智源青年科学家袁洋:机器学习可靠性与算法优化的方法探索

2020年2月11日,在“智源论坛Live | 青年科学家线上报告会”上,智源青年科学家、清华大学助理教授袁洋作了题为《机器学习可靠性与算法优化》的演讲。袁洋,2018 年获得康奈尔大学计算机专业博士学位,在机器学习理论与算法设计方面取得了突出成果。他参与合作的关于SGD 逃离鞍点的论文是机器学习理论顶级会议COLT 最近5 年来被引用次数最多的论文,并独立证明了第一个满足严格鞍点性质的函数,即张量分解问题;此外,袁洋还与他人合作给出了第一篇SGD 在非线性网络的收敛性分析。
本次讲座,袁洋主要从三大研究方向:机器学习理论、机器学习可靠性、机器学习与算法优化为大家做了精彩的阐述。在机器学习理论方向,袁洋和大家分享了随机梯度下降法(SGD)的理论分析和神经网络收敛性分析的一些结果;在机器学习可靠性方向,袁洋主要的工作和本次的分享主要集中在对抗样本和鲁棒性的研究;对于机器学习与算法优化方向,他认为虽然这其实是两个方向的结合,但是二者是互相帮助的,我们可以用算法、用理论的方式,来解决机器学习的一些问题,同时也可以用机器学习的技术来改进已有的传统算法获得更好的效果。
整理:钱小鹅
编辑:王炜强
![]()
机器学习理论
机器学习理论的基础分为三个方面,表达能力理论(Representation)、优化理论(Optimization)、泛化理论(Generalization),这三个方向目前都有很多很有意义的研究,袁洋的主要方向是优化理论,也会涉及一点泛化理论的内容。本次讲座,我们主要介绍给大家SGD方法的一些性质,重点是SGD逃离鞍点的工作,也会谈及SGD逃离局部最优点分析、两层神经网络收敛性分析以及对未来的研究构想,下面我们从这四个方向分别为大家整理说明。
SGD逃离鞍点[Ge, Jin, Huang, Yuan, COLT’15]
深度学习从某种角度看,可分成两个步骤:第一步,针对具体一个问题来设计好的网络结构,使得这个网络结构能对应解决我们要解决的问题;第二步,考虑使用随机梯度下降法(SGD)或者其变体进行优化。例如:在机器视觉领域,包括图像分类、风格迁移等,我们首先设计好的卷积网络结构,接着使用SGD去做数值优化;Alphago围棋对决,也是使用强化学习、卷积网络以及蒙特卡洛树搜索后使用SGD做优化;同样自然语言处理中一般是Transformer网络和SGD的组合算法。因此,袁洋认为机器学习如同一列很长的列车,卷积网络、强化学习等各种不同的算法可以看成是一节节不同的车厢,而SGD优化方法,如同整个火车的引擎,最终拖着不同的算法达到最后目的地,因此深刻理解SGD是非常重要的。

