Python的安装环境
python动态类型的解释性语言,被称作“胶水语言”,因为它能够轻易地操作其他程序,轻易地包装使用其他语言编写的库。
我们安装Python(3.7.1)和Pycharm两款软件。
Python是解释器,Pycharm是编辑器。PyCharm是一种Python IDE,其带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如, 调试、语法高亮、Project管理、代码跳转、智能提示、自动完成、单元测试、版本控 制等等。在pycharm中编写Python程序,最终还是要有Python解释器的支持, 两者配合工作。
Python中判断
- if else
结构格式:
if 要判断的条件:
满足条件时要执行的事情
else:
不满足条件时要执行的事情
案例(判断一个人的年龄):
#判断一个人的年龄
age=input('请输入您的年龄')
#type(age)判断变量的数据类型
#数据类型转换
#内置函数int()
age=int(age)
if age>=18:
print('恭喜您成年了,可以去网吧了')
else:
print('对不起,你还是个宝宝')
运行结果:

- elif
代替C语言中的switch语句,elif和if必须共同使用。
结构格式:
if xxx1:
执行xxx1
elif xxx2:
执行xxx2
elif xxx3:
执行xxx3
else:
以上都不满足要执行的事情
案例(考试分数对应的等级):
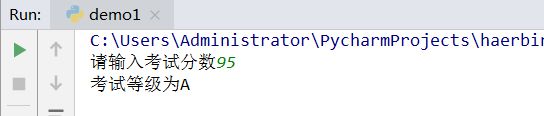
score=input('请输入考试分数')
score=int(score)
if score>=90 and score<=100:
print('考试等级为A')
elif score <90 and score >=80:
print('考试等级为B')
elif score <80 and score >=70:
print('考试等级为C')
elif score <70 and score >=60:
print('考试等级为D')
elif score < 60:
print('考试等级为不及格')
运行结果:
Python中循环
- while循环
结构格式:
while 循环条件:
循环体
死循环如下表示:
while True:
循环体
案例:
i=0
while i<5:
print(i)
i+=1
- for循环
在java和c中我们学到的for结构格式为:
for (int i=0;i<100;i++){
循环体
}
在Python中,结构格式为:
for 临时变量 in 可迭代对象(比如字符串,列表,元祖等):
循环体
案例1(依次输出字符串):
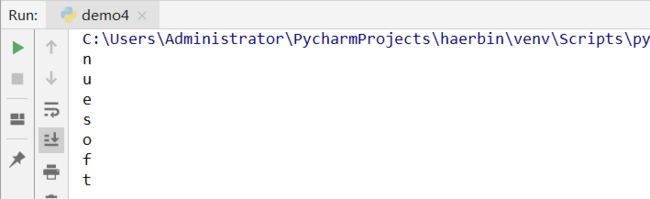
company='nuesoft'
for i in company:
print(i)
输出结果:
案例2(输出偶数):
range的用法:
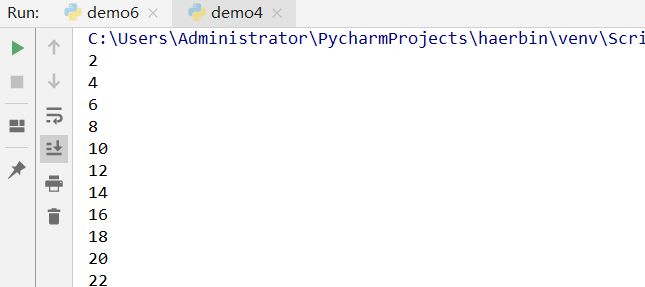
range(起始值,终止值,步长)
for i in range(2,101,2):
print(i)
运行结果:
案例3(打印99乘法表):
for i in range(1,10):
for j in range(1,i+1):
print(j,'X',i,'=',i*j,' ',end='')
print (end='\n')
运行结果:

- 生成随机整数
结构格式:
from random import randint
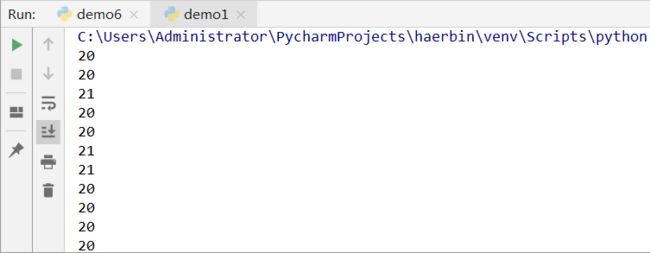
案例(不断生成20到21的随机整数):
from random import randint
while True:
print(randint(20,21))
运行结果:
·break/continue
break 跳出本层循环
案例(输出偶数合):
i=1
sum_num=0
while i<=100:
if i%2==0:
i += 1
continue
sum_num += i
i += 1
print(sum_num)
输出结果:

continue跳出本次循环,继续执行下一循环
案例(计算 累加和大于1000 就跳出循环):
i = 1
sum_num = 0
while i <= 100:
sum_num += i
if sum_num > 1000:
break
i += 1
print(sum_num)
运行结果:

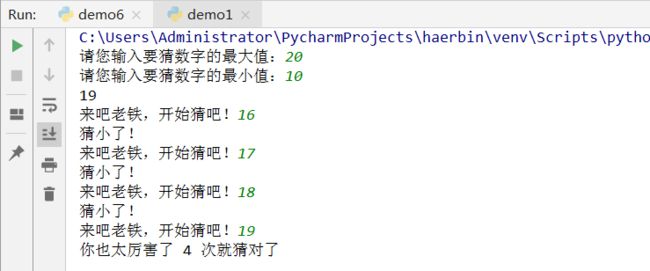
案例(猜数字游戏):
该游戏规则为:
玩家在控制台中输入要猜数字的范围
接下来玩家输入要猜的数字
要明确告诉玩家猜大了还是猜小了
如果猜对了告诉玩家: 一次猜中:这是高手
2-5次猜中,你也太厉害了i次就猜中了
5次以上,洗洗睡吧,i次才猜中
count=0
while True:
count+=1
guess_num=int(input('来吧老铁,开始猜吧!'))
if guess_numcomputer_num:
print('猜大了!')
else:
if count==1:
print('这是高手!')
elif count>=2 and count<=5:
print('你也太厉害了',count,'次就猜对了')
else:
print('洗洗睡吧',count,'次才猜对')
break
运行结果:
python 中常用数据类型
- 列表 list
它和我们学的C中的数组很像,与数组不一样的地方是可以存储不同种类的数据(灵活)。
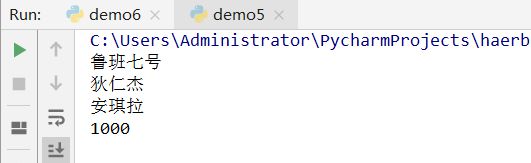
案例(创建列表):
hero_name=['鲁班七号','狄仁杰','安琪拉',1000]
print(hero_name)
运行结果:

案例(遍历列表):
hero_name=['鲁班七号','狄仁杰','安琪拉',1000]
for hero in hero_name:
print(hero)
运行结果:
- 关于列表的常见操作:
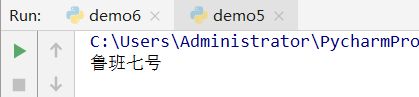
1、访问
结构格式:
hero_name[索引值]
hero_name=['鲁班七号','狄仁杰','安琪拉',1000]
print(hero_name[0])
运行结果:
2、修改
案例:
hero_name=['鲁班七号','狄仁杰','安琪拉',1000]
hero_name[3]='后羿'
print('修改后的列表',hero_name)
运行结果:

3、增加
append用来在末尾增加元素
案例:
hero_name=['鲁班七号','狄仁杰','安琪拉',1000]
hero_name.append('黄忠')
print('增加后的列表',hero_name)
运行结果:

4、删除
del用来删除列表元素
案例:
hero_name=['鲁班七号','狄仁杰','安琪拉',1000]
del hero_name[0]
print('删除后的列表',hero_name)
运行结果:

