
主要结论
1.测试自动化是一种妥善记录并具备清晰定义的方法,借此可以反复运行同一套测试脚本。然而与此同时,这种测试自动化脚本还可进一步实现其他更有创意的应用。
2.虽然自动化的分析思维很难实现,但我们的脚本中无疑可以具备一定的随机性。
3.测试中“随机性”的具体程度各异:从随机输入和参数,再到全面的随机测试用例,情况不一而足。
4.很难将随机步骤与相应的验证措施匹配起来,但我们可以使用不同的验证策略确保应用程序能够按照预期工作。
5.随机测试无法取代主观或传统测试技术,但可在回归测试过程中让我们对应用程序质量更为自信。
正如Cem Kaner在他的一片教程中所说,探索式测试是一种强调个人自由度和个体测试人员责任的软件测试方式,可通过将与测试有关的学习、测试设计、测试执行,以及测试结果的理解视作一系列彼此提携,在项目完整过程中并行执行的活动,借此对测试工作的成果进行持续不断的优化。

简而言之,按照他的定义,众所周知的“软件质量和消费者(Software Quality and Consumer)”主张为测试人员提供了在项目中按照自己认为合适的方式进行测试的自由和责任。循序渐进地记录所有规范,这种做法已经不再是必须,原因也很简单,创意过程基本式无法记录的,对吧!在他在TestBash 3大会上有关测试中决策工作的演讲中,Mark Tomlinson对系统的主观理解这一想法表示支持。如果将其作为探索式的,基于风险和基于会话的测试技术(可将其称之为主观技术)的核心,测试者将能主观地确定应用程序中可能导致失败的重要环节。
可以参看这张旋转舞者的动力学错觉示意图:不同时刻内,我们的大脑或判断舞者以一个特定的顺序旋转:向左或向右。测试工作也会面临类似情况:我们可能考虑使用不同流程实现相同结果,或相同流程导致虽不同但符合预期的结果,或者,嗯……任何其他结果。
整个测试执行过程所用的主观技术可以通过各种成熟的分析思维和“随机性”的优势加以引导。其中后者是一个更重要的要素,本文,将揭露自动化测试中“随机化”的神秘面纱。
如果你感觉到学编程有些吃力,但是又对IT行业非常喜爱的话,可以加测试交流群:1017539290,进群免费领取测试学习资料!
明确起见,测试自动化并不是一种创作活动,而是一种妥善记录且清晰定义的方法,借此可以让同一套测试脚本反复运行使用。问题在于,我们该如何使用这些测试自动化脚本,同时更更具创意?
产品质量随时间而变
产品质量模型和所记录的测试场景可通过特定的状态机以及外部特性加以概括。这一点正是测试自动化所热爱的。测试自动化所关注的正是根据一些非常具体的测试需求集编写测试脚本。
这种做法很适合功能性回归测试:清理、打磨、全新发布,随后由开发大师创建。姑且将其称之为Shiny吧。
但经过一段冗长、精疲力竭的开发时间线后(伴随着多次发布,长达数年的支持,数百个Bug的修复和功能请求等),系统会变成什么样?
