2021第一篇刷题笔记。今早开晨会领导也说了一句话:每天进步一点点。长年累月就是翻天覆地的变化。好了,不多说闲话啦,刷题继续。
前K个高频单词
题目:给一非空的单词列表,返回前 k 个出现次数最多的单词。返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
示例 1:
输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2
输出: ["i", "love"]
解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。
注意,按字母顺序 "i" 在 "love" 之前。
示例 2:
输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4
输出: ["the", "is", "sunny", "day"]
解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词,
出现次数依次为 4, 3, 2 和 1 次。
注意:
假定 k 总为有效值, 1 ≤ k ≤ 集合元素数。
输入的单词均由小写字母组成。
扩展练习:
尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。
思路:如果不考虑扩展中的时间空间复杂度的话,这个题还是比较容易的。比如单纯的用map计数。然后统计出现的频率。最后得出结果。然后考虑时间空间复杂度我也觉得这个思路没啥问题,我去写代码试试。
贴第一版代码:
class Solution {
public List topKFrequent(String[] words, int k) {
Map map = new HashMap();
for(String s:words) {
map.put(s, map.getOrDefault(s, 0)+1);
}
//所有的key放到list
List list = new ArrayList(map.keySet());
//排序规则:如果频率相同则字段排序,频率不同大的靠前
Collections.sort(list, (s1,s2)->map.get(s1).equals(map.get(s2))?s1.compareTo(s2):map.get(s2)-map.get(s1));
//截取前k个元素
return list.subList(0, k);
}
}
我竟然没get到这个题的难点在哪里,反着这个代码ac了性能也还行。我去看看题解吧:
看到一个天秀的写法,java一句话搞定:
return Arrays.stream(words)
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()))
.entrySet()
.stream()
.sorted((o1, o2) -> {
if (o1.getValue().equals(o2.getValue())) {
return o1.getKey().compareTo(o2.getKey());
} else {
return o2.getValue().compareTo(o1.getValue());
}
})
.map(Map.Entry::getKey)
.limit(k)
.collect(Collectors.toList());
怎么说呢,反正不要任何逻辑单纯看上面答案的话我觉得很帅,但是我要维护的项目里这么写我大概会打死上一个开发。。。真的是天秀,感觉这个题也就这样了,下一题。
岛屿的最大面积
题目:给定一个包含了一些 0 和 1 的非空二维数组 grid 。一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)
示例 1:
[[0,0,1,0,0,0,0,1,0,0,0,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,1,1,0,1,0,0,0,0,0,0,0,0],
[0,1,0,0,1,1,0,0,1,0,1,0,0],
[0,1,0,0,1,1,0,0,1,1,1,0,0],
[0,0,0,0,0,0,0,0,0,0,1,0,0],
[0,0,0,0,0,0,0,1,1,1,0,0,0],
[0,0,0,0,0,0,0,1,1,0,0,0,0]]
对于上面这个给定矩阵应返回 6。注意答案不应该是 11 ,因为岛屿只能包含水平或垂直的四个方向的 1 。
示例 2:
[[0,0,0,0,0,0,0,0]]
对于上面这个给定的矩阵, 返回 0。
注意: 给定的矩阵grid 的长度和宽度都不超过 50。
思路:这个题我做过类似的,反正第一反应就是递归。以前有个朋友圈的题目,就是有关系的算一个圈,最多看有多少个圈。这个题其实可以算是朋友圈的变种。有关系的算一个圈,找出圈中人数最多的那个数目?思路很清晰,我去撸代码。
第一版ac代码:
class Solution {
int max = 0;
public int maxAreaOfIsland(int[][] grid) {
int res = 0;
if(grid.length==0 || grid[0].length == 0) return res;
for(int i = 0;i0 && grid[x-1][y]==1) dfs(grid, x-1, y);
if(y>0 && grid[x][y-1]==1) dfs(grid, x, y-1);
if(x 虽然题目挺简单,但是暂时也找不到优化点,我直接去看性能第一的代码了:
class Solution {
