该系列文章为,观看“吴恩达机器学习”系列视频的学习笔记。虽然每个视频都很简单,但不得不说每一句都非常的简洁扼要,浅显易懂。非常适合我这样的小白入门。
本章含盖
- 7.1 分类
- 7.2 假设陈述
- 7.3 决策界限
- 7.4 代价函数
- 7.5 简化代价函数与梯度下降
- 7.6 高级优化
- 7.7 多元分类:一对多
分类

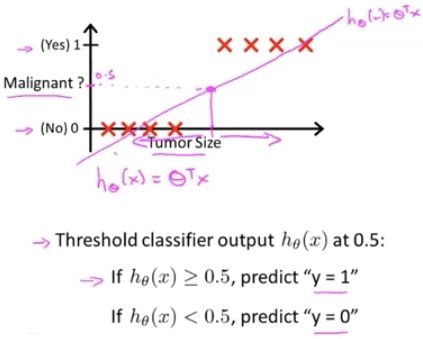
用线性回归拟合分类。
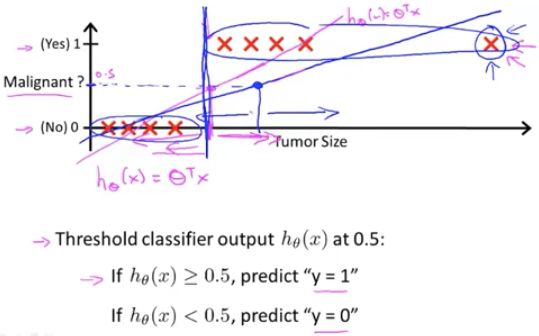
蓝色:加入新的训练集后,之前拟合的线性函数,显然适用于新的数据集。但是,此时我们因为新的数据集的加入,拟合出一个新的线性函数(蓝色),此时,若还用 0.5 作为阈值,那么分类结果就不那么理想了。
这里,新加的样本没有提供任何新的信息。但是却导致线性回归对数据的拟合直线从‘紫色的线’变成了’蓝色的线’,因此产生了一个更坏的假设。
所以,把线性回归应用于分类问题,通常不是一个好主意
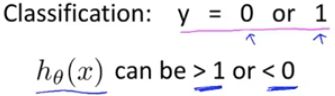
即便样本的数据集只有 0 和 1。但是,算法的结果可能远大于 1 或 远小于 0。 这有些怪。。。

“logistic 回归”算法的特点在于,算法的输出总是介于 0 和 1 之间。
btw,我们把 logistic 回归算法视为一种分类算法。因为名字中有回归,有些时候可能会令人产生困惑,但“logistic 回归”实际上是一个“分类算法”,而不是“回归算法”。
logistic 回归算法用在: y 为离散值 0 或 1 的情况下
7.2 假设陈述
假设:即,出现一个分类问题的时候,我们要使用哪个方程?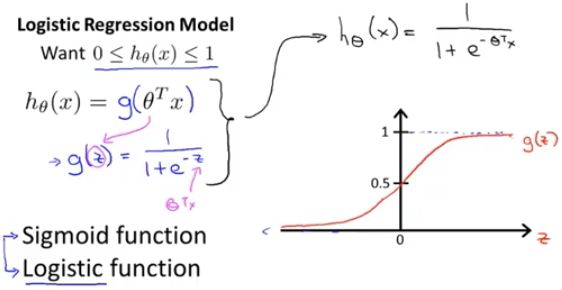
线性回归的假设函数:h_θ(x) = Θ^T * x
logistic 回归方程的假设函数为:h_θ(x) = g(Θ^T * x)
我们定义 g 函数为:g(z) ,如果 z 是一个实数,那么 g(z) = 1/(1+e^-z)
这是 sigmoid function 或 logistic function。这两个术语基本上是同义词。
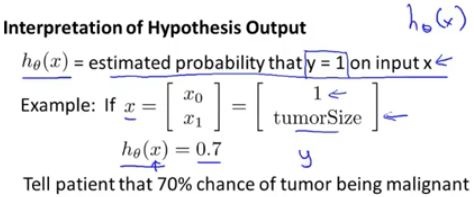
h_θ(x) 表示 一个新的输入值x,其应用于这个h_θ(x)时,得到的输出为 1 的概率。
如, 对于一个特征为x(该患者肿瘤大小的值)的患者,y=1 的概率是 0.7