确实,从用户接口的角度来看,可能非常类似于那种虽然老旧但依然工作良好的系统,但表面之下,这种情况通常被称之为“大泥球”。
对于这样的系统,算使用自动化脚本,具体功能的哪些部分依然能获得和初生产发布时同等程度的测试?也许只有30%-80%的部分可以吧。那么其他功能呢?不知道。
当然,此时简单的办法可能是审查所有现有的质量文档,改良原有的场景,(即时)引入新的场景等。但考虑到业内的经验,随着遗留系统的规则测试文档逐渐过时,虽然更新工作依然重要,但这种做法并非总是可行。
为测试自动化解决方案打造妥善定义的架构
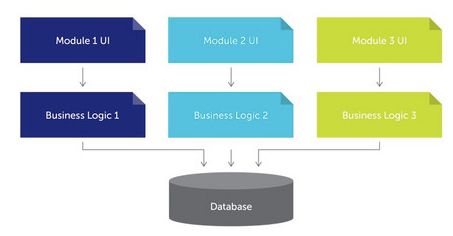
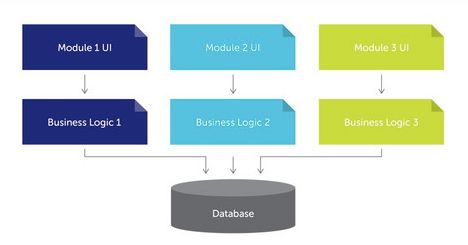
下图是一个精简的测试自动化解决方案的范例图,其中包含三层(类似于基于UI、业务逻辑和数据库实现业务应用程序的方法):UI/API映射、业务裸机,以及测试脚本。
1.UI/API映射代表该解决方案的技术端:UI自动化工具程度与自动化系统的UI高度绑定,这一层所用的方法可能类似于focus()、type_text()、click_button()。
2.业务逻辑是一种由来自业务操作的关键字组成的库。业务操作是指可以在应用程序中执行的某个步骤(如login()、create_user()、validate_user_created())。
3.测试脚本负责执行一系列链再一起的业务步骤。
深入了解独立测试(Separate Test)
考虑这样一种简单的记录测试用例:执行这个 – 验证这个,执行那个 – 验证那个,执行某某 – 验证某某。合格的自动化开发者会创建一系列类似下面这样的方法:
do_that(), verify_that(), do_this(), verify_this(), do_bla().
测试脚本会按照某种特定的顺序调用这样的方法:
mySpecifiedCase_1(){
do_that();
verify_that();
do_this();
verify_this();
do_bla();
verify_that();
verify_this();
}
由于脚本没找到任何Bug,我们在某些特定阶段的任务变成让它查找潜在的系统问题。
随机化方法1 – 裸随机
从业务角度来说,自动化解决方案中任何步骤都是有效的。因此探索式测试使得我们可以自由地在任何时间点执行任何步骤。这些步骤的混搭也很简单。我们需要在执行过少数几次测试后,遵循已实现步骤打造“随机”测试用例。
输入:解决方案中所有业务方法的数量,要生成的测试脚本数量,生成每个测试脚本所需步骤数量。
输出:类似于下列脚本:
myRandomCase_1(){
do_that();
do_bla();
verify_this();
}
很明显,算某些测试用例可能(甚至已经)成功运行,大部分依然会失败,因为大量用例实际上是在试图完成无效操作。如果还没执行过do_this(),那么verify_this()无疑会失败。
随机化方法2 – 有先决条件的随机方法
这种方式的想法在于只有在工作流中已包含先觉步骤后,才向工作流中加入后续步骤,但这需要对代码库进行必要的扩充,确保测试案例生成器可以理解并保证准确的序列。为此可在方法之上添加特性或注解:
@Reguires(do_this)
verify_this()
{…}
这样我们得到了:
myRandomCase_2(){
do_bla();
do_this();
verify_this(); //can be added, because prerequisite step is already in test
}
这是一种更可预测的方法。但如果do_this()和verify_that()需要在同一个Page1上执行,而do_bla()已经到了Page2又该怎样?

此时我们面临一个新问题:verify_that()会失败,因为无法找到执行所需的控制/上下文。
人工随机化方法3 – 上下文感知
如果你感觉到学编程有些吃力,但是又对IT行业非常喜爱的话,可以加测试交流群:1017539290,进群免费领取测试学习资料!