public int maxAreaOfIsland(int[][] grid) {
int m=grid.length,n=grid[0].length;
int sum=0;
for(int i=0;i=0&&i=0&&j 差不多的思路,就是处理上的细节。我这里是单纯的有个1加一次。用全局变量计数。人家是返回是1的个数。反正这个题总而言之思路就这样,下一题。
划分为k个相等的子集
题目:给定一个整数数组 nums 和一个正整数 k,找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。
示例 1:
输入: nums = [4, 3, 2, 3, 5, 2, 1], k = 4
输出: True
说明: 有可能将其分成 4 个子集(5),(1,4),(2,3),(2,3)等于总和。
提示:
1 <= k <= len(nums) <= 16
0 < nums[i] < 10000
思路:这个题的大概想法:第一步算出数组总和,看能不能被k整除,不能直接false。还有最大元素不能大于商,否则永远也分割不了。这些都没问题了再去做几数之和等于sum/k。等于则消除。需要注意的是要尽量用较大的元素小消除,比如 4,5,9 最后差一个9的话,要尽量选直接是9的而不要选择九个1,因为九个1比一个9更灵活。而且注意这个数组的长度小于等于16?范围这么小的么。。。啧啧,反正目前的思路就是这样,我去写代码试试。
只能说这个题不愧最大数只有16个,死去活来的调试,我先贴第一版本的代码:
class Solution {
public boolean canPartitionKSubsets(int[] nums, int k) {
int sum = 0;
for(int i = 0; i < nums.length; i++) sum += nums[i];
if(sum % k != 0) return false;
sum = sum / k;//子集的和
Arrays.sort(nums);
//如果子集的和小于数组最大的直接返回false
if(nums[nums.length - 1] > sum) return false;
//建立一个长度为k的桶
int[] arr = new int[k];
//桶的每一个值都是子集的和
Arrays.fill(arr, sum);
//从数组最后一个数开始进行递归
return dfs(nums, nums.length - 1, arr);
}
public boolean dfs(int[] nums,int idx,int[] arr) {
if(idx<0) return true;//所有元素都放完了
for(int i = 0;i=nums[0])) {
arr[i] -= nums[idx];//当前元素放进桶,递归看是不是true
if(dfs(nums, idx-1, arr)) return true;
arr[i] += nums[idx];//当前元素放这个桶不行,所以拿出来
}
}
//走到这步说明当前元素放哪都不行了,所以false
return false;
}
}
因为这个题我调试了好多次,所以注释写的挺全的,毕竟是为了方便自己的理解。简单来说这个题的主要目的就是分桶。本来我是想用最开始的思路去凑成一个个目标和为子元素和的target。看能不能凑成k个。
但是这样最大的问题就是元素使用问题:因为倒数第二个测试案例10,10,10,7,7,7,7,7,7,6,6,6.这个测试你案例分三个桶,正常应该和是30.如果我较大的数字优先使用,那么前三个10就凑成一个30,然后后面的就怎么都凑不成了。所以这个思路就这么pass了,其实到这里我是想出办法优化了的,比如这里发现前三个凑一起false,那么退一位前两个,再退一位前一个和所有的凑,凡是debug起来死去活来的,就12个元素我这边都点下一步点的手抽筋了,所以开始想还有没有别的好一点的实现方法。最终如上面的代码差不多思路:
其实这里是用满桶往下减还是用空桶往上加都可以。反正最终每一个元素都可以安排的明明白白的就行。上面代码性能也挺好的了,我再去看看题解吧。看有没有什么更有意思的思路:
行吧,官方题解据说是dp解法的,我没看懂,贴上来分享下就过了:
boolean search(int used, int todo, Boolean[] memo, int[] nums, int target) {
if (memo[used] == null) {
memo[used] = false;
int targ = (todo - 1) % target + 1;
for (int i = 0; i < nums.length; i++) {
if ((((used >> i) & 1) == 0) && nums[i] <= targ) {
if (search(used | (1< 0) return false;
Boolean[] memo = new Boolean[1 << nums.length];
memo[(1 << nums.length) - 1] = true;
return search(0, sum, memo, nums, sum / k);
}
然后这个代码的性能还不如我上面自己写的呢,所以就不多说了,下一题。
二叉搜索树中的插入操作
题目:给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 输入数据 保证 ,新值和原始二叉搜索树中的任意节点值都不同。注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回 任意有效的结果 。
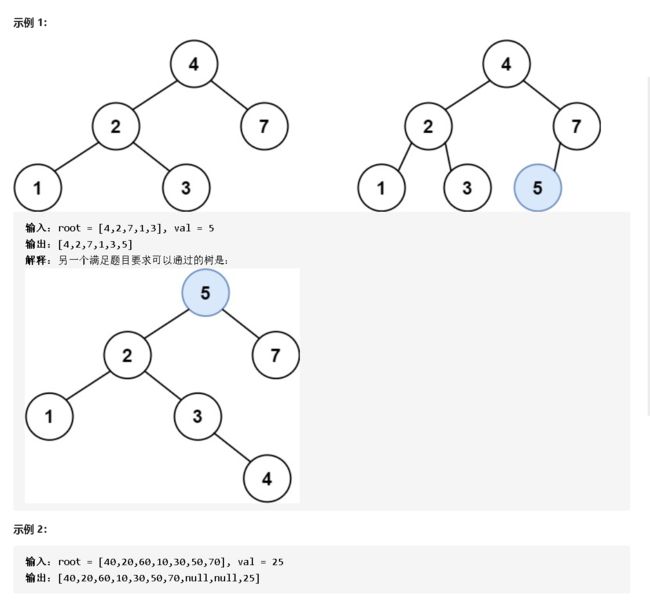
