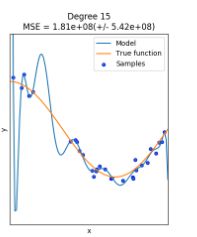
(scikit-learn里面内容太多了,把各个模块拆分一下,并且挑重点的说。)
详细文档:
https://scikit-learn.org/stable/
https://github.com/apachecn/sklearn-doc-zh
1、sklearn 预处理
5.3 数据变换
- 标准化
讲一下几个模块的区别:
数据标准化
StandardScaler (基于特征矩阵的列,将属性值转换至服从正态分布)
标准化是依照特征矩阵的列处理数据,其通过求z-score的方法,将样本的特征值转换到同一量纲下
常用与基于正态分布的算法,比如回归
from sklearn import preprocessing
standard_scaler = preprocessing.StandardScaler()
X_train_standard = standard_scaler.fit_transform(X_train)
standard_scaler.mean_ #查看每列均值
standard_scaler.var_ #查看每列方差
数据归一化
MinMaxScaler (区间缩放,基于最大最小值,将数据转换到特定区间上,默认是0~1,也可以对feature_range参数进行设置)
提升模型收敛速度,提升模型精度
常见用于神经网络
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler((0,1)) #构建模型,如果不设置范围参数,则默认是0~1
X_train_minmax = min_max_scaler.fit_transform(X_train) #使用模型,肯定是以列进行训练哈
min_max_scaler.data_max_ #查看每列最大值
min_max_scaler.data_min_ #查看每列最小值
范式归一化(查看后面)
Normalizer (基于矩阵的行,将样本向量转换为单位向量)
其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准
常见用于文本分类和聚类、logistic回归中也会使用,有效防止过拟合,目前没有遇到过。
from sklearn import preprocessing
normalizer = preprocessing.Normalizer(norm='l2')
X_normalized = normalizer.fit_transform(X)
标准化后的数据可以用numpy函数查看其均值和标准差,如果是标准化转换的话,均值和标准差肯定是0和1。
X_train_minmax.mean(axis=0) #每列的均值,为0
X_train_minmax.std(axis=0) #每列的标准差,为1
上面的min_max_scaler是已经训练好的缩放标准,每列的最大值和最小值都知道了,可以用这个标准来缩放其他数据(比如新来了一行数据)。
X_train_new_minmax = min_max_scaler.transform(X_train_new) #已经训练好的模型
- 非线性转换-转换为分位数(0~1之间)
from sklearn import preprocessing
quantile_transformer = preprocessing.QuantileTransformer(random_state=0)
X_train_trans = quantile_transformer.fit_transform(X_train)
- 非线性转换-高斯变换
有一些简单的变换,比如说指数变换、对数变换可以直接np函数处理,这里sklearn提供了高斯变换的模型,但是具体场景要应用变换的情况应该比较少,这里也不研究。 - 类别特征编码
from sklearn import preprocessing
enc = preprocessing.OrdinalEncoder()
enc.fit(X) #模型训练,实际上第一行全部编码为0,第n行编码为n-1,这样的一种对应关系,所以这里的X应当是需要编码的一个特征矩阵
enc.transform(X1) #上述模型,将X1编码,X1也是需要编码的特征矩阵
另外针对无序的特征,如果不适合采用连续数值编码,可以采用独热编码,可以参见https://www.cnblogs.com/zongfa/p/9305657.html
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
enc.fit(X) # fit来学习编码
enc.transform(X1).toarray() # 进行编码
- 离散化
k-bins离散方法用k个等宽的bins把特征离散化
from sklearn import preprocessing
est = preprocessing.KBinsDiscretizer(n_bins=[3, 2, 2], encode='ordinal').fit(X) #针对三列数据,分别分为3\2\2个bins,最后编码采用0~n-1的编码方式
est.transform(X) #进行离散化
当然也会有分位数的离散化方式,可以采用KBinsDiscretizer来实现。
- 二值化
设定阈值,不超过阈值的就为0:
from sklearn import preprocessing
binarizer = preprocessing.Binarizer(threshold=0) #构建模型
binarizer.fit_transform(X)
- 生成多项式特征
构建多项式特征来增加模型复杂度:
from sklearn import preprocessing
poly = preprocessing.PolynomialFeatures(2) #构建二次多项式模型
poly.fit_transform(X)
X 的特征已经从(X1,X2)扩展为(1,X1,X1平方,2,X2,X2平方)。
