一、自动化测试所属分类(站在代码可见度角度分类)
1. 黑盒测试(功能测试)
2. 灰盒测试(接口测试)
3. 白盒测试(单元测试)
提示:Web自动化测试属于黑盒测试(功能测试)
优点
1. 较少的时间内运行更多的测试用例;
2. 自动化脚本可重复运行;
3. 减少人为的错误;
4. 测试数据存储,测试数据统一放在文本中,自动化程序自动去读取
5. 解决回归测试,兼容性测试,压力测试,提高效率,保证产品质量
缺点
1. 不能取代手工测试;
2. 手工测试比自动化测试发现的缺陷更多;
3. 测试人员技能要求;
误区:
1). 自动化测试完全替代手工测试
2). 自动化测试一定比手工测试厉害
3). 自动化可以发掘更多的BUG
分类:web(UI)自动化测试,app移动自动化测试,接口自动化测试,单元测试自动化测试
需求变动不频繁,项目周期长,项目需要回归测试——适合做web自动化测试
web自动化测试工具:QTP(web,桌面自动化),Selenium(主要做功能测试),Jmeter(基于Java,web,接口,性能测试),Loadrunner(web,性能),Robot framework(基于Python,关键字驱动)
web自动化测试:selenium,robot framework
App端自动化测试:Appium,Monkeyrunner,UIautomation
PC客户端(win32)自动化测试:QTP
接口自动化测试:Jmeter,Postman,httpUnit,RESTClient
云测平台:Testin,Testbird
性能测试:Jmeter,LoadRunner
二、web自动化测试工具 ——Selenium:
特点:开源软件,跨平台(linux,mac,windows),核心功能(能多个浏览器上进行自动化测试),多语言(java,python,ruby,JavaScript,c#),成熟稳定,功能强大(能实现商业工具大部分功能,因为开源,可以实现定制化功能)
Selenium家族要了解:SeleniumIDE + Selenium2.0(Selenium1.0+Webdriver)
三、Selenium IDE?【重点】
为什么学习IDE:
Selenium IDE是一个Firefox的插件,用于记录和播放用户浏览器的交互(录制web操作脚本)
1. 使用Selenium IDE录制脚本,体验自动化脚本魅力
2. 使用Selenium IDE录制的脚本转换为代码语言
(后期如果自己设计脚本,如果不知道什么方式定位元素,可使用此方法参考)
Selenium IDE 安装: 火狐浏览器 V35.0 选择 selenium IDE 2.9.1.1
1. 官网安装
Version: 2.9.1.1
通过官网安装插件:https://addons.mozilla.org/en-GB/firefox/addon/selenium-ide/versions/
2. 附加组件管理器
1). 火狐浏览器 V24-V35
2). 附加组件管理器-->搜索selenium IDE
提示:
1. IDE前面有个空格
2. 附加组件管理器启动方式- 1) 工具菜单->附加组件 2) Ctrl+Shift+A
3. 离线安装
下载:https://github.com/SeleniumHQ/selenium-ide/releases
安装:下载好selenium_ide-2.9.1-fx.xpi直接拖入浏览器安装
界面介绍:
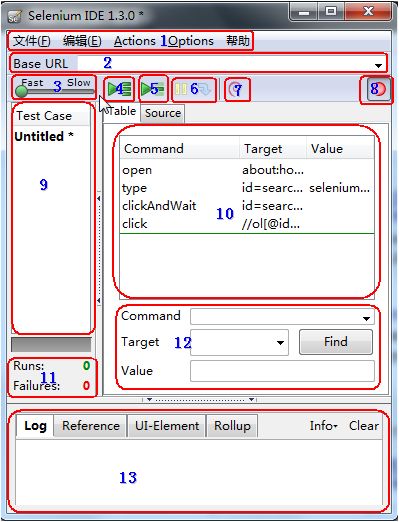
1. 文件:创建、打开和保存测试案例和测试案例集。编辑:复制、粘贴、删除、撤销和选择测试案例中的所有命令。Options : 用于设置seleniunm IDE。
2. 用来填写被测网站的地址。
3. 速度控制:控制案例的运行速度。
4. 运行所有:运行一个测试案例集中的所有案例。
5. 运行:运行当前选定的测试案例。
6. 暂停/恢复:暂停和恢复测试案例执行。
7. 单步:可以运行一个案例中的一行命令。
8. 录制:点击之后,开始记录你对浏览器的操作。
9. 案例集列表。