思路:这个题怎么说呢,暂时没get到难点在哪里,遵循左小右大不就行了么,我的想法是往最后一层插入。应该肯定能插进去。我去代码试一下吧
两次ac,第一次被卡在给定root是null的情况下,真的是一言难尽,我直接贴代码:
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public TreeNode insertIntoBST(TreeNode root, int val) {
if(root == null) return new TreeNode(val);
dfs(root, val);
return root;
}
public void dfs(TreeNode root, int val) {
if(root.val>val) {
if(root.left == null) {
root.left = new TreeNode(val);
return;
}else {
dfs(root.left, val);
}
}else {
if(root.right == null) {
root.right = new TreeNode(val);
return;
}else {
dfs(root.right, val);
}
}
}
}
因为这个题不是很难,所以就下一题了,没啥好说的。
设计链表
题目:设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index 等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
示例:
MyLinkedList linkedList = new MyLinkedList();
linkedList.addAtHead(1);
linkedList.addAtTail(3);
linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3
linkedList.get(1); //返回2
linkedList.deleteAtIndex(1); //现在链表是1-> 3
linkedList.get(1); //返回3
提示:
所有val值都在 [1, 1000] 之内。
操作次数将在 [1, 1000] 之内。
请不要使用内置的 LinkedList 库。
思路:这个题就是开放式题,简单来说我的思路就是用ArrayList?他只说不要用内置的LinkedList了啊。。然后头插就是add 在index=0的,尾插就是正常追加。。。然后这个题的考点呢?什么鬼。。有点蒙,我不确定这么实现是不是在要求内的。要不然自己写个链表也行啊,但是这样删除指定下标元素的话就是从头理到那个下标再去删除。。。所以种种实现方式我选择去看题解。。
public class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
class MyLinkedList {
int size;
ListNode head; // sentinel node as pseudo-head
public MyLinkedList() {
size = 0;
head = new ListNode(0);
}
/** Get the value of the index-th node in the linked list. If the index is invalid, return -1. */
public int get(int index) {
// if index is invalid
if (index < 0 || index >= size) return -1;
ListNode curr = head;
// index steps needed
// to move from sentinel node to wanted index
for(int i = 0; i < index + 1; ++i) curr = curr.next;
return curr.val;
}
/** Add a node of value val before the first element of the linked list. After the insertion, the new node will be the first node of the linked list. */
public void addAtHead(int val) {
addAtIndex(0, val);
}
/** Append a node of value val to the last element of the linked list. */
public void addAtTail(int val) {
addAtIndex(size, val);
}
/** Add a node of value val before the index-th node in the linked list. If index equals to the length of linked list, the node will be appended to the end of linked list. If index is greater than the length, the node will not be inserted. */
public void addAtIndex(int index, int val) {
// If index is greater than the length,
// the node will not be inserted.
