致初学者的深度学习入门系列(四)—— 深度学习目标检测篇(下)
SSD(Single Shot MultiBox Detector )
由于当网络逐渐深层时,感受野也逐渐越来越大。如果通过最终的feature maps进行区域生长,随着感受野增大对于小目标的检测效果也不理想。于是SSD诞生,其带来了一种新的想法:那如果是针对卷积过程中间的feature maps都进行区域生长呢?
SSD以VGG-16作为BackBone,并对其进行了一些修改:
- 分别将VGG16的全连接层FC6和FC7转换成 3x3 的卷积层 Conv6和 1x1 的卷积层Conv7
- 去掉所有的Dropout层和FC8层
- 同时将池化层pool5由原来的 stride=2 的 2x2 变成stride=1的 3x3 (猜想是不想reduce特征图大小)
- 添加了Atrous算法(hole算法),目的获得更加密集的得分映射
- 然后在VGG16的基础上新增了卷积层来获得更多的特征图以用于检测
- 多尺度特征映射

SSD在卷积层中的conv4_3、conv7、conv8_2、conv9_2、conv10_2、conv11_2都分别生成不同数量的Defalut box,在浅层的feature maps上的感受野较小,而在深层的feature maps上的感受野较大,所以多尺度上生成的Defalut box可以适应更多不同大小的目标。
不同feature maps上每个像素点生成Defalut box的数量以及总的Defalut box数量:
| name | Out_size | Prior_box_num | Total_num |
|---|---|---|---|
| conv4_3 | 38x38 | 4 | 5776 |
| conv7(fc7) | 19x19 | 6 | 2166 |
| conv8_2 | 10x10 | 6 | 600 |
| conv9_2 | 5x5 | 6 | 150 |
| conv10_2 | 3x3 | 4 | 36 |
| conv11_2 | 1x1 | 4 | 4 |
| 8732 |
- Defalut box生成规则
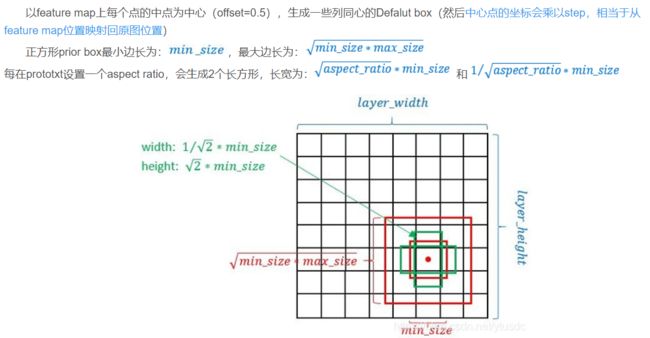
而每个feature map对应Prior box的min_size和max_size由以下公式决定,公式中m是使用feature map的数量(SSD 300中m=6)
S k = S m i n + S m a x − S m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] S_k=S_{min}+\dfrac{S_{max}-S_{min}}{m-1}(k-1), k\in[1, m] Sk=Smin+m−1Smax−Smin(k−1),k∈[1,m]
使用不同的ratio值,[1, 2, 3, 1/2, 1/3],通过下面的公式计算 default box 的宽度w和高度h:
w k a = s k a r , h k a = s k / a r w^a_k=s_k\sqrt{a_r},h^a_k=s_k/\sqrt{a_r} wka=skar,hka=sk/ar
而对于ratio=1的情况,指定的scale如下所示,即总共有 6 中不同的 default box
s k ′ = s k s k + 1 s_k'=\sqrt{s_ks_{k+1}} sk′=sksk+1
