6.机器学习-高级绘图工具seaborn-简单、快捷
可视化数据的分布
处理一组数据前,先了解变量分布情况
- 对于单变量的数据,采用直方图或核密度曲线
- 对于双变量,采用多面板图形展示,如:散点图、二维直方图、核密度估计图形等
单变量-直方图
displot(a,bins=None,hist=True,kde=True,rug=False,fit=None,color=None)
- a:要观察的数据,Series、一维数组或列表
- bins:用于控制条形的数量
- hist:是否绘制(标注)直方图
- mg:是否在支持的轴方向上绘制rugplot
# 生成随机数种子,确定随机数生成器生成的数据是一样的
np.random.seed(0)
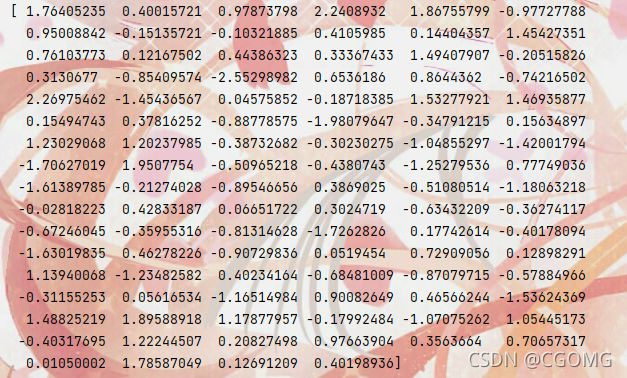
arr = np.random.randn(100)
print(arr)
sns.distplot(arr, bins=10, hist=True, kde=True, rug=True)
plt.show()

- 直方图共有10个条柱,每个条柱的颜色为蓝色,并且有核密度估计曲线
- 根据条柱的高度可知,位于-1到1区间的随机数值偏多,小于-2的随机数值偏少
直方图可以直观地展现样本数据的分布情况,不过因为条柱数量的不同导致直方图的效果有很大的差异,因此绘制核密度估计曲线
核密度估计是概率论中用来估计未知的密度函数,属于非参数校验方法之一,可以比较直观地看出数据样本本身的分布特征
双变量分布
sns.jointplot(x,y,data=None,kid=‘scatter’,stat_func=None,color=None,ratio=5,space=0.2,dropna=True)
- kind: 绘制图形的类型 scatter 散点图 ked 核密度图形 hex 二维直方图
- stat_func: 计算有关关系的统计量并标注图
- color: 绘图元素的颜色
- size: 图的边长
- ratio: 中心图与侧边图的比例(整数),值越大,中心图占比越大
- space: 设置中心图与侧边图的间隔大小
df = pd.DataFrame({"x": np.random.randn(500), "y": np.random.randn(500)})
print(df.head())
sns.jointplot(x="x", y="y", data=df, kind="scatter", color="r", size=5, ratio=1, space=0.2)
plt.show()

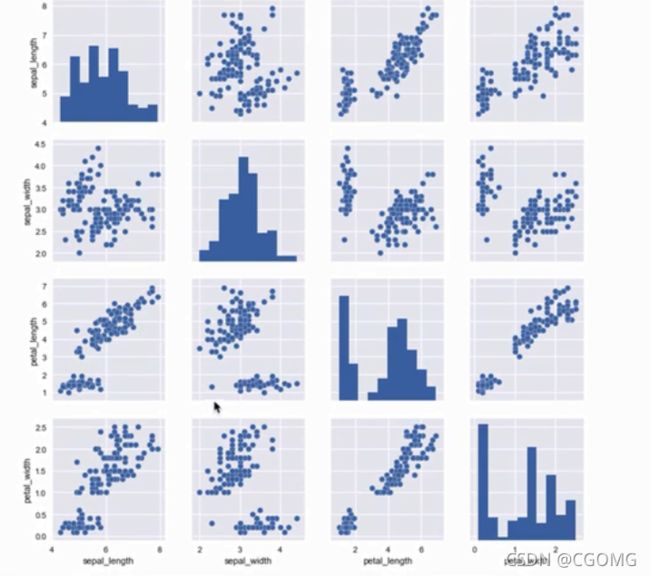
成对双变量分布
# 创建坐标轴矩阵,显示DataFram对象每对变量的关系
dataset = sns.load_dataset('iris')
print(dataset.head())
sns.pairplot(dataset)

