Chapter 4
1. 最小二乘和正规方程
1.1 最小二乘的两种视角
从数值计算视角看最小二乘法
我们在学习数值线性代数时,学习了当方程的解存在时,如何找到\(\textbf{A}\bm{x}=\bm{b}\)的解。但是当解不存在的时候该怎么办呢?当方程不一致(无解)时,有可能方程的个数超过未知变量的个数,我们需要找到第二可能好的解,即最小二乘近似。这就是最小二乘法的数值计算视角。
从统计视角看最小二乘法
我们在数值计算中学习过如何找出多项式精确拟合数据点(即插值),但是如果有大量的数据点,或者采集的数据点具有一定的误差,在这种情况下我们一般不采用高阶多项式进行拟合,而是采用简单模型近似数据。这就是最小二乘法的统计学视角。
1.2 数值计算的角度推导正规方程
对于线性方程组\(\textbf{A}\bm{x}=\bm{b}\),\(\textbf{A}\)为\(n\times m\)的矩阵,我们将\(\textbf{A}\)看做\(\textbf{F}^m \rightarrow \textbf{F}^n\)的线性映射。对于映射\(\textbf{A}\),方程组无解的情况对应于\(\bm{b}∉\text{range}(\textbf{A})\),即\(\bm{b}\)不在映射\(\textbf{A}\)的值域内,即\(b∉ \{\textbf{A}\bm{x} | \bm{x}∈\textbf{R}^{m}\}\)。(而这等价于\(\bm{b}\) 不在矩阵\(\textbf{A}\)的列向量 的张成空间中)。我们对于
将\(\left( \begin{matrix} 1\\ 1\\ 1 \end{matrix}\right)\)视为列向量\(\bm{a}_1\),\(\left(\begin{matrix}1\\-1\\1\end{matrix}\right)\)视为列向量\(\bm{a}_2\),\(\left(\begin{matrix}2\\1\\3\end{matrix}\right)\)视为列向量\(\bm{b}\),则该线性系统如下图所示:
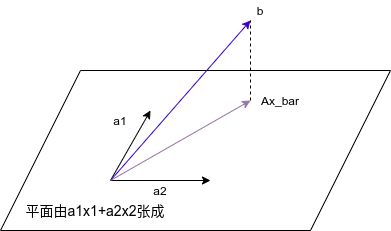
虽然解\(\bm{x}\)不存在,但我们仍然想要找到所有候选点构成的平面\(\textbf{A}\bm{x}\)中存在的与\(\bm{b}\)最接近的点\(\overline{\bm{x}}\)(读作\(\bm{x}\)_bar)。
观察图1,我们发现特殊向量\(\textbf{A}\)具有以下特点:余项\(\bm{b}-\textbf{A}\overline{\bm{x}}\)和平面\(\{\textbf{A}\bm{x} | \bm{x} \in \textbf{R}^n \}\)垂直。即对于\(\textbf{R}^n\)上的所有\(\bm{x}\),都有向量\(\textbf{A}\bm{x}\)和向量\(\bm{b}-\textbf{A}\overline{\bm{x}}\)正交,即\(\langle \textbf{A}\bm{x},\bm{b}-\textbf{A}\overline{\bm{x}}\rangle \geqslant0\),写成矩阵乘法的形式,我们有:
基于矩阵转置的性质,我们有:
因为对\(\bm{x}\)取任意值该式子都满足,那我们必须有:
然后我们就得到了正规方程(因为我们这里用法线推导出来的,也可称为法线方程):
该方程的解\(\overline{\bm{x}}\)是方程组\(\textbf{A}\bm{x} = \bm{b}\)的最小二乘解。如果我们采用数值优化的形式而不是解析的形式,这个最小二乘解也可以看做优化式子\(\underset{x}{\text{argmin}} \frac{1}{2} ||\textbf{A}\bm{x} − \bm{b}||^2\)的解。
1.3 统计的角度推导正规方程
统计里面有一个常用的模型叫做线性回归,将数据矩阵\(\textbf{X}∈\textbf{R}^{m\times n}\)(\(m\) 个样本, \(n\) 个特征维度)做为输入,预测的向量\(\bm{y}∈\textbf{R}^m\)(\(\bm{m}\)个样本,每个样本一个标签)做为输出。线性回归的输出是输入的线性函数,令\(\hat{\bm{y}}\)表示模型预测\(\bm{y}\)应该取的值。 我们定义
其中\(\bm{w}∈\textbf{R}^n\)是参数(parameter)向量。
