1散列思想
散列表的英文叫“Hash Table”,所以也阔以叫它“哈希表”或者“Hash表”。
散列表用的是数组支持按照下标随机访问数据的特性,所以说散列表就是数组的一种扩展,由数组演化而来。可以说,如果没有数组,就没有散列表。
举个例子,我们有100位学生参加运动会,它们的编号依次是1-100,我们希望实现通过编号快速找到对应的选手信息的功能。我们就可以把它们存在数组里,数组下标为1的位置存放编号为1的选手信息,数组下标为2的位置存放编号为2的选手信息,依次类推,数组下标为k的位置存放编号为k的选手信息。
因为参赛编号跟数组下标一一对应,所以我们想要查询编号为x的选手信息时,直接访问数组下标为x的位置的数据就好啦,时间复杂度是O(1),效率超高哒。
上面这个例子其实已经蕴含了散列的思想,但是它比较简单,散列的思想体现的还不够明显。下面我们再来一个例子。
假设我们想要通过学号快速找到对应的学生信息,我们都知道,学号比较长,比如这样:17011133401,每一位都有它的含义,这个时候我们就不能简单的将学号对应到相应的数组下标上,因为数字太大啦。
尽管我们不能直接取学号作为下标,但是我们可以取学号的后两位作为数组下标,存储对应的学生信息。然后想要获取学生信息的时候,直接用学号后两位来找到对应下标的数组位置。
这就是典型的散列思想。其中,学号我们称作键(key)或者关键字,用它来标识一个学生。将学号转化为数组下标的映射方法叫散列函数(或者哈希函数),而散列函数计算得到的值就是散列值(或者哈希值)。
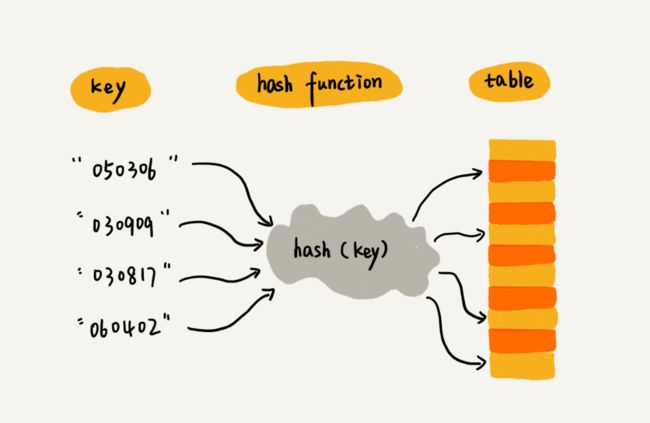
2散列函数
刚刚我们有提到散列函数,它在散列表中起着非常关键的作用。我们可以把它定义成hash(key)。
刚刚我们取学号最后两位作为散列值的方法就可以写成下面这样,伪代码如下图所示:

但是,键值并不总是像学号那样是简单的并且有规律的数字,它有可能是随机生成的数字,也有可能是字符串,我们就需要用其他方法来构造散列函数。
在构造散列函数的时候,我们需要满足下面三点基本要求:
1.散列函数计算得到的散列值是一个非负整数。
2.如果key1=key2,那么hash(key1)=hash(key2)。
3.如果key1!=key2,那么hash(key1)!=hash(key2)。
前两点比较容易满足,第三点很难满足,要想找到一个不同的key对应的散列值都不一样的散列函数,几乎是不可能的,即便是业界著名的MD5、SHA、CRC等哈希算法,也无法完全避免这种散列冲突。而且,因为数组的存储空间有限,也会加大散列冲突的概率。
3散列冲突
解决散列冲突问题有两个方法:开放寻址法和链表法。
1.开放寻址法。
开放寻址法的思想是,如果出现了散列冲突,我们就重新探测一个空闲位置将其插入。这里讲一个比较简单的探测方法:线性探测。
我们在往散列表中插入数据时,如果键值经过散列函数处理得到的散列值已经存在,也就是当前下标位置已经存入数据了的时候,我们就继续往后探测,直到找到空闲位置,然后将它存入这个空闲位置。
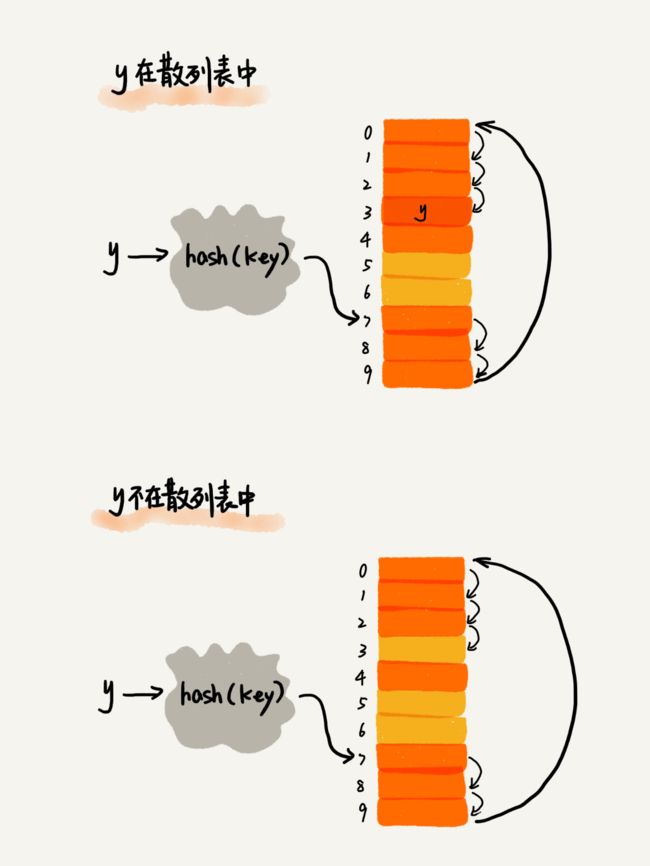
举个例子,如下图所示,橙色是已经存储数据的位置,黄色是空闲位置。x经hash(key)处理后,得到的散列值是7,但是下标为7的位置已经存储了数据,所以就继续向后探测空闲位置。但是直到数组尾部都没有探测到呢,没关系,我们继续返回数组头部继续探测空闲位置,找到了下标为2的位置是空闲的,将键值x存入。
