推荐系统二 之图算法:DeepWalk&Node2vec
写在前面
1、Deepwalk 和 Node2vec 这些图算法的本质就是特征提取器,对graph进行采样(Sampling),对采样出来的序列构造模型(embedding),最终把节点转化为特征向量,即为embedding。
2、图算法的优势
graph是对复杂的连接关系建模,通过用户行为序列,能够更好地学的items的高阶相似关系。
同时,在构建数据集的过程中,能够让长尾商品获得更多的训练,弥补数据稀疏的问题,有效提升覆盖率。
一、Deepwalk
1、来源:出自14年KDD:《DeepWalk: Online Learning of Social Representations》
2、思想:Deepwalk的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入word2vec进行训练,得到物品的embedding。
RandomWalk是一种可重复访问已访问节点的深度优先遍历算法。给定当前访问起始节点,从其邻居中随机采样节点作为下一个访问节点,重复此过程,直到访问序列长度满足预设条件。
3、图示:
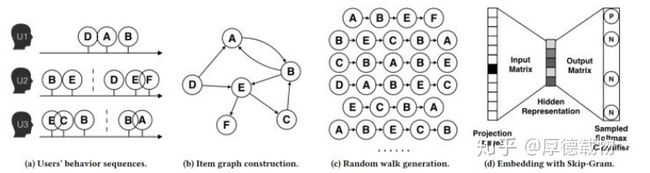
4、算法流程4步:
- )图a展示原始的用户行为序列
- )图b基于这些用户行为序列构建了物品相关图,可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后(原始的deepwalk paper中是没有权重的,就是randomWalk),得到全局的物品相关图。
- )图c采用随机游走的方式随机选择起始点,对每个节点重新生成部分物品序列(采样)。得到局部相关联的训练数据,deepwalk将这组序列当成语言模型的一个短句,最大化给定短句某个中心词时,出现上下文单词的概率。
- )图d最终将这些物品序列输入word2vec模型,生成最终的物品Embedding向量。
5、deepwalk的跳转概率
定义为到达节点vi后,下一步遍历vi的临接点vj的概率。跳转概率和跳转节点的出边权重正相关(跳转概率 = 当前出边权重/所有出边的权重和)。
6、随机游走生成所有单词序列
在语言模型的框架下可以理解为,在给定所有游走过的节点的前提下,下一个游走/访问到的节点是v_i的可能性:
![]()
假设有如下映射函数,得到节点的潜在表示(也就是后面得到的embedding,也就是抽取的节点特征)。
![]()
利用神经概率语言模型建模的知识,则deepWalk中对节点单词表达的概率建模方法就归结为以下最优化问题:
(目标函数是最大似然函数,样本|参数;使用单词来预测context;context是给定节点单词的左右两边w窗口内的单词组成;不考虑句子中context单词出现的顺序,直接最大化所有出现在上下文中单词的概率)

gamma次迭代执行deepwalk算法。每次循环中,先打乱词汇表V,生成一个随机排序来遍历所有节点。然后得到以每个节点为始节点的随机游走序列W_vi,利用语言模型SkipGram更新节点的embedding表达。
二、Node2vec
1、来源:2016年出现的n2v,相较于DeepWalk,是通过调整随机游走权重的方法使graph embedding的结果在网络的同质性(homophily)和结构性(structural equivalence)中进行权衡。
2、思想
用作者的原话来理解: use flexible, biased random walks that can trade off between local and global views of the network。
3、图解
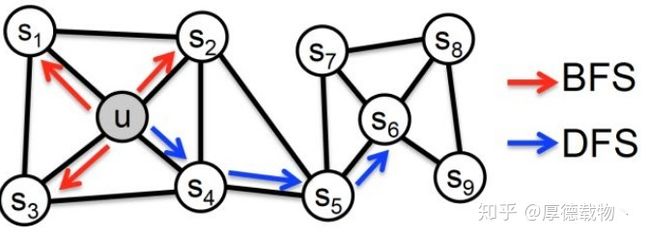
具体来讲,网络的“同质性”指的是距离相近节点的embedding应该尽量近似,如图4,节点u与其相连的节点s1、s2、s3、s4的embedding表达应该是接近的,这就是“同质性“的体现。
