参考:
第二版第三章 - sparkdev blog1
- sparkdev blog2
- Container本质上是host上运行的一个进程。
- Docker通过namespace实现了资源的隔离,通过cgroups实现了资源限制,通过COW(copy-on-write, 写时复制)实现了本地镜像文件的高效处理。
这些技术听起来是一些很“陌生”的,很“高深”的知识。其实不然,我们就用以下的篇幅为docker的核心namespace和cgroups做一个简单的入门介绍和操作。有了这些知识我们甚至可以实现一个简单的容器引擎。
如果让我们自己实现一个容器引擎,怎样实现资源隔离?
- 也许会用
chroot切换根目录的挂载点,实现文件系统的隔离。 - 必须使创建的容器有独立的IP,路由,端口等,即网络的隔离。
- 有独立的主机名,便于在网络中标志自身。
- 有了网络,就想到通信,为了避免主机其他进程的干扰,需要进程间通信的隔离。
- 也应该想到会需要用户权限的隔离。
- 容器中的进程需要有PID,所以肯定需要与Host中PID进行隔离。
namespace
- kernel提供了namespace的机制用来隔离相关资源。namespace设计之初就是为了实现轻量级的系统资源隔离。
- 可以让容器中的进程仿佛置身于一个独立的系统环境中。
| namespace | 系统调用参数 | 隔离内容 |
|---|---|---|
| UTC | CLONE_NEWUTS |
主机名和域名 |
| IPC | CLONE_NEWIPC |
信号量、消息队列和共享内存 |
| PID | CLONE_NEWPID |
进程编号 |
| Network | CLONE_NEWNET |
网络设备、网络栈、端口等 |
| Mount | CLONE_NEWNS |
文件系统 |
| User | CLONE_NEWUSER |
用户和用户组 |
注:网络隔离是相对复杂的内容,这篇博文里将不会展开。请读者自行查阅书中相关章节。
namespace的操作方式
API包括clone(), setns(),unshare以及/proc下的部分文件。通过上表中的6个参数经过位或(|)运算来使用这些API。
1. 通过clone()在创建新进程同时创建namespace
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg)
与namespace相关的四个参数:
-
child_func: 传入子进程运行的程序主函数。 -
child_stack: 传入子进程使用的栈空间。 -
flags: 上述的各个参数。 -
args: 可传入的用户参数。
2. /proc/[pid]/ns文件:本地文件替代namespace
从3.8版本的kernel开始,用户可以在/proc/[pid]/ns下看到指向不同namespace的文件。
# ll /proc/$$/ns
total 0
lrwxrwxrwx. 1 root root 0 Aug 25 00:31 ipc -> ipc:[4026531839]
lrwxrwxrwx. 1 root root 0 Aug 25 00:31 mnt -> mnt:[4026531840]
lrwxrwxrwx. 1 root root 0 Aug 25 00:31 net -> net:[4026531956]
lrwxrwxrwx. 1 root root 0 Aug 25 00:31 pid -> pid:[4026531836]
lrwxrwxrwx. 1 root root 0 Aug 25 00:31 user -> user:[4026531837]
lrwxrwxrwx. 1 root root 0 Aug 25 00:31 uts -> uts:[4026531838]
如果两个进程指向的namespace编号相同,就说明它们在同一个namespace下。
把/proc/[pid]/ns目录下的文件使用--bind方式挂载,可以让本地文件替代对应的namespace。
# touch ~/uts
# mount --bind /proc/27514/ns/uts ~/uts
3. 通过setns()加入一个已经存在的namespace
docker exec就用到了该方法。
int setns(int fd, int nstype);
-
fd: 指向/proc/[pid]/ns目录的文件描述符。 -
nstype: 检查相应的namespace类型是否符合实际要求。
4. unshare
unshare和clone()非常相似,不同点是unshare不创建新进程,直接在原有的进程中操作。
UTS namespace: 主机名和域名的隔离
首先,先写一个程序的骨架。以下代码只是新建一个子进程bash:
#define _GNU_SOURCE
#include
#include
#include
#include
#include
#include
#define STACK_SIZE (1024 * 1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args) {
printf("在子进程中!\n");
execv(child_args[0], child_args);
return 1;
}
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, SIGCHLD, NULL);
waitpid(child_pid, NULL, 0);
printf("程序结束!\n");
return 0;
}
编译并执行:
[root@edward-rhel7-2 cloud-user]# gcc -Wall uts.c -o uts.o && ./uts.o
程序开始:
在子进程中!