第一层feature map对应的min_size=S1,max_size=S2;第二层min_size=S2,max_size=S3;其他类推。在原文中,Smin=0.2,Smax=0.95。但是在SSD 300中prior box设置并不能和paper中上述公式对应:
| min_size | max_size | |
|---|---|---|
| conv4_3 | 30 | 60 |
| conv7(fc7) | 60 | 111 |
| conv8_2 | 111 | 162 |
| conv9_2 | 162 | 213 |
| conv10_2 | 213 | 264 |
| conv11_2 | 264 | 315 |
- Prior Box
得到的Defalut box数量很多,但大部分并不是我们想要的,所以需要进行一定的筛选选出Prior Box。首先筛除掉超出边缘的Defalut box,再筛除IOU过低的后,基本就剩下的为合理的Prior Box。这也是我们实际传入网络是采用的区域。
- Hard negative mining:
一般情况下negative default boxes数量>>positive default boxes数量,直接训练会导致网络过于重视负样本,从而loss不稳定。为了保证正负样本尽量平衡,SSD在训练时采用了hard negative mining,对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
FPN(feature pyramid networks)
FPN利用特征的方式是通过顶层特征上采样和底层特征做融合,然后每层都进行独立预测来实现的。上层特征通过2x的上采样与下层特征经过1x1卷积后相加进行融合,上采用采用的是最邻近插值的方法来实现。融合后还会用3x3大小的卷积核对融合后的结果进行卷积,消除上采样的混叠效应。Backbone采用的是ResNet。
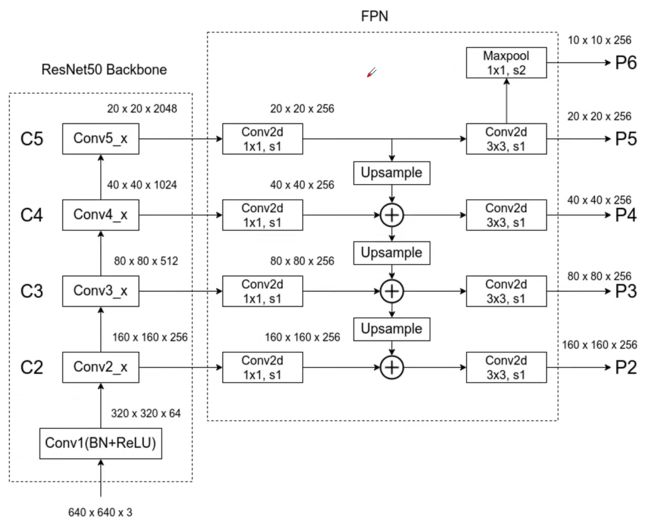
- 生成proposal
FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为322,642,1282,2562,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
GAN(Generative Adversarial Network)
网络整体示意图
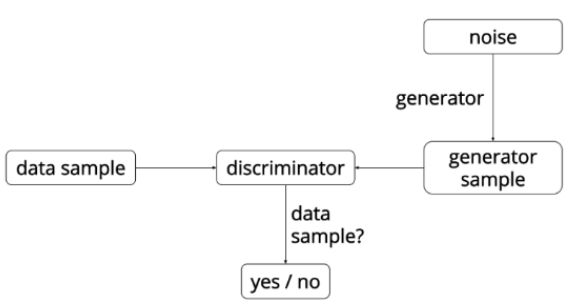
GAN中有两个网络,G(Generator)和D(Discriminator)。Generator是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。Discriminator是一个判别网络,判别一张图片是不是“真实的”。
在训练过程中,生成网络的目标就是尽量生成真实的图片去欺骗判别网络D。而网络D的目标就是尽量把网络G生成的图片和真实的图片分别开来。知道最终达到纳什平衡(指博弈中这样的局面,对于每个参与者来说,只要其他人不改变策略,他就无法改善自己的状况。)。
目标函数
m i n G m a x D V ( D , G ) = E x ∼ P d a t a [ log D ( x ) ] + E x ∼ P ( x ) [ log(1-D(G(z))) ] . min_Gmax_DV(D, G)=E_{x\sim P_{data}}[\text{log}D(x)]+E_{x\sim P_{(x)}}[\text{log(1-D(G(z)))}]. minGmaxDV(D,G)=Ex∼Pdata[logD(x)]+Ex∼P(x)[log(1-D(G(z)))].
