
论文地址:https://arxiv.org/abs/1904.11547
官方代码:https://github.com/Feiyang/MetaEmbedding
一 为什么读这篇
最近在做提高时效性的工作,范围放大点就是解决所谓item冷启动问题,恰逢读完DIN,看到参考DIN的论文有这么一篇,题目就很扣题了,正是瞌睡遇上枕头,第一时间读下,参考一下思路,看看对于解手头问题有没有帮助。
二 截止阅读时这篇论文的引用次数
2019.9.29 1次。毕竟今年4月才出,另外解决的问题域也确实更细分点,所以引用很少。
三 相关背景介绍
19年4月挂到arXiv上,中了19年的SIGIR。中科院出品,也有清华的唐平中老师加持,一作“肥羊”就有意思了,玩kaggle时各种屠榜,现在是中科院的博士生,也在蚂蚁实习,估计阿里星没跑了。
四 关键词
CTR
Embedding
Cold Start
meta-learning
learning to learn
五 论文的主要贡献
1 引入元学习来解决冷启动问题
2 给ID Embedding更好的初始化
六 详细解读
0 摘要
为了解决冷启动问题,本文提出Meta-Embedding,这是一种基于元学习的方法,可以习得为新广告ID生成理想的初始化Embedding。该方法通过基于梯度的元学习,利用之前习得过的广告来为新广告ID训练Embedding生成器,即本文方法是学习如何更好的学习Embedding。当遇到一个新广告时,训练生成器通过输入它的内容和属性来初始化Embedding。接着,生成的Embedding可以加速模型在warm up阶段(当有很少的标签样本可用时)的拟合。
1 介绍
在工业界,相比没有ID输入的方法,一个被学得很好的广告ID Embedding能极大提升预测准确率。尽管有许多成功的方法,但它们都需要相当多的数据来学习Embedding向量。而且对于一些只有很少训练样本的“小”广告来说,它们训练得到的Embedding很难和“大”广告一样出色,这些问题就是业界所谓的冷启动问题。
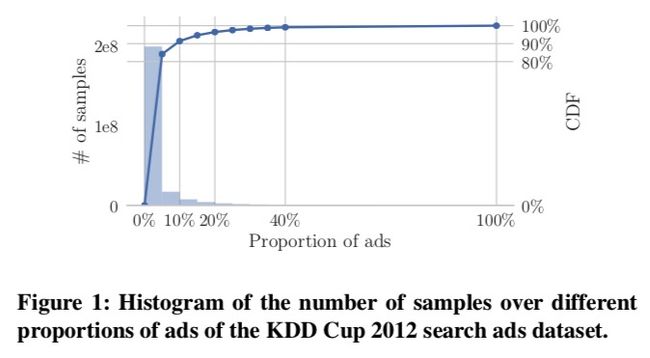
如图1所示,KDD2012的数据,5%的广告占据了超过80%的样本。
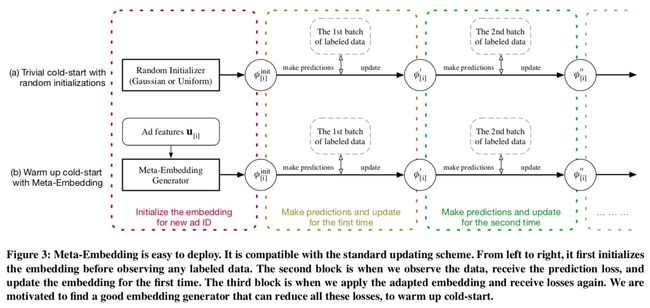
本文方法的主要理念包括,利用广告特征的参数函数作为ID Embedding生成器,通过两阶段模仿在旧ID上训练生成器,使用基于梯度的元学习来提升冷启动和warm-up阶段的效果。
本文的两个目标:
- 在冷启动阶段更好
- 在warm-up阶段更快
为了达到这两个目标,针对手中的“大”广告设计了冷启动和warm-up两个阶段的模拟。在冷启动阶段,需要为没有标签的ID赋Embedding初值,在有少量标签样本的warm-up阶段,通过模拟模型拟合过程来更新Embedding,用这种方式来学习如何学习。
本文方法的本质就是将CTR预估问题转化为元学习问题,将学习每个广告视为任务。提出的基于梯度的训练算法有着“与模型无关的元学习”(Model-Agnostic Meta-Learning MAML)的优势。MAML在许多领域快速适应上是成功的,但它对每个任务都训练一个模型,所以当有上百万个任务(广告)时不能直接用于CTR预估。为此,本文将MAML泛化为一个基于内容的Embedding生成器。同时构建同统一的优化目标来平衡冷启动和warm-up的效果。本文方法易于实现,可以应用在离线和在线环节。也可以应用在其他ID特征的冷启动,如用户ID,广告主ID。