图1:SGD在机器学习中如同引擎
首先,我们介绍SGD的“祖师爷”-GD,也就是所谓的梯度下降法。在机器学习中,梯度下降的目标是优化一个损失函数L,数学表达式即为:
![]()
优化方法是简单的迭代:
![]()
![]()
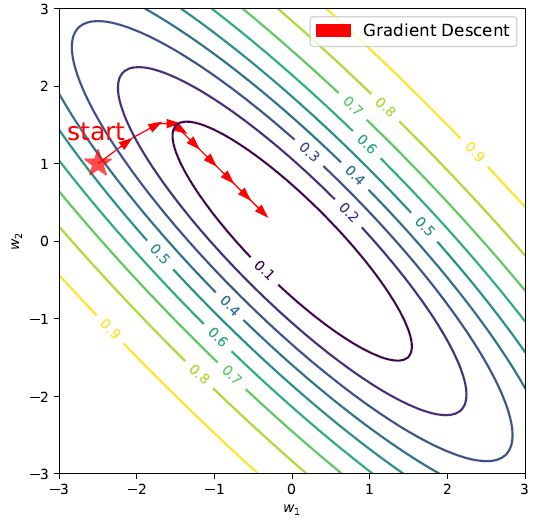
图2: 梯度下降法
如图2所示,迭代函数是个二维函数,从随机点做梯度下降的话,如果每一步都选择函数的严格梯度,逐步迭代后最终会找到函数的全局最优点。虽然GD算法的理论知识非常简单,图示也很直观,但是却有两个局限性:
1.(从应用角度来看)计算
![]()
非常慢:需要扫遍所有数据;如果数据很多,就会很慢。
2.(从理论角度来看)可能会卡在稳定点(导数为0的点)上,如图3中我们不难看出,有三个点是导数为0的点。虽然这三个点导数都是0,但是只有中间的点是全局最优点,而左边是鞍点,右边是局部最优点。有理论工作指出,当使用GD算法的话,有可能需要指数时间才能逃离鞍点[Du,Jin, Lee, Jordan, Poczos, Singh, NeurIPS’17]。
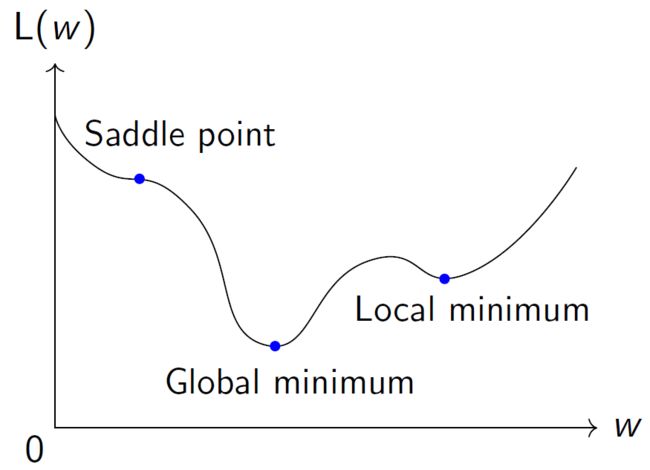
图3: L(w)函数图
鉴于GD算法的局限性,我们在实际应用中通常更偏向使用SGD。SGD与GD算法两者是非常相似的,唯一的区别在于迭代过程中,导数的选择具有随机性,其数学表达式如下:
![]()
也就是说随机梯度Gt的期望等于严格精确导数即可,而随机梯度本身并不需要严格等于导数。它允许包含一些噪声。如图4中,蓝色收敛路径为SGD的收敛路径,红色收敛路径为GD路径。不难看出,蓝色收敛路径比红色长很多而且杂乱很多,因为每次走的是它的随机梯度,它的方向有噪声,但最后也可以慢慢收敛到全局最优点。很多读者会问,既然它走的这么杂乱而且路径比GD这个算法要长,为何在实际中更常用呢?一开始是因为人们发现随机导数要比准确导数算的快,因为如果只需要一个期望正确的随机导数的话,我们只需要在数据里采几百个点算一算就可以,而不是把每个点都过一遍,现在我们发现,从理论角度SGD还有别的优点,比如可以逃离鞍点[Ge, Jin, Huang, Yuan, COLT’15],逃离比较陡的局部最优点[Kleinberg, Li, Yuan,ICML’18],这也是袁洋最近的一些工作,而且其他的科研人员发现SGD可以在实际中找到一些泛化性能更好的解[Keskar, Mudigere, Nocedal, Smelyanskiy, Tang, ICLR’17] ,所以与GD相比,SGD不仅是个更快的算法,而且是个实际效果更好的算法。