训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)和log(1-D(G(z))) ,训练网络G最小化log(1 – D(G(z))),即最大化D的损失。而训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布,也就是生成的样本更加的真实。
You Only Look Once Unified, Real-Time Object Detection
- 目标检测
将输入图像分成SxS个格子,如果对象的中心点落在某个格子中,该格子就负责对此对象进行检测。每个Bounding Box由5个预测量:x, y, w, h和confidence。(x, y)为box中心相对于格子边界的坐标(在[0,1]之间)。w, h为相对于整个图像的相对尺寸(在[0,1]之间)。
**confidence的计算:**每个格子预测为每个对象的概率预计对象是某个类的条件概率,并计算predict box和ground truth的IOU。作为格子对每个类的置信度。如果格子中判断为背景,则该置信度置为0。
c o n f i d e n c e = P r ( C l a s s i ∣ O b j e c t ) ∗ P r ( O b j e c t ) ∗ I O U p r e d t r u t h = P r C l a s s i ∗ I O U p r e d t r u t h confidence=Pr(Class_i|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr{Class_i}*IOU^{truth}_{pred} confidence=Pr(Classi∣Object)∗Pr(Object)∗IOUpredtruth=PrClassi∗IOUpredtruth
- Backbone
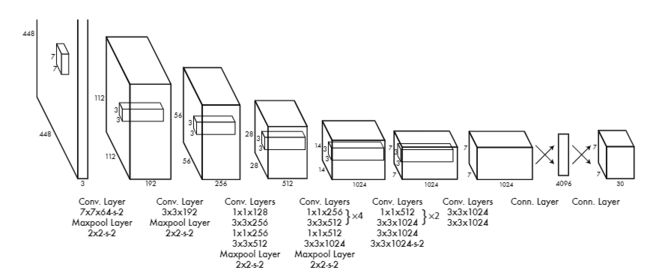
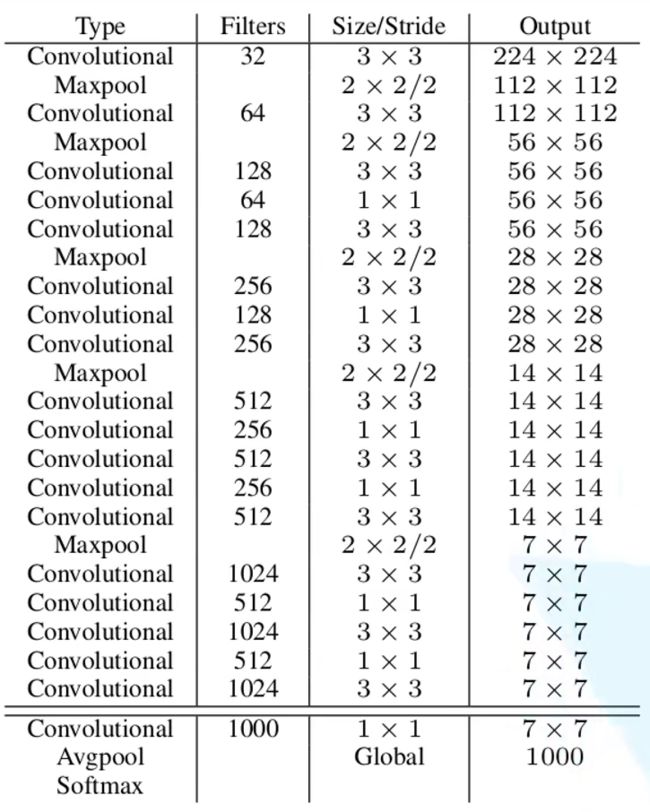
作者受GoogleNet启发进而构建的网络,由24个卷积层和2个全连接层组成。在ImageNet上进行与训练后,在检测时将分辨率提高一倍(224x224–>448x448)。
- 激活函数
使用Leaky ReLU函数,定义为
ϕ ( x ) = { x , if x > 0 0.1 x , otherwise \phi(x)=\left\{ \begin{matrix} x, \quad \text{if }x>0\\ 0.1x, \quad\text{otherwise} \end{matrix} \right. ϕ(x)={x,if x>00.1x,otherwise
- 正则化
采用的是随机概率为0.5的Dropout正则化,防止过拟合。
- 数据扩充
引入了随机缩放和最高原始图像20%的翻转。在HSV颜色空间中,随机调整图像的曝光和饱和度,最大调整系数为1.5。
- 损失函数
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ Loss=&\lambda_…
其中
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ & 1_{ij}^{obj}…
YOLO9000 Better, Faster, Stronger
- Backbone
1. Better
- Batch Normalization(批归一化)
- High Resolution Classifier(分类网络高分辨率预训练)
YOLOV1在ImageNet上训练的图片尺寸为224x224,而在YOLOV2中采用448x448训练10个epochs。
- Convolutional With Anchor Boxes
由原本对矩形框的宽高的绝对值进行预测改成预测Anchor的偏差。训练时最接近ground truth的框产生Loss,其他不产生Loss。map略微下降,但召回率大幅提高。
- Dimension Clusters
为了解决Anchor Box人为设定,YOLOV2采用k-means聚类得到先验框的宽和高,聚类类别中心的个数为5.