也可以通过参数设置来构建比如像X1*X2的较差项。一般这种比较简单直接的函数也可以调用np实现。
5.4 缺失值插补
sklearn插补方法不同于dataframe自己的fillna方法,可以用训练好的模型来插补其他值,所以要看具体的需求。如果fillna可以解决那就更方便。
- 单变量插补
from sklearn import preprocessing
imp = preprocessing.Imputer(missing_values='NaN', strategy='mean', axis=0) #设定缺失值的识别、填补方法
imp.fit_transform(X) #用X来训练,同时插补X
imp.transform(X1) #用训练好的模型来插补X1
- 多变量插补
使用其他列的情况来插补自己列,暂时也用不到
5.5 无监督降维
PCA和非负矩阵因式分解NNF都可以降维,都在第二章无监督学习的机器学习模型中再介绍。
5.8 距离、相似度以及核函数
tips:距离和相似度计算肯定是按行向量算的哈
- 距离计算
距离的定义也有几种,可以在参数进行设置,如果不设置那就是平方距离
from sklearn import metrics
metrics.pairwise_distances(X, Y)
- 相似度
余弦相似度
from sklearn import metrics
metrics.pairwise.cosine_similarity(X, Y)
jaccard相似度在sklearn.metrics.jaccard_similarity_score 里面
-
核函数
这里不是对单一的X进行变换,而是对X和Y进行联合变换。具体要看公式,比如线性变换:
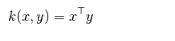 image.png
image.png
from sklearn import metrics
metrics.pairwise.linear_kernel(X, Y) #线性核函数
metrics.pairwise.polynomial_kernel(X, Y) #多项式核函数
metrics.pairwise.sigmoid_kernel(X, Y) #sigmoid核函数
metrics.pairwise.rbf_kernel(X, Y) #RBF核函数
metrics.pairwise.laplacian_kernel(X, Y) #拉普拉斯核函数
metrics.pairwise.chi2_kernel(X, Y) #卡方核函数
5.9 预测目标Y的转换
同样提供了二值化和编码的方法,但是这里要求只能输入series而不是多维的dataframe,所以更多是让你养成习惯,对特征进行编码就用OrdinalEncoder(),对标签进行编码就用LabelEncoder()
from sklearn import preprocessing
lb = preprocessing.LabelBinarizer()
lb.fit(Y)
le = preprocessing.LabelEncoder()
le.fit(Y)
1.13 特征选择(筛除列)
- 移除低方差特征
from sklearn import feature_selection
sel = feature_selection.VarianceThreshold(threshold=0.25) #方差阈值设置
sel.fit_transform(X)
- 单变量特征选择
SelectKBest :移除那些除了评分最高的 K 个特征之外的所有特征
SelectPercentile :移除除了用户指定的最高得分百分比之外的所有特征
from sklearn import feature_selection
sel= feature_selection.SelectKBest(feature_selection.chi2, k=2) #用卡方分布来对样本集进行评分,并选择最好的两个
sel.fit_transform(X, y) #卡方校验是需要y值的
这里讲一下卡方分布校验某项特征是否会影响分类情况:

假设某项特征与分类无关的话,对其进行区间离散,每个区间的分类数目应当是等分的,那么与实际分类数目的残差的平方(基本上校验都是对残差校验)是符合标准正态分布的,所以各个区间的残差之和是服从卡方分布的。函数会返回一个卡方值以及对应的p值,p值对应的是α显著性水平,如果过高的话则会被拒绝(α=1-置信度,这里希望α值越小越好,因为只用很小的置信度就可以满足)。这里我们是希望卡方越大越好,所需要的置信度就越高,p值则越小,因此可以拒绝H0,即认为该特征与分类有关。所以最后是保留卡方值很大的几项特征,对应的p很小。
p值、校验数值(卡方值)、H0假设真的要对应起来看,不过一般情况下做的H0假设都是我们希望拒绝的假设,这下的话P很小的话,我们就可以拒绝H0,从而找到符合自己的期望的结论。
from sklearn import feature_selection
feature_selection.chi2(X,y)#会返回卡方值以及对应的p
这里给了一个参考,不过就我个人而言,卡方值做特征值筛选是非常合理的,而其他做分类和回归校验好像没有特别合理的地方。

- 使用 SelectFromModel 选取特征
SelectFromModel 也是外包的一个元转换器,可以用来处理任何带有 coef_ 或者 feature_importances_ 属性的训练之后的评估器。
from sklearn import feature_selection
sel=feature_selection.SelectFromModel() #设置参考的模型,以及设置从coef_选择还是通过阈值(评分)从feature_importances_中选择
一般是从决策树中进行feature_importances_选择;或者其他模型结合L1正则项(L1会逼近系数为0)进行coef_选择。
2、模型
1.1 线性模型
- 普通最小二乘法