下面我们详细介绍袁洋在机器学习理论中的两个研究工作:
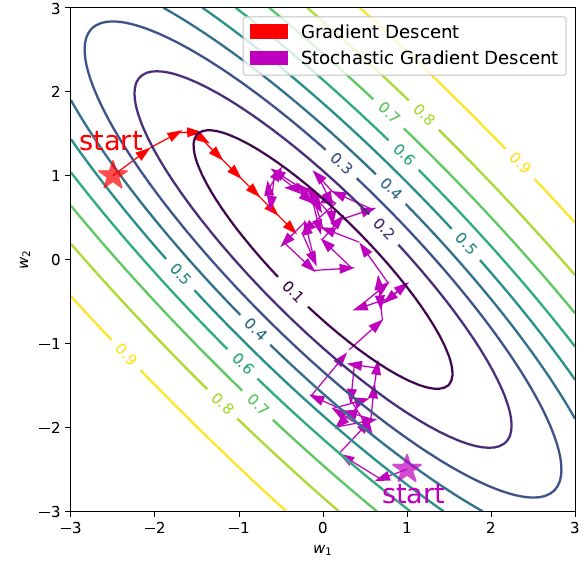
图4: 梯度下降法与随机梯度下降法图示
研究方向一:逃离鞍点
如图5所示,浅色箭头所指的点为鞍点。为何是个鞍点呢,首先导数是0,其次从某些方向来看它的函数不断上升,从某些方向来看它的函数不断下降,所以不是个局部最小或者最大值,因此它是个鞍点。要观察到的是,途中鞍点并不稳定,也就是说在图里加一个很小的扰动,我们就可以顺着梯度方向滑下去,所以这是个典型的容易处理的鞍点,就是说存在一个方向,有可能是能滑下去的,SGD因为梯度里有一些噪声,加上这个噪声之后,就像滑梯一样沿着这个方向滑下去了。更准确直观的说明,我们不妨给出它的数学定义:

与此同时,我们给出严格鞍点函数的非正式定义,不妨说:
L是一个严格鞍点函数,如果L定义域中不包含任何平坦鞍点。
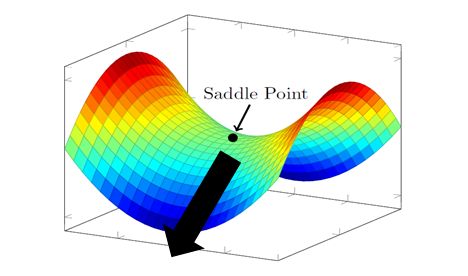
图5: 鞍点示意图
逃离鞍点的理论结果证明了,如果函数是严格鞍点的,那么SGD可以逃离所有鞍点,收敛到某一个局部最小值(注:这也是第一篇SGD逃离鞍点的严格理论证明)。该证明的意义深远:第一,如果L是严格鞍点的,则(根据该定理)SGD会收敛到局部最小值;第二,如果同时L的局部最小值一样好,则SGD收敛到的是全局最小值。因此,当严格鞍点函数和局部最小值一样好这两个条件同时存在时,使用SGD算法将可以完美优化L这个函数。
当然,很多读者又会思考,“严格鞍点函数和局部最小值一样好”这两个条件很强,在使用中如何满足呢?后来人们发现,在机器学习领域中,有大量问题函数都天然满足这两个条件,包括Community Detection [Huang, Niranjan, Hakeem,Anandkumar, JMLR'14]、Topic models [Zou, Hsu, Parkes, Adams, NeurIPS'13]、Shallow/linear networks [Kawaguchi, NeurIPS'16]、Matrix completion [Ge, Lee, Ma, NeurIPS'16]、Phase Retrieval [Sun, Qu, Wright, ISIT'16]、Matrix Sensing [Bhojanapalli, Neyshabur, Srebro,NeurIPS'16]等等。