if (index > size) return;
// [so weird] If index is negative,
// the node will be inserted at the head of the list.
if (index < 0) index = 0;
++size;
// find predecessor of the node to be added
ListNode pred = head;
for(int i = 0; i < index; ++i) pred = pred.next;
// node to be added
ListNode toAdd = new ListNode(val);
// insertion itself
toAdd.next = pred.next;
pred.next = toAdd;
}
/** Delete the index-th node in the linked list, if the index is valid. */
public void deleteAtIndex(int index) {
// if the index is invalid, do nothing
if (index < 0 || index >= size) return;
size--;
// find predecessor of the node to be deleted
ListNode pred = head;
for(int i = 0; i < index; ++i) pred = pred.next;
// delete pred.next
pred.next = pred.next.next;
}
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList obj = new MyLinkedList();
* int param_1 = obj.get(index);
* obj.addAtHead(val);
* obj.addAtTail(val);
* obj.addAtIndex(index,val);
* obj.deleteAtIndex(index);
*/
代码就这样了,这个题我觉得更没啥好说的,下一题。
两个字符串的最小ASCII删除和
题目:给定两个字符串s1, s2,找到使两个字符串相等所需删除字符的ASCII值的最小和。
示例 1:
输入: s1 = "sea", s2 = "eat"
输出: 231
解释: 在 "sea" 中删除 "s" 并将 "s" 的值(115)加入总和。
在 "eat" 中删除 "t" 并将 116 加入总和。
结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。
示例 2:
输入: s1 = "delete", s2 = "leet"
输出: 403
解释: 在 "delete" 中删除 "dee" 字符串变成 "let",
将 100[d]+101[e]+101[e] 加入总和。在 "leet" 中删除 "e" 将 101[e] 加入总和。
结束时,两个字符串都等于 "let",结果即为 100+101+101+101 = 403 。
如果改为将两个字符串转换为 "lee" 或 "eet",我们会得到 433 或 417 的结果,比答案更大。
注意:
0 < s1.length, s2.length <= 1000。
所有字符串中的字符ASCII值在[97, 122]之间。
思路:这个题可以简单的理解为找出两个字符串的最大公共子序列,并且使其ASCII编码最大(因为总编码是一定的,留下的越大删除的越小。)按照这个思路我们可以先获取最大公共子序列,因为字符码没有倍数关系,不存在某两个字符顶一个字符,所以肯定是找最大公共子序列。可能结果有多个,但是选择ASCII编码最大的那个。我去实现下试试
ac了,这个题不算难,我先贴代码再解释:
class Solution {
public int minimumDeleteSum(String s1, String s2) {
int len = s1.length();
int len2 = s2.length();
int sum = 0;
for(int i = 0;i这里我的思路和上面的差不多,一开始是求出最长子序列的长度,用的是常规的dp计数法,代码如下:
public int minimumDeleteSum(String s1, String s2) {
int len = s1.length();
int len2 = s2.length();
int[][] dp = new int[len+1][len2+1];
