Kubernetes 笔记 -- Kubernetes 监控 & 调试
文章目录
-
-
- 一. Kubernetes 监控
-
- 1.1 Metrics Server
- 1.2 Prometheus
- 二. Debug/Logging/TroubleShooting
-
- 2.1 Debug Pod/Service
- 2.2 网络调试
- 2.3 集群组件排错
-
一. Kubernetes 监控
1.1 Metrics Server
Metrics Server 是 Kubernetes 提供的监控工具,主要用来收集 Node 和 Pod 的 CPU、内存使用情况。其本质就是通过 kube-aggregator 实现的一个 server。
图片来自 https://www.jetstack.io/blog/resource-and-custom-metrics-hpa-v2/
Kubelet 内置了 cAdvisor 服务运行在每个节点上收集容器的各种资源信息,并对外提供了 API 来查询这些信息。Metric Server 正是访问 Kubelet 提供的 /stats/summary API 来获取监控数据,只要有这个 API 其实我们完全可以自行实现一个 Kubernetes 指标收集工具。
可以通过下面命令安装 MetricServer
$ kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
安装完成后就可以通过 kubectl top 命令查看 Pod 和 Node 的资源使用信息了。
$ kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
tk01 217m 10% 5296Mi 68%
vm-0-2-ubuntu 84m 4% 1189Mi 32%
$ kubectl top pods --all-namespaces
NAMESPACE NAME CPU(cores) MEMORY(bytes)
kube-system coredns-f9fd979d6-jzv8q 4m 10Mi
kube-system coredns-f9fd979d6-tx9m4 4m 10Mi
kube-system etcd-tk01 14m 50Mi
kube-system kube-apiserver-tk01 31m 293Mi
1.2 Prometheus
Prometheus 是 CNCF 的第二个毕业项目,目前已经是 Kubernetes 监控方面的事实标准。其架构如图:
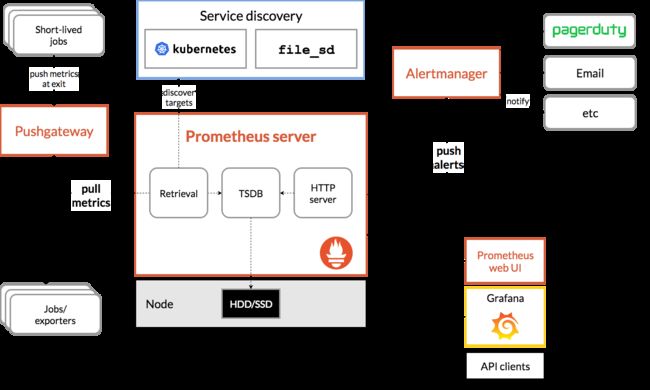
其提供了若干组件来完成数据的收集、存储、展示与告警等:
-
数据收集组件:Prometheus 采用 pull 的模式定期从各个目标收集数据。对于应用指标收集,应用只需要提供一个类似
/metrics接口供 Prometheus 访问即可,对于中间件、系统的监控,由官方和社区维护了一系列的 Exporter 来实现数据的收集。对于某些短时任务可以通过 pushGateway 来实现,先将任务的指标收集到 gateway,在被 pull 到 Prometheus 。 -
Prometheus Server: 存储数据,Prometheus 内置的时序数据库,也可以使用外部的 InfluxDB 等其他存储。关于数据的存储原理可以看之前皓哥的分享 技术分享:Prometheus是怎么存储数据的(陈皓)。
-
AlertManager: 告警组件,可以根据一系列规则实现及时的告警。
-
数据展示组件:Prometheus 本身提供了 API 供外部查询各种指标,同时也内置了 UI 界面实现可视化查询与展示,另外比较常用的是结合 Grafana 实现数据的可视化。
这里只对 Prometheus 监控 Kubernetes 做一个简单的 demo,其监控架构如图,从 Kubernetes 组件、节点以及各种中间件中收集数据并存储,然后经由 Grafana 展示并提供给 AlertManager 展示。当然还可以使用 remote_write 配置将指标发送到指定的地方根据需要做进一步的清洗、存储、查询。
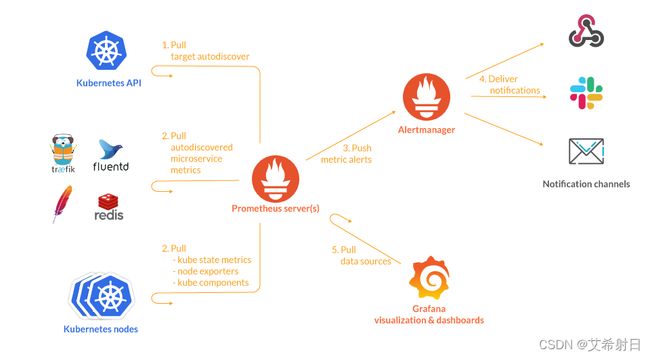
就 Kuberetes 而言,其监控数据分为三种:
- 主机指标:Kubernetes 各个宿主机节点的指标,由 Node Exporter 提供。
- 组件指标:Kuberetes 各个组件的指标,比如 api-server、kubelet 等组件的指标,这个由各个组件的 /metrics API 提供。
- 核心指标: Kubernetes 中各种资源对象的数据,比如 Pod 、Node、容器的各种指标,NameSpace、Deployment 、Service 等各种资源的信息。
下面是部署 Prometheus 并查看监控的一个示例,目前在 Kuberetes 中有三种方式安装 Prometheus:
- Prometheus-operator