同时,科研人员也据此提出了很多新的算法,例如:GD with random initialization [Lee, Simchowitz, Jordan, Recht, COLT'16]、Normalized GD [Levy'16]、Perturbed GD [Jin, Ge, Netrapalli, Kakade,Jordan, ICML'17]、Accelerated GD [Jin, Netrapalli, Jordan, COLT'18]等。通常情况下,理论和实际之间是有一定差别的,但是严格鞍点函数在优化理论和实际应用中却起到了很好的桥梁作用。如果一个函数是严格鞍点的,从理论角度可以设计各式各样有理论保证的算法,来解决严格鞍点的问题;而从实际角度看,我们发现实际中有各式各样的机器学习的问题,它们的损失函数满足严格鞍点的性质,因此又促使我们从理论设计新的方法来解决这些问题。
图6: 严格鞍点函数是一个很好的桥梁
SGD逃离局部最优点[Kleinberg, Li, Yuan, ICML’18]
在机器学习理论的第二部分,袁洋为我们分享了他及其合作伙伴关于SGD逃离最优点的研究成果。在此之前,有读者可能认为,SGD逃离最优点这件事本身就很荒诞:如图7所示,局部最优点是个“坑”,如果用SGD这样的迭代方法走进这个“坑”中,应该很难跳出来才对,但实际中如果遇到的“坑”特别陡,如图7中靠左边的蓝色局部最小点,我们看到即是收敛路径一开始已经陷入局部最小值中,如果加一些噪声扰动(SGD扰动较大的情况下)的话同样有可能从局部最优中逃离出来。袁洋在讲座中生动的分析到:“SGD可以看做是把原来的函数变得更平的一个算法,它可以抹去一些小坑”。
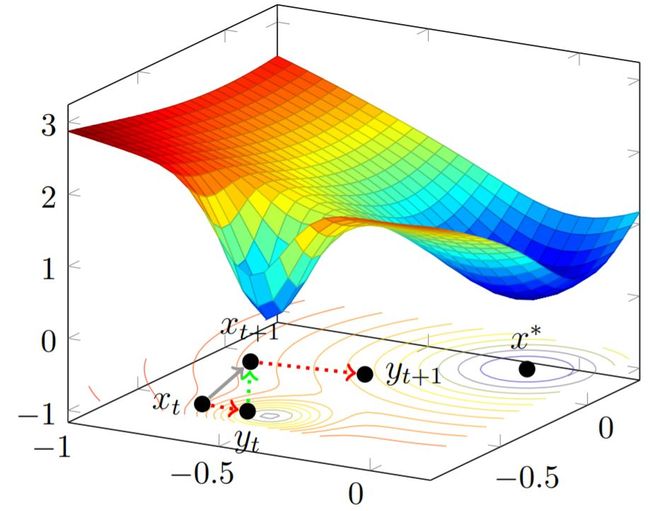
图7: SGD逃离最优点
两层神经网络的收敛性分析[Li, Yuan, NeurIPS’17]
第三部分,袁洋为我们带来了两层神经网络收敛性分析的成果展示(如图8)。论文主要介绍了:
1.对两层带跳跃连接的神经网络,SGD在多项式时间内分两个阶段收敛。第一阶段:逐渐远离最后的解,第二阶段:逐渐逼近最后的解,相关的理论也得到了实验证实[Orhan, Pitkow, ICLR’18];
2.是第一个关于SGD在非线性网络的收敛分析;
不过,这个属于神经网络理论的早期工作。目前使用超宽网络拟合理论可以得到更好的理论分析结果。
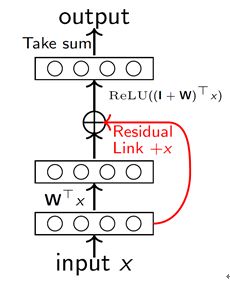
图8: 两层神经网络收敛性
未来研究设想
袁洋对未来主要有三方面的构想:
第一,可以用优化理论的这些工具更好地刻画神经网络的收敛规律;
