【图像处理】特征点算法整理总结
特征点检测
1.Susan
SUSA(Smallest Univalue Segment Assimilating Nucleus)算子是一种高效的边缘和角点检测算子,并且具有结构保留的降噪功能
原理
用一个圆形模板在图像上移动,若模板内的像素灰度与模板中心的像素(被称为核Nucleus)灰度值小于一定的阈值,则认为该点与核Nucleus具有相同的灰度,满足该条件的像素组成的区域就称为USAN(Univalue Segment Assimilating Nucleus)。边缘处的点的USAN值小于或等于最大值一半。由此,我们可以得出SUSAN提取边缘和角点算法的基本原理:在边缘或角点处的USAN值最小,可以根据USAN区域的大小来检测边缘、角点等特征的位置和方向信息。
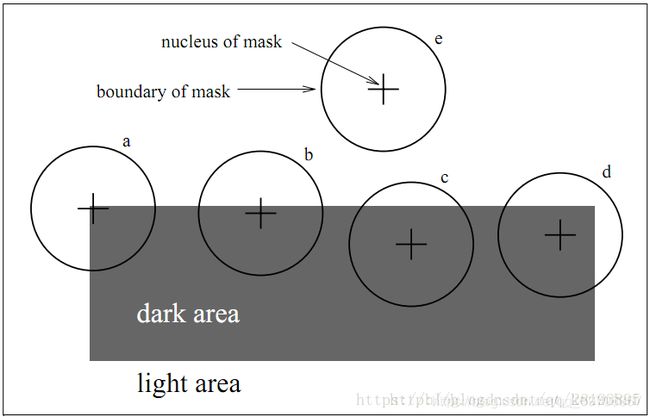
实现步骤
- 利用圆形模板遍历图像,计算每点处的USAN值
- 设置一阈值g,一般取值为1/2(Max(n)), 也即取值为USAN最大值的一半,进行阈值化,得到角点响应
- 使用非极大值抑制来寻找角点
优缺点
- 完全不涉及梯度的运算,因此其抗噪声能力很强,运算量也比较小
- SUSAN算子还是一个各向同性的算子
- 图像的对比度较大,则可选取较大的t值,而图像的对比度较小,则可选取较小的t值
- 不仅具有很好的边缘检测性能;而且对角点检测也具有很好的效果。
2.FAST
FAST( Features from Accelerated Segment Test)由Rosten等人在SUSAN角点特征检测方法的基础上利用机器学习方法提出.
原理
分割测试
在FAST角点检测算子中,一般是通过半径为3.4 pixel、外围16个像素的圆的作为模板筛选特征点。12点分割角点检测算法是在一个图像块上进行。其中p是中心像素点,12点取的是图上用弧线连接的12个点的像素值(通过测试,12点的角点检测性能最稳定、速度更快、效果也很好,有些文献指出9点的方式也很好)。

t是一个阈值(默认取值为10,不同场景取值有差异),Ip表示的是中心像素的像素值,Ip→x表示的是圆形模板中的像素值。统计圆形区域中d或b的个数,只要d或b出现的次数大于n((当是12点分割测试角点检测时,n=12;当是9点时,则n=9),那么该点就被认为是候选角点。
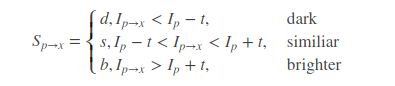
在分割测试步骤中,为了加快速度,其实不需要对这些像素进行逐一的比较。简单来说:首先比较1、5、9、13处点的像素值(也即水平方向和垂直方向上的4个点)与中心像素值的大小,如果这四个点中的像素值有3个或3个以上大于Ip→x+t或小于Ip→x−t,那么则认为该处是一个候选角点,否则就不可能是角点。
ID3训练