本文方法也可以扩展应用在E&E和active learning这两个领域。
本文贡献主要如下:
1 提出Meta-Embedding来学习如何学习新广告的Embedding
2 提出一个简单有效的算法来训练Meta-Embedding生成器,它通过利用反向传播时的二阶导数来使用基于梯度的元学习
3 本文方法可以很容易的在在线冷启动实现。一旦Embedding生成器训练好,它就可以代替简单的随机初始化来进行新ID的Embedding
4 在3个大规模真实数据集上验证了本文方法的有效性。6个SOTA的CTR模型都在冷启动上得到了极大的提升。
2 背景和公式
输入特征x可以划分为三部分,包括
1 表示广告ID
2 表示特定广告的特征和属性,可能有多个字段
3 表示不是必须与广告关联的特征,如用户特征,上下文信息
密集矩阵通常被称为Embedding矩阵,或者查找表。给定Embedding矩阵和ID i的Embedding ,我们就能得到作为判别模型的参数化函数:
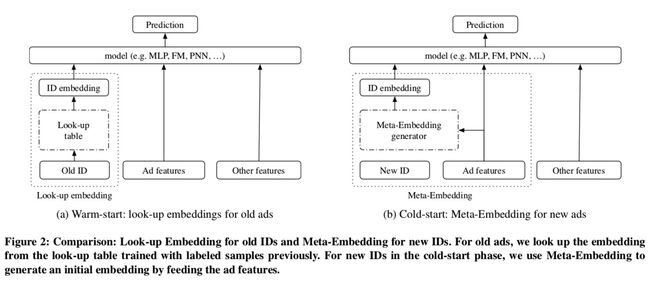
图2a展示了该模型的基本结构
和用SGD同时更新。
如果一个ID 从未在系统中出现过会发生什么?因为从没有见过该广告的标签数据,所以Embedding矩阵对应的行仍然是初始状态,例如是零值附近的随机数。为了解决这个问题,本文设计的Embedding生成器结构如图2b所示,它的初始化用公式表示如下:
问题来了。
1 如何训练这种Embedding生成器
2 更新参数的目标函数是什么
3 学习如何学习新广告的ID Embedding
3.1 将CTR预估转化为元学习
以元学习的视角来看,本文会引入新的符号,对于给定的ID ,将预测模型写为:
注意实际上和是一样的,参数都是和。用这种方式,可以看到通过将学习问题视为每个广告ID的一项任务,就可以将CTR预估视为元学习的一个实例。对于ID ,相应的任务是学习特定任务的模型。它们共享来自基模型的参数,同时有自己任务相关的参数
考虑可以访问ID 的先前任务,这个集合是已知ID的集合,及每个任务的训练样本。这个数据上原始的(预)训练可以提供一组已经学习好的共享参数,以及对于所有先前的ID 特定任务的参数。然后对于新的ID ,无法得知,因此可以考虑从那些老的ID中学习如何学习。这就是以元学习的视角考虑CTR预估的冷启动问题。
3.2 Meta-Embedding
因为共享参数通常通过相当多的历史数据去训练,我们对它的效果是有信心的,所以当训练Meta-Embedding时,可以在整个过程中冻结,不用去更新它。本文只考虑如何学习新ID的Embedding。
对于一个新ID ,另
作为生成的初始Embedding。此时通过生成的Embedding,模型可以表示为
所以这的是一个模型(元学习器),输入为特征,输出为预测,并且不涉及Embedding矩阵。可训练参数是来自的元参数。
考虑每个旧ID 的任务,会有这么多训练样本,其中是给定ID的样本个数。
开始的时候,随机选择,两个不相交的minibatch标签数据,每个都有K个样本。假设K相当小,例如