第二,超宽网络拟合理论,虽然上文中提到的超宽网络拟合理论[Du et al ICML’19, Allen-Zhu, Li,Song, ICML’19, Zou et al MJL’19]优美地回答了神经网络的优化问题,但并不是说没有任何缺点,比如:超宽网络拟合理论使用的神经切线核在优化过程中几乎不会发生任何变化,但在实际中如果看神经网络具体的优化过程,会发现其实变化量还是很大的,目前看这个理论和实际发生的现象不太一样,所以在想能否找到和实际发生的现象更加吻合的收敛分析;
第三,泛化理论,很多文章都声称目前的神经网络有比较强的泛化性,那从理论角度能不能对这个现象理解的更好呢?最近的一篇论文[ [Nagarajan, Kolter, NeurIPS’19]提到,目前常用的泛化理论都是基于Uniform convergence框架,而这个收敛框架是具有一定局限性的,在这个框架下我们很难做出真正的有意义的泛化理论结果,因此,能否设计一些写的理论框架,来针对这个局限性解决泛化的理论问题。
![]()
机器学习可靠性
目前,机器学习可靠性是非常有意义和热门的方向,所谓机器学习可靠性,是指除了算法的预测准确率之外,为了能够真正落地使用,需要解决的一系列其他问题,包括:对抗样本与鲁棒性、可解释性、数据安全与隐私性、决策因果性、逻辑性、公平性、无偏见。虽然这些问题不涉及到最终的算法精度问题,但是如果这些问题不解决的话,在很多落地的场景中,如医疗场景、法律场景等很多算法将无法真正落地使用。本此讲座,袁洋主要从三方面为我们介绍他的研究。
带鲁棒性保证的算法设计[Lee, Yuan, Chang, Jaakkola, NeurIPS’19] [Teng, Lee, Yuan, in submission]
首先,请各位读者仔细观察图9,这是个非常有名的熊猫图,相信大部分同学都看到过,其大概意思说,如果把图9中左边的熊猫图作为神经网络的输入,网络认为有57.7%的置信度认为图中是熊猫。接着,我们根据网络结构精心设计一些噪声,并将其加入到原始的图片中后,得到了右边的熊猫图。新的图片人们用肉眼仍然可以分辨出一只熊猫,但是输入与左图相同的神经网络,结果网络认为类人猿的置信度为99.3%,这是一个非常典型的实验,证明该网络的鲁棒性不是非常好。
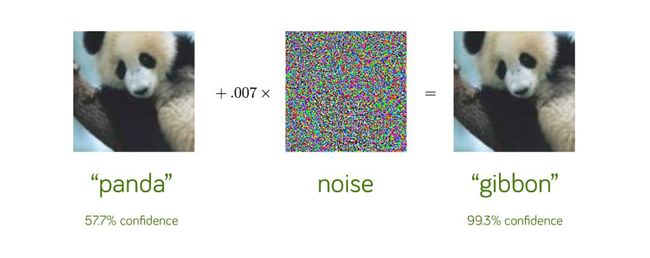
图9: 神经网络的低鲁棒性表现
当然,并不是某一个网络才会出现低鲁棒性的问题。虽然很多论文中声称自己的模型具有较好的鲁棒性,但是很多都是“虚假”鲁棒性模型。在2018年ICML最佳论文中[Athalye,Carlini, Wagner, ICML’18],作者调研了八篇顶级会议中被录用的鲁棒性模型文章,结果显示,虽然这些论文都被录用,并且被同行审议通过,文章均声称解决了上述图9中的“熊猫噪声问题”,但是其实模型均没有描述的那么有效,我们可以采取一些简单的攻击方法就能把模型的准确度降的很低甚至降为0,据图参数见图10。
