GraphEmbedding - DeepWalk 图文详解
一.引言
上一篇文章讲到了如何使用 networkx 获取图 ,通过networkx 获得的图我们可以通过获取节点的邻居开始随机游走,从而获得游走序列,进而结合 word2vec 进行节点向量化操作。
二.DeepWalk 原理
1.获得关注关系图
通过节点之间的关系生成图,在DeepWalk算法中,各个节点之间的权重默认为1。
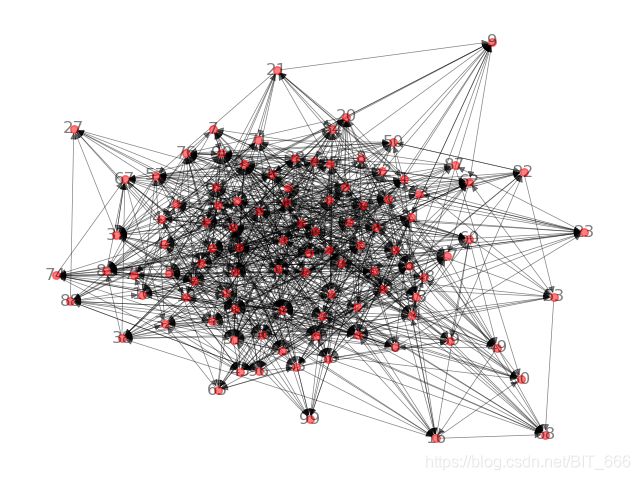 CSDN_BITDDD
CSDN_BITDDD
2.在图中游走获取序列
DeepWalk 涉及到的随机游走是一种可重复访问已访问节点的深度优先遍历(DFS)算法。给定起始节点,从该节点的邻居中随机选取访问节点,并将新的节点作为起始点继续探索,当该节点没有邻居或者达到序列长度时,退出循环。这里有几个点:
A.可重复访问
如果1只关注了2,恰巧2只关注了1,固定序列长度为10,起始点为1,则会生成 1-2-1-2-1-2-1-2-1-2 的关注关系序列。
B.深度优先遍历
可以把生成用户序列的过程理解为不断的二叉树划分,这里不断寻找新节点的邻居就可以看作是 DFS 遍历一颗树。在 Node2vec 算法中,涉及到了转移概率p,q,其中p,q的值代表了 walk 更偏向于 BFS 还是 DFS,后续介绍 Node2vec 可以详细盘一下。
C.关于有向图还是无向图
生成序列时需要获取图中节点的邻居,这里图可以是有向图和无向图,对于有向图而言 1-2 ,1的邻居有2,2的邻居没1,对于无向图而言 1-2,1、2互为邻居,可以双向奔赴。
G = nx.DiGraph() // nx.Graph()
G.add_edges_from([('1', '2'), ('3', '4'), ('1', '3')])
for node in G.nodes:
print("node:", node)
print("neighbour:", list(G.neighbors(node)))有向图:  无向图:
无向图: 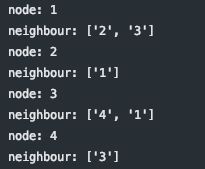
3.通过word2vec模型生成词嵌入
DeepWalk 采用 skip-gram 方式训练词嵌入,根据上一步游走得到的序列与预定的 window_size 即可获取训练语料从而进行词嵌入,这也是 GNN 最基本的形式。word2vec 暂时使用 gensim 库,可以通过下述方法获取,后续抽空补上 keras 的实现:
from gensim.models import Word2Vec三.DeepWalk 实现
这里和 DeepWalk 原理对应,分别实现获得关注关系图、随机游走、词嵌入生成
1.获得关注关系图
这里随机生成了约1000个关注关系样本,其中id用 0-100 的数字作数字化标识。
# 1.获取关注关系图
edge_file = "./test_edges.txt"
random.seed(100)
def createGraph():
f = open(edge_file, "w")
for i in range(1000):
a = random.randint(0, 100)
b = random.randint(0, 100)
if a != b:
f.write("%s %s\n" % (a, b))
f.close()
createGraph()
def loadGraph(fileName):
G = nx.read_edgelist(fileName, create_using=nx.DiGraph(), nodetype=None, data=None)
return G
G = loadGraph(edge_file)
2.在图中游走获取序列
通过 G.nodes() 获取图中每个节点,通过 G.neighbors(node) 获取当前节点的邻居,再通过 random 方法随机选取邻居,持续到规定的序列步长 (walk_length) 即完成一个节点的采样。
# 2.在图中游走获取序列
def deep_walk(all_nodes, walk_length=50):
walks = []
all_nodes = list(all_nodes)
random.shuffle(all_nodes)
for node in all_nodes:
walk = [node]
while len(walk) < walk_length:
cur_walk = walk[-1]
cur_neighbor = list(G.neighbors(cur_walk))
if len(cur_neighbor) > 0:
walk.append(random.choice(cur_neighbor))
else:
break
walks.append(walk)