from sklearn import linear_model
reg = linear_model.LinearRegression()
reg.fit (X,Y)
reg.coef_ #非常数项系数
reg.intercept_ #常数项
reg.predict(X_predict) #预测
-
岭回归
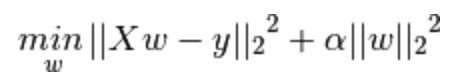 image.png
image.png
对非常数项系数做L2正则化,岭系数最小化的是带罚项的残差平方和。
from sklearn import linear_model
reg = linear_model.Ridge (alpha = .5) #设置惩罚系数
reg.fit (X,Y)
reg.coef_ #非常数项系数
reg.intercept_ #常数项
reg.predict(X_predict) #预测
-
Lasso回归
 image.png
image.png
L1正则项(前面的2n应该不用管,因为实际上只是控制α的惩罚大小)
由于 Lasso 回归产生稀疏模型,因此可以用于执行特征选择
from sklearn import linear_model
reg = linear_model.Lasso (alpha = .5) #设置惩罚系数
reg.fit (X,Y)
reg.coef_ #非常数项系数
reg.intercept_ #常数项
reg.predict(X_predict) #预测
-
弹性网络
 image.png
image.png
L1+L2,通过参数控制两者比例大小,模型不管
-
贝叶斯回归
在引入了L1和L2后,惩罚项的参数通常是人工设定或者参数寻优找到的,贝叶斯回归则是通过概率寻优得到的。(里面肯定是做了假设的,比如输出y服从什么分布之类的),模型不管
 image.png
image.png 逻辑回归
from sklearn import linear_model
LR = linear_model.LogisticRegression (penalty='l2',C=1.0) #默认是L2正则项
LR.fit (X,Y)
LR.coef_ #非常数项系数
LR.intercept_ #常数项
LR.predict(X_predict) #预测
LR.predict_proba(X_predict) #预测属于各个类的概率
LR.score(X,Y) #返回给定测试数据和标签上的平均准确度
逻辑回归因为是分类问题,所以有predict_proba的方法。
有一个细则是我现在学习的都是二分类的逻辑回归,要么0,要么1,而sigmoid函数也正好返回一个0~1的概率,所以如果是二分类问题,LR.predict_proba(X_predict) 会返回两个值,一个是属于0类的概率,一个是返回1类的概率,两者之和必为1.
但实际上逻辑回归是可以处理多分类问题的,比如有N个分类的话,会返回N个概率,和为1。所以逻辑回归如何处理多分类问题、sigmoid函数如何拓展,还没有研究。
1.4 支持向量机
from sklearn import svm
clf=svm.SVC() #其实有好几种svm模型,svc就是最典型那种
clf.fit(X, Y)
clf.predict(X_predict) #预测
clf.predict_proba(X_predict) #预测属于各个类的概率,得事先在模型中设置probability=True,不然向量机的模型概率意义不是很大
clf.score(X,Y) #返回给定测试数据和标签上的平均准确度
clf.support_vectors_ #获得支持向量
clf.support_ #获得支持向量的索引
clf.n_support_ #每一个类别的支持向量的数量
clf.dual_coef_ #支持向量的系数
SVC和NuSVC提供多元分类方式,具体可以看参数,本质上是“one-against-one”的模型训练,提供了多个分类器。
向量机也可以用于回归,理论上只要只是最开始的推导公式的不同,或者说把所有的值都归一化到0~1之间再进行分类,转化为为分类问题也是进行回归的一种方法(LR的理论。。)。具体细则没有多做研究。典型的回归模型是SVR。
from sklearn import svm
clf=svm.SVR() #选择核函数应该蛮关键的了,因为是做回归而不是分类
clf.fit(X,Y)
clf.predict(X_predict)
1.5 KNN
KNN寻找数据有两种思想,一种是K的数目限制,一种是radius半径限制。
from sklearn import neighbors
nbrs = neighbors.NearestNeighbors() #有两种KNN思想,一种是K的数目限制,一种是radius半径限制;参数里面可以设置距离的计算方法,与sklearn.meric里面的方法都可以用
nbrs.fit(X)
distances, indices = nbrs.kneighbors (X) #这里是用k数目,实际只返回K-1个值,因为会返回自己,占第一个位置
distances #返回距离 ,自己与自己的距离是0
indices #返回序号,第一项是自己的序号
distances, indices = nbrs.radius_neighbors (X) #这里是半径
distances
indices
nbrs.kneighbors_graph(X).toarray() #生成洗漱矩阵,是k邻近范围内为1,不在则为0
KNN分类的话,比聚类还简单粗暴,聚类是要不断更新质心的,而KNN是按照K邻近的分类结果进行投票,归为多数类,很直接简单。但KNN分类本质上是监督分类,不同于聚类的无监督。
from sklearn import neighbors
clf=neighbors.KNeighborsClassifier() #参数设置
clf.fit(X,Y)
clf.predict(X_predict)
KNN回归的话,是根据K邻近的值进行均值回归.