[root@edward-rhel7-2 cloud-user]# echo "hello"
hello
[root@edward-rhel7-2 cloud-user]# exit
exit
程序已经退出
我们来修改一下这个骨架。在子进程中加入设置新的hostname,并在clone()中加入uts对应的namespace参数。
....
int child_main(void* args) {
printf("在子进程中!\n");
sethostname("newns", 12);
....
....
int main() {
printf("程序开始: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, ClONE_NEWUTS | SIGCHLD, NULL);
....
再次执行:
[root@edward-rhel7-2 cloud-user]# gcc -Wall uts.c -o uts.o && ./uts.o
程序开始:
在子进程中
[root@newns cloud-user]# exit
exit
程序结束!
可以看到hostname已经变化成我们新设置的newns. exit之后主机名也恢复了。
IPC namespace: 进程间通信的隔离
IPC namespace中实际上包含了系统IPC标志符以及实现POSIX消息队列的文件系统。在同一个IPC namespace下的进程彼此可见,不同IPC namespace下的进程互不可见。
修改utc.c为ipc.c:
....
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
....
编译执行前现在host上创建一个message queue。
root@edward-rhel7-2 cloud-user]# ipcmk -Q
Message queue id: 0
编译并执行:
[root@edward-rhel7-2 cloud-user]# gcc -Wall ipc.c -o ipc.o && ./ipc.o
程序开始:
在子进程中
[root@newns cloud-user]#
在子进程中列出ipc:
root@newns cloud-user]# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
我们可以看到,在host上创建的message queue并没有出现在子进程中,说明ipc的隔离已经成功。退出后再看看host上的ipcs:
[root@newns cloud-user]# exit
exit
程序结束!
[root@edward-rhel7-2 cloud-user]# ipcs
------ Message Queues --------
key msqid owner perms used-bytes messages
0xda10ad1b 0 root 644 0 0
------ Shared Memory Segments --------
key shmid owner perms bytes nattch status
------ Semaphore Arrays --------
key semid owner perms nsems
可以通过ipcrm -q $mq来删除message queue.
PID namespace: PID的隔离
这个机制会对进程的PID重新编号,使得不同的namespace下可以有相同的PID。每个PID都有自己的计数程序。不同的PID namespace是一个层级体系,最顶层的是系统初创时建立的root namespace。父节点可以看到子节点中的进程,并可以通过信号对子节点的进程进行操作。但反过来,子节点不能看到和操作父节点的任何内容。
- 每个namespace下都有第一个进程"PID 1", 会像传统linux中的init进程一样起到特殊的作用。
- 如果在新的PID namespace中重新挂载/proc文件系统,会发现其下只显示同个namespace的其他进程。
- 在root namespace中可以看到所有进程,并且递归包含所有子节点中的进程。
继续修改代码,并命名为pid.c:
....
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
....
编译并执行:
[root@edward-rhel7-2 cloud-user]# gcc -Wall pid.c -o pid.o && ./pid.o
程序开始:
在子进程中
[root@newns cloud-user]# echo $$
1
[root@newns cloud-user]# exit
exit
程序结束!