3.2.1 冷启动阶段
首先在第一个minibatch 上使用做预测,如下式所示:
其中下标表示来自batch 的第j个样本,接着计算这些样本上的平均损失:
到这里也就完成了冷启动阶段:通过生成器生成了的Embedding,并在第一个batch上评估它得到损失
3.2.2 Warm-up阶段
接着用第2个batch 模拟Warm-up阶段的学习过程。
通过计算初始Embedding损失的梯度,以及一步梯度下降,可以得到更新的Embedding:
接着可以在第2个batch上用最小数量的数据训练得到的新Embedding评估。与之前类似,做预测如下:
同时计算平均损失:
3.2.3 统一优化目标
从两方面来评估初始Embedding的好坏:
1 对于新广告的CTR预估错误应尽可能小
2 在收集一小部分标签数据后,一点梯度更新就应该有很快的学习
惊喜的是,本文发现,两个损失可以分别完美地适配这两个方面。在第1个batch,因为用生成的初始Embedding做预测,是一个评估冷启动阶段生成器的天然指标。在第2个batch,因为Embedding已经更新过一次,所以在warm-up阶段用评估样本效率就相当直接了。
为了统一这两个损失,这里提出Meta-Embedding的最终损失函数,即和的加权和:
其中系数用于平衡两个阶段。
因为是初始Embedding的函数,可以通过链式法则来做元参数的梯度反向传播:
其中:
尽管有二阶导Hessian-vector存在,也可以很有效的在TensorFlow中实现。
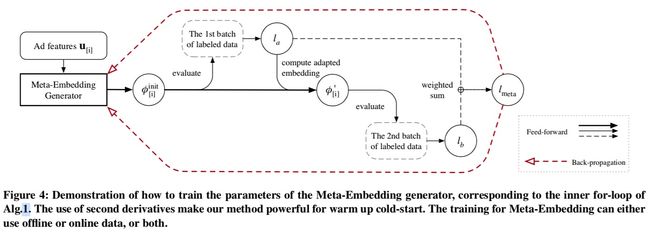
训练算法如下图所示,一个ID的训练过程如图4所示。

3.3 架构和超参
3.3.1 的架构
如图5所示
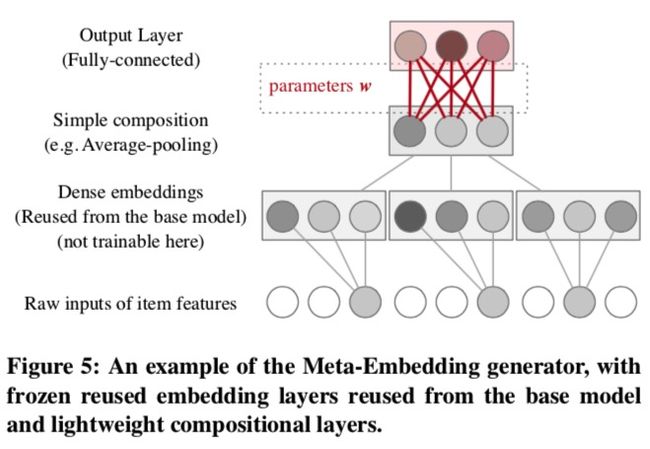
不同字段的Embedding可以用不同的pooling方式。最后用于输出的密集层是生成器唯一需要训练的部分。
通过在最后一层使用三个trick,可以获得数值稳定的输出:
1 使用tanh激活
2 不要增加偏置项
3 使用L2正则惩罚权重
3.3.2 超参
因为实践上warm-up阶段比冷启动阶段需要更多的步数,因此推荐将设置为一个小值,使得元学习器更注意warm-up阶段来加速收敛。本文所有实验将该值设置为0.1。
4 实验
4.1 数据集
MovieLens-1M
腾讯2018社交广告比赛
KDD Cup 2012
4.2 基本模型
FM
Wide & Deep
PNN
DeepFM
每个输入字段的Embedding维度固定为256。对于NLP特征,首先将每个token(word)转化为256维的word-embedding,然后使用AveragePooling来得到字段(句子)级别的表示。
4.3 实验设置
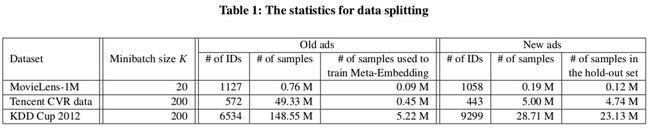
4.3.1 数据集划分
4.3.2 实验pipeline
开始时先使用老的广告预训练基础模型,用于训练Meta-Embedding的样本个数可见表1。完成训练后,在新广告上进行测试。对于每个新广告,一个接一个的训练3个mini-batch,就好像它们是warm-up的数据,分别命名为batch-a,batch-b,batch-c,每个batch有K个实例,新广告的其他实例用于测试。具体实验步骤如下:
- 用老广告数据预训练基模型(1 epoch)
- 用训练数据训练Meta-Embedding(2 epoch)
- 用随机初始化或Meta-Embedding生成新广告的初始Embedding
- 在测试集上评估冷启动效果
- 用batch-a更新新广告的ID Embedding,同时计算在测试集上的评估指标
- 用batch-b更新新广告的ID Embedding,同时计算在测试集上的评估指标
- 用batch-c更新新广告的ID Embedding,同时计算在测试集上的评估指标
4.3.3 评估指标
用LogLoss和AUC,同时用百分比公式来展示相对提升:
4.4 实验结果
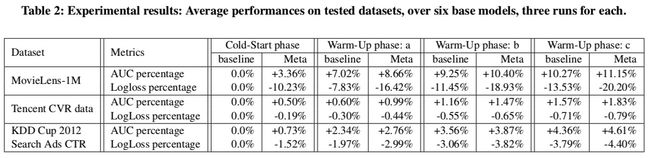
一个有趣的发现是相对提升在越小的数据集上越显著。
5 相关工作
5.1 解决冷启动问题的方法
有两种类型的方法,一种是通过设计决策策略,例如使用contextual-bandits,或通过为冷item或user设计interview来收集信息。本文属于第二种类型,是将冷启动视为在线监督学习,它通常使用side information用于冷启动阶段,例如使用user属性,item属性,关系数据等等。但是这些方法即没有考虑使用ID,也没有在warm-up阶段对它们做优化。本文不仅使用了全部可用特征,此外目的也是同时提升冷启动阶段和warm-up阶段的效果。
Dropout-Net通过在深度协同过滤模型上应用dropout来处理缺失输入,可以被视为一种用于预训练基础模型的成功训练方法。
5.2 元学习
本文研究的是如何warm-up冷启动广告,在元学习领域相关的问题就是few-shot learning和fast adaptation。本文受到MAML的启发,用基于梯度的元学习方法来学习共享模型参数。
七 小结
本文最大的亮点就是引入元学习来解决CTR预估中的冷启动问题,meta-learning,few shot learning,这些概念已经在CV里有不少应用,现在也迁移到推荐广告领域了。看了第三节感觉写的是真繁琐,说的很玄乎,看起来也很累,得一个字一个字扣,但看完后回味下,好像也没说什么啊,就是交替训练更新参数?另外本文第五节相关工作的梳理很值得一看。
素质四连
要解决什么问题
item冷启动问题
用了什么方法解决
引入元学习,用Meta-Embedding替代随机初始化Embedding
效果如何
离线效果都有提升,这个某种程度上应该也是,专门优化过的Embedding肯定优于随机初始化
还存在什么问题
实验结果那一小节,作者也提到,在腾讯的数据集上,Wide&Deep的对比实验并没有提升,反而有轻微下降,推测原因可能是Wide部分直接使用了原始输入。另外只给出相对提升,没给出原始值。还有对于线上效果如何,没有提到。
算法背后的模式和原理
引入元学习解决CTR问题,借花献佛
八 补充
Model-Agnostic Meta-Learning (MAML)模型介绍及算法详解 https://zhuanlan.zhihu.com/p/57864886
什么是meta-learning? https://www.zhihu.com/question/264595128/answer/743067364