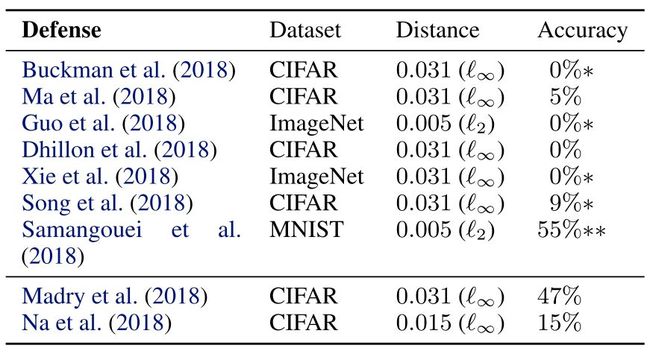
图10: 虚假鲁棒性模型实验数据
这是一个非常典型的“现代版矛与盾”的故事:甲提出了鲁棒模型A,乙提出了攻击算法B可以干掉A,丙提出了鲁棒模型C可以抵御B,丁提出了攻击算法D可以干掉C。我们发现,之所以现在的深度学习算法中有这样的问题,主要原因是因为没有很好的理论支持,我们没有办法从理论角度说明鲁棒性。因此最近一两年,人们开始从理论角度设计带有鲁棒性保证的算法。人们提出了各种巧妙的想法,目前最流行的方法是随机光滑化法[Cohen,Rosenfeld, Kolter, ICML’19]。
我们简单介绍什么是随机光滑化。如图11,图中左侧正方形为预测空间,正方形中的每一个点都是一个输入,每种颜色对应函数对输入的不同分类,比如:我们不妨假设蓝色区域中的每个点表示猩猩,绿色区域中的点表示熊猫,红色区域中的点表示随机。这是一个函数的分类区间,如果我们将输入函数投影到一个非常高维的空间中,那么我们很容易找到某个方向,沿着该方向可以穿过该色而抵达另外一个颜色区域中,这也就是所谓的对抗样本高维空间的解释。所谓随机光滑化,是用统计的方法来解决这个问题。我们不妨以x为中心画一个球,在这个球内统计每种颜色面积大小,根据每种颜色在球内的面积大小排序,颜色最高一类就是用随机光滑化方法得到的对x分类的判定。例如,图11中以x为中心画球,我们看到球内蓝色区域是面积最大的,所以判定该点的分类也是蓝色。随机光滑化法是比较稳定的一种分类方法,从图中我们也不难看出这个结论。例如,如果我们把x区往绿色区域移动一小点并以此点为圆心画的球,各种颜色统计后蓝色面积仍然是最大的。
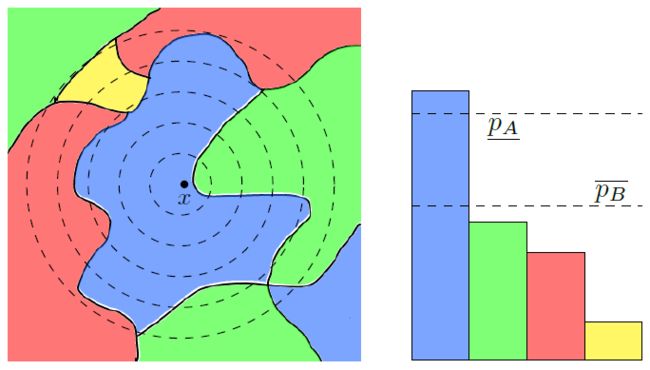
图11: 随机光滑化方法,投影高维空间
当然,这个方法并非完全不能攻击。如图12中我们看到,如果中心点往绿色区域走的足够远,那么球中面积最大的颜色很可能变成了绿色,这时攻击就成功了。
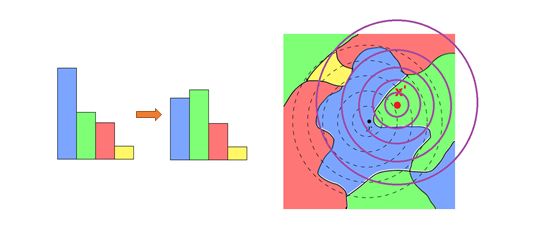
图12: 更稳定不代表不能够进行攻击
那么问题来了,我们能否从理论角度证明,到底走多远攻击能够成功呢?Cohen等人[Cohen, Rosenfeld, Kolter, ICML’19]在2019年所做的工作中指出:在l2利用高斯分布的对称性得到任何攻击方向都是等价的,并且给出了该范数空间下鲁棒性的界。袁洋在此基础上得出了范数取l0和l1时鲁棒性的界,如图13。感兴趣的读者可以阅读相关的文献继续研究。