h_θ(x) = P( y =1 | x;θ )
7.3 决策界限
decision boundary(决策边界):
 给定了 x,参数为 θ 时,y = 1 的概率。
给定了 x,参数为 θ 时,y = 1 的概率。
也就是说,我们将预测 y=1 ,只需要 Θ^Tx 大于等于0,这取决于我们定义的 h_θ(x) >= 0.5 时 y = 1;
实例:
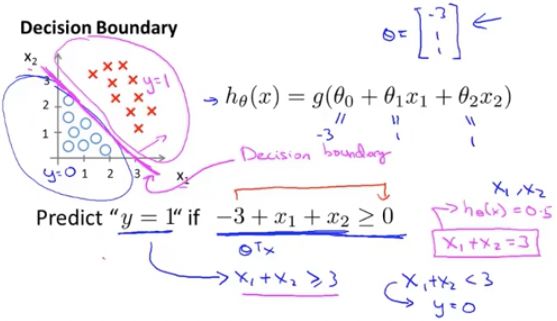
决策边界,是假设函数的一个属性。以及,这里说的 y = 0 ,y = 1 它们都是假设函数的属性。
一旦参数确定下来,我们就能够完全确定“决策边界”。
一个更复杂的例子:

该例子中,Θ_3 * x_1^2 + Θ_4 * x_2^2 就是额外增加的那个高阶多项式。。。
再次强调,“决策边界”不是训练集的属性。而是“假设函数”本身及其参数的属性。只要给定了参数向量Θ,决策边界就决定了。
我们不是用训练集来决定“决策边界”,我们用训练集来拟合参数。
7.4 代价函数
用于拟合参数的优化目标或者叫代价函数
对这个代价函数的理解是:它是在,输出的预期值是h(x),而实际的标签是y的情况下,我们希望学习算法付出的代价。
如果,我们能够最小化函数J里面的这个代价函数,它也能工作。但实际上,如果我们使用这个代价函数,它会变成参数 Θ 的非凸函数。
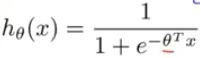
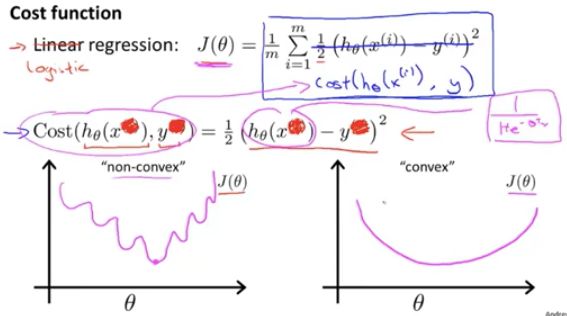
左图为目前,J(Θ) 的效果图,是一个非凸函数,它有很多的局部最优解。
所以,目前这个平方代价函数的问题是,中间这个非线性的sigmoid函数,导致J(Θ) 成为一个非凸函数,如果你用平方函数定义它的话。
所以,我们需要找另外一个不同的代价函数,它是凸函数,使得我们可以使用很好的算法(如,梯度下降法)找到全局最小值。

当h(x)趋于 0 时,即,当假设函数的输出趋于 0 时,代价函数激增,且趋于无穷大。之所以这样描述,是因为我们认为,如果假设函数的输出为 0 ,那么相当于说我们的假设函数输出,相对于 y = 1 的概率等于 0 来说,有非常非常大的代价,以此来惩罚我们的学习算法。(因为,这里非分类只有 yes or no 的区别)
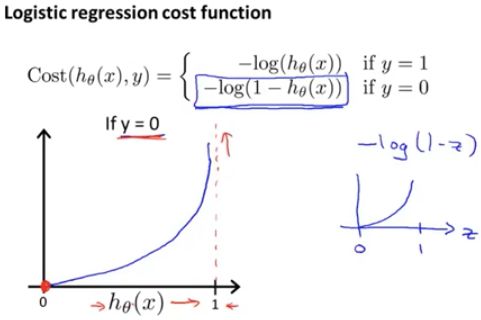
7.5 简化代价函数与梯度下降

对于分类问题,在我们训练集中,甚至不在训练集中的样本,y 的值总是等于 0 或 1。正因为如此,我们可以使用一个方式写这个代价函数。

分别把 y = 1,和 y = 0 带入下面的公式,自然就会得到上面的公式了。
这个式子是从统计学中的极大似然法得来的。它是统计学中为不同的模型快速找到参数的方法。同时,它还有一个很好的性质,它是凸的。因此,它就是大部分人用来拟合logistic回归模型的代价函数


