缺失值处理
import pandas as pd
# 读取杭州天气文件
df = pd.read_csv("hz_weather.csv")
# 数据透视表
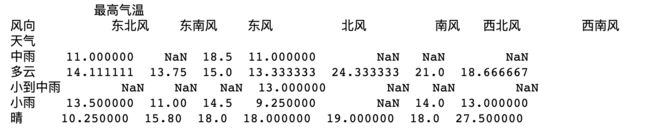
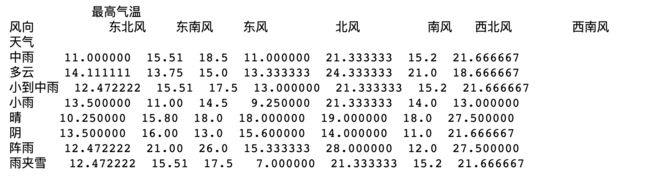
df1 = pd.pivot_table(df, index=['天气'], columns=['风向'], values=['最高气温'])
print(df.head())

print(df1.head())
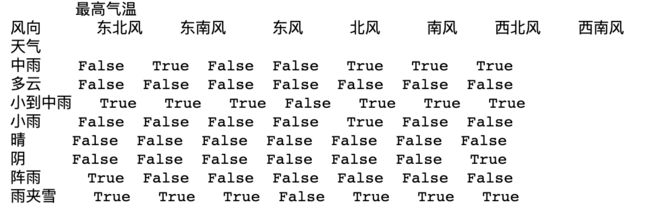
# 用isnull()获得缺失值位置为True,非缺失值位置为False的DataFrame
lack = df1.isnull()
print(lack)
# 用any()可以看到哪些列有缺失值
lack_col = lack.any()
print(lack_col)

# 显示存在缺失值的行列
df1_lack_only = df1[df1.isnull().values == True]
print(df1_lack_only
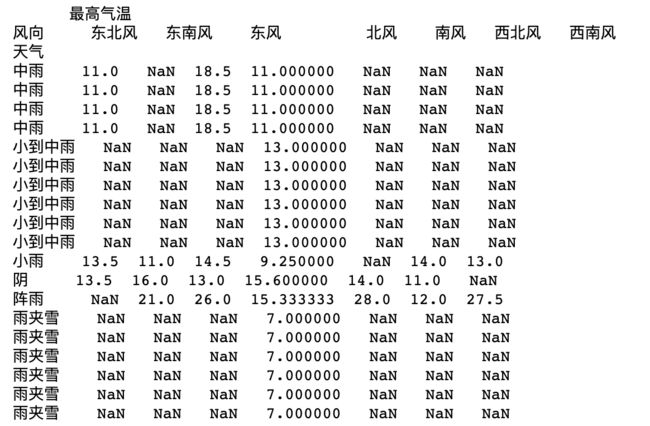
# 删除缺失的行
df1_del_lack_row = df1.dropna(axis=0)
print(df1_del_lack_row)

# 删除缺失的列(一般不因为某列有缺失值就删除列, 因为列常代表某指标)
df1_del_lack_col = df1.dropna(axis=1)
print(df1_del_lack_col) # 只剩下北风

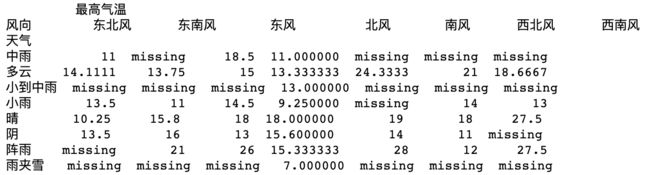
# 使用字符串代替缺失值
df1_fill_lcak1 = df1.fillna('missing')
print(df1_fill_lcak1)
# 使用前一个数据(同列的上一个数据)替代缺失值,第一行的缺失值没法找到替代值
df1_fill_lack2 = df1.fillna(method='pad')
print(df1_fill_lack2)

# 使用后一个数据(同列的下一个数据)替代缺失值,最后一行的缺失值没法找到替代值
# 参数limit=1限制每列最多只能替代掉一个NaN
df1_fill_lack3 = df1.fillna(method='bfill', limit=1)
print(df1_fill_lack3)