用分类数据绘图
数据集中的数据类型有很多种,除了连续的特别变量之外,最常见的就是类别型的数据,如:性别、学历、爱好等,这些数据类型都不能用连续的变量来表示,而是用分类的数据来表示
分类数据散点图:swarmplot() stripplot()
类数据分布图: boxplot() violinplot()
分类数据的统计估算图:barplot() pointplot()
分类数据散点图
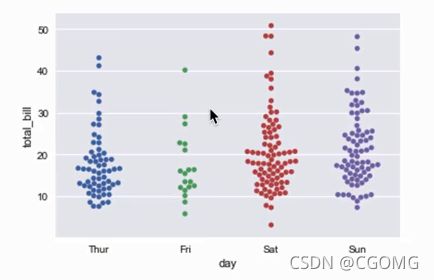
stripplot swarmplot
sns.stripplot(x=None,y=None,hue=None,data=None,order=None,hue_order=None,jitter=False)
- x,y,hue: 用来绘制长格式数据的输入
- data: 用于绘制的数据集。如果x和y不存在,在它作为宽格式,否则作为长格式
- jitter: 抖动的程度(仅沿类别轴)。当很多数据点重叠时,可以指定抖动的数量或者设为True使用默认值
data = sns.load_dataset("tips")
print(data.head())
sns.stripplot(x="day", y='total_bill', data=data, hue="time", jitter=False)
sns.stripplot(x="day", y='total_bill', data=data, hue="time", jitter=True)
sns.swarmplot(x="day", y="total_bill", data=data)



类数据分布图
类别内的数据分布
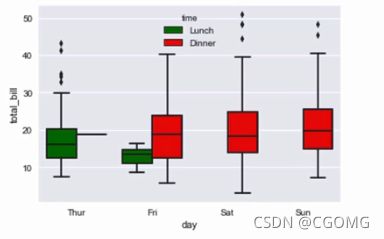
箱形图(boxplot)
又称盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图,
能显示出一组数据的最大值、最小值、中位数、及上下四分位数

boxplot(x=None,y=None,hue=None,data=None,orient=None,color=None,staturation=0.75,width=0.8)
- palette:用于设置不同级别色相的颜色变量 “r”,“g”,“b”,“y”
- staturation:用于设置数据显示的颜色饱和度。 使用小数
sns.boxplot("day","total_bill",data=data,hue="time",palette=['g','r'],saturation=0.9)
小提琴图(violin Plot):
- 用于显示数据分布及其概率密度
- 结合了箱形图和密度图的特征,主要用来显示数据的分布形状
- 中间的黑色粗条表示四分位数范围,从其延伸的幼细黑线代表98%置信区间,而白点则为中位数
- 箱型图在数据显示方面受到限制,简单的设计往往隐藏了有关数据分布的重要细节,例如使用箱型图时,我们不能了解数据分布,虽然小提琴图可以显示更多详情,但他们也可能包含较多干扰信息。

sns.violinplot("day", "total_bill", data=data)

分类数据的统计估算图
查看每个分类的集中趋势,则可以使用条形图和点图进行展示
barplot()函数:绘制条形图
pointplot()函数:绘制点图
条形图:barplot()
barplot函数会在整个数据集上使用均值进行估计。
若每个类别中有多个类别时(使用hue参数),则条形图可以使用引导来计算估计的置信区间(样本统计量所构造的总体参数的估计区间),并使用误差条来表示置信区间
sns.barplot(x='day',y='total_bill',data=data)
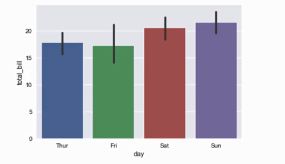
点图:pointplot()
用高度低计值对数据进行描述,而不是显示完整的条形,只会绘制点估计和置信区间
sns.pointplot(x="day",y="total_bill",data=data)

案例:NBA球员数据分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
获取数据
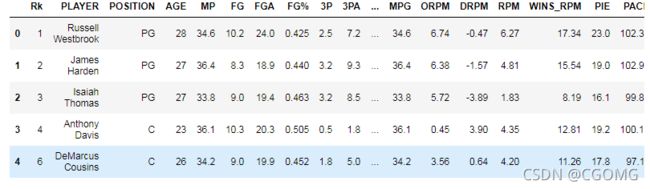
data = pd.read_csv("./nba_2017_nba_players_with_salary.csv")
data.head()

data.shape
(342, 38)
数据相关性
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB',
'AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
data_cor.head()

corr = data_cor.corr()
#获取两列数据之间的相关性
corr.head()

plt.figure(figsize=(20,8))
sns.heatmap(corr,square=True,linewidths=0.1,annot=True)