[root@edward-rhel7-2 cloud-user]# echo $$
21270
可以看到,进入子进程以后当前运行的bash的PID变成了1. 退出后就变回了以前进程的PID。如果在子进程中执行ps/top之类的命令,会发现还可以看到父进程中的PID,这是因为这类命令调用的是host下的/proc中的文件内容。
在unix系统中PID为1的进程(init)需要维护一张进程表,不断检查进程的状态,一旦有子进程因为父进程出错成为“孤儿”进程,init就会负责收养这个子进程并最终回收资源,结束进程。所以在我们实现的容器中,启动的第一个进程也需要实现类似的功能,可以维护后续进程的运行状态。因此,如果需要在container中运行多个进程,最先启动的进程应该具备资源监控和管理能力,例如bash。
现在我们尝试挂载proc文件系统,这样用ps等命令查看时就看不到root namespace下的进程:
[root@edward-rhel7-2 cloud-user]# ./pid.o
程序开始:
在子进程中
[root@newns cloud-user]# mount -t proc proc /proc
[root@newns cloud-user]# ps -a
PID TTY TIME CMD
1 pts/0 00:00:00 bash
13 pts/0 00:00:00 ps
[root@newns cloud-user]# exit
exit
程序结束!
退出程序后,发现ps不工作了。是因为刚才在子进程中没有对文件系统隔离。所以退出之后我们需要重新mount proc,才能让ps继续工作。
[root@edward-rhel7-2 cloud-user]# ps
Error, do this: mount -t proc proc /proc
[root@edward-rhel7-2 cloud-user]# mount -t proc proc /proc
[root@edward-rhel7-2 cloud-user]# ps
PID TTY TIME CMD
21267 pts/0 00:00:00 sudo
21269 pts/0 00:00:00 su
21270 pts/0 00:00:00 bash
21543 pts/0 00:00:00 vim
21626 pts/0 00:00:00 ps
mount namespace:文件系统的隔离
通过隔离文件系统挂载点对隔离文件系统提供支持,是历史上第一个支持的namespace,所以名字比较特殊CLONE_NEWNS
-
/proc/[pid]/mounts查看挂载在当前namespace的文件系统。 -
/proc/[pid]/mountstats查看文件设备的统计信息。
我们再来修改代码,并且尝试修复上一节中mount损坏的问题:
int child_pid = clone(child_main, child_stack+STACK_SIZE,
CLONE_NEWNS | CLONE_NEWPID | CLONE_NEWIPC | CLONE_NEWUTS | SIGCHLD, NULL);
在host上/proc由于被子进程损坏了mount的信息,所以我们现在host上挂载好proc。
[root@edward-rhel7-2 cloud-user]# mount --make-private -t proc proc /proc
由于历史原因,mount namespace分为很多种类型。比较复杂,这里就不展开说了,详细请参阅文档。注意,这里必须指定挂载类型为private。
然后编译执行:
[root@edward-rhel7-2 cloud-user]# gcc -Wall mount.c -o mount.o && ./mount.o
程序开始:
在子进程中
[root@newns cloud-user]# ps
PID TTY TIME CMD
23977 pts/0 00:00:00 sudo
23979 pts/0 00:00:00 su
23980 pts/0 00:00:00 bash
24120 pts/0 00:00:00 mount.o
24121 pts/0 00:00:00 bash
24132 pts/0 00:00:00 ps
[root@newns cloud-user]# mount -t proc proc /proc
[root@newns cloud-user]# ps
PID TTY TIME CMD
1 pts/0 00:00:00 bash
14 pts/0 00:00:00 ps
[root@newns cloud-user]# exit
exit
程序结束!