聚类点之间的距离函数为
d ( b o x , c e n t r o i d ) = 1 − I O U ( b o x , c e n t r o i d ) d(box, centroid)=1-IOU(box,centroid) d(box,centroid)=1−IOU(box,centroid)
- Direct location prediction(绝对位置预测)
作者发现模型在早期训练时很不稳定,原因在于预测anchor box的中心坐标上。
其他多数网络的位置预测公式(tx和ty为神经网络的预测值):
x = ( t x ∗ w a ) + x a y = ( t y ∗ h a ) + y a x=(t_x*w_a)+x_a\\ y=(t_y*h_a)+y_a x=(tx∗wa)+xay=(ty∗ha)+ya
YOLOV2的位置预测公式:
b x = σ ( t x ) + c x b y = σ ( t y ) + c y b w = p w e t w b h = p h e t h b_x=\sigma(t_x)+c_x\\ b_y=\sigma(t_y)+c_y\\ b_w=p_we^{t_{w}}\\ b_h=p_he^{t_{h}} bx=σ(tx)+cxby=σ(ty)+cybw=pwetwbh=pheth
优点:与矩形框的宽高独立。
- Fine-Grained Features(细粒度特征)
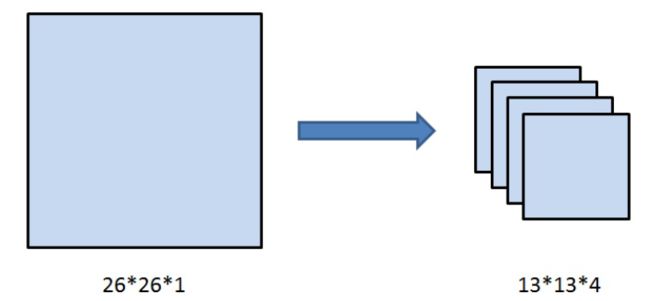
特征图经过卷积后尺寸的变小导致了很多细粒度特征的丢失,导致小尺寸物体的识别效果不佳,加入passthrough层,减小特征图的尺寸但通道的数量增加,相当于裁剪之后在通道维度进行拼接。26x26x1–>13x13x4。
- Multi-Scale Training(多尺寸训练)
在每10个batch之后,就将图片resize成{320, 352, …, 608}中的一种。不同的输入,最后产生的格点数不同,比如输入图片是320320,那么输出格点是1010,如果每个格点的先验框个数设置为5,那么总共输出500个预测结果;如果输入图片大小是608608,输出格点就是1919,共1805个预测结果。
2. Stronger
- 分类和检测联合训练策略
对于分类数据集,仅学习分类扩充模型所能检测的物体种类。对于检测数据集,学习预测物体的边界框、置信度和分类等。如果是检测样本则既计算分类误差也计算位置误差,对于分类样本则只计算分类误差。学习检测数据集网络可以学会对物体的检测和定位,然后通过学习大规模的分类数据集来增大能够检测对象的种类,从而实现能够检测9000种物体。
- 数据集与 WordTree 的组合
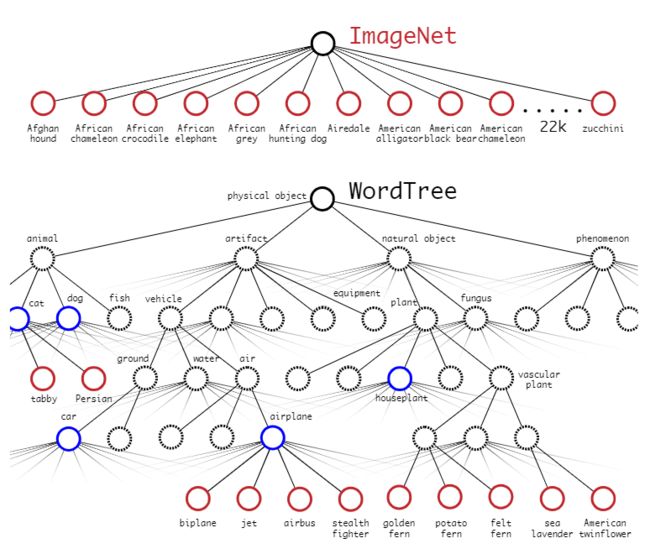

使用树结构来表示类别之间的从属关系,同一类别之间才进行softmax操作,在树的每一层都选取softmax预测分值最高的节点并向下检索,知道所有选择的节点预测分值连乘都小于某一阈值为止。
YOLOv3 An Incremental Improvement
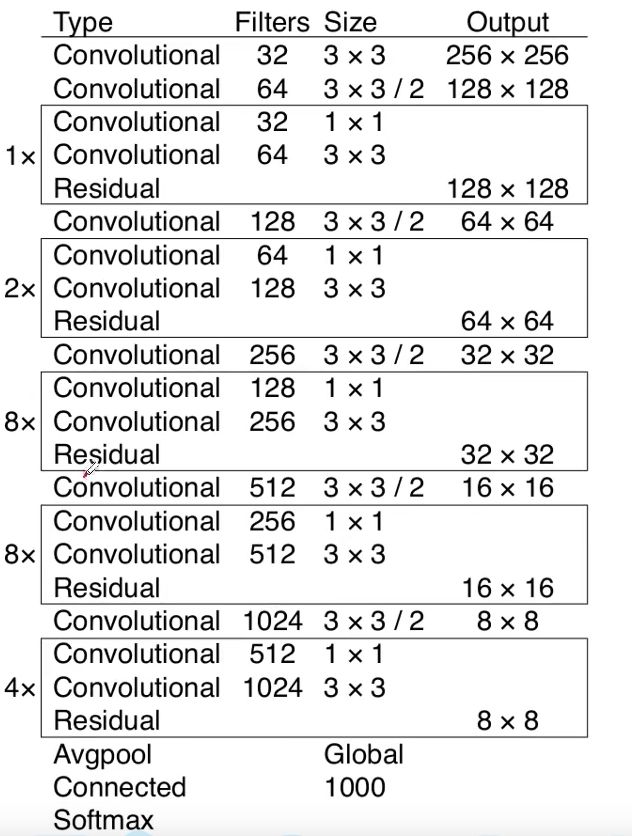
- BackBone:Darknet-53
- Loss
- 计算公式