测试生成器必须了解执行位置上下文(例如Web开发中的“页面”)。当然,此时也可以通过特性/注解为生成器提供活跃上下文。
@ReguiresContext(pageThis)
verify_this()
{…}
@ReguiresContext(pageThis)
do_this()
{…}
@ReguiresContext(pageThis)
@MovesContextTo(pageThat)
do_bla()
{…}
本例中do_this()和verify_this()不会放在将上下文改为pageThat的方法,或上下文为pageThat的方法之后。
因此我们可以得到一个类似下面这样的测试脚本:
myRandomCase_3(){
do_this();
do_bla();
do_that();
}
或者也可以通过方法链实现。假设业务方法返回的对象为页面,测试案例生成器会持续追踪执行“步骤”前后浏览器中显示的页面,因此可以确定需要调用验证或“步骤”方法的正确页面。这种方法需要额外检查以验证流程是否正确,但这个操作可以无须注解实现。
筛选恰当的用例
至此介绍的方法已经可以生成相当大量的测试用例。
主要问题在于,验证过程本身,以及验证失败的测试场景是否是应用程序内的Bug,而非自动化测试脚本逻辑导致的,这些工作也需要耗费大量时间。
因此可以实现一种“预言”类,借此预测所获得的结果是否满意,或是否代表任何错误信息,并且必要时可进行后续分析。然而本例我们选择了一个略微不同的方法。
可以通过下列这一套规则代表应用程序的失败是Bug引起的:
1.500错误或类似页面
2.JavaScript错误
3.“未知错误”或因为误用造成的类似的错误信息
4.应用程序日志中有关异常和/或错误情况的信息
5.发现与任何其他产品有关的错误
本例中,可在每个步骤执行完毕后验证应用程序状态。因此自动生成的脚本看起来是这样的:
myRandomCase_3(){
do_this();
validate_standard_rules();
do_bla();
validate_standard_rules();
do_that();
validate_standard_rules();
}
其中validate_standard_rules()方法可以搜索上文提到的各种问题。
注意:通过与OOP结合,这种方法会显得更为强大,可以检测出实际的Bug。在Page Object超类实现常规检查需要查找“常规问题”,例如JavaScript错误、日志中的应用程序错误等。对于与特定页面有关的合理检查,可以绕过这种方法额外增加针对具体页面的检查。
实验
为了进行实验,我们决定使用公开的邮件系统。考虑到Gmail和Yahoo的流行度,这些系统中所有存在的Bug都已被发现的可能性相当高。因此我们选择了ProtonMail。

Taking Over Random
假设自动化解决方案已经位,我们“采用”了Shiny系统的自动化测试机制:首先建立一个通用的Java/Selenium测试项目,其中包含几个使用Page Object模式实现的冒烟测试。随后按照佳实践,所有业务方法可以返回一个新的Page Object(针对业务方法结束时依然显示在浏览器中的页面)或当前Page Object,除非页面被更改。
为进行自动化探索式测试,我们增加了包含在explr.core包中的类,其中感兴趣的当属TestCaseGenerator和TesCaseExecutor。
TestCaseGenerator
为了生成新的“随机”测试用例,可以通过TestCaseGenerator类调用两个generateTestCase方法之一。这两个方法都能以参数的方式接受代表所生成测试用例中“步骤验证对”数量的整数。第二个方法还可额外接受一个代表要使用的“验证策略”数量的参数(第一个方法使用默认策略,本例为USE_PAGE_SANITY_VERIFICATIONS)。
验证策略代表在向测试用例添加“检查”步骤时所用的方法。目前我们有两个选项:
1.USE_RANDOM_VERIFICATIONS:第一个,同时也是明显的策略。该策略的想法在于,使用来自页对象的当前验证方法。但不足之处在于严重依赖上下文。例如:我们随机选择了一个方法来验证特定主题的消息是否存在。首先,我们必须知道要查找哪个主题。为此我们引入了@Default注解和DefaultTestData类。DefaultTestData包含的常规测试数据可用于随机测试。@Default注解可用于将该数据绑定给特定的方法参数。随后我们需要确保包含该主题的消息先于验证操作已存在(可在执行该规范的过程中,或之前的任何测试过程中创建)。为此可通过@Depends注解告诉TestCaseGenerator检查特定方法的调用,如果当前步骤之前没找到则直接添加。此外我们还需要确保消息没有在验证之前删除。我们发现对于生成的测试用例,依赖性问题大幅降低了随机化程度,并且这种方法的稳定性也无法满足要求。
2.USE_PAGE_SANITY_VERIFICATIONS:该策略可检查显而易见的应用程序失败,如显示了错误的页,错误信息,JavaScript错误,应用程序日志中的错误等。在依赖性方面这个策略更灵活,可在需要时实现针对具体页的检查,例如已经足够灵活到可以找出实际的Bug。目前我们将其用作默认的验证策略。