接下来我们采用机器学习的视角。《机器学习:一种人工智能方法》中Tom.Mitchell 对机器学习的定义是:“假设用\(P\)来评估计算机程序在某任务类\(T\)上的性能,若一个程序通过利用经验\(E\)在任务\(T\)上获得了性能改善,则我们说关于\(T\)和\(P\),该任务对\(E\)进行了学习。”我们将样本划分为训练数据\(\{\bm{x}_{train}^{(i)}, y_{train}^{(i)}\}\)和测试数据\(\{\bm{x}_{test}^{(i)}, y_{test}^{(i)}\}\)采用训练数据\(\{\bm{x}_{train}^{(i)}, y_{train}^{(i)}\}\)做为经验,按照一定策略去训练模型,得到\(w\)向量的值,然后 在测试集上采用同样策略对模型的性能进行评估。
我们的模型采用的评估策略是评估测试集上的均方误差(MSE,mean squared error):\(\text{MSE}_{test} = \frac{1}{m}\sum_{i}(\hat{y}_{test}^{(i)} − y_{test}^{(i)})^2\)。我们通过观察训练集\(\{\bm{x}_{train}^{(i)}, y_{train}^{(i)}\}\)获得经验, 降低训练集上的均方误\(\text{MSE}_{test} = \frac{1}{m}\sum_{i}(\hat{y}_{test}^{(i)} − y_{test}^{(i)})^2\)以改进权重$bm{w}$(注意,机器学习和传统的最优化不同,最优化单纯优化一个目标函数,而 机器学习是降低训练集上的误差以期求降低测试集上的误差,即追求泛化性。而 这往往面临欠拟合和过拟合的问题,需要后面提到的正则化技巧来解决),最小化这个均方误差式子实际上和最 大化对数似然的期望 \(\mathbb{E}_{\bm{x}\sim \hat{p}_{data}}\text{log}_{p_{model}}(y_{train}|\bm{x}_{train}, \bm{θ})\)的得到的参数是相同的。这里\(\hat{p}_{data}\)是样本的经验分布。然而。我们要最小化的这个均方误差(或称为损失函数)是凸函数,也就是说可以通过我们前面学习的数值优化算法(如牛顿法,梯度下降法,参见《一阶和二阶优化算法》)可以找到唯一的最优解。然而,最小二乘问题有个美妙之处就是它可以找到解析解而无需数值迭代。计算其解析解的步骤如下:
我们这里简单地采用一阶导数条件判别法即可,即令\(∇_\bm{w}\text{MSE}_{train}\),即:
这样就得到了统计视角的正规方程,等同于我们前面从数值计算角度推导的正规方程。
值得注意的是,我们除了权重\(\textbf{W}\)之外,经常会加一个偏置\(b\),这样\(\bm{y} = \textbf{X}\bm{w} + b\)。
我们想继续上面推导的正规方程求解,就需要将这个\(b\)并入权重向量\(\bm{w}\)中(即下面的\(w_1\))。 对于\(\textbf{X}\in \mathbb{R}^{m\times n}\),我们给\(\textbf{X}\)扩充一列,有:
然后我们继续按照我们前面的正规方程来求即可。
我们还有最小二乘的多项式拟合形式,允许我们用多项式曲线去拟合数据 点。(关于给定向量\(\bm{w}\)的函数是非线性的,但是关于\(\bm{w}\)的函数是线性的,我们的正规方程解法仍然有效)不过这要求我们先对数据矩阵进行预处理,得到:
然后求解方法与我们之前所述相同。
1.4 矩阵方程的近似解和矩阵的 Moore-Penrose 伪拟(广义逆)
我们前面得到的基于数值计算视角的正规方程是:\(\textbf{A}^T\textbf{A}\hat{\bm{x}}=\textbf{A}^T\bm{b}\)
基于概率统计视角的正规方程式:\(\textbf{X}^T\textbf{X}\bm{w}=\textbf{X}^T\bm{y}\)
很显然,这两个式是等效的,只不过是字母命名不太一样而已。一般而言, 我们会根据上下文采取字母命名风格。如果上下文是数值计算,那么我们会采用 第一种写法,如果上下文是概率统计,我们会采取第二种写法。
我们现在继续数值计算的符号命名风格,但是采用统计和机器学习的思想对 我们的理解也是很有帮助的。对于\(\textbf{A}^T\textbf{A}\bm{x}=\textbf{A}^T\bm{b}\),我们将\(\textbf{A}^T\textbf{A}\)移项,得到:
当线性系统\(\textbf{A}\bm{x}=\bm{b}\)无解时,即因\(\textbf{A}\)不可逆而导致无法按照\(\bm{x}=\textbf{A}^{-1}\bm{b}\)求解时,我们可以将等式右边的\((\textbf{A}^T\textbf{A})^{-1}\textbf{A}^T\)做为线性系统\(\textbf{A}\bm{x}=\bm{b}\)中\(\textbf{A}\)的伪逆。
由前面的推导知道这个伪逆是由最小二乘问题的正规方程得到的。最小二乘还可以描述成最优化问题的形式进行数值迭代求解,所求解的最优解\(\bm{x}\)为
