深度强化学习入门
面向序列分析的代表性学习策略——深度强化学习
(代表性研究机构:阿尔伯特大学、deepMind,openAI、伯克利大学)
传统序列学习策略的不足:

强化学习的通用框架:learn by interacting with our environment
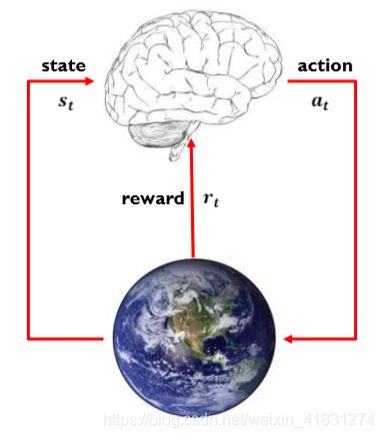
强化学习区别于其他机器学习策略最重要的四大特质:
动态地影响;
持续地交互;
稀疏的标注;
延迟的反馈
强化学习基本概念
强化学习的形式化描述——Markov Decision Processes-某状态的未来奖励与之前的历史无关
强化学习的前提条件:
1)满足马尔可夫决策过程的性质;
2)存在最优解;
3)环境的潜在规律/模型是固定不变的
状态(state):只能主体(agent)某时刻对环境的观测值
行为(action):交互过程中每时刻
奖励(rewards):交互过程中每时刻获得的回馈
观测序列/样本/经验(trajectory):
策略(policy):输入当前的状态s,输出采取的动作a的函数
状态价值(value)/未来奖励:某个状态s开始,采用策略 π \pi π,得到的完整序列/交互过程的各时刻奖励的累加和的期望值
间接优化:Deep Q-Learning算法
例_房间逃离问题:假设一栋建筑里有五个房间,房间之间通过门相连。将其按照0-4进行编号,建筑外面可以看作一个大房间,编号为5.
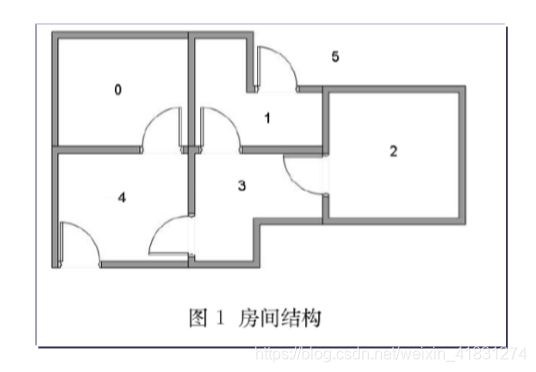
问题:假定现在agent处于2号房间/状态,希望它通过学习到达5号房间。或者求解从任何房间到达5号房间/逃离出去的最佳策略。
解决方法:价值迭代方法
步骤1:以状态state为行,行为action为列,构建一个关于rewards的奖励矩阵R,其中-1表示没有边相连

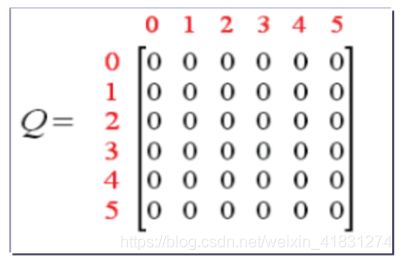
步骤2:再构建一个价值矩阵Q,用于记录agent从经验中学到的知识,矩阵Q和R是同阶的,以状态state为行,以行为action为列。
步骤3:初始化Q矩阵为0矩阵。(对于状态数目未知的情况,可以每发现一个新状态,就在Q中增加相应的行列)
步骤4:根据价值迭代算法的状态-动作价值更新规则,agent不断进行学习,在各个状态之间进行转移和搜索,直至到达目标。(每一轮完整的探索称为一个episode)
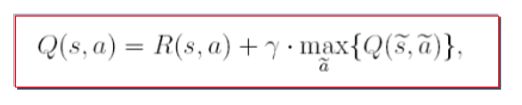
步骤5:策略生成。根据最终的状态-动作价值表,就学到了各状态下到达目标状态的最佳路径、策略。
pseudo:

示例代码:
import torch
import numpy as np
import random
def q_learning():
reward=torch.tensor([[-1,-1,-1,-1,0,-1],[-1,-1,-1,0,-1,100],[-1,-1,-1,0,-1,-1],[-1,0,0,-1,0,-1],[0,-1,-1,0,-1,100],[-1,0,-1,-1,0,100]])
q=torch.zeros(6,6)
gamma=0.8
episode=1000
for i in range(episode):
print("episode:{}".format(i))
s=np.random.randint(0,6)
while(True):
print("状态:{}".format(s))
actions=[]
for j in range(6):
if(reward[s][j].item() is not -1):
# print(reward[s][j].item())
actions.append(j)
# print(actions)
if(actions is not []):
action=np.random.choice(np.array(actions),1)
# print(action[0])
s_=action[0]
max_q=-2
for k in range(6):
# print(q[s_][k])
max_q=max(max_q,q[s_][k].item())
# print(max_q)
Q_sa=torch.zeros(6,6)
Q_sa.copy_(q)
# print(Q_sa)
Q_sa[s][s_]=reward[s][s_].item()+gamma*max_q
# print(q)
s=s_
# print(Q_sa)
if(torch.equal(Q_sa,q)):
# print(Q_sa)
break
q.copy_(Q_sa)
# break
# break
print(q)
if __name__=="__main__":
q_learning()
Deep Q-Learning Network
当面对几乎无尽的状态空间时,基于有限的纬度表格的穷举搜索算法失效。因此,我们可以使用深度网络来学习更为复杂的价值函数。

直接优化:Policy Gradients算法
尽管DQL系列方法对Q(s,a)值近似估计进行了大量的改进和优化,但当状态s太多变化时,(s,a)有接近无穷多种组合,对应的Q(s,a)值也有无穷多种可能,即使采用深度网络页非常难以准确拟合。
能否直接学习S——>a的映射函数呢?
策略梯度(Policy Gradients) 的基本思想是:通过评价动作action的好坏,来直接调整action的出现概率
PG_based RL in PONG:
step 1:随机初始化策略网络的两层权重
step 2:尝试玩100局完整的Pong游戏/Policy rollouts
step 3:对所有最终胜利的episodes中的动作进行权重增强/增大执行该动作的概率;反之,对所有最终失败的episodes中的动作进行权重削减/减少执行该动作的概率
step 4:再使用更新的策略网络玩新的100局,反复迭代直至收敛。
为什么说Policy Gradient方法具有较大的variance,需要引入baseline/advantage来控制?
==回答:==因为Policy Gradient方法通过有限抽样来逼近统计概率,训练中使用每一个样本序列的最终得分来提升/降低序列中所有动作的概率。在样本数无穷大的时候/大数定理,这种近似是合理的。但是在样本不够大的时候,这样不加区分的加权会导致严重的credit assignment问题(序列中不够好的动作也被增强了)。因此,引入baseline,就相当于对序列中每个action进行了更准确的判断:若执行动作a后的累计奖励还不如不执行/不如平均值,则此动作a即使在成功序列中,也不能被鼓励!
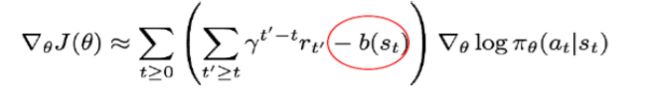
Actor-Critic Algorithm:
考虑到:如果在状态s下采用动作a,其值能够远远大于采取所有动作的期望值,则这个动作很重要!更应该被加强!因此引入基于Advantage reward的Actor-Critic Algorithm。

RL两大类算法的本质区别(Policy Gradient & Q-Learning)
1.Q-learning是一种基于值函数估计的强化学习方法,Policy Gradient是一种策略搜索强化学习方法。前者可类比Naive Bayes——通过后验概率来间接预测,后者可类比SVM——不估计后验概率而直接优化学习目标。
2.理论上:Q-Learning在离散状态空间理论上可以收敛到最优策略,但收敛速度可能极慢,在使用函数逼近后则不一定;Policy Gradient使用梯度方法求解非凸目标,只收敛到不动点,不能证明收敛到最优策略。
3.应用上:Q-Learning 等基于值函数的方法存在策略退化问题,即值函数估计已经很准确了,但通过值函数得到的策略仍然不是最优。本质在于策略的间接优化,且价值的轻微扰动可能会大幅度修改策略;Policy Gradient不会出现策略退化现象,其目标表达更直接,求解方法更现代,还能够直接求解stochastic policy等等优点更加实用。
4.Actor-Critic就是在求解策略的同时用值函数进行辅助,用估计的值函数替代采样的reward,提高样本利用率。