- 社区提供的 Helm Chart
- Kube-prometheus
这里我使用 prometheus-operator 作为部署方式:
$ git clone https://github.com/prometheus-operator/kube-prometheus.git
kubectl create -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
完成后就可以在 monitoring namespace 下看到 Prometheus 相关的组件了:
$ kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 9h
alertmanager-main-1 2/2 Running 0 9h
alertmanager-main-2 2/2 Running 0 9h
blackbox-exporter-6798fb5bb4-88bhj 3/3 Running 0 9h
grafana-698f6895f4-8gwt7 1/1 Running 0 9h
kube-state-metrics-5fcb7d6fcb-hpsn6 3/3 Running 0 9h
node-exporter-2z8sq 2/2 Running 0 9h
node-exporter-bcfcr 2/2 Running 0 9h
node-exporter-jg2w4 2/2 Running 0 9h
prometheus-adapter-7dc46dd46d-6tw7k 1/1 Running 0 9h
prometheus-adapter-7dc46dd46d-ss7h8 1/1 Running 0 9h
prometheus-k8s-0 2/2 Running 0 9h
prometheus-k8s-1 2/2 Running 0 9h
prometheus-operator-66cf6bd9c6-w9m5k 2/2 Running 0 9h
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.104.201.190 <none> 9093/TCP,8080/TCP 9h
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 9h
blackbox-exporter ClusterIP 10.105.110.192 <none> 9115/TCP,19115/TCP 9h
grafana ClusterIP 10.103.196.221 <none> 3000/TCP 9h
grafana-pub NodePort 10.109.122.46 <none> 3000:32130/TCP 9h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 9h
node-exporter ClusterIP None <none> 9100/TCP 9h
prometheus-adapter ClusterIP 10.106.96.212 <none> 443/TCP 9h
prometheus-k8s NodePort 10.99.87.46 <none> 9090:32142/TCP,8080:32161/TCP 9h
prometheus-operated ClusterIP None <none> 9090/TCP 9h
prometheus-operator ClusterIP None <none> 8443/TCP 9h
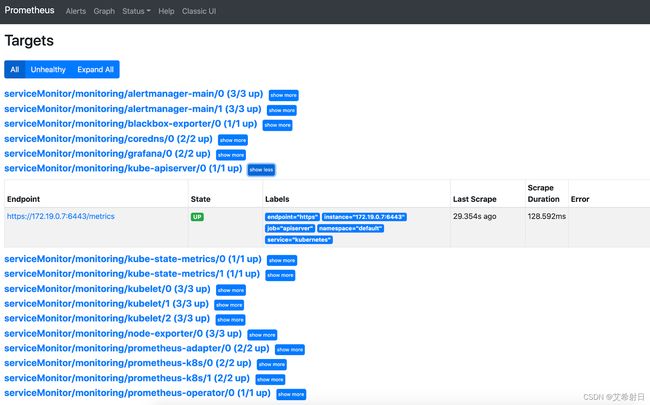
可以看到 Prometheus Server、node-exporter、grafana 等组件都已经部署好了,除了 Operator 自己创建的 Service 上面还额外加了两个 NodePort 的 service 方便从外部访问。Prometheus 默认监听 9090 端口,下面是 Prometheus 的UI 示例,我们可以查询 Prometheus 的监听对象,设置报警规则,查询各种指标等操作:
- 目标 target,表示收集目标的对象,这里是在 Kubernetes 部署后自动配置的,我们也可以在 Prometheus 文件中设置。
- 查询节点信息

- 查询 deployment 信息

除了 Prometheus 本身的 UI,Operator 还部署了 Grafana 并自动创建了众多 Dashboard,默认用户名密码是 admin:admin,登陆进后就可以查看相关的监控指标了,下面是几个示例:
-
Dashboard 列表
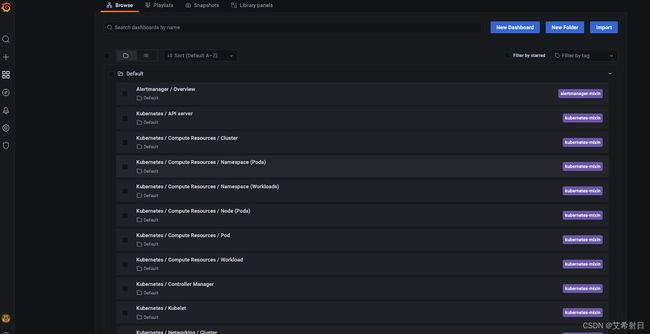
-
集群整体监控

- kubelet 监控

- 宿主机节点监控
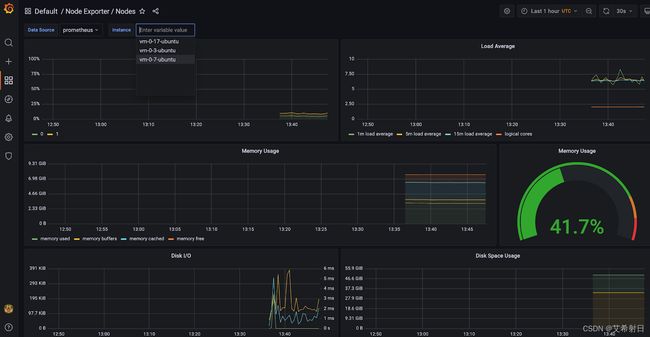
二. Debug/Logging/TroubleShooting
当运行的应用出现问题时,我们需要找出问题,恢复正常运行,一般包含一些操作:
- 查看 Pod 状态以及 Spec,看是否被正确调度,Volume 挂载是否准确等。
- 查看应用本身是否正确,比如数据库配置是否正确,代码是否报错等,一般可以通过查看日志来解决,另外如果 Pod 内容器支持 debug 可以运行命令进入容器执行 debug。
- 查看 Service、Ingress 等配置是否正确,保证外部请求能正确访问到应用。
另外集群的控制组件、worker node 都有可能出现问题,导致集群不可用,此时需要检查 Kubernetes 的各个组件是否正常运行。
2.1 Debug Pod/Service
首先可以通过 kubectl describe 命令和 kubectl get pod $
$ kubectl describe pod -n ingress-nginx ingress-nginx-controller-5fd866c9b6-qc824
Name: ingress-nginx-controller-5fd866c9b6-qc824
Namespace: ingress-nginx
Priority: 0
Node: vm-0-7-ubuntu/172.19.0.7
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Pulling 28m (x73 over 7h8m) kubelet Pulling image "k8s.gcr.io/ingress-nginx/controller:v1.1.0@sha256:f766669fdcf3dc26347ed273a55e754b427eb4411ee075a53f30718b4499076a"
Normal BackOff 8m42s (x1613 over 7h7m) kubelet Back-off pulling image "k8s.gcr.io/ingress-nginx/controller:v1.1.0@sha256:f766669fdcf3dc26347ed273a55e754b427eb4411ee075a53f30718b4499076a"
Normal RELOAD 5m33s nginx-ingress-controller NGINX reload triggered due to a change in configuration
这样通过查看 Pod 的状态、Event信息可以初步了解 Pod 启动失败的原因。比如
- 如果Pod一直处于 Pending的状态,那说明Kubernetes 无法将其分配到一个节点上。一般会有以下几种情况:
- CPU/Memory 资源不足,首先确认除了master 节点外的机器资源,可以通过命令kubectl get nodes -o yaml | egrep ‘\sname:|cpu:|memory:’, Pod 的资源申请不能大于节点容量。或者添加一个Node,或者删除一些再需要的Pod 来释放一些资源
如果Pod 有使用 hostPort资源(即Node上实际的端口资源),这样会限制Pod能被调度到的Node节点,除非必要,请用service资源替代。 - 如果Pod一直处于waiting 的状态,那说明Pod已经被调度都某一个节点,但是无法执行成功,一般比较大的概率是镜像问题,可以检查:
- 镜像名称是否有误?版本号码是否正确
- 是否已经push到镜像仓库,可以使用docker pull 来进行验证
- CPU/Memory 资源不足,首先确认除了master 节点外的机器资源,可以通过命令kubectl get nodes -o yaml | egrep ‘\sname:|cpu:|memory:’, Pod 的资源申请不能大于节点容量。或者添加一个Node,或者删除一些再需要的Pod 来释放一些资源
- 如果Pod已经执行起来,但是一直crashing 或者处于不健康状态,此时可能需要通过日志或者 debug 命令来检查 Pod 中容器的运行情况。
首先可以通过 kubectl log 命令查看 Pod 某个容器的 log
kubectl logs ${POD_NAME} ${CONTAINER_NAME}
如果容器之前有crash 过,可以通过以下命令查看crash 的容器的log
kubectl logs --previous ${POD_NAME} ${CONTAINER_NAME}
如果容器镜像已经包含 debug 功能的命令,可以使用 kube exec 命令来执行:
kubectl exec ${POD_NAME} -c ${CONTAINER_NAME} -- ${CMD} ${ARG1} ${ARG2} ... ${ARGN},例如:
kubectl exec -it cassandra -- sh
如果容器本身没有开启 debug ,可以使用SideCar 容器或者 Ephemeral 容器来定位那些运行没有包含debugging功能镜像的容器。
$ kubectl run ephemeral-demo --image=k8s.gcr.io/pause:3.1 --restart=Never