这里的\(\frac{1}{2}\)为为了方人工求导配凑的。而在机器学习中,我们为了避免模型 过拟合,我们会对目标函数进行正则化(regularization)。以最优化的视角,即添 加惩罚项以避免权重过大。我们将正则化后的最优化式子写作:
人工求导可知,这个最小二乘问题对应的正规方程是:
从而得到新的矩阵伪逆形式为:
我们将这个更“全面”的伪逆形式称为 Moore-Penrose 伪逆(Moore-Penrose pseudoinverse),常常记做\(\textbf{A}^+\)。注意和另外一个在拟牛顿法中做为对Hessian矩阵近似的Shaann伪逆做区别。
伪逆的作用常常用于当\(\textbf{A}\)不可逆(奇异)对矩阵方程\(\textbf{A}\bm{x}=\bm{b}\)的近似求解,在数值计算领域有重要的应用。
2. Ridge回归和Lasso
前面我们给出了未对目标函数施以正则化时的最优解\(\bm{x}\)为
因为我们下面要讨论机器学习的正则化问题,于是我们采用机器学习视角, 将\(\textbf{A}\)做为数据矩阵\(\textbf{X}\),\(\bm{x}\)做为优化向量 \(\bm{w}\),舍去为了方便人工求导配凑的\(\frac{1}{2}\), 并配凑一个\(\frac{1}{m}\),\(m\)为样本个数。则我们就得到均方误差(MSE, mean squared error)
\(\text{MSE} = \frac{1}{m}||\textbf{X}\bm{w} − \bm{y}||_2^2\),在机器学习领域一般称为均方误差损失函数(MSE Loss),这样最优解写作:
添加正则项,写作:
其中正则化参数\(λ>0\)。
这里,因为引入了正则项\(||\bm{w}||_2^2\),我们称使用了\(L_2\)正则化。相应的回归问题称为ridge regression(岭回归/极回归)
我们定义\(p\)范数,正则项为\(||\bm{w}||_p^p\)的正则化为\(L_p\)正则化。
有类特殊的正则化,叫 Lasso(读作“拉索”),它对应的是\(L_1\)正则化:
其中正则化参数\(λ>0\)。
\(L_1\)范数和\(L_2\)范数正则化都有助于降低过拟合的风险,但前者还会带来一个额外的好处:它比后者更易于获得”稀疏“(sparse)解,即它求得的\(w\)会有更少的非零分量。(事实上,对\(w\)施加“稀疏约束”(即希望\(w\)的非零分量尽可能少) 最自然的是使用\(L_0\)范数(\(L_0\)范数可以理解为向量所有维度取绝对值,然后取最大的维度)。但\(L_0\)范数不连续,不是凸的,其优化是 NP-hard 的,因此常使用\(L_1\)范数来近似。\(L_1\)范数的优化是凸优化问题,在多项式时间内有数值最优解)
为了理解这一点,我们来看一个直观的例子:假定任意一个样本\(\bm{x}\)只有两个属性,于是无论是\(L_1\)正则化还是\(L_2\)正则化解出的\(\bm{w}\)都只有两个分量,即\(w_1\)和\(w_2\)。我们将其做为两个坐标轴,然后在图中绘制出式\((1)\)和式\((2)\)第一项的”等值线“,即在\((w_1,w_2)\)空间中平方误差项取值相同的点的连线,在分别绘制出\(L_1\)范数和\(L_2\)范数的等值线,即在\((w_1,w_2)\)空间中\(L_1\)范数取值相同的点的连线,以及\(L_2\)范数取值相同的点的连线,如下图所示。(图片来自《西瓜书》253 页)
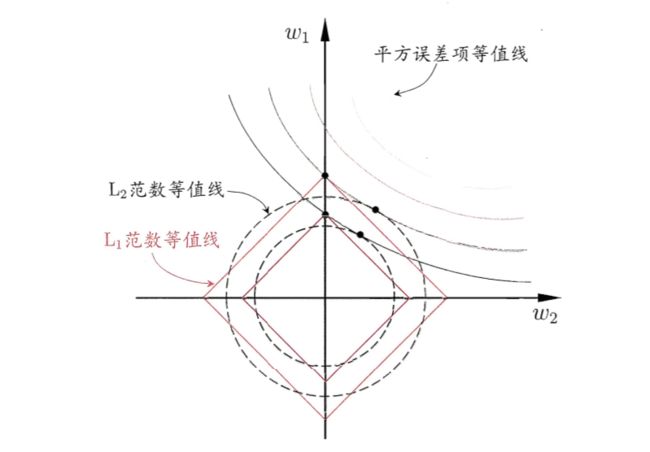
式\((1)\)和式\((2)\)的解要在平方误差项与正则化项之间折中,即出现在图中平方误差项等值线与正则化项等值线相交处。如图可以看出,采用\(L_1\)范数时平方误差项等值线与正则化项等值线的交点常出现在坐标轴上,即\(w_1\)和\(w_2\)为0,而在采用\(L_2\)范数时,两者的交点出现在某个象限中国,即\(w_1\)和\(w_2\)均非0;换言之,采用\(L_1\)范数比\(L_2\)范数更易于得到稀疏解。
L2正则化还可以有从二次规划的角度来理解,参见《统计学习3:线性支持向量机(Pytorch实现)》
以下是最小二乘解析解的算法描述:
例 1 最小二乘的解析解(待优化变量\(\bm{c}\)维度为2(结合了\(w\)和\(b\)),\(x\)为数据点的横坐标,\(y\)为数据点的纵坐标)
import numpy as np
if __name__ == '__main__':
X = np.array(
[
[-1],
[0],
[1],
[2]
]
)
y = [1, 0, 0, -2]
