一、关于Pandas
【简介】: pandas是建立在Numpy基础上的高效数据分析处理库,是Python的重要数据分析库。pandas提供了众多的高级函数,极大地简化了数据处理的流程,尤其是被广泛地应用于金融领域的数据分析。
【学习参考】pandas官网: http://pandas.pydata.org/

二、Pandas特点
pandas主要特点主要有以下几个方面,力图营造一个Pandas共呢能十分强大的印象:
- 带有标签的数据结构,Pandas库主要围绕Series类型(一维)和DataFrame类型(二维)这两种数据结构。
- 允许简单索引和多级索引;
- 轻松处理浮点数据中的丢失数据(以NaN表示)以及非浮点数据;
- 功能强大,灵活的按组功能来执行对数据集拆分申请,联合行动,对于聚合和转换数据;
- 可以轻松地将其他Python和NumPy数据结构中的不同索引的数据转换为DataFrame对象;
- 基于智能标签的切片,花式索引和 大型数据集的子集;
- 直观的合并和连接数据集;
- 数据集的灵活的重塑和旋转;
【重点指南】:下面将重点介绍pandas 中的三大数据结构:Series、DATa Frame、Index;
三、Series类型
【介绍】:Series可以运用ndarray或字典的几乎所有索引操作和函数,融合了字典和ndarray的优点。
# 导入包
import numpy as np
import pandas as pd

1、把series当成Numpy的数组来操作
data[1:3]
输出:
1 0.50
2 0.75
dtype: float64
【注释】:Series定义时,可以自己指定索引。
2、将Series当成一个特殊的字典
population_dict = {'Californis':345987634,'New York':40768934,'Florida':76543212,'Illinois':156898456}
population = pd.Series(population_dict)
population
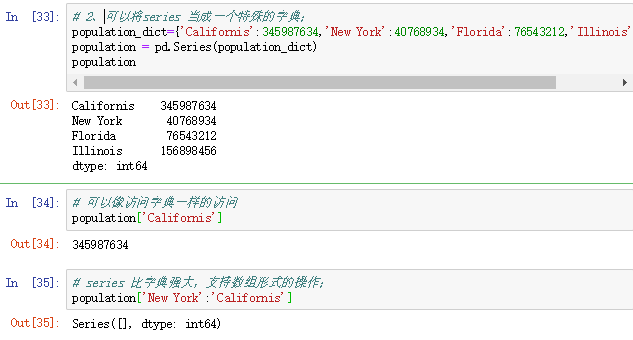
【注释】:Series可以像访问字典一样的访问,但是Series比字典强大,支持数组形式的操作;
population['Californis']
population['New York':'Californis']
3、创建series对象
基本形式:pd.Series(data,index=index),(index是可选参数)。
- data 可以是列表或者numpy 数组;
- data 可以是一个标量。创建时会被重复填充到各个索引上。
-
data 可以是一个字典;
 创建series对象.png
创建series对象.png
【注释】:每一种创建方式,都可以通过指定的索引,筛选需要的结果;
四、DataFrame类型
【介绍】:DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)。
(1)、将DataFrame对象当成Numpy数组
area_dict= {'Californis':336784,'New York':4908874,'Florida':43212,'Illinois':12986}
area = pd.Series(area_dict)
states = pd.DataFrame({'population':population,'area':area})
states
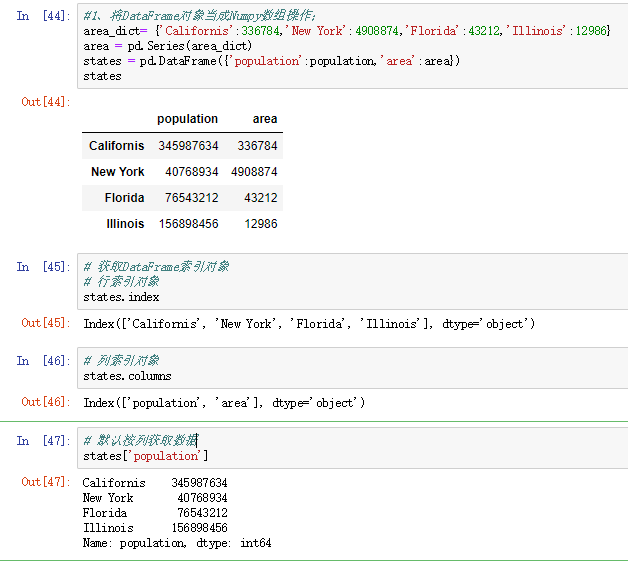
# 行索引对象
states.index
# 列索引对象
states.columns
# 默认按列获取数据
states['population']
(2)、创建DataFrame对象
1、通过Series创建
area_dict= {'Californis':336784,'New York':4908874,'Florida':43212,'Illinois':12986}
area = pd.Series(area_dict)
pd.DataFrame(population,columns=['population'])
# columns: 用来指定列的索引名称;
---
输出:
population
Californis 345987634
New York 40768934
Florida 76543212
Illinois 156898456
2、通过字典列表创建
data = [{'a':i,'b':2*i} for i in range(3)]
pd.DataFrame(data)
---
输出:
a b
0 0 0
1 1 2
2 2 4
【注释】: 如果字典中有些键不存在,Pandas 会用缺失值NaN来表示
3、通过Series对象字典来创建
pd.DataFrame({'population':population,'area':area})
--
输出:
population area
Californis 345987634 336784
New York 40768934 4908874
Florida 76543212 43212
Illinois 156898456 12986
4、通过Numpy 的二维数组创建
5、从Numpy 的结构化数组创建
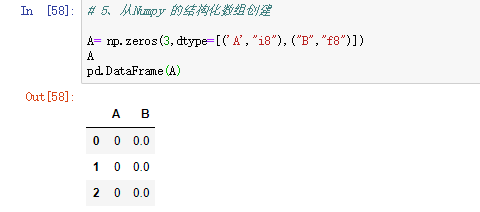
【小提示】:默认情况下,Dataframe和Series之间的算术运算会将Series的索引匹配到的Dataframe的列,沿着列一直向下传播。若索引找不到,则会重新索引产生并集。
五、 Index 类型
【介绍】: pandas的索引对象负责管理轴标签和其他元数据(比如轴名称等)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index。Index对象不可修改,从而在多个数据结构之间安全共享。
(1)使用Pandas创建Index对象
- 1、将Index看做不可变得数组
ind[1]
ind[::2]
print(ind.size,ind.shape, ind.ndim,ind.dtype)
# Index 对象:拥有与Numpy数组相似的属性
# 注意,Index对象是不可变的,这样使得多个Series或者DataFrame之间共享数据更安全。
-
2、将Index看做有序的集合

(2)Pandas属性与方法汇总
| 属性或方法 | 说明 |
|---|---|
axes |
返回行轴标签列表 |
dtype/dtypes |
返回对象的数据类型 |
empty |
如果系列为空,则返回True |
ndim |
返回底层数据的维数 |
size |
元素总数 |
values |
将系列作为ndarray返回 |
head() |
返回前n行 |
tail() |
返回最后n行 |
T |
转置行和列,适用于DataFrame |
关于更多Pandas的使用,可参考:https://blog.csdn.net/lolita0164/article/details/80258990