“结构性”指的是结构上相似的节点的embedding应该尽量接近,图4中节点u和节点s6都是各自局域网络的中心节点,结构上相似,其embedding的表达也应该近似,这是“结构性”的体现。
node2vec区别于deepwalk,主要是通过节点间的跳转概率。跳转概率是三阶关系,即考虑当前跳转节点,以及前一个节点 到下一个节点的“距离”,通过返回参数p和进出(或叫远离)参数q控制游走的方向(返回还是继续向前)
节点跳转示意图如下:
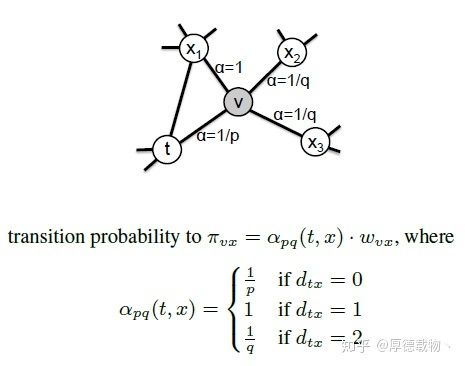
其中,d_tx指的是节点t到节点x的距离,参数p和q共同控制着随机游走的倾向性。
参数p被称为返回参数(return parameter),p越小,随机游走回节点t的可能性越大,node2vec就更注重表达网络的结构性
参数q被称为进出参数(in-out parameter),q越小,则随机游走到远方节点的可能性越大,node2vec更注重表达网络的同质性,反之,当前节点更可能在附近节点游走。
4、算法流程
- )计算转移概率矩阵,即构建全网转移概率图。
(preNode, curNode, [curNode所有邻居dstNode的跳转概率] )
2. )采样,生成训练样本序列
3. )梯度下降优化

维度d,每个节点生成r个长度为l的语料序列。上下文context长度为k。
start node : u
初始节点u和它的邻域表示:{u,s4,s5,s6,s8,s9}
u的邻域:$N_s(u)=(s_4,s_5,s_6,s_8,s_9)$
walk是节点u生成的随机游走的样本结果集。为了便于说明,上下两个伪代码框分别从0开始编号。
第5行到第8行对每个顶点进行r轮游走,生成长度为l的顶点序列,保存在集合walks中。
第9行是做梯度下降优化。推荐使用负采样
5、总结
node2vecWalk部分的第1步是初始化序列walk,只需注意此时walk已经包含了两个元素[pre, curr],然后进行l步n2v游走。第3行获取walk中上一步的节点作为当前节点curr,…剩下就没有难度了。
注意,在GetNeighbors中,对于当前节点curr,可以对所有邻居采样,再计算。
代码写得很清楚,只需要注意构建图的时候,对每个节点先走一步,产生(prevNodeId ,currentNodeId) 这个itempair,在调用node2vecWalk,对currentNodeId走l轮,产生(item1,item2,item3..)
参考:https://zhuanlan.zhihu.com/p/90783845
三、node2vec源码运行
1、下载地址:https://github.com/aditya-grover/node2vec
2、python 版本:src/main.py中修改
1)路径:
default='graph/karate.edgelist'—>default='../graph/karate.edgelist' # 构造的边
default='emb/karate.emb'—>default='../emb/karate.emb' # 生成的模型
2) 做下类型转换
walks = [map(str, walk) for walk in walks]—>walks = [list(map(str, walk)) for walk in walks]
3) save_word2vec_format方法已弃用
model.save_word2vec_format(args.output)—>model.wv.save_word2vec_format(args.output)
3、scala版本
上述项目中node2vec_spark为scala版本的项目
1)导入项目
先删除.idea文件目录,然后在文件src下右键—Make Directory as—Sources Root【否则会出现import本地文件找不到路径的问题】