pod/ephemeral-demo created
$ kubectl exec -it ephemeral-demo -- sh
OCI runtime exec failed: exec failed: container_linux.go:380: starting container process caused: exec: "sh": executable file not found in $PATH: unknown
command terminated with exit code 126
此时执行 debug 命令会报错,因此可以使用
$ kubectl debug -it ephemeral-demo --image=busybox --target=ephemeral-demo
Defaulting debug container name to debugger-8xzrl.
If you don't see a command prompt, try pressing enter.
/ #
除了 Pod 一般还会有 Service 的调试以保证 Pod 会被访问到,对于 Service 主要就是查看 Service 资源创建成功以及 Endpoints 是否是对应的 Pod。其次可以通过
2.2 网络调试
除了应用本身的问题 ,Kuberetes 中网络问题算是占比较大的问题类型,但 Pod 中的容器往往都只安装了应用所需的依赖和命令,操作系统中的很多程序和命令都是没有的,比如 tcdump 、ifconfig、vim 等程序。为了方便调试网络问题社区提供了 nicolaka/netshoot 工具,其包含众多常用的网络以及相关调试命令。

下面是使用 netshoot 的一个示例,在使用我们的 EaseMesh 做灰度时,需要通过抓包检查下请求是否到了灰度应用中。
首先查看下 Pod 所在节点并找到对应的容器:
$ kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-pod-975986b55-r66kg 2/2 Running 0 13h 10.233.68.108 node5 <none> <none>
node:➜ ~ |>docker ps [~]
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
k8s_my-pod_mesh-service_1f563154-8a25-431e-8d44-3b1e2b0aab02_0
a2ba0b7db5a5 k8s.gcr.io/pause:3.3 "/pause" 14 hours ago Up 14 hours
在对应的节点上找到已经创建的容器,因为 Kubernetes 是通过 pause 容器来创建的网络 namespaace,因此我们在 pause 容器中进行抓包操作,netshoot 提供了命令 docker run -it --net container: 使我们进入目标容器内部,进入容器后就可以使用相关的命令了。下面我们通过 ifconfig 查看容器内网络设备以及通过 tcpdump 命令一抓包查看是否有请求进入容器的操作示例:
node4:➜ ~ |>docker run -it --net container:a2ba0b7db5a5 nicolaka/netshoot [~]
dP dP dP
88 88 88
88d888b. .d8888b. d8888P .d8888b. 88d888b. .d8888b. .d8888b. d8888P
88' `88 88ooood8 88 Y8ooooo. 88' `88 88' `88 88' `88 88
88 88 88. ... 88 88 88 88 88. .88 88. .88 88
dP dP `88888P' dP `88888P' dP dP `88888P' `88888P' dP
Welcome to Netshoot! (github.com/nicolaka/netshoot)
my-pod-7647db59f5-vcdzn ~ ifconfig
eth0 Link encap:Ethernet HWaddr 6A:A1:BD:16:29:85
inet addr:10.233.67.129 Bcast:0.0.0.0 Mask:255.255.255.255
UP BROADCAST RUNNING MULTICAST MTU:9001 Metric:1
RX packets:599624 errors:0 dropped:0 overruns:0 frame:0
TX packets:737437 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:161261874 (153.7 MiB) TX bytes:295757144 (282.0 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:228767 errors:0 dropped:0 overruns:0 frame:0