from sklearn import neighbors
reg=neighbors. KNeighborsRegressor() #参数设置
reg.fit(X,Y)
reg.predict(X_predict)
1.9 朴素贝叶斯
相比于其他更复杂的方法,朴素贝叶斯学习器和分类器非常快。 而且在文档分类和垃圾邮件过滤等方面的效果都不错(取决于实际场景是否适用)。但是,尽管朴素贝叶斯被认为是一种相当不错的分类器,但却不是好的估计器(estimator),所以不能太过于重视从 predict_proba 输出的概率。(因为实际值可能都非常非常小,概率值和也不会为1)
-
高斯朴素贝叶斯:
 image.png
image.png
所以如果对n维特征,可以分为m类,是有n*m个高斯参数的,因为是相互独立进行估计的。。
from sklearn import naive_bayes
clf= naive_bayes. GaussianNB() #参数设置
clf.fit(X,Y)
clf.predict(X_predict)
clf.predict_proba(X_predict)
-
多项分布朴素贝叶斯
 image.png
image.png
这个就是典型的贝叶斯了,靠频率计数来估计。。
from sklearn import naive_bayes
clf= naive_bayes. MultinomialNB() #参数设置
clf.fit(X,Y)
clf.predict(X_predict)
clf.predict_proba(X_predict)
1.10 决策树
决策树典型的集中方法ID3、C4.5、CART,scikit-learn 使用 CART 算法的优化版本。
ID3:熵的信息增益
C4.5:熵的信息增益率
CART:基尼指数来划分
- 决策树分类
from sklearn import tree
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
clf.predict(X_predict)
clf.predict_proba(X_predict) #返回的是属于各个类的概率,应该是根节点上面三个类的样本的数目占比
- 决策树可视化
进一步,采用graphviz进行决策树可视化。
import graphviz
dot_data = tree.export_graphviz(clf) #graphviz是识别dot_data数据类型,这里的dot_data可以用out_file参数导出
graph = graphviz.Source(dot_data) #形成图像
graph

上面的value是什么意思?是分属于几个类的样本数目!!!