[root@edward-rhel7-2 cloud-user]# ps
PID TTY TIME CMD
23977 pts/0 00:00:00 sudo
23979 pts/0 00:00:00 su
23980 pts/0 00:00:00 bash
24135 pts/0 00:00:00 ps
user namespace: 隔离用户,用户组,root目录,秘钥等
user namespace是最晚实现的namespace, 所以有些内核可能还没有支持。check的方法:
[root@edward-rhel7-2 cloud-user]# cat /boot/config-* | grep -i "user_ns"
CONFIG_USER_NS=y
如果是y,那就恭喜,如果不是,就需要重新编译内核。此外,还需要检查系统允许创建的新user namespace的数量,我用的是rhel7.6,默认是0,所以需要修改:
[root@edward-rhel7-2 cloud-user]# echo 23137 > /proc/sys/user/max_user_namespaces
user namespace不同的地方是,新创建的namespace用户/用户组必须要与外部的namespace用户/用户组映射。如果不建立映射关系,新namespace的用户将会再外部没有任何权限。这将导致此用户无法操作外部namespace的文件,因为操作系统无法检验它的权限。映射关系可以用下图表示:
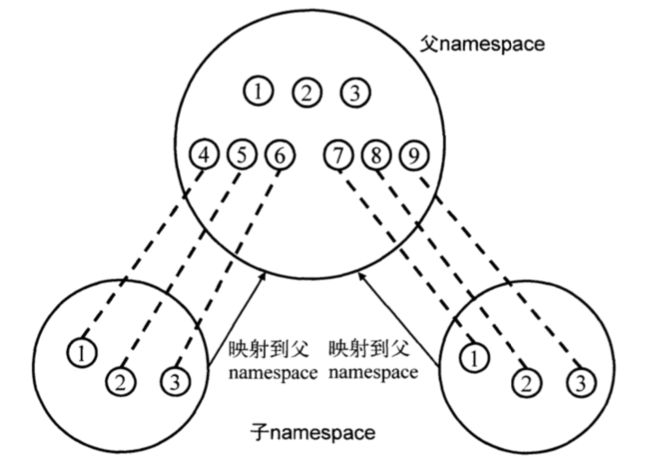
鉴于user namespace相对来说复杂一点,如果改代码会比较繁琐。这里我们用unshare的方式介绍user namespace。
通过option--user来创建新的user namespace:
[cloud-user@edward-rhel7-2 ~]# unshare --user /bin/bash
/usr/bin/id: cannot find name for group ID 65534
/usr/bin/id: cannot find name for user ID 65534
[I have no name!@edward-rhel7-2 ~]$ id
uid=65534 gid=65534 groups=65534 context=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
因为没有映射的关系,系统找不到它的映射关系,会自动帮它映射到/proc/sys/kernel/overflowuid,也就是65534。
接下来我们把这个新的用户映射到外部的namespace中。映射 ID 的方法就是让外部user namespace的用户添加映射信息到 /proc/$PID/uid_map 和 /proc/$PID/gid_map (这里的 PID 是新 user namespace 中的进程 ID)文件中。配置的格式如下:
ID-inside-ns ID-outside-ns length
比如0 1000 1就是把外部user namespace的用户1000映射到内部namespace的root用户。length等于1表示只映射一个用户。
先来查看当前进程的pid:
[I have no name!@edward-rhel7-2 ~]$ echo $$
25432
我们再打开一个新的terminal查看两个map文件的属性:
[cloud-user@edward-rhel7-2 ~]$ ll /proc/25432/uid_map /proc/25432/gid_map
-rw-r--r--. 1 cloud-user cloud-user 0 Aug 26 03:52 /proc/25432/gid_map
-rw-r--r--. 1 cloud-user cloud-user 0 Aug 26 03:52 /proc/25432/uid_map
可以看到两个文件的owner都是cloud-user。接下来我们尝试写入映射信息:
[cloud-user@edward-rhel7-2 ~]$ echo '0 1000 1' > /proc/25432/uid_map
-bash: echo: write error: Operation not permitted
[cloud-user@edward-rhel7-2 ~]$ echo '0 1000 1' > /proc/25432/gid_map
-bash: echo: write error: Operation not permitted
因为这个bash进程没有相应的capabilities,重新设置capabilities,并且重新加载bash:
[cloud-user@edward-rhel7-2 ~]$ sudo setcap cap_setgid,cap_setuid+ep /bin/bash
[cloud-user@edward-rhel7-2 ~]$ cat /proc/$$/status | egrep 'Cap(Inh|Prm|Eff)'
CapInh: 0000000000000000
CapPrm: 0000000000000000
CapEff: 0000000000000000
[cloud-user@edward-rhel7-2 ~]$ exec bash
[cloud-user@edward-rhel7-2 ~]$ cat /proc/$$/status | egrep 'Cap(Inh|Prm|Eff)'
CapInh: 0000000000000000
CapPrm: 00000000000000c0
CapEff: 00000000000000c0
写入映射信息:
[cloud-user@edward-rhel7-2 ~]$ echo '0 1000 1' > /proc/25432/uid_map