查找与插入的方法很像,也是通过hash(key)得到散列值,若当前散列值下标处存放的数据和我们要查找的数据相等,则就是我们要找的元素,若不相等,则继续向后探测。若探测到空闲位置的时候还没有找到,说明要查找的元素并没有在散列表中。
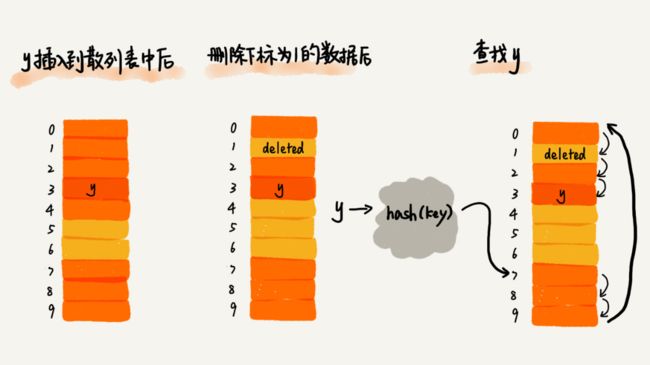
下面是删除操作,删除操作和插入、查找的思想也基本一致,但是要注意的是,我们不能简单的将元素直接删除,这样后面再查找的时候,探测到这个位置还没有找到元素,就会判定为元素不存在,有可能发生误判,所以我们在删除的时候,需要将这个位置标记为deleted,查找的时候探测到deleted的空间时就可以不用停下来,而是继续向后探测。
但是线性探测法存在的问题是,当散列表中插入的数据越来越多时,散列冲突发生的可能性就会越来越大,空闲位置会越来越少,线性探测的时间就会越来越久。极端情况下可能需要探测整个散列表,这个时候时间复杂度是O(n)。同理,删除和查找也可能是这种情况。
所以除了线性探测方法之外,还有另外两种比较经典的探测方法:二次探测和双重散列。
二次探测跟线性探测很像,线性探测每次探测的步长是1,而二次探测探测的步长是原来的二次方。
双重散列意思就是不仅要用一个散列函数,如果通过第一个散列函数计算得到的位置已经被占用,那么就再用第二个散列函数,以此类推,直到找到空闲的存储位置。
不管用哪种探测方法,当散列表中空闲位置不多的时候,散列冲突发生的概率就会大大提高,所以为了尽可能保证散列表的操作效率,我们会尽可能去保证散列表中有一定比例的空闲槽位,我们用装载因子来标识空位的多少。
装载因子的计算公式:
装载因子越大则散列表中空闲位置越少,发生散列冲突的概率越大,散列表的性能越低。
2.链表法
这种方法比线性探测法就简单多啦。
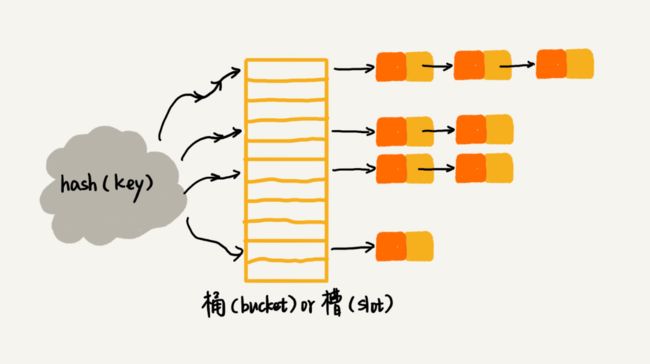
如上图所示,散列表中的每个“桶”或“槽”都对应一条链表,所有散列值相同的元素我们都会放到相同槽位对应的链表中去。插入的时间复杂度是O(1),查找和删除的时间复杂度跟链表的长度k成正比,也就是O(k)。对于散列表比较均匀地散列函数来说,理论上讲k=n/m,其中n表示散列表中数据的个数,m表示散列表中“槽”的个数。
4word中的单词拼写检查功能是如何实现的
实际上它就是通过散列表实现的。
我们将所有单词都存在散列表中(常用的英文单词有20万个左右,假设单词的平均长度是10个字母,平均一个单词占用10个字节的内存空间,20万英文单词大约占2MB的存储空间,这个大小放在内存中完全不是问题)。
当用户输入某个英文单词时,我们只需要在散列表中进行查找,如果没有查到,则说明拼写可能有误,就进行拼写错误提示。
5内容小结
这节课的散列表知识都比较基础、比较偏理论,包括散列表的由来,散列函数,散列冲突的解决方法。
散列表来源于数组,它借助散列函数对数组这种数据结构进行扩展,利用的是数组支持按照下标随机访问元素的特性。散列表的两个核心问题是散列函数设计和散列冲突解决。散列冲突有两种常用的解决方法:开放寻址法和链表法。散列函数设计的好坏决定了散列冲突的概率,也就决定散列表的性能。
后面的章节我们还会更贴近实战更加深入的探讨散列函数和散列冲突的问题~