10. 测试脚本;table标签:用表格形式展现命令及参数。source标签:用原始方式展现,默认是HTML语言格式,也可以用其他语言展示。
11. 查看脚本运行通过/失败的个数。
12. 当选中前命令对应参数。
13. 日志/参考/UI元素/Rollup
示例:
在base url输入https://www.baidu.com,点击录制按钮,开始录制
进入www.baidu.com,在搜索框中输入“淘宝官网”,点击百度一下,出来结果后,点击淘宝官网,进入淘宝官网,打开IDE结束录制,至此一个案例录制完毕
注意:
1. 录制:录制时红色录制按钮一定要打开->按下状态
2. 回放:由于网络延迟原因-建议选择最低
3. 浏览器:回放时浏览器要保持打开状态(否则点击回放,脚本无响应)
保存脚本,文件——save test case成html文件,导出成python语言,文件菜单->Export Test Cast As..->python2/unittest/WebDriver
重点解释:
1. id=kw:为百度搜索文本框id属性和值
2. id=su: 为百度一下按钮id属性和值
如何快速查找一个元素标签的属性和值?—— Firebug
定位调试插件 Firebug:FireBug插件是火狐浏览器一款插件,能够调试所有网站语言,同时也可以快速定位HTML页面中的元素;作用:定位元素(获取元素定位和查看元素属性); 在线安装: 1). 火狐浏览器 V35 2). 附加组件管理器-->搜索FireBug
Selenium IDE脚本编辑与操作 【了解】录制脚本时候是录制鼠标和键盘的所有在浏览器操作,那么脚本会出现多余的步骤,有时候我们需要手动填写脚本或修改脚本,所有我们有必要对Selenium IDE脚本编辑与操作有所了解;目的:手动修改或编写脚本(采用录制方式很容易记录出多余的操作)
编辑一行命令:在Table标签下选中某一行命令,命令由command、Target、value三部分组成。可以对这三部分内容那进行编辑。
插入命令:在某一条命令上右击,选择“insert new command”命令,就可以插入一个空白,然后对空白行进程编辑
插入注释:鼠标右击选择“insert new comment”命令插入注解空白行,本行内容不被执行,可以帮助我们更好的理解脚本,插入的内容以紫色字体显示。
移动命令:有时我们需要移动某行命令的顺序,我们只需要左击鼠标拖动到相应的位置即可。
删除命令:选择单个或多个命令,然后点击鼠标右键选择“Delete”
命令执行:选定要执行的命令点击单个执行按钮即可,注意:有一些命令必须依赖于前面命令的运行结果才能成功执行,否则会导致执行失败。
Selenium IDE常用command命令【了解】
open(url)命令
作用:打开指定的URL,URL可以为相对或是绝对URL;
Target:要打开的URL;value值为空
1). 当Target为空,将打开Base URL中填写的页面;
2). 当Target不为空且值为相对路径,将打开Base URL + Target页面。如,假设Base URL为http://www.zhi97.com,而Target为/about.aspx,则执行open命令时,将打开http://www.zhi97.com/about.aspx
3). 当Target以http://开头时,将忽略Base URL,直接打开Target的网址;对于url,http开头就是绝对路径
pause(waitTime)
作用:暂停脚本运行
waitTime:等待时间,单位为ms;//Target=1000
goBack()
作用:模拟单击浏览器的后退按钮;
提示:由于没有参数,所以Target和Value可不填;
refresh()
作用:刷新当前页;
提示:由于没有参数,所以Target和Value可不填;
click(locator)
作用:单击一个链接、按钮、复选框或单选按钮;
提示:如果该单击事件导致新的页面加载,命令将会加上后缀“AndWait”,即“clickAnd Wait”, 或“waitForPageToLoad”命令;
type(locator,value)
作用:向指定输入域中输入指定值;也可为下拉框、复选框和单选框按钮赋值.