将模板内的像素分成三部分d、s、b,分别记为:Pd,Ps,Pb。因此对于每个Sp→x都属于Pd,Ps,Pb中的一个。另外,令Kp为true,如果p为角点,否则为false。通过ID3算法来选择具有最大信息增益的像素来判断一个像素是否为角点。Kp的熵用下式来计算:
![]()
上式中c表示角点数量,c−表示非角点数量。某一像素的信息增益通过下式表示:
![]()
非极大值抑制
在上面的分割测试中,没有计算角点响应函数(Corner Response Function),非极大值抑制无法直接应用于提取的特征。因此,定义一个角点响应函数V,考虑到分割测试的特征以及计算速度的需要,角点响应函数的定义如下:
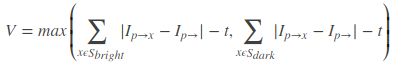
实现步骤
- 对固定半径圆上的像素进行分割测试,通过逻辑测试可以去处大量的非特征候选点。
- 基于分类的角点特征检测,利用ID3 分类器根据16个特征判决候选点是否为角点特征,每个特征的状态为一1,0,1。
- 利用非极大值抑制进行角点特征的验证。
优缺点
- 计算速度快,可以应用于实时场景中
- 容易受到噪声影响,阈值t的影响也较大
3.Harris角点检测
原理
用一个固定窗口在图像上进行任意方向上的滑动,比较滑动前与滑动后两种情况,窗口中的像素灰度变化程度,如果存在任意方向上的滑动,都有着较大灰度变化,那么我们可以认为该窗口中存在角点。
BRIEF
Brief为特征描述子,对已检测到的特征点进行描述,是一种二进制编码描述子
实现步骤
- 为减少噪声干扰,先对图像进行高斯滤波(方差2,窗口9x9)
- 以特征点为中心,取SxS的邻域大窗口。在大窗口中随机选取(有5种经典方法)一对(两个)5x5的子窗口,比较子窗口内的像素和(可用积分图像完成),进行二进制赋值。(一般S=31),其中p(x),p(y)分别为所在5x5子窗口的像素和
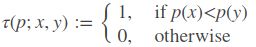

- 在大窗口中随机选取N对子窗口,重复步骤2的二进制赋值,形成一个二进制编码,这个编码就是对特征点的描述,即特征描述子。(一般N=256)构造一个512个bit的BRIEF,就需要512对[x,y],且需要注意,它们是有序的,每次计算位置都相同,否则影响最终结果。也就说说,一旦选定了512对[x,y],那么,无论是提取特征,还是匹配特征,都要按照这512对进行计算。
- 用汉明距离进行配对。两个特征编码对应bit位上相同元素的个数小于128的,一定不是配对的。一幅图上特征点与另一幅图上特征编码对应bit位上相同元素的个数最多的特征点配成一对。
优缺点
- 抛弃了传统的用梯度直方图描述区域的方法,改用检测随机响应,大大加快了描述子建立速度
- 生成的二进制描述子便于高速匹配,计算Hamming距离只需通过异或操作加上统计二进制编码中“1”的个数的操作,这些通过底层的运算即可实现