5、列表推导式(详细的在明天的内容里)
案例(生成1、2、3、、、20的列表):
li=[]
for x in range(1,21):
li.append(x)
print(li)
- 字符串string
1、如何把列表变成字符串
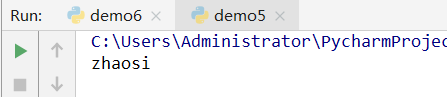
案例1:
name=['z','h','a','o','s','i']
str_name=''.join(name)
print(str_name)
运行结果:
如果想在各个字符中加‘\’应该怎么做呢?请看案例2。
案例2:
name=['z','h','a','o','s','i']
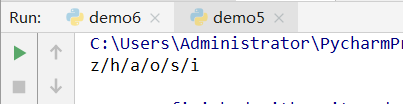
str_name='/'.join(name)
print(str_name)
运行结果:
2、去空格
案例:
name2=' nuesoft '
print(len(name2))#len 判断变量中元素个数
name2=name2.strip()
print('去空格之后的长度',len(name2))
运行结果:
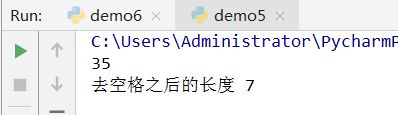
从输出的字符长度来看,我们知道空格消除了。
3、替换
replace,用一个字符代替另一个字符
案例(美元符号换成人民币符号):
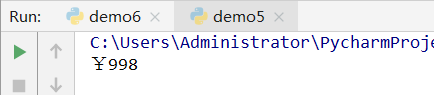
price='$998'
price=price.replace('$','¥')
print(price)
运行结果:
- 数字
数字与c和java相类似 - 元组
tuple,与列表相似,但不支持修改
1、访问
案例:
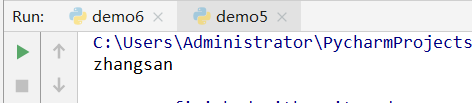
a=('zhangsan','lisi',1000)
print(a[0])
运行结果:
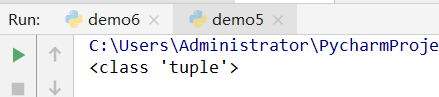
2、类型
案例:
a=('zhangsan','lisi',1000)
print(type(a))
运行结果:
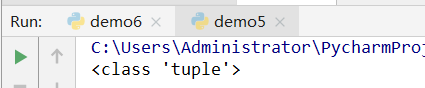
3、表示只有一个元素的元组
案例:
b=(1000,)
print(type(b))
运行结果:
- 字典
以键值对形式存储的数结构 key----value
1、创建字典
案例:
info={'name':'刘强东','age':45,'addr':'北京市朝阳区'}
print(info)
print(len(info))
运行结果:

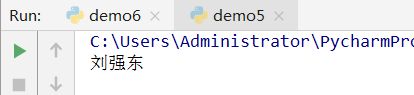
2、访问
案例:
info={'name':'刘强东','age':45,'addr':'北京市朝阳区'}
print(info['name'])
运行结果:
3、修改
案例:
info={'name':'刘强东','age':45,'addr':'北京市朝阳区'}
info['age']=55
print('修改后字典的值',info)
运行结果:

4、增加
如果键不存在则为增加操作
案例:
info={'name':'刘强东','age':45,'addr':'北京市朝阳区'}
info['sex']='female'
print('增加后字典的值',info)
运行结果:

5、删除
案例:
info={'name':'刘强东','age':45,'addr':'北京市朝阳区'}
del info['addr']
print('删除后字典的值',info)
运行结果:

6、获取字典中所有的键
print(info.keys())
7、获取字典中所有的值
print(info.values())
8、获取字典中所有的值
print(info.items())
运行结果(6、7、8):

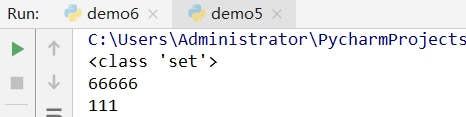
- 集合
集合无序,里面的元素不重复
set1={111,66666}
print(type(set1))
for x in set1:
print(x)
运行结果:
总结:列表[] 字符串'' 元组() 字典{} 集合
数据类型+判断循环是解决问题的工具
中文分词
借助中文分词工具进行分词
jieba 结巴
安装Python第三方工具包
pip install 包名
在用户目录下新建pip文件夹
新建pip.ini文件,输入:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
在pycharm中terminal输入pip install jieba
即导入成功
案例1:
import jieba
txt='我来到北京清华大学'
#精确分词模式 nlp自然语言处理
seg_list=jieba.lcut(txt)
print(seg_list)
运行结果:

案例2:
import jieba
txt='我来到北京清华大学'
#搜索引擎模式,先执行精确模式,然后再对长词进行分析
seg_list2 = jieba.lcut_for_search(txt)
print(seg_list2)
运行结果:

今天就到这里了,明日更新。