for(int i =0;i这样一个方法是求出最长子序列的长度的。但是这里有一个问题,可能同样长度有好多,所以怎么找出最长子序列的ASCII码最大值呢?于是乎这里不要用计数的方式,而是直接记ASCII码。也无所谓长度不长度的,反正码大就行。
然后最后的结果其实是最大的子序列的ASCII码的值。
又因为两个字符串都保存这些字符,所以*2就是有用的字符。总数-有用的就是删除了的字符。
感觉思路没啥问题,我去看看性能第一的代码了:
class Solution {
public int minimumDeleteSum(String s1, String s2) {
char[] c1 = s1.toCharArray();
char[] c2 = s2.toCharArray();
int m = c1.length;
int n = c2.length;
int[] dp = new int[n + 1];
for(int i = n - 1; i >= 0; i--) {
dp[i] = dp[i + 1] + c2[i];
}
for(int i = m - 1; i >= 0; i--) {
int pre = dp[n];
dp[n] += c1[i];
for(int j = n - 1; j >= 0; j--) {
int temp = dp[j];
if(c1[i] == c2[j]) {
dp[j] = pre;
} else {
dp[j] = Math.min(dp[j] + c1[i], dp[j + 1] + c2[j]);
}
pre = temp;
}
}
return dp[0];
}
}
感觉思路差不多,只不过人家是倒着往前算的。。还算是比较好看懂,这个题就这样了啊。
乘积小于K的子数组
题目:给定一个正整数数组 nums。找出该数组内乘积小于 k 的连续的子数组的个数。
示例 1:
输入: nums = [10,5,2,6], k = 100
输出: 8
解释: 8个乘积小于100的子数组分别为: [10], [5], [2], [6], [10,5], [5,2], [2,6], [5,2,6]。
需要注意的是 [10,5,2] 并不是乘积小于100的子数组。
说明:
0 < nums.length <= 50000
0 < nums[i] < 1000
0 <= k < 10^6
思路:这个题怎么说呢,暴力法就是遍历。因为是连续数组,所以直到下一个不合适的位置就好了,但是我觉得有可能会超时,一会儿可以试试。而优化算法呢,就是滑窗。下一个元素不用从下下一个开始一个个往后算了, 前面符合要求的后面肯定也符合。反正有很明确的思路,我去实现试试
我就这么说吧,当我第一次看到测试案例的无数个1,我就是知道我超时了。然后第二次看到测试案例无数个1里面混了一个6,我就知道这个测试案例太骚了。先贴代码:
class Solution {
public int numSubarrayProductLessThanK(int[] nums, int k) {
int sum = 1;
int res = 0;
int j = 0;
for(int i = 0;i=k) continue;
j = Math.max(i,j);
for(;j=k) break;
}
//j到这里一定是第一个不满足条件的下标(也可能是没元素了)
res += j-i;
//因为乘第j个已经超过了,所以退回到没超过的时候
if(j 思路蠢得要死,但是都做了三分之二了,所以咬牙用这个思路做了下来。我觉得这个思路应该挺屌的,不知道为啥我实现起来性能这么差,应该就是我这个人的问题。。我去看看性能排行第一的代码:
class Solution {
public int numSubarrayProductLessThanK(int[] nums, int k) {
if (nums == null || nums.length == 0 || k <= 1) return 0;
int count = 0, prod = 1;
for (int i = 0, j = 0; i < nums.length; i++) {
prod *= nums[i];
while (prod >= k) {
prod /= nums[j++];
}
count += i - j + 1;
}
return count;
}
}
这个思路和我的多像啊,也就思路像,处理起来完全比不上,心都碎了。
一个很完美的双指针。j是左边的下标。i是最后的下标。一开始左边的固定,右边的往后走,发现溢出了左边下标右移。
反正是看能看懂,写又写不出来。太难了。
本篇笔记就记到这里,如果稍微帮到你了记得点个喜欢点个关注,也祝大家工作顺顺利利!生活健健康康!