文章地址
https://blog.csdn.net/yxs9527/article/details/83749549
概述
>>> 每个点都有一个核函数,如选定高斯核函数,核函数下面积为1
>>> 离的近的点概率高
>>> 每个点的核密度累加
>>> 累加出的曲线下的面积为点的数量,除以点的数量就实现了,曲线下面积的归一化
已知n个点,使用概率密度估计求整体的概率密度分布。
用盒子模型求解(直方图求解)
X=[2, 22, 42, 62, 82, 102, 122, 142,162, 182, 202 , 222],最简单的我们可以直接使用直方图来进行概率估计。每一个点用一个盒子来替代,那么此时我们有3个参数需要人工确定:
盒子长我们分别设定0.5
盒子右边界设定为[0-0.5]和[0.25-0.75]两种情况分别讨论如下两个图所示。
盒子高度为1/n=1/12 ,n为数据的总数
那么我们,利用盒子累加的方式,画图如下所示,则方块的高地为密度的一直估计:

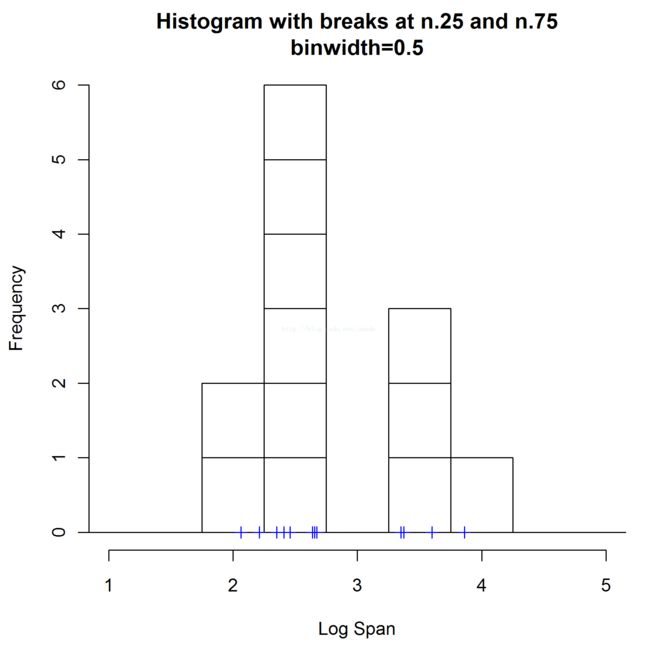
可以看出,当你的右边界设定不同的时候,产生的概率密度估计差异非常大,单峰和双峰的区别。
暴露了一下的一些不足:
1.盒子长度对结果影响太大
2.盒子的边界对结果影响太大
3.不平滑
以盒子为核的核密度估计
盒子模型不是围绕着点来展开,而是围绕区间范围的展开,它是区间范围频数累加,这就是直方图了,上面三点总结的就是直方图的弱点。
如果不围绕着区间范围而是围绕着点来展开,也就是说把核函数设置为盒子,我们称之为盒子核,
而且盒子的中心点和就是数据点,盒子宽度仍然是固定的,高度是1/12
那就是下面这样的:

这个我们则可以称为以盒子为核的核密度估计。它解决了区间段划分对核密度估计的影响。但仍然存在以下问题:
1. 不平滑
2. 盒子长度不好确定
基于此,我们可以选择出更加平滑的核进行密度估计,比如高斯核,则可以有效解决问题1,即不平滑的问题。
高斯核概率密度估计
我们使用高斯核来进行密度估计,则唯一需要确定的参数就是带宽,即盒子长度,同样也是正态分布的标准差。我们设为0.1,则高斯核密度估计可以如下进行:
对每一个点都产生一个高斯分布,u=点坐标,σ=0.1,则可以得到如下的核密度估计,总体的密度估计则为每一个点的密度估计总和,注意的是因为所有的密度概率函数积分等1,所有我们得到的子正态分布的概率即覆盖的面积为1/12才行。

因为h=0.1导致不平滑,所以我们用h=0.5来替代,但是有导致另外一问题,即远离了真实的最优值,我们需要一些方法去确认最优h,则可以使用最小化MASE。

理论上存在一个最小化mean square error的一个h。h的选取应该取决于N,当N越大的时候,我们可以用一个比较小的h,因为较大的N保证了即使比较小的h也足以保证区间内有足够多的点用于计算概率密度。因而,我们通常要求当N→∞,h→0。比如,在这里可以推导出,最优的h应该是N的-1/5次方乘以一个常数,也就是。对于正态分布而言,可以计算出c=1.05×标准差。
关于h的确定可以查看这篇博客
http://blog.csdn.net/chixuezhihun/article/details/73928749

自适应带宽的核密度估计可以参考维基百科:https://en.wikipedia.org/wiki/Variable_kernel_density_estimation
推荐帖子:http://blog.sina.com.cn/s/blog_62b37bfe0101homb.html
参考资料
https://en.wikipedia.org/wiki/Kernel_density_estimation
https://www.zhihu.com/question/20212426/answer/74989607
https://en.wikipedia.org/wiki/Variable_kernel_density_estimation
http://www.tuicool.com/articles/EVJnI3
袁修开,吕震宙,池巧君. 基于核密度估计的自适应重要抽样可靠性灵敏度分析.西北工业大学学报.Vol.26 No.3.2008.6.
应用例子:
https://www.kaggle.com/arthurtok/introduction-to-ensembling-stacking-in-python
g = sns.pairplot(train[['Survived', u'Pclass', u'Age', u'Sex',u'Parch', u'Fare', u'Embarked',
u'FamilySize', u'Title']], hue='Survived', palette = 'seismic',height=1.2,diag_kind = 'kde',diag_kws=dict(shade=True, kernel='gau',bw=1.0),plot_kws=dict(s=10) )
g.set(xticklabels=[])