开始前先做一下pivot_table的实现。
import pandas as pd
import numpy as np
df = pd.DataFrame({"A": ["foo", "foo", "foo", "foo", "foo",
... "bar", "bar", "bar", "bar"],
... "B": ["one", "one", "one", "two", "two",
... "one", "one", "two", "two"],
... "C": ["small", "large", "large", "small",
... "small", "large", "small", "small",
... "large"],
... "D": [1, 2, 2, 3, 3, 4, 5, 6, 7]})
df
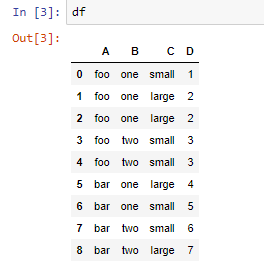
table = pd.pivot_table(df, values='D', index=['A','B'],columns=['C'],aggfunc=np.sum)
table
table = pd.pivot_table(df, values=['D'], index=['A', 'B','C'],
... aggfunc=[min, max, np.mean])
table

接下来进入整体使用文本矩阵计算相似性
def word2vec(verblist): #define input format should be list
#func1 find unique word and build matrix
uniquemat=set([])
for words in verblist:
uniquemat = uniquemat | set(words)
uniquemat=list(uniquemat)
#statistics for TF
vectormat=[]
for words in verblist:
vector=[0]*len(uniquemat)
for word in words:
if word in uniquemat:
vector[uniquemat.index(word)]+=1
vectormat.append(vector)
vectormat=pd.DataFrame(vectormat)
vectormat.columns=uniquemat
return(vectormat)
import jieba
import codecs
import pandas as pd
f = codecs.open("C:\\Users\\Data Engineer\\Desktop\\xx\\NBA.txt",'r','gbk')
doc1=f.read()
f = codecs.open("C:\\Users\\Data Engineer\\Desktop\\xx\\worldcup.txt",'r','gbk')
doc2=f.read()
jieba.load_userdict("C:\\Users\\Data Engineer\\Desktop\\xx\\sougoNBA.txt")
jieba.load_userdict("C:\\Users\\Data Engineer\\Desktop\\xx\\sougoSoccer.txt")
在这里我们发现有很多标点符号和换行符在里边,所以去除标点符号,同时,我们发现一些求源的名字被拆解开,所以我们需要构建词库和停用词库。
doc1words=[]
for word in jieba.cut(doc1):
doc1words.append(word)
doc2words=[]
for word in jieba.cut(doc2):
doc2words.append(word)
stopwords = pd.read_csv("C:\\Users\\Data Engineer\\Desktop\\xx\\StopwordsCN.txt",encoding='utf-8',index_col=False)
words1=[] #doc1的文字
for word in doc1words:
if word not in stopwords and len(word.strip())>1:
words1.append(word)
words2=[] #doc2的文字
for word in doc2words:
if word not in stopwords and len(word.strip())>1:
words2.append(word)
contents=[words1,words2]
TF_table=word2vec(contents)
TF_table #词频

#然后这时候我们计算两篇文章的相似度,通过公式cos(\theta)=\frac{\sum_{i=1}^N(X_i \cdot Y_i)}{\sqrt(\sum_{i=1}^N(X_i)^2)*\sqrt(\sum_{i=1}^N(Y_i)^2)}
CosineSimularity=sum(TF_table.loc[0]*TF_table.loc[1])/(np.sqrt(sum(TF_table.loc[0]**2)*sum(TF_table.loc[1]**2)))
print("两篇文章的余弦相似度是:",CosineSimularity)
这时候我们通过云图来直观查看
#把数据转为我们习惯的数据结构和格式
columns=list(TF_table.columns)
counts1=list(TF_table.loc[0])
counts2=list(TF_table.loc[1])
contentstat1=pd.DataFrame({'words':columns,'计数':counts1})
contentstat1=contentstat1.sort_values(['计数'],axis=0,ascending=False)
contentstat2=pd.DataFrame({'words':columns,'计数':counts2})
contentstat2=contentstat2.sort_values(['计数'],axis=0,ascending=False)
#导入wordcloud模块
from wordcloud import WordCloud
from scipy.misc import imread
from wordcloud import ImageColorGenerator
import matplotlib.pyplot as plt
bimg1=imread("C:\\Users\\Data Engineer\\Desktop\\xx\\NBA.PNG")
image_colors1 = ImageColorGenerator(bimg1)
bimg2=imread("C:\\Users\\Data Engineer\\Desktop\\xx\\timg1.jpg")
image_colors2 = ImageColorGenerator(bimg2)
wordcloud=WordCloud(font_path='C:\\Users\\Data Engineer\\Desktop\\xx\\2.4 词云绘制\\2.4\\simhei.ttf',background_color='black',mask=bimg1,max_font_size=300) #这里的mask就是选择背景的过程
words = contentstat1.set_index('words').to_dict()
wordcloud.fit_words(words['计数'])
plt.show(wordcloud.recolor(color_func=image_colors1))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
wordcloud=WordCloud(font_path='C:\\Users\\Data Engineer\\Desktop\\xx\\2.4 词云绘制\\2.4\\simhei.ttf',background_color='black',mask=bimg2,max_font_size=300) #这里的mask就是选择背景的过程
words = contentstat2.set_index('words').to_dict()
wordcloud.fit_words(words['计数'])
plt.show(wordcloud.recolor(color_func=image_colors2))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()

文章一:有关NBA伦纳德转会的新闻

文章二:有关世界杯话题的新闻
也看出来,两篇文章真的是风马牛不相及,也佐证了相似度计算结果的正确性。