基本数据排名分析
#按照效率值排名
data.loc[:,['PLAYER','RPM','AGE']].sort_values(by='RPM',ascending=False).head()

按照薪资排名
data.loc[:,["PLAYER","RPM","AGE","SALARY_MILLIONS"]].sort_values(by="SALARY_MILLIONS",ascending=False).head()

Seaborn 常用三个数据可视化方法
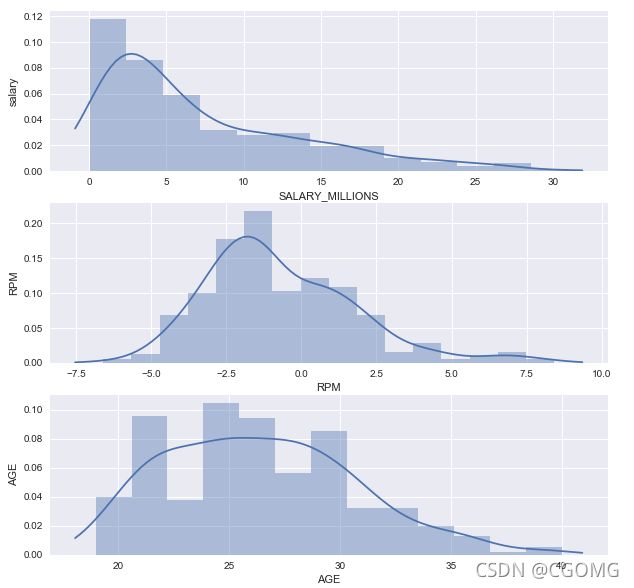
利用seaborn中国displot绘图来分别看球员薪水,效率值,年龄三个信息的分布情况
单变量
sns.set_style("darkgrid")
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
sns.distplot(data['SALARY_MILLIONS'])
plt.ylabel("salary")
plt.subplot(3,1,2)
sns.distplot(data['RPM'])
plt.ylabel("RPM")
plt.subplot(3,1,3)
sns.distplot(data['AGE'])
plt.ylabel("AGE")
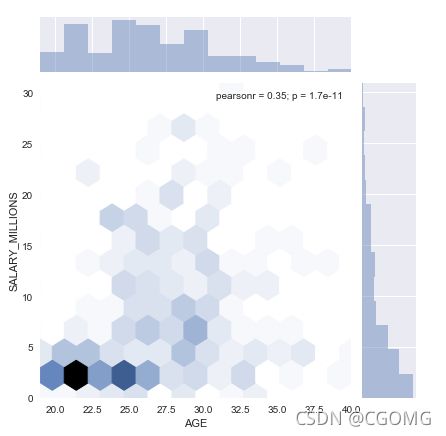
双变量
sns.jointplot(data.AGE,data.SALARY_MILLIONS,kind="hex")
多变量
multi_data = data.loc[:,["RPM","SALARY_MILLIONS","AGE","POINTS"]]
multi_data.head()
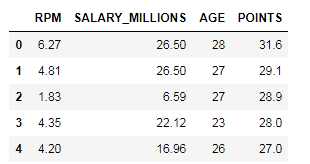
sns.pairplot(multi_data)

衍生变量的一些可视化
def age_cut(df):
if df.AGE <= 24:
return "young"
elif df.AGE >= 30:
return "old"
else:
return "best"
#使用apply对年龄进行划分
data["age_cut"] = data.apply(lambda x:age_cut(x),axis=1)
data.head()
基于年龄段对球员薪水和效率值进行分析
sns.set_style("darkgrid")
plt.figure(figsize=(10,10),dpi=100)
plt.title("RPM and Salary")
x1=data.loc[data.age_cut=="old"].SALARY_MILLIONS
y1=data.loc[data.age_cut=="old"].RPM
plt.plot(x1,y1,"^")
x2=data.loc[data.age_cut=="best"].SALARY_MILLIONS
y2=data.loc[data.age_cut=="best"].RPM
plt.plot(x2,y2,"^")
x3=data.loc[data.age_cut=="young"].SALARY_MILLIONS
y3=data.loc[data.age_cut=="young"].RPM
plt.plot(x3,y3,".")

