 消费者的mask,用来计算当前消费需要消费的数据的位置。默认跟producerMask一样。 |
| consumerBuffer | AtomicReferenceArray | 表示消费者当前需要消费的那个数组节点。意义跟producerBuffer差不多 |
| consumerIndex | AtomicLong | 表示当前消费者需要消费的数据的index,意义跟producerIndex差不多。 |
| HAS_NEXT | Object | 用来表示当前数组节点有下一个节点。 |
3.构造方法
我们先来看看SpscLinkedArrayQueue的构造方法,看看它为我们做了哪些初始化。
public SpscLinkedArrayQueue(final int bufferSize) {
int p2capacity = Pow2.roundToPowerOfTwo(Math.max(8, bufferSize));
int mask = p2capacity - 1;
AtomicReferenceArray 初始化的东西还真的不少,但是我们这里挑比较重要的说。
首先,是对传递进来的bufferSize进行了重新计算的操作,让它始终为2^n。也就是如下的代码。
int p2capacity = Pow2.roundToPowerOfTwo(Math.max(8, bufferSize));
其实这个调整为2^n的操作也不是什么骚操作,就是最普通的位运算。我们先来看看Pow2的roundToPowerOfTwo方法里面究竟是怎么计算的。
public static int roundToPowerOfTwo(final int value) {
return 1 << (32 - Integer.numberOfLeadingZeros(value - 1));
}
是不是一脸懵逼?其实我们这样来考虑,一个int为32bit,其中32个bit中,有且只有1,那么这个数字肯定是2^n。如果我们这样想的话,就非常的简单。
在这个构造方法里面,还有几个地方需要我们注意。
AtomicReferenceArray 数组的容量为2 ^ n + 1,这个得需要我们特别注意,如果这里没有注意,后面就会有理解上的误差。
还有就是需要注意producerLookAhead:
producerLookAhead = mask - 1; // we know it's all empty to start with
producerLookAhead为mask - 1,也就是 2 ^ n - 2,至于为什么是,这里也有很大的学问咯。
4. offer方法
在SpscLinkedArrayQueue中,offer方法和poll方法是占据非常重要的地位,所以分析这两个方法是非常有必要的,当然我们也可以通过分析这两个方法来了解SpscLinkedArrayQueue的本质。我们首先来看看offer方法。
public boolean offer(final T e) {
if (null == e) {
throw new NullPointerException("Null is not a valid element");
}
// local load of field to avoid repeated loads after volatile reads
final AtomicReferenceArray 整个offer过程,我将它分为两种情形。
1.第一情形是index还未超过producerLookAhead,这种情形下,直接通过插入到相应位置当中去就行了。
2.第二情形就是index超过producerLookAhead,这种情形比较复杂,既要考虑到producerLookAheadStep的存在,又要考虑到是否达到必须扩容的条件。
(1).当index还未超过producerLookAhead
这种情况比较简单,在这里主要讲解offset的计算。offset的计算主要通过calcWrappedOffset方法来计算,我们来看看这个方法到底为我们做了什么吧。
private static int calcWrappedOffset(long index, int mask) {
return calcDirectOffset((int)index & mask);
}
private static int calcDirectOffset(int index) {
return index;
}
方法比较简单,归根结底就是index & mask。这个计算有什么特殊的含义吗?当然有了,还记得mask的值为多少吗?mask为2^n - 1,index & mask相当于index % 2 ^ n。
在统一说明成员变量那里,我曾说过index是只增不减的,这里的计算就能体现出来。当index超出了这个数组的长度时,通过mask来取模又能定位一个位置。
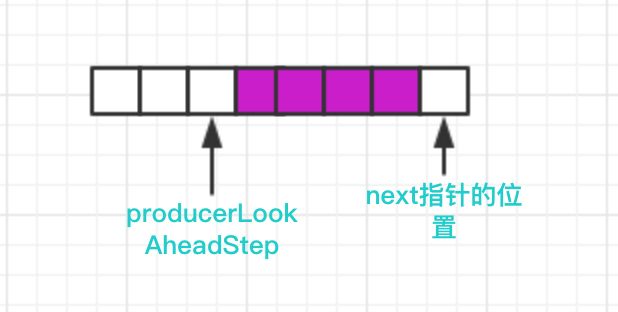
但是在哪种情况下可能会出现index超过数组的长度呢?我们从producerLookAhead这个变量里面寻找答案,之前也说过,producerLookAhead是index能达到的最大位置。当生产者产生数组已经达到了数组末尾时,此时还不能立即进行扩容,而是得看看这个数组节点的前面部分是否已经被消费者消费了,如果已经消费了,我们此时可以往前部分产生数据,而没必要去扩容。这个相当于是一个循环队列的设计思想。
所以,
producerLookAhead不一定固定为数组长度 - 2,当前面已经被消费者消费了,此时producerLookAhead就需要增大了。但是这个增加了多少了,在哪种情况下增加,这些都可以从我们接下来要说的第二种情形中找到答案。
(2).当index超过producerLookAhead
这种情形下,我们还可以分为三种小情形:
1.判断当前index + producerLookAheadStep的位置上是否为null,如果为null,那么表示producerLookAheadStep可以增大,同时index也可以继续增大到新的producerLookAheadStep;如果不为null,就是第二种情形
2.如果第一种情形的条件不能达到,那么看看是否存在有消费者被消费了的位置,但是还不足producerLookAheadStep。如果存在,就进行index + 1操作,同时producerLookAheadStep不能变;如果不存在,那么进行第三种情形的操作。
3.如果上面两种情形都不成立的话,那么进行此种情形的操作,那就是扩容。