[cloud-user@edward-rhel7-2 ~]$ echo '0 1000 1' > /proc/25432/gid_map
现在我们回到第一个terminal,重新加载bash:
[I have no name!@edward-rhel7-2 ~]$ exec bash
[root@edward-rhel7-2 ~]#
再试试查看host的/root目录和系统信息:
[root@edward-rhel7-2 ~]# ll /root
ls: cannot open directory /root: Permission denied
[root@edward-rhel7-2 ~]# hostnamectl
[root@edward-rhel7-2 ~]# echo $?
1
可以看到映射已经成功了。在新的namespace里root用户并没有权限操作外部namespace里root的内容。
namespace相关的内容就先告一段落,我们再来看看cgroups。
cgroups
从字面上理解,cgroups就是把任务放到一个组里面统一加以控制。怎么控制呢?就是限制、记录任务组所使用的物理资源,包括CPU、Memory、IO等。
本质上来说,cgroups是内核附加在程序上的一系列hook,通过程序运行时对资源的调度触发相应的钩子以达到资源跟踪和限制的目的。
在cgroup里,任务(task)就是系统的一个进程或者线程。
cgroups的四大作用:
- 资源限制: 比如设定任务内存使用的上限。
- 优先级分配: 比如给任务分配CPU的时间片数量和磁盘IO的带宽大小来控制任务运行的优先级。
- 资源统计:比如统计CPU的使用时长、内存用量等。这个功能非常适用于计费。
- 任务控制:cgroups可以对任务执行挂起、恢复等操作。
cgroups以操作文件的方式作为API。它的操作目录是/sys/fs/cgroup。我们来看看这个目录下有什么内容:
[root@edward-rhel7-2 cloud-user]# ls /sys/fs/cgroup
blkio cpu cpuacct cpu,cpuacct cpuset devices freezer hugetlb memory net_cls net_cls,net_prio net_prio perf_event pids systemd
除了systemd这个文件夹,其他的都是子系统(sub system)。子系统就是资源调度器。比如CPU子系统可以控制CPU的时间分配,memory子系统可以限制内存的使用量。我们以memory这个子系统为例,
[root@edward-rhel7-2 cloud-user]# ls -l /sys/fs/cgroup/memory/
total 0
-rw-r--r--. 1 root root 0 Aug 24 03:03 cgroup.clone_children
--w--w--w-. 1 root root 0 Aug 24 03:03 cgroup.event_control
-rw-r--r--. 1 root root 0 Aug 24 03:03 cgroup.procs
-r--r--r--. 1 root root 0 Aug 24 03:03 cgroup.sane_behavior
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.failcnt
--w-------. 1 root root 0 Aug 24 03:03 memory.force_empty
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.failcnt
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.limit_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.max_usage_in_bytes
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.slabinfo
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.tcp.failcnt
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.tcp.limit_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.tcp.max_usage_in_bytes
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.tcp.usage_in_bytes
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.kmem.usage_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.limit_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.max_usage_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.memsw.failcnt
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.memsw.limit_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.memsw.max_usage_in_bytes