# df对象的mean()方法会求每一列的平均值,也就是每个指标的平均值.下面使用平均数代替NaN
df1_fill_lack4 = df1.fillna(df1.mean())
print(df1_fill_lack4)
检测异常值
检测异常值的方法:https://blog.csdn.net/qianfeng_dashuju/article/details/81708597
假设"最低气温"是符合正态分布的,那么就可以根据3σ原则,认为落在[−3σ+μ,+3σ+μ]之外的值是异常值
# %matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
# 读取杭州天气数据
df = pd.read_csv("hz_weather.csv")
# 创建图的布局,位于1行1列,宽度为8,高度为5,这两个指标*dpi=像素值,dpi默认为80(保存图像时为100)
# 返回的fig是绘图窗口,ax是坐标系
fig, ax = plt.subplots(1, 1, figsize=(8, 5))
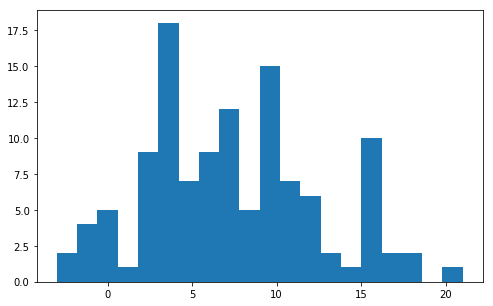
# hist函数绘制柱状图,第一个参数传入数值序列(这里是Series),这里即是最低气温.bins指定有多少个柱子
ax.hist(df['最低气温'], bins=20)
# 显示图
plt.show()
# 取最低气温一列,得到的是Series对象
s = df['最低气温']
# 计算到miu的距离(还没取绝对值)
zscore = s - s.mean()
# 标准差sigma
sigma = s.std()
# 添加一列,记录是否是异常值,如果>3倍sigma就认为是异常值
df['isOutlier'] = zscore.abs() > 3 * sigma
# 计算异常值数目,也就是这一列中值为True的数目
print(df['isOutlier'].value_counts())
四分位数作箱型图和检测异常值
p分位数概念:https://blog.csdn.net/u011327333/article/details/71263081?locationNum=14&fps=1
# %matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
# 符合格式的txt文件也可以直接当csv文件读入
df = pd.read_csv('sale_data.txt')
# 创建图布局
fig, ax = plt.subplots(1, 1, figsize=(8, 5))
# 取上海数据
df_ = df[df['位置'] == '上海']
# 函数boxplot用于绘制箱型图,绘制的指标是'成交量',坐标用前面matplotlib创建的坐标系
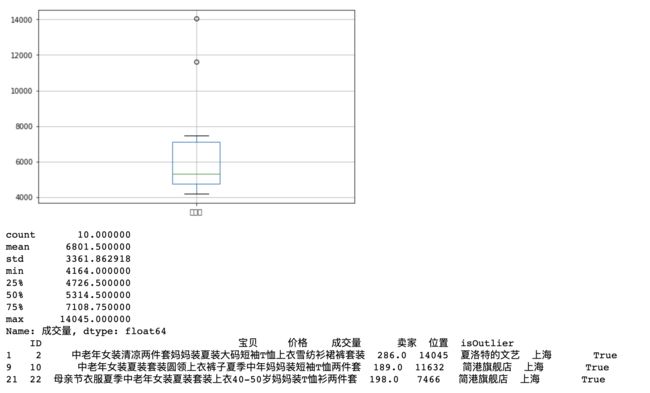
df_.boxplot(column='成交量', ax=ax)
plt.show()
# 查看上海的成交量情况,这里即提取为Series对象
s = df_['成交量']
print(s.describe())
# 这里规避A value is trying to be set on a copy of a slice from a DataFrame
df_ = df_.copy()
# 这里将大于上四分位数(Q3)的设定为异常值
# df_['isOutlier'] = s > s.quantile(0.75)
df_.loc[:, 'isOutlier'] = s > s.quantile(0.75)
# 查看上海成交量异常的数据
df_rst = df_[df_['isOutlier'] == True]
print(df_rst)
重复值处理
import pandas as pd
# 读取杭州天气数据
df = pd.read_csv('E:/Data/practice/hz_weather.csv')
# 检测重复行,生成bool的DF
s_isdup = df.duplicated()
# print(s_isdup)
print(s_isdup.value_counts()) # 全是False

# 检测最高气温重复的行
s_isdup_zgqw = df.duplicated('最高气温')
print(s_isdup_zgqw.value_counts())
# 去除'最高气温'重复的行
df_dup_zgqw = df.drop_duplicates('最高气温')
# print(df_dup_zgqw)