L ( o , c , O , C , l , g ) = λ 1 L c o n f ( o , c ) + λ 2 L c l a ( O , C ) + λ 1 L l o c ( l , g ) λ 1 、 λ 2 、 λ 3 为 平 衡 系 数 L(o, c, O, C, l, g)=\lambda_1L_{conf}(o, c)+\lambda_2L_{cla}(O, C)+\lambda_1L_{loc}(l, g)\\ \lambda_1、\lambda_2、\lambda_3为平衡系数 L(o,c,O,C,l,g)=λ1Lconf(o,c)+λ2Lcla(O,C)+λ1Lloc(l,g)λ1、λ2、λ3为平衡系数
- 类别损失
二值交叉熵损失
L c l a ( O , C ) = − ∑ i ∈ p o s ∑ j ∈ c l a ( O i j l n ( C ^ i j ) + ( 1 − O i j ) l n ( 1 − C ^ i j ) ) N p o s C ^ i j = S i g m o i d ( C i j ) L_{cla}(O, C)=-\dfrac{\sum_{i\in pos}\sum_{j\in cla}(O_{ij}ln(\hat{C}_{ij})+(1-O_{ij})ln(1-\hat{C}_{ij}))}{N_{pos}}\\ \hat{C}_{ij}=Sigmoid(C_{ij}) Lcla(O,C)=−Npos∑i∈pos∑j∈cla(Oijln(C^ij)+(1−Oij)ln(1−C^ij))C^ij=Sigmoid(Cij)
- 定位损失
L l o c ( l , g ) = ∑ i ∈ p o s ∑ m ∈ { x , y , w , h } ( l ^ i m − g ^ i m ) 2 N p o s L_{loc}(l, g)=\dfrac{\sum_{i\in pos}\sum_{m\in \{x, y, w, h\}}(\hat{l}_i^m-\hat{g}_i^m)^2}{N_{pos}} Lloc(l,g)=Npos∑i∈pos∑m∈{x,y,w,h}(l^im−g^im)2
YOLOV3 SPP
- Mosaic图像增强
将图像进行拼接,作用:
- 增加数据的多样性
- 增加目标个数
- BN能一次性统计多张图片的参数
- SPP模块
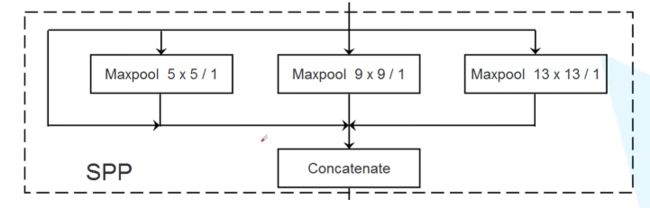
通道数量变为原来的四倍, 实现了不同尺度的特征融合。
- 损失函数优化
1. IOU Loss
I O U L o s s = − ln I n t e r s e c t i o n ( □ , □ ) U n i o n ( □ , □ ) IOU Loss=-\text{ln}\dfrac{Intersection(\Box, \Box)}{Union(\Box, \Box)} IOULoss=−lnUnion(□,□)Intersection(□,□)
优点:
- 能够更好的反映矩形框的重合程度
- 具有尺度不变性
缺点:
- Bounding Box不相交时Loss等于0
2. GIOU Loss
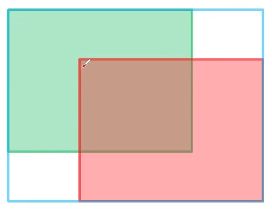
G I O U = I O U = A c − u A c − 1 ≤ G I O U ≤ 1 L G I O U = 1 − G I O U 0 ≤ L G I O U ≤ 2 A c 为 蓝 色 矩 形 框 面 积 , u 为 U n i o n 面 积 GIOU=IOU=\dfrac{A^c-u}{A^c}\quad\quad -1\leq GIOU\leq 1\\ L_{GIOU}=1-GIOU\quad\quad 0\leq L_{GIOU}\leq 2\\\\ A^c为蓝色矩形框面积,u为Union面积 GIOU=IOU=AcAc−u−1≤GIOU≤1LGIOU=1−GIOU0≤LGIOU≤2Ac为蓝色矩形框面积,u为Union面积