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.memsw.usage_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.move_charge_at_immigrate
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.numa_stat
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.oom_control
----------. 1 root root 0 Aug 24 03:03 memory.pressure_level
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.soft_limit_in_bytes
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.stat
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.swappiness
-r--r--r--. 1 root root 0 Aug 24 03:03 memory.usage_in_bytes
-rw-r--r--. 1 root root 0 Aug 24 03:03 memory.use_hierarchy
-rw-r--r--. 1 root root 0 Aug 24 03:03 notify_on_release
-rw-r--r--. 1 root root 0 Aug 24 03:03 release_agent
drwxr-xr-x. 64 root root 0 Aug 27 02:03 system.slice
-rw-r--r--. 1 root root 0 Aug 24 03:03 tasks
drwxr-xr-x. 2 root root 0 Aug 26 06:42 user.slice
memory.limit_in_bytes 中的数字用来限制进程的最大可用内存,memory.swappiness 中保存着使用 swap 的权重。
接下来我们看看cgroups怎么使用(操作文件)。我们以cpu子系统做一个例子。
在/sys/fs/cgroup/cpu这个目录下新建一个目录,让我们惊讶的是创建新文件夹之后会有很多新的文件一起被创建:
[root@edward-rhel7-2 cpu]# ll example/
total 0
-rw-r--r--. 1 root root 0 Aug 27 02:34 cgroup.clone_children
--w--w--w-. 1 root root 0 Aug 27 02:34 cgroup.event_control
-rw-r--r--. 1 root root 0 Aug 27 02:34 cgroup.procs
-r--r--r--. 1 root root 0 Aug 27 02:34 cpuacct.stat
-rw-r--r--. 1 root root 0 Aug 27 02:34 cpuacct.usage
-r--r--r--. 1 root root 0 Aug 27 02:34 cpuacct.usage_percpu
-rw-r--r--. 1 root root 0 Aug 27 02:34 cpu.cfs_period_us
-rw-r--r--. 1 root root 0 Aug 27 02:34 cpu.cfs_quota_us
-rw-r--r--. 1 root root 0 Aug 27 02:34 cpu.rt_period_us
-rw-r--r--. 1 root root 0 Aug 27 02:34 cpu.rt_runtime_us
-rw-r--r--. 1 root root 0 Aug 27 02:34 cpu.shares
-r--r--r--. 1 root root 0 Aug 27 02:34 cpu.stat
-rw-r--r--. 1 root root 0 Aug 27 02:34 notify_on_release
-rw-r--r--. 1 root root 0 Aug 27 02:34 tasks
通过下面的设置把CPU周期限制为总量的十分之一:
[root@edward-rhel7-2 cpu]# echo 100000 > example/cpu.cfs_period_us
[root@edward-rhel7-2 cpu]# echo 10000 > example/cpu.cfs_quota_us
其实docker run的两个options--cpu-period --cpu-quota就是由它们实现的。
我们先创建一个CPU密集型的程序:
void main()
{
unsigned int i, end;
end = 1024 * 1024 * 1024;
for(i = 0; i < end; )
{
i ++;
}
}
编译之后,并比较一般执行和在cgroup限制下执行的结果差异:
[root@edward-rhel7-2 cloud-user]# gcc cputime.c -o cputime
[root@edward-rhel7-2 cloud-user]# time ./cputime
real 0m2.546s
user 0m2.543s
sys 0m0.001s
[root@edward-rhel7-2 cloud-user]# time cgexec -g cpu:example ./cputime
real 0m25.695s
user 0m2.577s
sys 0m0.007s
可以看到,执行时间明显变慢,大概是没有限制的情形下的十倍。
好,我们的讲解到此为止。这些内容都是入门知识,但可以很好的给我们一个指引,同时也为我们理解使用容器技术提供了一个全新的角度,遇到问题的时候可以更深层次的去debug。