# 多项式拟合的话要先对X预处理,从第三列开始依次计算出第二列的次方值(还是拟合平面上的点,不过扩充了)
# 此处X一共两列,最高次数只有1次
A = np.concatenate([np.ones([X.shape[0], 1]), X], axis=1)
AT_A = A.T.dot(A)
AT_y = A.T.dot(y)
c_bar = np.linalg.solve(AT_A, AT_y)
print("最小二乘估计得到的参数:", c_bar)
# 条件数
print("条件数:", np.linalg.cond(AT_A))
这里因为涉及到解线性方程组,所以向量\(\bm{x}\)写成矩阵(列向量)形式。
解析解和条件数分别为:
最小二乘估计得到的参数: [ 0.2 -0.9]
条件数: 2.6180339887498953
例2 最小二乘的多项式拟合(待优化变量\(c\)维度仍然为1,数据点为二维平面上的点,\(x\)仍然为数据点的横坐标,不过需要先进行预处理。\(y\)仍然为数据点的纵坐标)
import numpy as np
if __name__ == '__main__':
x = np.array(
[
[-1],
[0],
[1],
[2]
]
)
y = [1, 0, 0, -2]
# 多项式拟合的话要先对X预处理,从第三列开始依次计算出第二列的次方值(还是拟合平面上的点,不过扩充了)
# 此处X一共三列,最高次数有2次,即抛物线
A = np.concatenate([np.ones([x.shape[0], 1]), x, x**2], axis=1)
AT_A = A.T.dot(A)
AT_y = A.T.dot(y)
c_bar = np.linalg.solve(AT_A, AT_y) # 该API AT_y是一维/二维的都行
print("最小二乘估计得到的参数:", c_bar)
# 条件数
print("条件数:", np.linalg.cond(AT_A))
解析解和A的条件数分别为:
最小二乘估计得到的参数: [ 0.45 -0.65 -0.25]
条件数: 20.608278259652856
最小二乘也可以写成迭代解的形式,以下是用梯度下降法求解最小二乘。
例2 最小二乘的迭代解
import numpy as np
import torch
def mse_loss(y_pred, y, w, lam, reg):
m = y.shape[0]
return 1/m*torch.square(y-y_pred).sum()
def linear_f(X, w):
return torch.matmul(X, w)
# 之前实现的梯度下降法,做了一些小修改
def gradient_descent(X, w, y, n_iter, eta, lam, reg, loss_func, f):
# 初始化计算图参数,注意:这里是创建新对象,非参数引用
w = torch.tensor(w, requires_grad=True)
X = torch.tensor(X)
y = torch.tensor(y)
for i in range(1, n_iter+1):
y_pred = f(X, w)
loss_v = loss_func(y_pred, y, w, lam, reg)
loss_v.backward()
with torch.no_grad():
w.sub_(eta*w.grad)
w.grad.zero_()
w_star = w.detach().numpy()
return w_star
# 本模型按照多分类架构设计
def linear_model(
X, y, n_iter=200, eta=0.001, loss_func=mse_loss, optimizer=gradient_descent):
# 初始化模型参数
# 我们使w和b融合,X后面添加一维
X = np.concatenate([np.ones([X.shape[0], 1]), X], axis=1)
w = np.zeros((X.shape[1],), dtype=np.float64)
# 调用梯度下降法对函数进行优化
# 这里采用单次迭代对所有样本进行估计,后面我们会介绍小批量法减少时间复杂度
w_star = optimizer(X, w, y, n_iter, eta, mse_loss, linear_f)
return w_star
if __name__ == '__main__':
X = np.array(
[
[-1],
[0],
[1],
[2]
], dtype=np.float32
)
y = np.array([1, 0, 0, -2], dtype=np.float32)
n_iter, eta = 200, 0.1, 0.1
w_star = linear_model(X, y, n_iter, eta, mse_loss, gradient_descent)