TestCaseGenerator类可按照类名搜索Page对象:每个名称中包含“Page”字符串的类都会被看作是页对象。页对象的所有公开方法会被视作业务方法。名称包含“Verify”字符串的业务方法会被视作验证,所有其他方法会被视作测试步骤。@IgnoreInRandomTesting注解可用于从列表中排除某些工具方法或整个页对象。

随后可从两个列表中随机选择方法生成测试用例:一个列表包含测试步骤,一个列表包含验证步骤(如果所选验证策略需要验证步骤的话)。选择第一个方法后,将检查其返回值是否为另一个页对象。如果返回值是另一个页对象,那么将从其方法中选择下一个步骤(参见上文备注)。为避免在两个页之间循环往复,有一成的概率会跳转至一个完全随机的页面。如果方法使用@Depends注解标注了任何依赖项,则会按需解决这些问题并添加。
为避免出现从当前所显示页之外其他对象调用测试方法的情况,生成的测试用例会传递一个额外的验证,借此添加缺少的导航调用。
TesCaseExecutor
生成之后,测试用例基本上是一种“类-方法对”列表,可通过特定方式执行或保存。尽管可在运行时执行,但从调试和后续分析的角度来看,保存为文件是一种更好的做法。
如果你感觉到学编程有些吃力,但是又对IT行业非常喜爱的话,可以加测试交流群:1017539290,进群免费领取测试学习资料!
生成的测试用例可通过多种方式执行,可以TesCaseExecutor作为其接口,以SaveToFileExecutor作为的实现,借此可简单地创建一个代表所生成测试用例的.java文件。令人惊异的是,这种相当简单的解决方案完全满足了我们的需求:实现速度快,可对测试结果进行深入分析,并能了解具体的生成方式。的不足在于,必须手工编译并运行生成的测试用例,不过对于实验来说,这也算不得什么大问题。
SaveToFileExecutor生成的测试用例代码可通过模板转换为可编译的文件。这样生成的测试范例如下:
@Test(dataProvider = "WebDriverProvider")
public void test(WebDriver driver){
login(driver);
//****
ContactsPage contactspage = new ContactsPage(driver, true);
InboxMailPage inboxmailpage = contactspage.inbox();
inboxmailpage.sanityCheck();
ComposeMailPage composemailpage = inboxmailpage.compose();
composemailpage.sanityCheck();
composemailpage.setTo("[email protected]");
composemailpage.send();
inboxmailpage.sanityCheck();
List list = inboxmailpage.findBySubject("Seen that?");
inboxmailpage.sanityCheck();
inboxmailpage.inbox();
inboxmailpage.sanityCheck();
DraftsMailPage draftsmailpage = inboxmailpage.drafts();
draftsmailpage.sanityCheck();
inboxmailpage.inbox();
inboxmailpage.sanityCheck();
inboxmailpage.sendNewMessageToMe();
inboxmailpage.setMessagesStarred(true, "autotest", "Seen that?");
inboxmailpage.sanityCheck();
TrashMailPage trashmailpage = inboxmailpage.trash();
trashmailpage.sanityCheck();
//********
}
SaveToFileExecutor生成的代码位于
从所执行的操作方面来看,我们生成的用例多样化程度一般,但只要添加包含更多测试步骤的更多页对象即可轻松解决。
如果你感觉到学编程有些吃力,但是又对IT行业非常喜爱的话,可以加测试交流群:1017539290,进群免费领取测试学习资料!
在进行过上千个“随机”测试后,我们发现Protonmail没什么大问题(例如错误页),但浏览器汇报了一些JavaScript错误,对于依赖JavaScript进行邮件编解码工作的系统,这些问题非常重要。很明显,整个实验中我们并不能访问服务器日志,但实验的角度来说,已经足够展示出这样的方法对被测试系统质量的促进能起到多大的作用。
当然,随机测试无法取代主观或传统测试技术,但可在回归测试过程中让我们对应用程序质量更为自信。