以上两种损失函数有两个共同缺点:
- 收敛慢
- 回归不是很准确
3. DIOU Loss
D I O U = I O U − ρ 2 ( b , b g t ) c 2 = I O U − d 2 c 2 DIOU=IOU-\dfrac{\rho^2(b, b^{gt})}{c^2}=IOU-\dfrac{d^2}{c^2}\quad DIOU=IOU−c2ρ2(b,bgt)=IOU−c2d2
− 1 ≤ D I O U ≤ 1 L D I O U = 1 − D I O U \\-1\leq DIOU\leq1\quad L_{DIOU}=1-DIOU\quad\\ −1≤DIOU≤1LDIOU=1−DIOU
0 ≤ L D I O U ≤ 2 b 为 B o u n d i n g B o x 中 心 坐 标 \\ 0\leq L_{DIOU}\leq2\quad b为Bounding Box中心坐标 0≤LDIOU≤2b为BoundingBox中心坐标
c 为 两 个 B o u n i n g B o x 对 角 连 线 的 长 度 , d 为 两 个 中 线 点 的 距 离 c为两个Bouning Box对角连线的长度,\\ d为两个中线点的距离 c为两个BouningBox对角连线的长度,d为两个中线点的距离
优点:直接最小化两个Boxes之间的距离,收敛速度很快
4. CIOU Loss
C I O U = I O U − ( ρ 2 ( b , b g t ) c 2 + α ν ) CIOU=IOU-(\dfrac{\rho^2(b, b^{gt})}{c^2}+\alpha \nu)\\ CIOU=IOU−(c2ρ2(b,bgt)+αν)
ν = 4 π 2 ( a r c t a n w g t h g t − a r c t a n w h ) 2 \nu=\dfrac{4}{\pi^2}(arctan\dfrac{w^{gt}}{h^{gt}}-arctan\dfrac{w}{h})^2\\ ν=π24(arctanhgtwgt−arctanhw)2
α = ν ( 1 − I O U ) + ν \alpha=\dfrac{\nu}{(1-IOU)+\nu}\\ α=(1−IOU)+νν
L C I O U = 1 − C I O U L_{CIOU}=1-CIOU LCIOU=1−CIOU
优点:同时考虑了重叠面积、中心点之间的距离和纵横比,可以达到较好的收敛速度和精度。
5. Focal Loss
Focal Loss的设计是为了应对one-stage目标检测中前景与背景样本极度不平衡的状况。
C E ( p , y ) = { − l o g ( p ) i f y = 1 − l o g ( 1 − p ) o t h e r w i s e (1) CE(p,y)=\left\{ \begin{matrix} -log(p)\quad \quad \quad if\quad y=1\\ -log(1-p)\quad \quad otherwise \end{matrix} \right.\\\tag{1} CE(p,y)={−log(p)ify=1−log(1−p)otherwise(1)