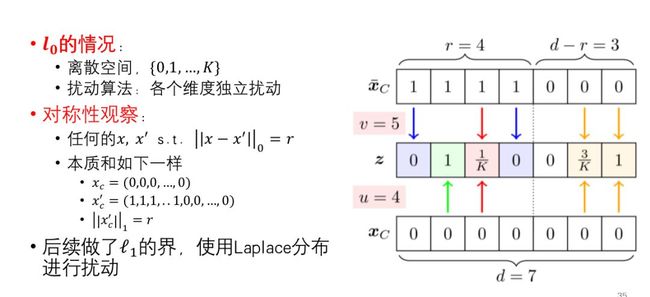
图13: l0和l1时该问题的界
数据安全与隐私保护[Huet. al. in submission] [Wu, Du, Yuan, in submission]
在机器学习可靠性方向,袁洋团队所做的第二类工作为数据安全与隐私保护,他在讲座中为我们分享了两类问题。第一类是:是否能够找到一种数据加密方法,使得当我们分享数据时,人类可以使用但是机器无法使用?例如图14中,原始图加密后所得的图输入机器学习的模型后计算结果失效,但是肉眼看起来二者差别并不是很大。
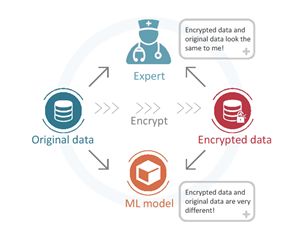
图14: 图片加密问题
袁洋团队是基于已有对抗样本相关的技术实现上述目标,见Madry教授团队的工作[Ilyaset al, NeurIPS’19],感兴趣的读者可以阅读论文了解算法详情。我们在这里为大家举一个较为通俗易懂的例子。首先我们解释两个名词:鲁棒性特征和非鲁棒性特征。所谓鲁棒性特征我们可以理解为人类可以察觉的特征,比如:狗的整体形态、两只眼睛、嘴巴的形状等等;所谓非鲁棒性特征即我们人类不易察觉但是机器学习可以提取的特征。在图15中,袁洋团队将原始图片中狗的非鲁棒性特征更换为猫的非鲁棒性特征,所得到的图片进行训练,结果显示模型对图片中带有狗的鲁棒性特征及猫的非鲁棒性特征的图片预测良好,对狗的原始图片预测能力较差。当然,我们可以做更为复杂的图片加密。(该研究工作仍在进行中)
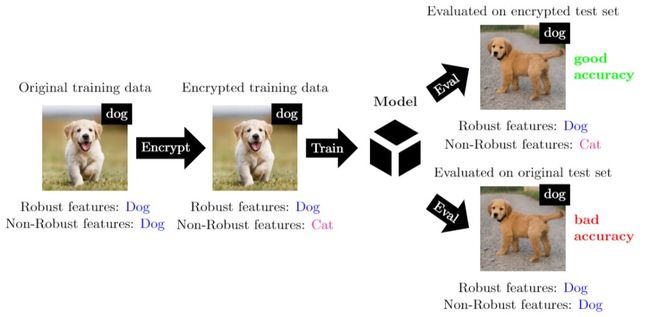
图15: 数据安全实例
另外一类问题是,是否能够找到一种数据加密方法,使得当我们分享数据时,机器可以使用但是人类无法使用?例如我们作为数据的提供商,想要把数据交给某个人工智能公司训练模型,但是对方极有可能会将数据/模型卖给第三方,此刻我们该如何保护自己的数据?目前这方面的工作,袁洋团队仍在继续探索,主要的思路是:将图片通过流模型转换到抽象的特征空间,在特征空间中进行加密后再将其通过流模型转换为图片,从而得到加密后的图片。由于整个转换在特征空间中进行,因此图片虽然看起来不甚相同,但是仍然保留了很多相通的语义信息。如果同时能确保特征转换绝对私密,那么该过程将不会被破解。
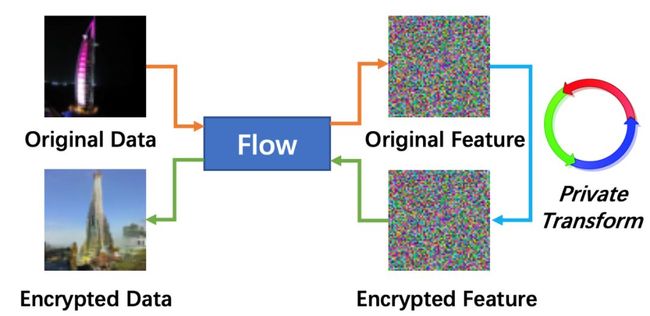