return walks
walks = deep_walk(G.nodes)
# take 5 samples
print("-----------------------")
random_seq = walks[0: 5]
for i in random_seq:
print(i)
print("-----------------------")
通过随机游走获取 DeepWalk 游走序列:

3.通过word2vec模型生成词嵌入
通过 gensim 的 word2vec 模型对上述随机游走获得的训练语料进行训练,获取词嵌入:
# 3.通过word2vec模型生成词嵌入
from gensim.models import Word2Vec
kwargs = {"sentences": walks, "min_count": 0, "vector_size": 64,
"sg": 1, "hs": 0, "workers": 3, "window": 5, "epochs": 3}
model = Word2Vec(**kwargs)=> 这里训练只选择了部分常用参数:
sentneces: walks - 随机游走获取的随机关注关系序列
min_count: 0 - 为了所有节点都能生成 embedding
vector_size: 64 - 一般为2的开方倍数
sg: 1 - 选择 skip-gram
hs: 0 - 不使用层次 softmax,因为这里语料库很少
workers: 3 - 并行度,单机选择合适核数即可
window: 5 - 窗口大小
epochs: 3 - 训练三轮 Tips: 参数说明

4.获取词嵌入
def get_embeddings(w2v_model, graph):
count = 0
invalid_word = []
_embeddings = {}
for word in graph.nodes():
if word in w2v_model.wv:
_embeddings[word] = w2v_model.wv[word]
else:
invalid_word.append(word)
count += 1
print("无效word", len(invalid_word))
print("有效embedding", len(_embeddings))
return _embeddings
embeddings = get_embeddings(model, G)
embedding 示例:
embeddings 中包含了图中所有节点的 embedding,因为 word2vec 的参数 min_count = 0。
'66': array([ 0.16813594, -0.08579705, 0.14222355, -0.02370718, 0.13019496,
-0.08648787, 0.08844486, 0.01725838, -0.14669202, -0.08005974,
0.23162098, -0.43159565, -0.17642093, -0.19328424, -0.01723822,
0.25570047, 0.18466431, -0.06668554, 0.01028909, 0.3636664 ,
0.2317302 , 0.20645727, 0.25969195, -0.2385212 , -0.14786883,
0.14411835, -0.22160596, -0.17755191, 0.06139074, 0.05162533,
-0.19335145, 0.11888868, -0.270623 , -0.08170396, -0.33513343,
-0.02528459, 0.13055046, 0.04454559, 0.1981014 , -0.1125013 ,
0.10232925, -0.00103224, 0.00687569, -0.17043409, 0.01417654,
-0.15750904, 0.03035425, -0.23062049, -0.01350352, 0.13234578,
0.00224355, -0.12026031, 0.16231693, 0.1659788 , 0.17250071,
0.04181172, 0.09494174, 0.05082603, -0.1504332 , 0.08051857,
0.11740875, -0.12749803, -0.1126245 , -0.03306595], dtype=float32)四.总结
DeepWalk 是 GraphEmbedding 中最基础的算法,后续很多的改进算法都是对图游走生成关注关系序列进行调整,添加转移概率和采样等。现在已经可以通过简单的随机游走获取节点的词嵌入,后续看看如何评估和可视化这些词向量。