export_graphviz 还支持各种美化,包括通过他们的类着色节点(或回归值),如果需要,还能使用显式变量和类名。具体可以看模块说明。
- 决策树回归
决策树分类是以熵、基尼系数等来作为树决策的,决策树回归是以均方误差mse(也可以选其他的标准)来作为树决策的,在设定的最大树深度、叶节点所需最小样本数、拆分内部节点所需最小样本数等参数的限制下(所以对参数选择应该很敏感),最终展开为决策回归树。所以最后应该是有多少根节点就有多少个回归值(为其样本均值)。
from sklearn import tree
reg= tree.DecisionTreeRegressor()
reg= reg.fit(X, Y)
reg.predict(X_predict)
- 多输出决策树
可以构建多个决策树,每个决策树有一个输出,也可以直接构建多输出决策树,本质上和单决策树也没区别。。
1.11 集合方法
- bagging-元估计器
元估计器可以实现用任意clf或者reg模型来组合,只需要人工设定基模型类型、基模型数目、基模型样本量、基模型特征量、基模型有无放回抽样等等
from sklearn import ensemble
from sklearn import neighbors
bagging = ensemble.BaggingClassifier(neighbors.KNeighborsClassifier(),max_samples=0.5, max_features=0.5)
- bagging-随机森林
from sklearn import ensemble
clf = ensemble.RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, Y)
当然也可以用RandomForestRegressor做随机森林回归。
有几个参数:
n_estimators:理论上是越多越好,但当树的数量超过一个临界值之后,算法的效果并不会很显著地变好。
max_features:随机选择的特征数目,根据经验,回归问题中使用 max_features = None (总是考虑所有的特征), 分类问题使用 max_features = "sqrt" (随机考虑 sqrt(n_features) 特征,其中 n_features 是特征的个数)是比较好的默认值。
max_depth = None 和 min_samples_split = 2结合通常会有不错的效果(即生成完全的树)。
n_jobs = k:并行化提升速度。
feature_importances_:这是属性(不是参数),表征各个特征的重要性,总和为1。重要性的计算依据?一是顶部特征肯定最重要(纯度减少更多);二是在森林中的使用次数越多说明越重要。所以sklearn是将两者进行结合计算的。具体算法没有详说,反正参照的是别人的论文。
- boosting- adaboost
from sklearn import ensemble
clf=ensemble.AdaBoostClassifier(n_estimators=100)
clf = clf.fit(X, Y)
参数说明:
n_estimators:控制弱学习器的数量(boosting也是多个学习器),相当于迭代次数
learning_rate:学习率/贡献率,需要和n_estimators配合使用。我找了一下,adaboost的贡献率α是严格推导出来的最优值,但可以更改的地方在于向前分布算法只是一种求解原复杂问题的替代方案,所以通过比率缩放贡献率的话,可以推动用更多弱学习器来进行拟合。
base_estimator:弱学习器的类型(可以不是决策树),还可以进一步设置弱学习器的max_depth等等(所以也不是弱学习器只有一个决策分支)。。。
- Gradient Tree Boosting(梯度树提升)
from sklearn import ensemble
clf=ensemble.GradientBoostingClassifier(n_estimators=100)
clf = clf.fit(X, Y)
也可以做回归(都可以做回归。。)
from sklearn import ensemble
reg=ensemble.GradientBoostingRegressor(n_estimators=100)
reg= reg.fit(X, Y)
有几个重要参数:
loss:设定损失函数。(adaboost是指数损失函数,不能更改的)
clf.train_score_:属性,返回每一次迭代的训练误差
clf.staged_predict():方法,返回的是一个生成器,用来产生每一 个迭代的预测结果,所以得用生成器的方式来取数(i,y_pred)。如果要返回每一次预测的误差,需要配合clf.loss_来计算一下,具体可以参见案例:
https://scikit-learn.org/stable/auto_examples/ensemble/plot_gradient_boosting_regression.html#sphx-glr-auto-examples-ensemble-plot-gradient-boosting-regression-py
- 投票器
投票器是再用一层包装(就像bagging的元估计器),对多个不同的机器学习分类器的结果进行投票。
分类:
from sklearn import ensemble
clf1=...
clf2=...
clf3=...