Target:元素的定位表达式;
Value:要输入的值;
close()
作用:模拟用户单击窗口上的关闭按钮;
提示:由于没有参数,所以Target和Value可不填;
四. WebDriver了解与安装
- Webdriver (Selenium2)是一种用于Web应用程序的自动测试工具;
- 它提供了一套友好的API;说明:API:应用编程接口说明(WebDriver类库内封装非常多的方法,要使用这些方法,就需要友好的调用命名规则,API就是对库里的所有方法,参数,返回值的一些说明,有了这个,我们根据我们调用的方法名称,就知道这个方法有什么用,库有库的API,接口有接口的API,要使用一个库,就去看他的API,就可以用这个库来做项目开发)
- Webdriver完全就是一套类库,不依赖于任何测试框架,除了必要的浏览器驱动;必须要浏览器驱动,才能调用Webdriver
WebDriverAPI 支持的浏览器
1. Firefox (FirefoxDriver)【推荐-本阶段学习使用】
2. IE(InternetExplorerDriver)
3. Opera(OperaDriver)
4. Chrome (ChromeDriver)
5. safari(SafariDriver)
6. HtmlUnit (HtmlUnit Driver)
提示:
Firefox、Chrome:对元素定位和操作有良好的支持,同时对JavaScript支持也非常好。
IE:只能在windows平台运行,所有浏览器中运行速度最慢
HtmlUnit:无GUI(界面)运行,运行速度最快;
推荐原因:1. Selenium IDE, 2. FireBug,3. 对WebDriver API支持良好
WebDriverAPI 支持的开发语言:Java,Python,PHP,JavaScript,Perl,Ruby,C#,可以用这些语言来调用webdriverAPI,用这个库里面的方法
官网文档:https://docs.seleniumhq.org/docs/03_webdriver.jsp
为什么要学习WebDriver? 自动化测试概念,WebDriver-定位元素,WebDriver-操作元素
环境搭建:要使用一种编程语言,也要搭建环境,把语言中别人写好的包安装好,还有就是要有编译器(对于java来说)或者解释器(对于python来说)来把我们写的代码编译或解释成计算机能懂的指令
基于Python环境搭建:Windows系统(在这里我们以Windows7为案例),Python 3.5(以上版本),安装selenium包,浏览器,安装PyCharm
浏览器驱动:各个驱动下载地址:http://www.seleniumhq.org/download/
火狐浏览器【推荐】
FireFox 48以上版本:Selenium 3.X +FireFox驱动——geckodriver
Firefox 48 以下版本:Selenium2.X 内置驱动
IE浏览器(了解)
IE 9以上版本:Selenium3.X +IE驱动
IE 9以下版本:Selenium 2.X +IE驱动
谷歌浏览器:selenium2.x/3.x +Chrome驱动
注意:
1. 浏览器的版本和驱动版本要一致!(如果是32bit浏览器而Driver是64bit则会导致脚本运行失败!)
2. 浏览器驱动下载好后需要添加Path环境变量中(只要一个文件,例如.exe文件,它存在的目录路径是添加到环境变量中的,那么在系统的其他任何地方都可以执行这个这个文件,在添加环境变量的时候,一般是选择添加系统变量,而不是针对某个用户变量的path,添加时以;相隔,把路径粘贴进去即可),或者直接放到Python安装目录,因为Python以添加到Path中
3. 推荐使用火狐浏览器(24、35)版
selenium 安装、卸载、查看命令
在安装selenium时,前提是Python3.5以上版本安装完毕且能正常运行
安装:pip install selenium==2.48.0
1). pip:通用的 Python 包管理工具。提供了对 Python 包的查找、下载、安装、卸载的功能
2). install: 安装命令
3). selenium==2.48.0: 指定安装selenium2.48.0版本(如果不指定版本默认为最新版本)
卸载:pip uninstall selenium
查看:pip show selenium
五、Webdriver的元素定位
为什么要学习元素定位方式?1. 让程序操作指定元素,就必须先找到此元素;2. 程序不像人类用眼睛直接定位到元素;3. WebDriver提供了八种定位元素方式
定位方式分类-汇总:
1). id、name、class_name(指的是class这个属性对应的值):为元素属性定位
2). tag_name(就是标签的名称):为元素标签名称
3). link_text、partial_link_text:为超链接定位(a标签),只对链接有效,定位的是链接文本
4). Xpath:为元素路径定位
5). Css:为CSS选择器定位
元素定位【重点】
id,一般唯一,但重复也不报错
说明:通过元素的id属性来定位,HTML规定id属性在整个HTML文档中必须是唯一的,id定位就是通过元素的id属性来定位元素
前提:元素必须有id属性
方法:driver.find_element_by_id(id值)
实现案例-1需求: 1). 打开注册A.html页面,使用id定位,自动填写(账号A:admin、密码A:123456) 2). 填写完毕后,3秒钟关闭浏览器窗口
案例实施步骤思路分析
1.导包 ——> from selenium import webdriver,from time import sleep
2.指定浏览器(实例化浏览器对象) ——> driver=webdriver.Firefox()
3.打开项目 ——> 打开注册A.html :driver.get(url)
4.找到元素(定位元素) ——> driver.find_element_by_id("")
5.操作元素 ——> 使用send_keys()方法发送数据: .send_keys("admin")
6.暂停 ——> sleep(3) 暂停3秒
7.关闭浏览器——> quit()
案例1代码实现:
from selenium import webdriver
from time import sleep# 实例化浏览器
driver=webdriver.Firefox()
# 第二种写法:url=r'E:\...\注册A.html'
# r的作用:被r修饰的字符串,字符串中的转义符不做转义使用
# 第三种写法:"file:///E:/.../注册A.html"
# /:斜杠,除法,5/3;\:反斜杠,目录结构
url='E:\\...\\注册A.html' # url中\\转义
driver.get(url)
user=driver.find_element_by_id("userA")
user.send_keys("admin")
pwd=driver.find_element_by_id("passwordA") #这里的element没有s
pwd.send_keys("123456")
# 打完sleep后,ctrl+alt+空格,回车,快速导from time import sleep包
sleep(3)
driver.quit()
name,可重复
说明:通过元素的name属性来定位,name的属性值在当前文档中可以不是唯一的
前提:元素必须有name属性
方法:driver.find_element_by_name(name值)
class_name,同一元素可属于不同的class
说明:通过元素的class属性来定位
前提:元素必须有class属性
方法:find_element_by_class_name()
tag_name
说明:通过元素的标签名称,如:... ,HTML本质就是由不同的tag(标签)组成,而每个tag都是指同一类,所以tag定位效率低, 一般不建议使用;tag_name定位就是通过标签名来定位;
前提:元素标签名在当前页面必须为唯一元素,或定位符合条件第一个元素;
返回:符合条件的第一个元素
方法: find_element_by_tag_name(标签名称) ——> 返回:符合条件的第一个标签
link_text
说明:只定位超链接标签,它专门用来定位超链接文本(标签)
注意:必须为全部匹配本,需要传入a标签全部文本
方法:find_element_by_link_text(全部问本值)
找到元素后,单击以下click()
find_element_by_link_text(全部问本值).click()
partial_link_text
说明:它为link_text定位的补充说明,partial_like_text为模糊匹配;link_text全部匹配
注意:为模糊匹配,需要传入a标签局部文本-能表达唯一性
方法:find_element_by_partial_link_text(局部文本)
find_element[s]_by_XXX()
作用:查找定位所有符合条件的元素;返回的定位元素格式为数组(列表)格式;
说明:列表数据格式的读取需要指定下标(下标从0开始)
说明:使用tag_name获取第二个元素(密码框),即便页面只有唯一一个input标签元素,也一定要指定下标[0]
代码:driver.find_elements_by_tag_name("input")[1].send_keys("123456")
-----------------------------------------------------------------------------------------------------------------------------------
当在实际项目中标签没有id、name、class属性,或者id、name、class属性值为动态获取,随着刷新或加载而变化,要定位:Xpath,css定位
Xpath
说明:XPath即为XML Path 的简称,它是一种用来确定XML文档中某部分位置的语言。HTML可以看做是XML的一种实现,所以Selenium用户可以使用这种强大的语言在Web应用中定位元素。
XML:一种标记语言,用于数据的存储和传递。 后缀.xml结尾
提示:Xpath为强大的语言,那是因为它有非常灵活定位策略;
- Xpath定位策略(方式)
路径-定位:绝对路径,相对路径
利用元素属性-定位
层级与属性结合-定位
属性与逻辑结合-定位
Xpath定位方法:driver.find_element_by_xpath()
路径(绝对路径、相对路径):
绝对路径:从最外层元素到指定元素之间所有经过元素层级路径 ;以单斜杠/开头,中间不能跳跃元素,如:/html/body/div/p[2]
提示:绝对路径以/开始,使用Firebug可以快速生成,元素XPath绝对路径:使用在firebug中的html选项下,某一元素右键复制Xpath路径可得到绝对路径
相对路径:从第一个符合条件元素开始(一般配合属性来区分);以双斜杠开头;后边必须跟标签名称或*(*表示所有标签),-Xpath路径内使用属性时,必须要使用@修饰,如://input[@id='userA']
提示:相对路径以//开始,使用Friebug扩展插件FirePaht可快速生成,使用在firebug中的html选项下,某一元素右键复制最简Xpath路径可得到相对路径,但不一定找到,所以最好自己写
提示:为了方便练习Xpath,可以在FireBug内安装扩展插件-FireFinder插件;火狐浏览器-->组件管理器-->搜索FireFinder
利用元素属性
说明:快速定位元素,利用元素唯一属性;
示例:"//*[@id='userA']" #Python中" "中再有字符串,要用单引号''层级与属性结合
说明:要找的元素没有属性,但是它的父级有;
示例://*[@id='p1']/input属性与逻辑结合
说明:解决元素之间个相同属性重名问题
示例://*[@id='telA' and @class='telA']Xpath-延伸
//*[text()="xxx"] 文本内容是xxx的元素,一定是全部匹配
//*[starts-with(@attribute,'xxx')] 属性以xxx开头的元素
//*[contains(@attribute,'xxx')] 属性中含有xxx的元素
CSS
说明:CSS(Cascading Style Sheets)是一种语言,它用来描述HTML和XML的元素显示样式; (css语言书写两个格式:写在HTML语言中