TX packets:228767 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:22301724 (21.2 MiB) TX bytes:22301724 (21.2 MiB)
// 抓包
mypod-7647db59f5-vcdzn ~ tcpdump -s0 -Xvn -i eth0 tcp port 13001
tcpdump: listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
22:56:43.071099 IP (tos 0x0, ttl 63, id 58997, offset 0, flags [DF], proto TCP (6), length 60)
10.233.65.136.56160 > 10.233.67.129.13001: Flags [S], cksum 0xfeca (correct), seq 938442090, win 62377, options [mss 8911,sackOK,TS val 4022397520 ecr 0,nop,wscale 7], length 0
0x0000: 4500 003c e675 4000 3f06 ba6b 0ae9 4188 E..<.u@.?..k..A.
0x0010: 0ae9 4381 db60 32c9 37ef 7d6a 0000 0000 ..C..`2.7.}j....
0x0020: a002 f3a9 feca 0000 0204 22cf 0402 080a ..........".....
0x0030: efc0 ea50 0000 0000 0103 0307 ...P........
22:56:43.071114 IP (tos 0x0, ttl 64, id 0, offset 0, flags [DF], proto TCP (6), length 60)
10.233.67.129.13001 > 10.233.65.136.56160: Flags [S.], cksum 0x9b09 (incorrect -> 0x4b72), seq 2068664002, ack 938442091, win 62293, options [mss 8911,sackOK,TS val 3323601777 ecr 4022397520,nop,wscale 7], length 0
0x0000: 4500 003c 0000 4000 4006 9fe1 0ae9 4381 E..<..@[email protected].
0x0010: 0ae9 4188 32c9 db60 7b4d 4ec2 37ef 7d6b ..A.2..`{MN.7.}k
0x0020: a012 f355 9b09 0000 0204 22cf 0402 080a ...U......".....
0x0030: c61a 2371 efc0 ea50 0103 0307 ..#q...P....
22:56:43.071221 IP (tos 0x0, ttl 63, id 58998, offset 0, flags [DF], proto TCP (6), length 52)
10.233.65.136.56160 > 10.233.67.129.13001: Flags [.], cksum 0x88c7 (correct), ack 1, win 488, options [nop,nop,TS val 4022397520 ecr 3323601777], length 0
2.3 集群组件排错
如果是集群出错,我们需要查看控制节点和 worker 节点的各个组件是否正确。下面是一些基本的步骤供参考:
- 检查控制组件 api-server、etcd、scheduler、controller 是否启动成功,可以通过上面提到的 debug Pod 的方式以及检查 /etc/kubernetes/manifests/ 下的 yaml 文件是否有问题。
- 检查网络插件是否安装正确以及确保网络插件支持所需的特性。
- 检查 kube-proxy 是否部署配置正确。
- 检查 DNS 是否配置正确。
- 检查 kubelet 是否正常启动,可以通过 systemd status kubelet 命令查看 kubelet 的状态以及 journalctl -u kubelet | tail 命令查看 kubelet 的日志。
另外关于集群的基本信息,在 kube-public 命名空间下有 ConfigMap 记录,这里记录了基本的 Kubernetes server 信息,如果在节点变化时 server 信息没有及时同步,可以手动该这里的配置进行排错。
$ kubectl get cm -n kube-public
NAME DATA AGE
cluster-info 1 28d