eclf = ensemble.VotingClassifier(estimators=[('lr', clf1), ('rf', clf2), ('gnb', clf3)], voting='hard')
投票方式又可以分为硬投票、软投票;
投票也可以用来回归;
详情可以看案例。
1.12 多类和多标签算法
sklearn.multiclass模块采用了 元评估器 ,通过把多类 和 多标签 分类问题分解为 二元分类问题去解决。这同样适用于多目标回归问题。
但是本身很多分类器本身就提就是多类分类器,可以查看其是否为多分类器、属于哪一类多分类器。总的可以分为:
- 固有的多类分类器:比如sklearn.neighbors.KNeighborsClassifier返回的是一个矩阵,值分别为分属于N个类的概率,概率之和为1。
- 1对1的多类分类器:只有两类,且最后只输出属于哪一类
- 1对多的多累分类器:有多类,且最后只输出属于哪一类
- 支持多标签分类的分类器:可以多属于多个标签里面。
- 多输出分类:输出多个值。
1.17 神经网络
- 多层感知器
from sklearn import neural_network
clf=neural_network.MLPClassifier(hidden_layer_sizes=(5,3,2),activation='logistic',solver='sgd',learning_rate_init=0.5,shuffle =True) # MLP的话只能设置隐藏层的激活函数,不存在输出层的函数;采用交叉熵函数为损失函数,不能自定义损失函数
clf.fit(X, y)
clf.predict(X_predict)
clf.predict_proba(X_predict)
clf.coefs_ #系数矩阵
ps,sgd随机梯度下降就是每次在众多样本中只随机选择一个样本的梯度作为全局梯度迭代,所以需要配合shuffle设置为True保证每次选择样本的时候会混洗;除了随机梯度也有批量梯度迭代(全局梯度迭代)和小批量梯度迭代。
也可以用MLPRegressor做回归,但是局限比较大(MLP分类的局限性都比较大了,毕竟不允许输出层激活函数和损失函数的设置),采用恒等函数做为激活函数、平方误差作为损失函数,不能自行设置。
2.3 聚类
- kmeans
距离计算方式为平方距离,不能更改
from sklearn import cluster
clf=cluster.KMeans(n_clusters=2, random_state=0) #k数目、迭代次数、迭代最小值等;距离方式为平方距离,不能更改
kmeans=clf.fit(X)
kmeans=clf.predict(X_predict)
kmeans.labels_ #返回样本所属簇标签
kmeans.cluster_centers_ #返回簇质心
- 层次聚类
层次聚类需要设定最终的树的数目;树间的距离计算方式一般采用ward(平方差总和)方式
from sklearn import cluster
clf=cluster.AgglomerativeClustering(n_clusters=2) #最终树的数目、affinity距离方式、linkage树内的距离计算方式ward、complete等
kmeans=clf.fit(X)
kmeans.labels_ #返回样本所属簇标签
用scipy进行层次聚类的可视化,scipy实现层次聚类的可视化都是计算+可视化一体的,所以无法先用sklearn计算,再用scipy可视化。。。
https://blog.csdn.net/fengchi863/article/details/80537733
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
X=np.array([[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]])
Z = linkage(X, 'ward','euclidean') #linkage是层次聚类函数,
plt.figure()
dn = dendrogram(Z)
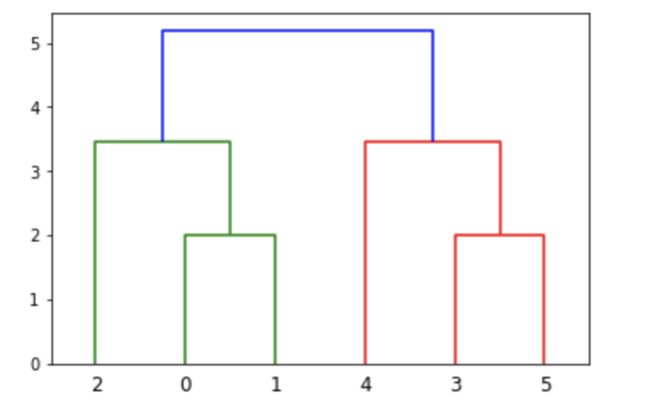
可以和sklearn的聚类结果对比,前三项被聚为一类、后三项被聚为一类,所以是一致的!:

- 其他聚类
谱聚类、密度聚类等等,提供了相当多的包,但是最常用的可能还是k聚类和层次聚类 - 聚类性能度量
python提供了的聚类度量主要是监督性的聚类度量(已知正确分类结果),兰德指数、互信息等。。。
2.5成分分解
- PCA
https://blog.csdn.net/program_developer/article/details/80632779
PCA可以通过特征值分解EVD和奇异值分解SVD两种方案实现,EVD的步骤是:1)去平均值(即去中心化),即每一位特征减去各自的平均值。2) 计算协方差矩阵。3) 用特征值分解方法求协方差矩阵的特征值与特征向量。4) 对特征值从大到小排序,选择其中最大的k个。然后将其对应的k个特征向量分别作为行向量组成特征向量矩阵P。5) 将数据转换到k个特征向量构建的新空间中,即Y=PX。
import numpy as np
from sklearn import decomposition
X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
pca =decomposition.PCA(n_components=2) #设定降维数 ,也可以用小数点设置降维后达到的方差量为多少
pca.fit_transform(X)
pca.get_covariance() #协方差矩阵
pca.components_ #n个维度的映射关系,是以行排列的
pca.explained_variance_ratio_ #n个维度的方差百分比
np.dot(X,pca.components_.T) #这个等价于pca.fit_transform(X) ,就是转换关系!!
