本文主要用于记录发表于2014年的一篇神作(引用量破5k)。该论文第一次将注意力机制引入了NLP领域,而本笔记意在方便初学者快速入门,以及自我回顾。
论文链接:https://arxiv.org/pdf/1409.0473.pdf
基本目录如下:
- 摘要
- 核心思想
- 总结
------------------第一菇 - 摘要------------------
1.1 论文摘要
近年来,基于神经网络的机器翻译模型经常被用来处理机器翻译任务。与传统基于统计的翻译方法相比,神经机器翻译模型意在构建单个神经网络模型来提升整体翻译准确率,主要的模型架构基本都是seq2seq家族的(不熟的同学可以参考我上一篇对seq2seq模型的论文笔记)。在本论文中,作者认为该模型的瓶颈主要在于中间转换的固定纬度大小的向量。因此,作者提出了一种新的解码方式,其解码的源头并不仅仅包括该向量,他们希望构建一种为当前预测词从输入序列中自动搜寻相关部分的机制(soft-search,也就是注意力机制)。作者运用这种新的机制来搭建升级版的神经机器翻译模型,取得了卓越的效果,并且也通过定量分析来证明这种注意力机制的合理性。
------------------第二菇 - 核心思想------------------
2.1 注意力机制解决的问题
在深入模型细节之前,我先来聊一下为什么会需要引入注意力机制,该机制到底在解决什么问题,以此来加深大家的理解。
熟悉seq2seq基本框架的朋友应该都知道,当前输出词仅取决于当前隐状态以及上一个输出词,即
潜在的问题就是,在编码输入序列时,该模型框架需要压缩(compress)所有的信息在一个固定长度的向量中(虽然这个向量的长度其实也是可以变化的),这就会让该模型在面对长句的时候显得十分无力(seq2seq论文中的图也表明当大于35个字的时候,模型的表现直线下降),而且随着序列的增长,句子越前面的词的信息就会丢失的越厉害,虽然有几个小trick来解决这些问题,比如倒序输入句子一遍,或者重复输入两遍,或者使用LSTM模型。但这些都治标不治本,对模型的提升微乎其微,因为在解码时,当前预测词对应的输入词的上下文信息,位置信息等基本都已丢失。
为了解决这个问题,才引入了注意力机制,该机制的本质其实就是引入了当前预测词对应输入词的上下文信息以及位置信息。或者用论文中比较易懂的说法就是,我们现在这个模型不再是傻乎乎的把输入序列编码为一个固定向量,再去解码这个固定向量;我们现在的解码本质上是自动从这个固定向量中抽取有用的信息来解码我的当前词。
2.2 论文模型结构
该模型的编码部分并没有什么特别的创新点,无非就是把传统的一些小技巧运用上去,用了双向的Bi-RNN作为编码器,而其隐状态自然也就包括了正向与逆向输入的两部分,使得模型对输入序列由更好的表达
在新的模型架构里,当前的输出词仍然取决于当前隐状态及上一个输出词,但是文本向量不再是那个固定纬度大小的向量,而是新的文本向量,如下:
而这个新的文本向量的引入和计算就是整个注意力机制的核心,改名一下叫它为语境向量好了。而其本质也很简单,就是一个全部隐状态h_1, h_2...h_T的一个加权和,
其中的注意力权重参数也是由另一个神经网络训练得到的,
其中a就是一个对齐模型,用来评估当前预测词,与输入词每一个词的相关度(我们肯定更希望要翻译的那个词,能完整获取到那个词的上下文及位置信息,而对其他词并不是特别关心)。而这个网络的输入就是上一个输出序列隐状态和输入序列隐状态,然后最后再走一个softmax作归一化,这样就能计算出权重了。直观的理解就是在解码的时候,我们希望解码的信息是直接与预测词相关的,或者说我们更集中注意于那部分与我们预测词相关的部分。而这种思想反馈到对齐模型上就是,在生成一个输出词的时候,会考虑每一个输入词与当前词的对齐关系,对齐越好的词,应该享有更大的权重,自然对预测当前词会产生更大的影响。这里我盗用一张网上的图【1】,来让大家更加直观的理解对齐模型的计算方式,

大家关注一下红线的部分,就是对齐模型的输入与输出。以及整张图能诠释整个对齐模型的输出,是如何影响最后输出。
至此,整个新的模型架构就介绍完了,对论文作者的模型细节感兴趣的读者可以详细看一下论文的附录部分(Model Architecture)。值得一提的是,论文中也说明了该对齐模型并非传统统计翻译模型中的隐变量,而是可以直接从反向传播回来的误差中直接更新梯度,因此这个对齐模型,可以在训练整个模型框架的时候一起被训练。
2.3 论文实验结果分析
具体的实验结果这里就不展现了,原文中也表述的十分清晰,该框架模
型的结果还是杠杠的,这里具体谈2个比较有趣且有价值的点。
1)对齐模型的表现
该论文在定量分析中特地可视化了由对齐模型产生的权重值,这里也贴一张论文的原图,
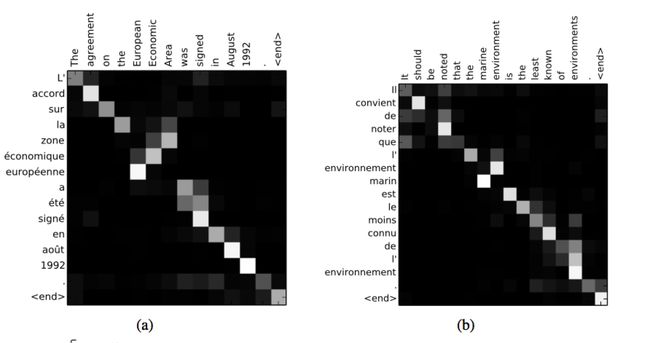
不难想象,不考虑什么语法情况的话,理论上应该是这个矩阵的对角线享有最大的权重,而作者贴出的图也论证了我们的猜想,以及证明了对齐模型的学习有效性。当然,并非每一个词都是很理想化的一一对应,尤其是有些形容词和名词,作者还特地强调了一些Zone和Area的对齐情况(这中间可是隔了2个词)。此外,该对齐模型也不会要求输入句子与输出句子的长度的一致,这对我们的训练和应用都能带来极大的益处。
2)长句翻译的表现
显然本文模型的提出就是为了来提升长句的翻译表现的,而事实也证明了模型的可行性。原文有更多更细致的例子来对照(然而我看不懂法文,所以并不是特别有感),不过还是强行贴一张实验的结果图(对长句对表现还是很稳定对)在这里,对细节感兴趣的读者还得多看一眼原文。

------------------第三菇 - 总结------------------
3.1 总结
到这里,整篇论文的核心思想及其创新点已经说清楚了。这套注意力机制模型,也为后续更多注意力机制的变体奠定了基础。论文作者也是对对齐模型的效能大为赞赏(major positive impact),并且用实验论证了该模型对长句翻译能力的提升。
简单总结一下本文就是先罗列了一下该论文的摘要,再具体介绍了一下模型细节,尤其是注意力机制那一块的理论,最后再列举了几个实验结果来结束该论文笔记。希望大家读完本文后能进一步加深对该论文的理解。有说的不对的地方也请大家指出,多多交流,大家一起进步~
参考文献:
【1】https://blog.csdn.net/u011414416/article/details/51057789