p t = { p i f y = 1 1 − p o t h e r w i s e (2) p_t=\left\{ \begin{matrix} p \quad \quad if \quad y=1\\ 1-p \quad otherwise \end{matrix} \right.\\\tag{2} pt={pify=11−potherwise(2)
C E ( p , y ) = C E ( p t ) = − α t l o g ( p t ) (3) CE(p, y)=CE(p_t)=-\alpha_t log(p_t)\tag{3}\\ CE(p,y)=CE(pt)=−αtlog(pt)(3)
F L ( p t ) = − ( 1 − p t ) γ l o g ( p t ) 通 过 ( 1 − p t ) γ 能 够 降 低 易 分 样 本 的 损 失 贡 献 (4) FL(p_t)=-(1-p_t)^\gamma log(p_t)\tag{4}\\ 通过(1-p_t)^\gamma 能够降低易分样本的损失贡献 FL(pt)=−(1−pt)γlog(pt)通过(1−pt)γ能够降低易分样本的损失贡献(4)
综合以上各式,写出最终Focal Loss公式
F L ( p t ) = − α t ( 1 − p t ) γ l o g ( p t ) (5) FL(p_t)=-\alpha_t (1-p_t)^\gamma log(p_t)\tag{5} FL(pt)=−αt(1−pt)γlog(pt)(5)
对于分类较好的样本,其pt较大,采用Focal Loss其计算出的损失较小,目的在于可以将损失集中在分类较差的类别上,但缺点是易受噪声干扰。
YOLOV4 Optimal Speed and Accuracy of Object Detection
1. Bag of freebies
“Bag of freebies”指的是只改变训练策略或者只增加训练成本,而不影响推理速度的方法。例如数据增强,类别不平衡,损失函数,软标签、边界框回归目标函数等。
- Data Augmentation(数据增强):像素级调整、模拟对象遮挡、多个图像叠加等。
- Semantic Distribution Bias (语义分布偏差):hard negative example mining
- Data Imbalance(数据不平衡):Focal Loss
- 不同类别关联表达困难:软标签
- Bounding Box回归损失:CIOU Loss
2. Bag of specials
“Bag of specials”指的是仅增加少量推理成本但是可以显著提高目标检测准确度的模块或后处理方法。常见的specials模块有扩大感受野、引入注意力机制、增强特征集成能力等,而后处理是用于筛选模型预测结果的方法。
- 增强感受野:SPP、ASPP、RFB。
- 注意力模块:channel-wise attention(代表为Squeeze-and Excitation(SE))、point-wise attention(代表为Spatial Attention Module)。
- Feature Integration:常见有SFAM、ASFF、BiFPN。
- 激活函数:ReLU、LReLU、PReLU、ReLU6。
- 后处理方法:NMS(greedy NMS、Soft NMS)
3. Methodology
结构选择
- BackBone:CSPDarkNet53