核PCA
上述是线性的PCA,sklearn也提供核PCA,不做多研究。非负矩阵因式分解NNF
from sklearn import decomposition
X = np.array([[1, 1], [2, 1], [3, 1.2], [4, 1], [5, 0.8], [6, 1]])
nmf = NMF(n_components=2) #设置特征数目
W = nmf.fit_transform(X) #权重矩阵
H = nmf.components_ #特征矩阵
np.dot(W,H) #X=WH

与X值是相等的。
三、模型选择和评估
3.1 交叉验证
- 训练集测试集分割
from sklearn import model_selection
from sklearn import datasets
iris = datasets.load_iris()
X_train, X_test, y_train, y_test = model_selection.train_test_split(iris.data, iris.target, train_size=0.4, random_state=0)
clf=svm.SVC().fit(X_train,y_train)
clf.score(X_test, y_test)
- 模型交叉验证CV
from sklearn import model_selection
clf = svm.SVC(kernel='linear', C=1)
scores =model_selection.cross_val_score(clf, iris.data, iris.target, cv=10) #cv设置为整数则为采用K折法
scores.mean() #得到n此交叉验证的模型平均精度
print("Accuracy: %0.2f (+/- %0.2f)" % (scores.mean(), scores.std() * 2)) #置信度表示
cross_val_score只返回测试得分,cross_validate 可以返回多个指标,如果不进行设置的化,会返回训练得分、拟合次数、得分次数(time是时间还是次数表示怀疑?这里可能表示用于模型训练和测试的时间)的字典。一般不会用到cross_validate。
- 交叉验证迭代器K-Fold
from sklearn import model_selection
X = ["a", "b", "c", "d"] #X是什么不重要,它只是需要计算下X的长度
kf = model_selection.KFold(n_splits=4) #设置K折数目
for train, test in kf.split(X):
print("%s %s" % (train, test))

可以看到,KFold是一个迭代器,而且返回的是原始数据的序号,如果要取数据的话,需要用序号再取。
RepeatedKFold可以设置参数从而重复K-Fold n次。。
LeaveOneOut和LeavePOut是留一法和留P法,不过可以也可以设置KFold中n_splits=X.shape[1]来实现。
- 基于类标签、具有分层的交叉验证迭代器
用于解决样本不平衡问题,理想情况是希望筛选的样本在各个类别中的比例保持原样。(如果是希望各类样本的数目一致的话不能用这个模型选)
from sklearn import model_selection
X = np.ones(10) #X是什么不重要,它只是需要计算下X的长度
y = [0, 0, 1, 1, 1, 1, 1, 1, 1, 1] #y是什么很重要,它需要计算原始分层比例
skf = model_selection.StratifiedKFold(n_splits=3)
for train, test in skf.split(X, y):
print("%s %s" % (train, test))

结果可以看出,原始的分层比例被保留,这里对比一下用KFOLD来选择的结果:

- 组k-fold
组k-fold的核心思想是希望用尽少可能的组做训练,然后测试集中的组都是新的,这样可以检测新来源的样本(新的组),是否适用于该模型。
from sklearn import model_selection
X = [0.1, 0.2, 2.2, 2.4, 2.3, 4.55, 5.8, 8.8, 9, 10]
#X不重要
y = ["a", "b", "b", "b", "c", "c", "c", "d", "d", "d"]
#y是可选,看你自己认为需不需要
groups = [1, 1, 1, 2, 2, 2, 3, 3, 3, 3]
#groups很重要,他需要知道标签
gkf = model_selection.GroupKFold(n_splits=3)
for train, test in gkf.split(X,y, groups=groups):
... print("%s %s" % (train, test))
这里的y是可选,我认为是如果没有y的话,就按照groups最优切割进行切割,如果有考虑y的话,则要进一步考虑对y的分层切割。。
相对应的,还有留一组和留P组的分割,不过都用不着。。。
ps:为了避免原始数据中心数据的顺序是有一定规则的(例如,相同标签的数据连续出现),一般情况是设置参数shuffle=True进行原始数据打散,再进行切割的。
3.2 超参数估计
https://www.cnblogs.com/nolonely/p/7007961.html
学习器模型中一般有两个参数:一类参数可以从数据中学习估计得到,还有一类参数无法从数据中估计,只能靠人的经验进行指定,后一类参数就叫超参数。
sklearn 提供了两种通用的参数优化方法:
a) 网格搜索交叉验证(GridSearchCV):以穷举的方式遍历所有可能的参数组合;