图16: 数据在特征空间中进行加密
未来研究设想
袁洋对于机器学习可靠性的未来设想主要有:
第一:探索各类新的问题;
第二:探索各类可靠性问题间的相互关系,包括鲁棒性和可解释性 [Tsipras et al, 18]、因果推断,与贝叶斯网络结合、数据共享与数据安全、算法设计,理论保证等,最终目标是让机器学习技术更饱满。
![]()
机器学习与算法优化
袁洋认为,机器学习与算法优化之间应该形成正向反馈作用:我们设计更好的算法解决机器学习问题,从理论方面推动机器学习的发展;同时,我们使用机器学习技术设计更好的算法,从数据方面推动算法的发展。在这一研究方向中,袁洋主要介绍了两方面的内容。
自动调参数法[Hazan, Klivans, Yuan, ICLR’2018]
自动调参数法是目前机器学习中非常热门的方向,包括:调整网络结构、网络层数、网络部件、Mini-batch大小以及训练算法、优化算法步长等。袁洋团队目前在这方面的研究表示:如果参数对应的函数可以被大小s的决策树近似,那么我们可以采用布尔泛函分析及压缩感知技术来学习决策树,并且极大的优化了采样复杂度,只有![]() ,并且非常适合并行,实验证明得到比手调更好的解。
,并且非常适合并行,实验证明得到比手调更好的解。
加速矩阵低秩分解算法[Indyk, Vakilian, Yuan, NeurIPS’19]
正如上文中所说,我们第二类工作的核心思想是使用数据来帮助算法设计。袁洋为我们介绍了低秩分解的一些优化想法。我们知道,经典的低秩分解方法为Sketching方法,即:
选择一个随机矩阵![]() ,其中m很小,计算
,其中m很小,计算![]() (很小),最后对SA计算SVD。该算法理论证明可以应用到任何场景,但是如果某些特定的场景中,袁洋表示,可以使用优化方法学习更好的S,使得S不再是一个任意的随机矩阵。可以使用导数方法不断优化S来适应特定的问题。
(很小),最后对SA计算SVD。该算法理论证明可以应用到任何场景,但是如果某些特定的场景中,袁洋表示,可以使用优化方法学习更好的S,使得S不再是一个任意的随机矩阵。可以使用导数方法不断优化S来适应特定的问题。
未来研究设想:
袁洋对未来主要有三方面的构想:
第一,针对各种传统算法进行改进,使得其在实际应用中能够得到更好的效果。例如:各种传统数据结构(搜索树)、各种嵌入算法(例如树分解算法)。
第二,针对已有算法进行理论分析,包括:找出传统算法与机器学习技术结合的共性,提出分析方案、应用于新的问题。
第三,使用机器学习技术处理NP-难问题,包括:找到某一类NP-难问题的应用场景、在给定数据分布下找到更快算法。