multi_data2 = data.loc[:,["RPM","POINTS","TRB","AST","STL","BLK","age_cut"]]
sns.pairplot(multi_data2,hue="age_cut")

球队数据分析
data.groupby(by="age_cut").agg({"SALARY_MILLIONS":np.max})

按球队分组,平均薪水降序排列
data_team = data.groupby(by="TEAM").agg({"SALARY_MILLIONS":np.mean})
data_team.sort_values(by="SALARY_MILLIONS",ascending=False).head()

分球队,分年龄段,上榜球员降序排列,上榜球员数量相同,则按效率值降序排列
data_rpm = data.groupby(by=["TEAM","age_cut"]).agg({"SALARY_MILLIONS":np.mean,"RPM":np.mean,"PLAYER":np.size})
data_rpm.head()

data_rpm.sort_values(by=["PLAYER","RPM"],ascending=False).head()

按照球队综合实力排名
data_rpm2 = data.groupby(by=['TEAM'], as_index=False).agg({'SALARY_MILLIONS': np.mean,
'RPM': np.mean,
'PLAYER': np.size,
'POINTS': np.mean,
'eFG%': np.mean,
'MPG': np.mean,
'AGE': np.mean})
data_rpm2.head()

data_rpm2.sort_values(by="RPM",ascending=False).head()

利用箱线图和小提琴图看10个球队的相关数据
data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS']).head()

sns.set_style("whitegrid")
plt.figure(figsize=(20, 10))
# 获取需要的数据
data_team2 = data[data.TEAM.isin(['GS', 'CLE', 'SA', 'LAC', 'OKC', 'UTAH', 'CHA', 'TOR', 'NO', 'BOS'])]
#箱线图
plt.subplot(3,1,1)
sns.boxplot(x="TEAM",y="SALARY_MILLIONS",data=data_team2)
plt.subplot(3,1,2)
sns.boxplot(x="TEAM",y="AGE",data=data_team2)
plt.subplot(3,1,3)
sns.boxplot(x="TEAM",y="MPG",data=data_team2)

#小提琴图
sns.set_style("whitegrid")
plt.figure(figsize=(20, 10))
plt.subplot(3,1,1)
sns.violinplot(x="TEAM",y="3P%",data=data_team2)
plt.subplot(3,1,2)
sns.violinplot(x="TEAM",y="eFG%",data=data_team2)
plt.subplot(3,1,3)
sns.violinplot(x="TEAM",y="POINTS",data=data_team2)

北京租房数据统计分析
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
file_data = pd.read_csv("./链家北京租房数据.csv")
file_data

file_data.shape
(8223, 5)
file_data.info()

file_data.describe()

数据基本处理
重复值和空值处理
file_data = file_data.drop_duplicates()
file_data.shape
(5773, 5)
空值处理
file_data = file_data.dropna()
file_data.shape
(5773, 5)
file_data.head()

数据转换类型
面积数据类型转换
# 创建一个空的数组
data_new = np.array([])
data_area = file_data["面积(㎡)"].values
for i in data_area:
data_new = np.append(data_new, np.array(i[:-2]))
data_area
![]()
data_new
![]()
转换data_new中的数据类型
data_new = data_new.astype(np.float64)
data_new
![]()
file_data.loc[:, "面积(㎡)"] = data_new
file_data.head()

户型表达方式替换
file_data

house_data = file_data["户型"]
temp_list = []
for i in house_data:
# print(i)
new_info = i.replace("房间", "室")
temp_list.append(new_info)
file_data.loc[:, "户型"] = temp_list
file_data

图表分析
房源数量、位置分布分析
file_data["区域"].unique()
![]()
new_df = pd.DataFrame({"区域":file_data["区域"].unique(), "数量":[0]*13})
new_df

# 获取每个区域房源数量
area_count = file_data.groupby(by="区域").count()
new_df["数量"] = area_count.values
new_df.sort_values(by="数量", ascending=False)