b) 随机采样交叉验证(RandomizedSearchCV):依据某种分布对参数空间采样,随机的得到一些候选参数组合方案(相当于已知概率曲线,然后按概率取值)。
在此之外,还有贝叶斯优化,也是对超参数的的一种优化。个人感觉是通过先验概率来不断优化假定的概率函数的参数,并进一步进行概率筛选,相当于比随机采样还多了一步概率函数的参数优化(以后有机会再研究)。
- 网格搜索
https://scikit-learn.org/stable//auto_examples/model_selection/plot_grid_search_digits.html#sphx-glr-auto-examples-model-selection-plot-grid-search-digits-py
from sklearn import model_selection
from sklearn import metrics
from sklearn.svm import SVC #设定模型
# 超参数设定格式是含多个字典的list
tuned_parameters = [{'kernel': ['rbf'], 'gamma': [1e-3, 1e-4],'C': [1, 10, 100, 1000]},
{'kernel': ['linear'], 'C': [1, 10, 100, 1000]}]
#寻优目标
scores = ['precision', 'recall']
for score in scores:
print("# Tuning hyper-parameters for %s" % score)
clf = model_selection.GridSearchCV(SVC(), tuned_parameters,scoring='%s_macro' % score)
#网格搜索的格式!!cv是k折法,不属于超参数
clf.fit(X_train, y_train)
print("Best parameters set found on development set:")
print()
print(clf.best_params_)
print()
print("Grid scores on development set:")
print()
means = clf.cv_results_['mean_test_score'] #网格搜索后所带有的属性
stds = clf.cv_results_['std_test_score'] #网格搜索后所带有的属性,就这两者用的比较多吧
for mean, std, params in zip(means, stds, clf.cv_results_['params']):
print("%0.3f (+/-%0.03f) for %r"
% (mean, std * 2, params)) #两倍标准差设置
print()
print("Detailed classification report:")
print()
y_true, y_pred = y_test, clf.predict(X_test)
print(metrics.classification_report(y_true, y_pred))
#metrics带有的报告模块。要用打印格式才不会乱码;这里返回结果有9组,是因为有9种label
print()
随机采样可以查看文档。。
3.3 模型评估
- 常见分类评估指标
召回率recall,TP/(TP+FN):
metrics.recall_score()
精度precision,TP/(TP+FP):
metrics.precision_score()
准确性accuracy,(TP+TN)/(TP+TN+FP+FN):
metrics.accuracy_score()
f1,2PrecisionRecall)/(Precision+Recall):
metrics.f1_score() #实际上还有微观f1、宏观f1、权重f1等方式
roc_auc:
metrics.roc_auc_score #这个有点问题,之后再看
metrics.auc(fpr, tpr) #上面那个有问题,可以用下面这个计算auc面积,fpr和tpr是数组,对应不同阈值时的值
- 常见回归评估指标
https://blog.csdn.net/Softdiamonds/article/details/80061191
绝对值误差:metrics.mean_absolute_error
均方误差:metrics.mean_squared_error
决定系数(拟合优度)r2:metrics.r2_score
模型越好:r2→1
模型越差:r2→0
- 混淆矩阵
y_true = [0, 0, 0, 1, 1, 1, 1, 1]
y_pred = [0, 1, 0, 1, 0, 1, 0, 1]
tn, fp, fn, tp=confusion_matrix(y_true, y_pred).ravel() #展开数组,得到的是tn, fp, fn, tp
-
分类报告
 image.png
image.png
3.4 模型持久化
使用pickle模块,或者joblib模块
from sklearn.externals import joblib
joblib.dump(clf, 'filename.pkl') #保存模型
clf = joblib.load('filename.pkl') #加载模型
3.5 验证曲线和学习曲线
核心概念是偏差-方差困境:如果模型过于简单,会有很大的偏差(也就是模型误差),如果模型过于复杂,很有可能是用很复杂的模型进行过拟合,这时候虽然在验证集上有很好的效果,但是在测试集、或者是新数据上效果不好,即不能很好地拟合真实的函数,即对训练数据的变化(高方差)非常敏感。一般解决的办法就是尽量找到合适的参数避免过拟合和欠拟合(验证曲线)、以及利用合适的样本数目保证模型训练拟合度(学习曲线)。详细可以参见文档。