这个梯度下降法的公式同我们前面对线性回归做梯度下降法时是一样的!!
那么,线性回归和logistic回归是同一个算法吗?
不是的,请注意。在logistic回归中,h(θ) 的定义发生了变化。
所以只是梯度下降法的规则看起来相似而已,但实际上规则中的假设函数(h(θ))已经发生了变化。所以,它和线性回归的梯度下降法实际上是两个完全不同的东西。
我们使用同线性回归的梯度下降法同样的监控方法,监控logistic回归的梯度下降法是否收敛。
当使用梯度下降法来实现logistic回归时,我们有这些( θ。即,θ_0 ~ θ_n)不同的参数要用这个表达式(logistic的梯度下降法)来同时更新这些参数。
实现的方式有2中:
1,使用for循环,从 0 ~ n 逐个更新
2,使用向量化的实现。向量化的实现可以把所有 n+1 个参数同时更新。
特征缩放同样也适用于 logistic 回归,使得梯度下降收敛更快。
7.6 高级优化
高级优化算法同梯度下降法相比大大提高了logistic回归运行的速度。这也使得算法更加适合解决大型的机器学习问题,比如,我们有数目庞大的特征。
现在,我们换个角度来看什么是梯度下降
我们需要写出代码来计算 J(θ) 和 它的偏导数,然后把这些带入梯度下降中。然后,它就可以为我们最小化J(θ)这个函数
梯度下降,从技术上来说,你实际并不需要编写代码来计算代价函数J(θ),你只需要编写代码来计算导数项。但是,如果你希望代码还能够监控这些J(θ)的收敛性,那么我们就需要自己编写代码来计算代价函数和偏导数项。

梯度下降并不是我们能够使用的唯一算法,还有其他一些算法更高级、更复杂。如果我们能够使用这些算法来计算 J(θ) 和 它的偏导数,那么这些算法就是为我们优化代价函数的不同方法。
BFGS —— 共轭梯度法 和 L-BFGS 就是其中一些更高级的优化算法。它们需要一种方法来计算 J(θ) ,还需要一个计算导数项的方法。然后使用比梯度下降法更复杂的算法来最小化代价函数

Conjugate gradient、BFGS、L-BFGS 这三种算法有很多优点。
1,使用其中任何一个算法,你通常不需要手动选择 学习率α。
所以理解这些算法的一种思路是:给出‘计算导数项和代价函数’的方法。你可以理解这些算法有个智能的内循环,事实上它确实有个智能的内循环,称为’线搜索算法’,它可以自动尝试不同的 学习速率α 并自动选择一个好的 学习速率α 。它甚至可以每次迭代选择不同的学习速率,那么你就不需要自己选择。
2,这些算法实际上在做更复杂的事情,而不仅仅是选择一个好的学习速率α。所以它们往往最终收敛得远远快于梯度下降。
缺点:
1,它们比梯度下降法复杂多了。
特别是,你最好不要自己实现 共轭梯度法、L-BFGS 这些算法,除非你是数值计算方面的专家。
注意,不同库对这些算法的实现也是有差距的!! 毕竟库也是别人对该算法实现的封装而已。
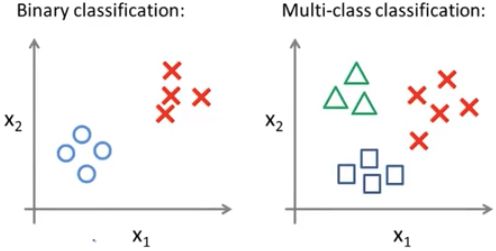
7.7 多元分类:一对多
使用 logistic 回归 解决‘多类别分类问题’
“一对多”分类算法

所有的例子中,y 可以取 一些 离散值。
‘一对多 分类’ 原理:
有时也称为“one-versus-rest”方法
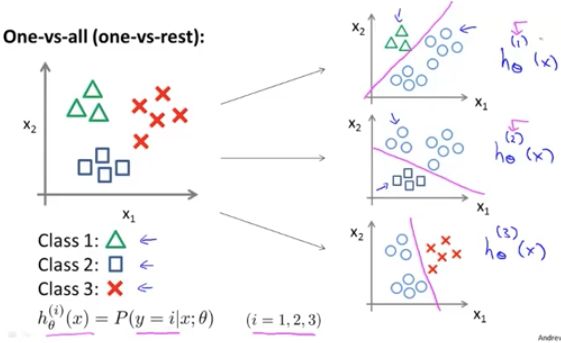
假设,我们有一个训练集,其中有三个类型。我们要做的就是将这个训练集转化为 3个独立的二元分类问题
新的“伪”训练集,其中的类别2 和类别3 设定为 负类,类别1 设定为 正类。
其他两个,同理可得。。。
总而言之,我们拟合出三个分类器。来尝试估算出给定 x 和 θ 时, y = i 的概率。
-
总结:

我们训练一个logistic 回归分类器,h_θ^(i)(x)用于,类别 i 去预测 y = i 的概率。
然后在新给定的输入 x ,做预测,选择 类别 i 最大的那个 类别为我们预测的 x 的类别。