户型数量分析
house_data = file_data["户型"]
house_data.head()

def all_house(arr):
key = np.unique(arr)
result = {}
for k in key:
mask = (arr == k)
arr_new = arr[mask]
v = arr_new.size
result[k] = v
return result
house_info = all_house(house_data)
house_info.head(20)

# 去掉统计数量较少的值
house_data = dict((key, value) for key, value in house_info.items() if value > 50)
show_houses = pd.DataFrame({"户型": [x for x in house_data.keys()],
"数量": [x for x in house_data.values()]})
show_houses

# 图形展示房屋类型
house_type = show_houses["户型"]
house_type_num = show_houses["数量"]
plt.barh(range(11), house_type_num)
plt.yticks(range(11), house_type)
plt.xlim(0, 2500)
plt.title("北京市各区域租房数量统计")
plt.xlabel("数量")
plt.ylabel("房屋类型")
# 给每个条上面添加具体数字
for x, y in enumerate(house_type_num):
# print(x, y)
plt.text(y+0.5, x-0.2, "%s" %y)
plt.show()

平均租金分析
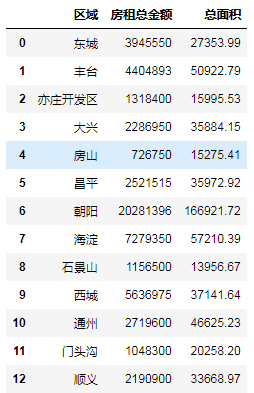
df_all = pd.DataFrame({"区域": file_data["区域"].unique(),
"房租总金额": [0]*13,
"总面积": [0]*13})
df_all

file_data.head()

sum_price = file_data["价格(元/月)"].groupby(file_data["区域"]).sum()
sum_area = file_data["面积(㎡)"].groupby(file_data["区域"]).sum()
df_all["房租总金额"] = sum_price.values
df_all["总面积"] = sum_area.values
df_all
# 计算各个区域每平方米的房租
df_all["每平米租金(元)"] = round(df_all["房租总金额"] / df_all["总面积"], 2)
df_all

df_merge = pd.merge(new_df, df_all)
df_merge

# 图形可视化
num = df_merge["数量"]
price = df_merge["每平米租金(元)"]
lx = df_merge["区域"]
l = [i for i in range(13)]
fig = plt.figure(figsize=(10, 8), dpi=100)
# 显示折线图
ax1 = fig.add_subplot(111)
ax1.plot(l, price, "or-", label="价格")
for i, (_x, _y) in enumerate(zip(l, price)):
plt.text(_x+0.2, _y, price[i])
ax1.set_ylim([0, 160])
ax1.set_ylabel("价格")
plt.legend(loc="upper right")
# 显示条形图
ax2 = ax1.twinx()
plt.bar(l, num, label="数量", alpha=0.2, color="green")
ax2.set_ylabel("数量")
plt.legend(loc="upper left")
plt.xticks(l, lx)
plt.show()

面积基本分析
# 查看房屋的最大面积和最小面积
print('房屋最大面积是%d平米'%(file_data['面积(㎡)'].max()))
print('房屋最小面积是%d平米'%(file_data['面积(㎡)'].min()))
# 查看房租的最高值和最小值
print('房租最高价格为每月%d元'%(file_data['价格(元/月)'].max()))
print('房屋最低价格为每月%d元'%(file_data['价格(元/月)'].min()))
房屋最大面积是1133平米
房屋最小面积是11平米
房租最高价格为每月150000元
房屋最低价格为每月566元
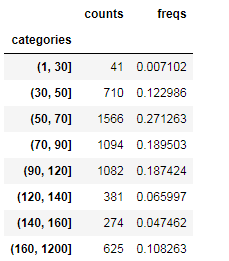
# 面积划分
area_divide = [1, 30, 50, 70, 90, 120, 140, 160, 1200]
area_cut = pd.cut(list(file_data["面积(㎡)"]), area_divide)
area_cut_num = area_cut.describe()
area_cut_num
# 图像可视化
area_per = (area_cut_num["freqs"].values)*100
labels = ['30平米以下', '30-50平米', '50-70平米', '70-90平米',
'90-120平米','120-140平米','140-160平米','160平米以上']
plt.figure(figsize=(20, 8), dpi=100)
# plt.axes(aspect=1)
plt.pie(x=area_per, labels=labels, autopct="%.2f %%")
plt.legend()
plt.show()