- 缺点很明显就是旋转不变性较差
ORB
DoG
DoG算子是由Lowe D.G.提出的,对噪声、尺度、仿射变化和旋转等具有很强的鲁棒性,能够提供更丰富的局部特征信息
原理
尺度空间
在用机器视觉系统分析未知场景时,机器并不知道图像中物体的尺度,只有通过对图像的多尺度描述,才能获得对物体感知的最佳尺度。如果在不同尺度上,对输入的图像都能检测到相同的关键点特征,那么在不同尺度下也可以实现关键点的匹配,从而实现关键点的尺度不变特性。
图像金字塔多分辨率
金字塔是早期图像多尺度的表示形式,图像金字塔一般包括2个步骤,分别是使用低通滤波平滑图像;对图像进行降采样(也即图像缩小为原来的1/4,长宽高缩小为1/2),从而得到一系列尺寸缩小的图像。金字塔的构造如下所示:

高斯平滑滤波
高斯核是唯一可以产生多尺度空间的核。一个图像的尺度空间L(x,y,σ) ,定义为原始图像I(x,y)与一个可变尺度的2维高斯函数G(x,y,σ)卷积运算。 二维空间高斯函数:
![]()
尺度空间表示为:
![]()
高斯模版是圆对称的,且卷积的结果使原始像素值有最大的权重,距离中心越远的相邻像素值权重也越小。高斯模糊另一个重要的性质就是线性可分,使用二维矩阵变换的高斯模糊可以通过在水平和竖直方向各进行一维高斯矩阵变换相加得到。
多尺度与多分辨率
尺度空间表达和金字塔多分辨率表达之间最大的不同是:
- 尺度空间表达是由不同高斯核平滑卷积得到,在所有尺度上有相同的分辨率;
- 金字塔多分辨率表达每层分辨率减少固定比率。
所以,金字塔多分辨率生成较快,且占用存储空间少;而多尺度表达随着尺度参数的增加冗余信息也变多。多尺度表达的优点在于图像的局部特征可以用简单的形式在不同尺度上描述;而金字塔表达没有理论基础,难以分析图像局部特征。
拉普拉斯金字塔
结合尺度空间表达和金字塔多分辨率表达,就是在使用尺度空间时使用金字塔表示,在计算机视觉中最有名莫过于拉普拉斯金字塔。拉普拉斯金字塔顾名思义就是通过对图像进行拉普拉斯操作,然后进行一个降采样的过程。具体来说就是:原始图像作为金字塔的底层,也即0层,称为g0,对0层图像 g0 进行进行拉普拉斯金操作,得到第一层图像g1;接着对第一层图像进行拉普拉斯操作,得到第二层图像g2,依次类推,并进行一个降采样,如此构造拉普拉斯金字塔。
DoG金字塔
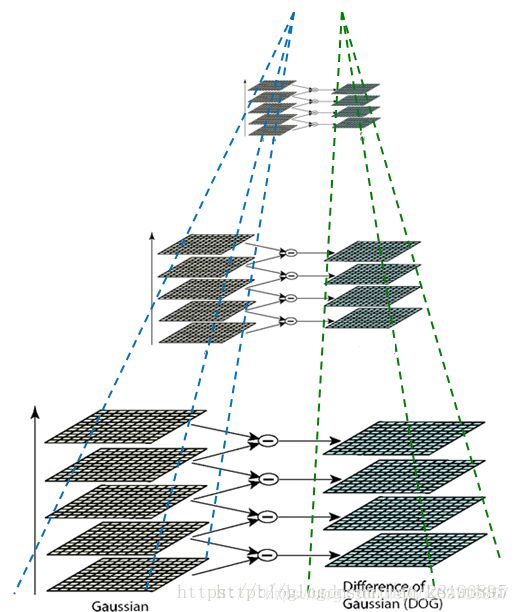
DoG(Difference of Gaussian)其实是对高斯拉普拉斯(LoG)的近似,在某一尺度上的特征检测可以通过对两个相邻高斯尺度空间的图像相减,得到DoG的响应值图像D(x,y,σ),这比直接计算LoG效率更高。
- 对原图进行相邻尺度的高斯滤波
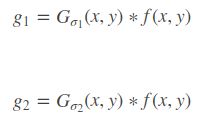
- 将上面的滤波得到的两幅图像相减:
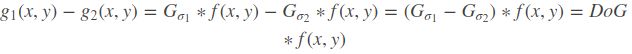
- 将公式简化写法:
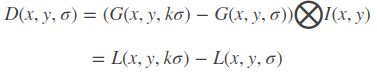
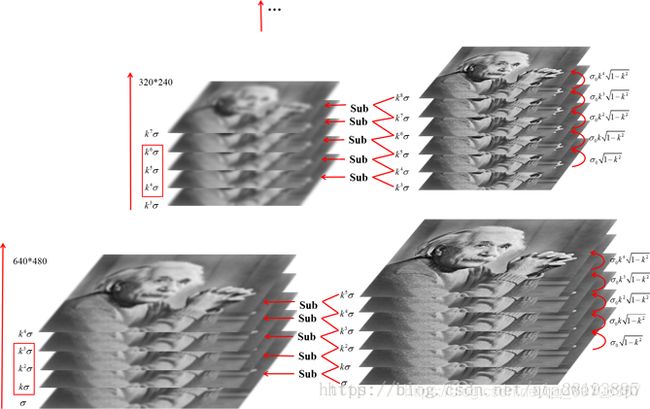
- 构造高斯金字塔
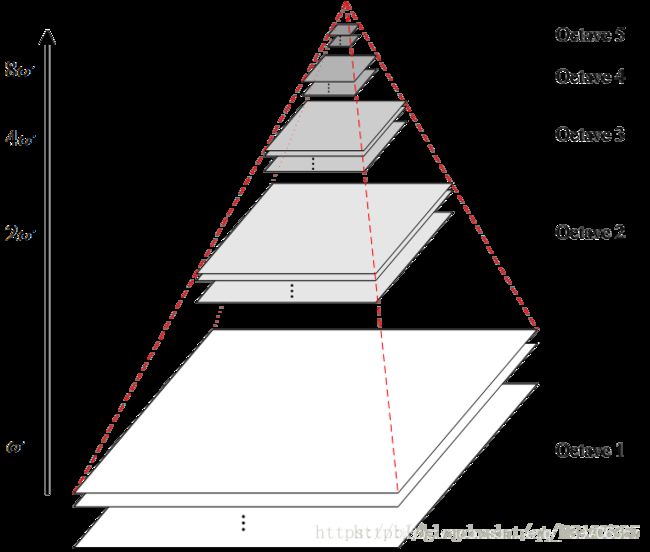
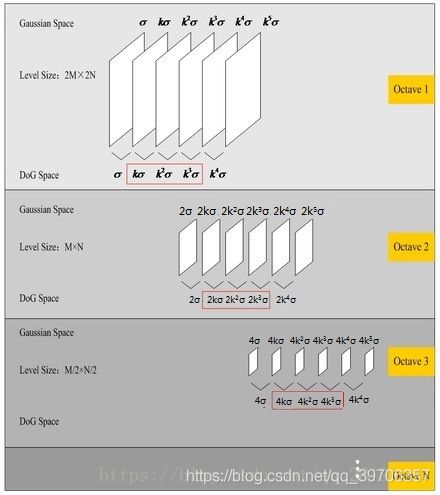
为了得到DoG图像,首先要构造高斯金字塔,高斯金字塔在多分辨率金字塔的基础上加入了高斯滤波,也就是对金字塔每层图像采用不同的参数sigma进行了高斯卷积,使得金字塔的每层有多张图片组成为一个Octave,每组有多张(也叫层interval)图像。每个Octave是由同一大小的图像,经过不同sigma高斯滤波得到的,而Interval则表示的是同一个sigma高斯滤波的图像。另外,降采样时,金字塔上边一组图像的第一张图像(最底层的一张)是由前一组(金字塔下面一组)图像的倒数第三张隔点采样得到,图像表示如下:
- 求DoG
求角点
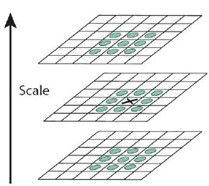
X标记当前像素点,绿圈标记邻接像素点,用这个方式,最多检测相邻尺度的26个像素点。如果它是所有邻接像素点的最大值或最小值点,则X被标记为特征点,如此依次进行,则可以完成图像的特征点提取。
优缺点
- 具有尺度不变特性,抗旋转
- 计算量大
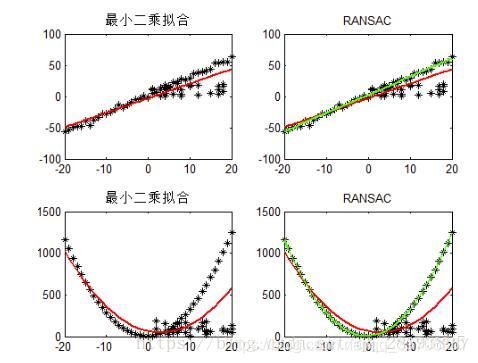
RANSC特征点筛选
随机抽样一致算法(random sample consensus,RANSAC),采用迭代的方式从一组包含离群的被观测数据中估算出数学模型的参数。
RANSAC算法的基本假设是样本中包含正确数据(inliers,可以被模型描述的数据),也包含异常数据(outliers,偏离正常范围很远、无法适应数学模型的数据),即数据集中含有噪声。这些异常数据可能是由于错误的测量、错误的假设、错误的计算等产生的。同时RANSAC也假设,给定一组正确的数据,存在可以计算出符合这些数据的模型参数的方法。
实现步骤
- 假定模型(如直线方程),并随机抽取Nums个(以2个为例)样本点,对模型进行拟合
- 由于不是严格线性,数据点都有一定波动,假设容差范围为:sigma,找出距离拟合曲线容差范围内的点,并统计点的个数
- 重新随机选取Nums个点,重复第一步~第二步的操作,直到结束迭代
- 每一次拟合后,容差范围内都有对应的数据点数,找出数据点个数最多的情况,就是最终的拟合结果
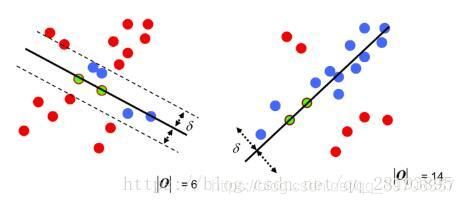
优缺点
最小二乘法适用于有效数据占大多数,无效数据少的情况,是从一个整体误差最小的角度去考虑。RANSC基于假设寻找最优。