这里先只讲解前面两种情形,扩容操作比较特殊,单独来讲。
先来看看第一种情形:
final int lookAheadStep = producerLookAheadStep;
// go around the buffer or resize if full (unless we hit max capacity)
int lookAheadElementOffset = calcWrappedOffset(index + lookAheadStep, mask);
if (null == lvElement(buffer, lookAheadElementOffset)) { // LoadLoad
producerLookAhead = index + lookAheadStep - 1; // joy, there's plenty of room
return writeToQueue(buffer, e, index, offset);
}
这里的逻辑非常简单,简单来说就是我们上面所说的。先是通过取模计算了index + producerLookAheadStep的offset,然后判断offset位置上是否为null,如果为null,表示达到producerLookAhead增大的条件,然后就是,producerLookAhead增大了lookAheadStep - 1,虽然这里是index + lookAheadStep - 1,但是我认为,在只要符合这种条件的,index等于producerLookAhead。因为如果index不等于producerLookAhead,肯定不是第一次进入这个判断语句,而第一次进来的话,如果符合的话,就已经扩容了,就变成了index还未超过producerLookAhead的情况。
再来看看第二种情形:
else if (null == lvElement(buffer, calcWrappedOffset(index + 1, mask))) { // buffer is not full
return writeToQueue(buffer, e, index, offset);
}
这种情况比较简单,此时index只是简单的做加1操作。这种情形就像是,前面步子迈大了,扯着X了,开始一步一步的迈。
第三种情形便是我们的扩容操作,这个也是我们SpscLinkedArrayQueue神奇之处之一。接下来,我们慢慢看这个扩容骚操作。
5.扩容骚操作
说这个骚,不是一般的骚,不得不佩服大佬们写的代码。
在这里,我们会知道数组的容量为什么为2 ^ n + 1,而不是2 ^ n。
首先,我们还是先来看看整个扩容的过程。
private void resize(final AtomicReferenceArray 整个方法的比较简单,就是创建了一个新的AtomicReferenceArray对象,跟原对象容量是一模一样的,然后通过soNext方法将两个节点连接起来,我们来看看放的位置:
private void soNext(AtomicReferenceArray 没错,将新的AtomicReferenceArray对象放在了原对象的最后一位,这样相当于是将两个节点起来,也应证我们前面的总结。
soElement(newBuffer, offset, e);// StoreStore
soElement(oldBuffer, offset, HAS_NEXT); // new buffer is visible after element is
然后接下来,你会看到极其骚的操作,将原数组的offset位置上设置为HAS_NEXT,同时在新数组的offset位置上放入需要加入的数据。这样做有什么好处呢?
这个有利于poll操作,当poll操作操作到这个位置上时,发现是HAS_NEXT,会到下一个节点的offset位置上去寻找。因为offer操作也是offset开始,所以必须保证poll操作从offer操作开始的地方进行。
整个过程差不多就是这样的,接下来我们分析上面的两个问题。
(1).数组容量为什么为2 ^ n + 1
我们知道index是自增不减的,同时offset是通过index & mask计算得到的。同时HAS_NEXT坐标也是offset,所以,我们可以知道,在扩容是,HAS_NEXT的坐标是不定的。那数组容量为129为例来说,HAS_NEXT可能出现在0 ~ 127任何一个位置,但是128位置上始终是为next指针准备。
这是为什么?我们可以这样来理解,将HAS_NEXT当成一个特殊的数据,它也属于生产者生成的数据其中一个,但是next指针不可能当成其中一个,因为消费者不能正确找到next指针,除非将整个数组遍历,显然这是一个愚蠢的做法。所以next指针放在一个固定位置上,哪个位置不可能被占据呢?在0 ~ 127的范围里面显然是不可能的,所以得单独找一个不在0 ~ 127范围里面的位置,哪个位置呢?肯定是128,所以数组容量才为2 ^ n + 1。
6.poll方法
看完了offer方法,现在我们再来看看poll方法。
public T poll() {
// local load of field to avoid repeated loads after volatile reads
final AtomicReferenceArray 整个poll方法比较简单,通过获取offset的数据,先判断是否是HAS_NEXT,如果不是那么就可以取出;如果是的话,那么就到mask + 1的位置找到下一个节点,再到下一个节点的offset位置上去取数据。
7.总结
总的来说,SpscLinkedArrayQueue涉及过于神奇。这里我来做一个简单的总结。
1.SpscLinkedArrayQueue的数据结构为数组+链表,其中SpscLinkedArrayQueue不会遍历数组,这个是SpscLinkedArrayQueue涉及的神奇之处。
2.SpscLinkedArrayQueue扩容必须同时达到三个条件,一是index大于producerLookAhead,二是index + lookAheadStep位置上不为null,三是index + 1不为null,也就是说,当前0 ~ 2^n - 1范围内,只有index位置上为null。在这种情况下,才会扩容。
3.扩容时,会将原数组的offset位置上设置为HAS_NEXT,同时将新数组的offset位置上设置为新添加的数据,然后就是,将新数组的指针设置在原数组的最后一位。
4.poll时,当发现是HAS_NEXT,此时就去下一个数组相应的offset位置上去找。