- Neck:SPP、PANet路径聚合
- Head:与YOLOV3相同
Selection of BOF and BoS
-
Data Augmentation :Mosaic,Self-Adversarial Training (SAT)
-
Mosaic
通过混合四幅训练图像(直接拼接成一幅),可以较小训练集规模,增加数据集中的目标个数。
-
SAT(自对抗训练)
a. 第一阶段,神经网络改变原始图像而不是网络权重。通过这种方式,神经网络对其自身执行对抗性攻击,改变原始图像以制造图像上没有所需对象的欺骗。
b. 在第二阶段,训练神经网络去以正常的方式在修改后的图像上检测目标。
-
-
应用遗传算法选择最优超参数
-
使用改进的SAM,改进的PAN,跨小批量标准化Cross mini-Batch Normalization(CmBN)
-
Mish激活函数
M i s h ( x ) = x × t a n h ( l n ( 1 + e x ) ) Mish(x)=x\times tanh(ln(1+e^x)) Mish(x)=x×tanh(ln(1+ex))
优点:成本低、平滑、非单调、无上界有下界
Network Slimming
- channel-wise稀疏化
对于稀疏化,可以在不同级别进行实现(weight-level,kernel-level,channel-level,layer-level)。细粒度(weight-level)的稀疏化具有较高的灵活性和泛化性能,且能获得较高的压缩比率,但需要特殊的软硬件加速器支持;粗粒度(layer-level)的灵活性差且只有在网络足够深时才会起到作用。相比之下,channel-wise是个较好的选择。
- 缩放因子
对每个通道我们引入一个缩放因子γ,与通道的输出进行相乘。接着联合训练网络权重和缩放因子,对于不重要的通道或神经元,其缩放因子将会逐渐趋向于0。最终只需将小的缩放因子直接剪除即可实现剪枝。
原本的L1正则化函数修改为:
L = ∑ x , y l ( f ( x , W ) , y ) + γ ∑ γ ∈ Γ g ( γ ) L=\sum_{x,y}l(f(x, W),y)+\gamma\sum_{\gamma\in \Gamma}g(\gamma) L=x,y∑l(f(x,W),y)+γγ∈Γ∑g(γ)
剪掉一个通道的本质是要剪掉所有与这个通道相关的输入和输出连接关系,我们可以直接获得一个窄的网络,而不需要借用任何特殊的稀疏计算包。缩放因子扮演的是通道选择的角色,因为我们缩放因子的正则项和权重损失函数联合优化,网络自动鉴别不重要的通道,然后移除掉,几乎不影响网络的泛化性能。
- BUN层与缩放因子结合
z ^ = z i n − μ σ 2 + ϵ z o u t = γ z ^ + β \hat{z}=\dfrac{z_{in}-\mu}{\sqrt{\sigma^2+\epsilon}}\quad\quad z_{out}=\gamma \hat{z}+\beta z^=σ2+ϵzin−μzout=γz^+β
在选择阈值时,比如我们将剪掉整个网络中70%的通道,那么我们先对缩放因子的绝对值排个序,然后取从小到大排序的缩放因子中70%的位置的缩放因子为阈值,这样就可以得到一个较少参数、运行时占内存小、低计算量的紧凑网络。
后续
喜欢的话可以关注一下我的公众号技术开发小圈,尤其是对深度学习以及计算机视觉有兴趣的朋友,我会把相关的源码以及更多资料发在上面,希望可以帮助到新入门的大家!
