Semi-Supervised Semantic Segmentation with High- and Low-level Consistency
TPAMI 2019
论文原文
code
创新点:
利用两个分支结构分别处理low-level和high-level的特征,进行半监督语义分割
网络结构
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第1张图片](http://img.e-com-net.com/image/info8/ea7f8feb5cb24004802084f3c94cc7d6.jpg)
上分支:Semi-Supervised Semantic Segmentation GAN (s4GAN)
下分支:Multi-Label Mean Teacher (MLMT)
s4GAN
训练segmentation network \(S\)
segmentation network \(S\)的损失函数由以下三部分组成:
- Cross-entropy loss
输入原图到segmentation network \(S\)中,对于labeled images,输出的分割结果\(S(x^l)\)和标签\(y^l\)对比,计算交叉熵损失\(L_{ce}\)

- Feature matching loss
为了使得分割结果\(S(x^l)\)和标签\(y^l\)的特征分布尽可能一致,本文计算分割结果\(S(x^l)\)和标签\(y^l\)的特征分布差异mean discrepancy,并设计Feature matching loss
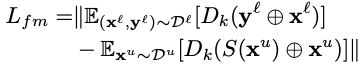
上式中\(D_k\)表示discriminator的第\(k\)层
注:此Feature matching loss适用于有标签和无标签的数据 - Self-training loss
本文认为,在训练过程中generator和discriminator需要达到某种平衡,如果discriminator过于strong,则无法给generator任何有用的学习信号。因此,对于unlabeled image,本文每次将generator产生的,可以成功欺骗discriminator的分割图当作真实标签,用于监督学习。由此可以促使segmentation network(即generator)变强,且一定程度上阻碍discriminator的进步,不希望discriminator过于强大,破坏平衡。
具体而言,discriminator在s4GAN中用于在image-level判断一张分割图是真实标签(real label),还是segmentation network的输出(fake label),根据为真实标签的可能性输出一个0~1之间的概率值(若为真实标签,则输出1)
文章设置闸值,对于输出大于闸值的分割图,作为高质量的预测图,当作真实标签,用于监督学习,并计算交叉熵损失

s4GAN总损失:
![]()
训练discriminator
discriminator的输入包含原图image和对应标签,训练discriminator,希望discriminator能给真实标签打高分,给fake label打低分。具体损失函数和传统的GAN相同。

![]() (channel wise)
(channel wise)
MLMT
该分支包含两个网络,分别为学生网络和老师网络,训练时,一张image经过微小的,不同的扰动之后分别输入学生网络和老师网络,学生网络和老师网络使用online ensemble的weight(老师网络是学生网络学习的目标,老师网络的权重在学生网络的基础上根据指数平均移动线移动,详见论文)。本文希望学生网络的输出和老师网络的输出尽可能一致,则对于所有image,使用均方误差来衡量两个网络输出的差异,对于labeled image,同时使用类交叉熵函数计算损失
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第2张图片](http://img.e-com-net.com/image/info8/9dbd7875d9834cf59a536884fbfb417f.jpg)
Network Fusion
简单的通过deactivate segmentation networks的输出中没有出现在input image中的图片来融合两个网络的结果。
对于一张image分割图的一个类别c的mask,尺寸为\(HxWx1\),(对于每一个像素?)如果学生网络的输出(soft label)小于设定的某个闸值,则令segmentation network的输出为0,否则segmentation network的输出不变。

实验
数据集:
PASCAL VOC 2012 segmentation benchmark, the PASCAL-Context dataset, and the Cityscapes dataset.
网络具体结构:
segmentation network:
deeplab v2
discriminator:
4层卷积层,通道数分别为\({64,128,256,512}\),卷积核大小为4x4,每个卷积层后面都有一个negative slope of 0.2的Leaky-ReLU层和一个dropout概率为0.5的dropout层(该高概率的dropout layer对于GAN的稳定训练非常关键)。最后一个卷积层后面是一个全局平均池化层和全连接层,全局平均池化的输出用于Feature matching loss的计算
学生网络和老师网络:
ResNet101(在imagenet上预训练)
实验结果:
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第3张图片](http://img.e-com-net.com/image/info8/88bed3722a014fb9a67de7455070cee9.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第4张图片](http://img.e-com-net.com/image/info8/e7c76a5ef5344c59933e3d090e86a72e.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第5张图片](http://img.e-com-net.com/image/info8/6876d17ad6dc43fb8f7c7ee38ad2917a.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第6张图片](http://img.e-com-net.com/image/info8/774763132c51420db893158a73d33cb5.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第7张图片](http://img.e-com-net.com/image/info8/51969c335ba14c1691134681ea75443e.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第8张图片](http://img.e-com-net.com/image/info8/afc5b4cd412a450183fffcc28f0512e6.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第9张图片](http://img.e-com-net.com/image/info8/963e915460e34518948f283f405867ae.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第10张图片](http://img.e-com-net.com/image/info8/662eb861417d4924a5d2b08aae55ffc4.jpg)
![[论文][半监督语义分割]Semi-Supervised Semantic Segmentation with High- and Low-level Consistency_第11张图片](http://img.e-com-net.com/image/info8/6b8bd8b3722a4d889a1395db2b1fab10.jpg)
疑问:
- 网络融合的目的?
- self-train loss的设定(为阻止discriminator变强)?