print("最小二乘估计得到的参数:", w_star)
可以看出经过足够的迭代次数(200)次,最终收敛到最优解(等于我们之前求的解析解(0.2, -0.9)):
最小二乘估计得到的参数: [ 0.2 -0.9]
最小二乘也可以用正则化项对权重进行约束,以下是用梯度下降法求解待正则项的最小二乘。
例3 最小二乘的迭代解(带正则项)
import numpy as np
import torch
def mse_loss(y_pred, y, w, lam, reg):
# 这里y是创建新的对象,这里将y变为(batch_size. 1)形式
m = y.shape[0]
if reg == 'L2':
reg_item = lam*torch.square(w).sum()
elif reg == 'L1':
reg_item = lam*torch.norm(w, p=1).sum()
else:
reg_item = 0
return 1/m*torch.square(y-y_pred).sum() + reg_item
def linear_f(X, w):
return torch.matmul(X, w)
# 之前实现的梯度下降法,做了一些小修改
def gradient_descent(X, w, y, n_iter, eta, lam, reg, loss_func, f):
# 初始化计算图参数,注意:这里是创建新对象,非参数引用
w = torch.tensor(w, requires_grad=True)
X = torch.tensor(X)
y = torch.tensor(y)
for i in range(1, n_iter+1):
y_pred = f(X, w)
loss_v = loss_func(y_pred, y, w, lam, reg)
loss_v.backward()
with torch.no_grad():
w.sub_(eta*w.grad)
w.grad.zero_()
w_star = w.detach().numpy()
return w_star
# 本模型按照多分类架构设计
def linear_model(
X, y, n_iter=200, eta=0.001, lam=0.01, reg="L2", loss_func=mse_loss, optimizer=gradient_descent):
# 初始化模型参数
# 我们使w和b融合,X后面添加一维
X = np.concatenate([np.ones([X.shape[0], 1]), X], axis=1)
w = np.zeros((X.shape[1],), dtype=np.float64)
# 调用梯度下降法对函数进行优化
# 这里采用单次迭代对所有样本进行估计,后面我们会介绍小批量法减少时间复杂度
w_star = optimizer(X, w, y, n_iter, eta, lam, reg, mse_loss, linear_f)
return w_star
if __name__ == '__main__':
X = np.array(
[
[-1],
[0],
[1],
[2]
], dtype=np.float32
)
y = np.array([1, 0, 0, -2], dtype=np.float32)
n_iter, eta, lam = 200, 0.1, 0.1
reg = "L1"
w_star = linear_model(X, y, n_iter, eta, lam, reg, mse_loss, gradient_descent)
print("最小二乘估计得到的参数:", w_star)
不采用正则化,即令正则化系数\(\lambda\)为0,迭代次数和学习率不变,可以看到最终估计的结果和上一个例子一样:
最小二乘估计得到的参数: [ 0.2 -0.9]
采用\(L_2\)范数正则化,正则化系数为0.1,迭代次数和学习率不变,可以看到参数向量整体的范数(可以理解成大小)变小了,可见正则化对参数的范数进行了限制:
最小二乘估计得到的参数: [ 0.14900662 -0.82781457]
注意这里采用的梯度下降法不是随机算法,具有可复现性,算法运行多次也还是同样的结果。
引用
- [1] Timothy sauer. 数值分析(第2版)[M].机械工业出版社, 2018.
- [2] Golub, Van Loan. 矩阵计算[M]. 人民邮电出版社, 2020.
- [3] 周志华. 机器学习[M]. 清华大学出版社, 2016.
- [4] Ian Goodfellow,Yoshua Bengio等.深度学习[M].人民邮电出版社, 2017.